應(yīng)對(duì)萬億數(shù)據(jù)上億并發(fā)!字節(jié)跳動(dòng)的圖數(shù)據(jù)庫研發(fā)實(shí)踐
一、圖狀結(jié)構(gòu)數(shù)據(jù)廣泛存在
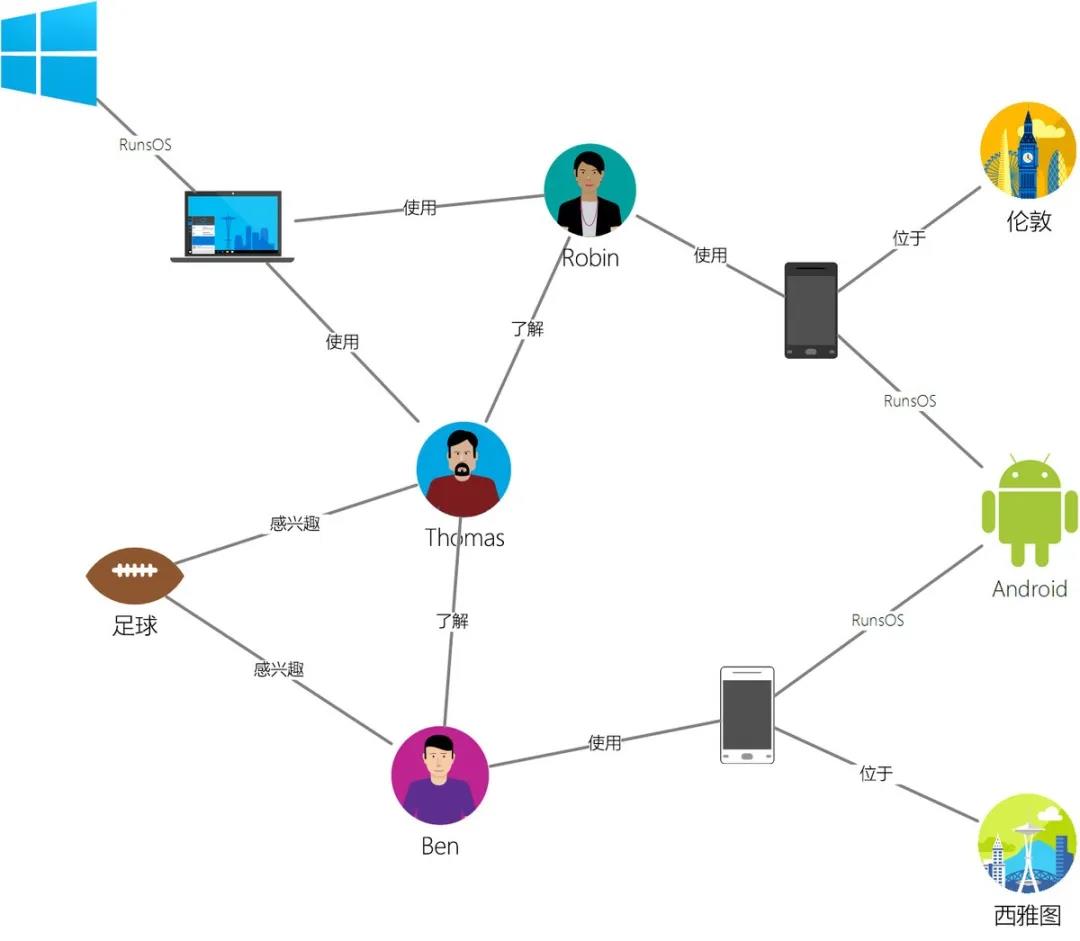
字節(jié)跳動(dòng)的所有產(chǎn)品的大部分業(yè)務(wù)數(shù)據(jù),幾乎都可以歸入到以下三種:
- 用戶信息、用戶和用戶的關(guān)系(關(guān)注、好友等);
- 內(nèi)容(視頻、文章、廣告等);
- 用戶和內(nèi)容的聯(lián)系(點(diǎn)贊、評(píng)論、轉(zhuǎn)發(fā)、點(diǎn)擊廣告等)。
這三種數(shù)據(jù)關(guān)聯(lián)在一起,形成圖狀(Graph)結(jié)構(gòu)數(shù)據(jù)。
為了滿足 social graph 的在線增刪改查場景,字節(jié)跳動(dòng)自研了分布式圖存儲(chǔ)系統(tǒng)——ByteGraph。針對(duì)上述圖狀結(jié)構(gòu)數(shù)據(jù),ByteGraph 支持有向?qū)傩詧D數(shù)據(jù)模型,支持 Gremlin 查詢語言,支持靈活豐富的寫入和查詢接口,讀寫吞吐可擴(kuò)展到千萬 QPS,延遲毫秒級(jí)。目前,ByteGraph 支持了頭條、抖音、 TikTok、西瓜、火山等幾乎字節(jié)跳動(dòng)全部產(chǎn)品線,遍布全球機(jī)房。在這篇文章中,將從適用場景、內(nèi)部架構(gòu)、關(guān)鍵問題分析幾個(gè)方面作深入介紹。
ByteGraph 主要用于在線 OLTP 場景,而在離線場景下,圖數(shù)據(jù)的分析和計(jì)算需求也逐漸顯現(xiàn)。2019 年年初,Gartner 數(shù)據(jù)與分析峰會(huì)上將圖列為 2019 年十大數(shù)據(jù)和分析趨勢之一,預(yù)計(jì)全球圖分析應(yīng)用將以每年 100% 的速度迅猛增長,2020 年將達(dá)到 80 億美元。因此,我們團(tuán)隊(duì)同時(shí)也開啟了在離線圖計(jì)算場景的支持和實(shí)踐。
下面會(huì)從圖數(shù)據(jù)庫和圖計(jì)算兩個(gè)部分,分別來介紹字節(jié)跳動(dòng)在這方面的一些工作。
二、自研圖數(shù)據(jù)庫(ByteGraph)介紹
從數(shù)據(jù)模型角度看,圖數(shù)據(jù)庫內(nèi)部數(shù)據(jù)是有向?qū)傩詧D,其基本元素是 Graph 中的點(diǎn)(Vertex)、邊(Edge)以及其上附著的屬性;作為一個(gè)工具,圖數(shù)據(jù)對(duì)外提供的接口都是圍繞這些元素展開。
圖數(shù)據(jù)庫本質(zhì)也是一個(gè)存儲(chǔ)系統(tǒng),它和常見的 KV 存儲(chǔ)系統(tǒng)、MySQL 存儲(chǔ)系統(tǒng)的相比主要區(qū)別在于目標(biāo)數(shù)據(jù)的邏輯關(guān)系不同和訪問模式不同,對(duì)于數(shù)據(jù)內(nèi)在關(guān)系是圖模型以及在圖上游走類和模式匹配類的查詢,比如社交關(guān)系查詢,圖數(shù)據(jù)庫會(huì)有更大的性能優(yōu)勢和更加簡潔高效的接口。
1、為什么不選擇開源圖數(shù)據(jù)庫
圖數(shù)據(jù)庫在 90 年代出現(xiàn),直到最近幾年在數(shù)據(jù)爆炸的大趨勢下快速發(fā)展,百花齊放;但目前比較成熟的大部分都是面對(duì)傳統(tǒng)行業(yè)較小的數(shù)據(jù)集和較低的訪問吞吐場景,比如開源的 Neo4j 是單機(jī)架構(gòu);因此,在互聯(lián)網(wǎng)場景下,通常都是基于已有的基礎(chǔ)設(shè)施定制系統(tǒng):比如 Facebook 基于 MySQL 系統(tǒng)封裝了 Social Graph 系統(tǒng) TAO,幾乎承載了 Facebook 所有數(shù)據(jù)邏輯;Linkedln 在 KV 之上構(gòu)建了 Social Graph 服務(wù);微博是基于 Redis 構(gòu)建了粉絲和關(guān)注關(guān)系。
字節(jié)跳動(dòng)的 Graph 在線存儲(chǔ)場景, 其需求也是有自身特點(diǎn)的,可以總結(jié)為:
- 海量數(shù)據(jù)存儲(chǔ):百億點(diǎn)、萬億邊的數(shù)據(jù)規(guī)模;并且圖符合冪律分布,比如少量大 V 粉絲達(dá)到幾千萬;
- 海量吞吐:最大集群 QPS 達(dá)到數(shù)千萬;
- 低延遲:要求訪問延遲 pct99 需要限制在毫秒級(jí);
- 讀多寫少:讀流量是寫流量的接近百倍之多;
- 輕量查詢多,重量查詢少:90%查詢是圖上二度以內(nèi)查詢;
- 容災(zāi)架構(gòu)演進(jìn):要能支持字節(jié)跳動(dòng)城域網(wǎng)、廣域網(wǎng)、洲際網(wǎng)絡(luò)之間主備容災(zāi)、異地多活等不同容災(zāi)部署方案。
事實(shí)上,我們調(diào)研過了很多業(yè)界系統(tǒng), 這個(gè)主題可以再單獨(dú)分享一篇文章。但是,面對(duì)字節(jié)跳動(dòng)世界級(jí)的海量數(shù)據(jù)和海量并發(fā)請(qǐng)求,用萬億級(jí)分布式存儲(chǔ)、千萬高并發(fā)、低延遲、穩(wěn)定可控這三個(gè)條件一起去篩選,業(yè)界在線上被驗(yàn)證穩(wěn)定可信賴的開源圖存儲(chǔ)系統(tǒng)基本沒有滿足的了;另外,對(duì)于一個(gè)承載公司核心數(shù)據(jù)的重要的基礎(chǔ)設(shè)施,是值得長期投入并且深度掌控的。
因此,我們?cè)?18 年 8 月份,開始從第一行代碼開始踏上圖數(shù)據(jù)庫的漫漫征程,從解決一個(gè)最核心的抖音社交關(guān)系問題入手,逐漸演變?yōu)橹С钟邢驅(qū)傩詧D數(shù)據(jù)模型、支持寫入原子性、部分 Gremlin 圖查詢語言的通用圖數(shù)據(jù)庫系統(tǒng),在公司所有產(chǎn)品體系落地,我們稱之為 ByteGraph。下面,會(huì)從數(shù)據(jù)模型、系統(tǒng)架構(gòu)等幾個(gè)部分,由淺入深和大家分享我們的工作。
2、ByteGraph 的數(shù)據(jù)模型和 API
1)數(shù)據(jù)模型
就像我們?cè)谑褂?SQL 數(shù)據(jù)庫時(shí),先要完成數(shù)據(jù)庫 Schema 以及范式設(shè)計(jì)一樣,ByteGraph 也需要用戶完成類似的數(shù)據(jù)模型抽象,但圖的數(shù)據(jù)抽象更加簡單,基本上是把數(shù)據(jù)之間的關(guān)系“翻譯”成有向?qū)傩詧D,我們稱之為“構(gòu)圖”過程。
比如在前面提到的,如果想把用戶關(guān)系存入 ByteGraph,第一步就是需要把用戶抽象為點(diǎn),第二步把"關(guān)注關(guān)系”、“好友關(guān)系”抽象為邊就完全搞定了。下面,我們就從代碼層面介紹下點(diǎn)邊的數(shù)據(jù)類型。
① 點(diǎn)(Vertex)
點(diǎn)是圖數(shù)據(jù)庫的基本元素,通常反映的是靜態(tài)信息。在 ByteGraph 中,點(diǎn)包含以下字段:
- 點(diǎn)的id(uint64_t): 比如用戶id作為一個(gè)點(diǎn)
- 點(diǎn)的type(uint32_t): 比如appID作為點(diǎn)的type
- 點(diǎn)的屬性(KV 對(duì)):比如 'name': string,'age': int, 'gender': male,等自定義屬性
- [id, type]唯一定義一個(gè)點(diǎn)
② 邊(Edge)
一條邊由兩個(gè)點(diǎn)和點(diǎn)之間的邊的類型組成,邊可以描述點(diǎn)之間的關(guān)系,比如用戶 A 關(guān)注了用戶 B ,可以用以下字段來描述:
- 兩個(gè)點(diǎn)(Vertex): 比如用戶A和用戶B
邊的類型(string): 比如“關(guān)注”
- 邊的時(shí)間戳(uint64_t):這個(gè)t值是業(yè)務(wù)自定義含義的,比如可以用于記錄關(guān)注發(fā)生的時(shí)間戳
- 邊屬性(KV對(duì)):比如'ts_us': int64 描述關(guān)系創(chuàng)建時(shí)間的屬性,以及其他用戶自定義屬性
③ 邊的方向
在 ByteGraph 的數(shù)據(jù)模型中,邊是有方向的,目前支持 3 種邊的方向:
- 正向邊:如 A 關(guān)注 B(A -> B)
- 反向邊:如 B 被 A 關(guān)注(B <- A)
- 雙向邊:如 A 與 B 是好友(A <-> B)
2)場景使用偽碼舉例
構(gòu)圖完畢后,我們就可以把業(yè)務(wù)邏輯通過 Gremlin 查詢語言來實(shí)現(xiàn)了;為便于大家理解,我們列舉幾種典型的場景為例。
場景一:記錄關(guān)注關(guān)系 A 關(guān)注 B
- // 創(chuàng)建用戶A和B,可以使用 .property('name', 'Alice') 語句添加用戶屬性
- g.addV().property("type", A.type).property("id", A.id)
- g.addV().property("type", B.type).property("id", B.id)
- // 創(chuàng)建關(guān)注關(guān)系 A -> B,其中addE("關(guān)注")中指定了邊的類型信息,from和to分別指定起點(diǎn)和終點(diǎn),
- g.addE("關(guān)注").from(A.id, A.type).to(B.id, B.type).property("ts_us", now)
場景二:查詢 A 關(guān)注的且關(guān)注了 C 的所有用戶
用戶 A 進(jìn)入用戶 C 的詳情頁面,想看看 A 和 C 之間的二度中間節(jié)點(diǎn)有哪些,比如 A->B,B->C,B 則為中間節(jié)點(diǎn)。
- // where()表示對(duì)于上一個(gè)step的每個(gè)執(zhí)行結(jié)果,執(zhí)行子查詢過濾條件,只保留關(guān)注了C的用戶。
- g.V().has("type", A.type).has("id", A.id).out("關(guān)注").where(out("關(guān)注").has("type", C.type).has("id", C.id).count().is(gte(1)))
場景三:查詢 A 的好友的好友(二度關(guān)系)
- // both("好友")相當(dāng)于in("好友")和out("好友")的合集
- g.V().has("type", A.type).has("id", A.id).both("好友").both("好友").toSet()
3、系統(tǒng)架構(gòu)
前面幾個(gè)章節(jié),從用戶角度介紹了 ByteGraph 的適用場景和對(duì)外使用姿勢。那 ByteGraph 架構(gòu)是怎樣的,內(nèi)部是如何工作的呢,這一節(jié)就來從內(nèi)部實(shí)現(xiàn)來作進(jìn)一步介紹。
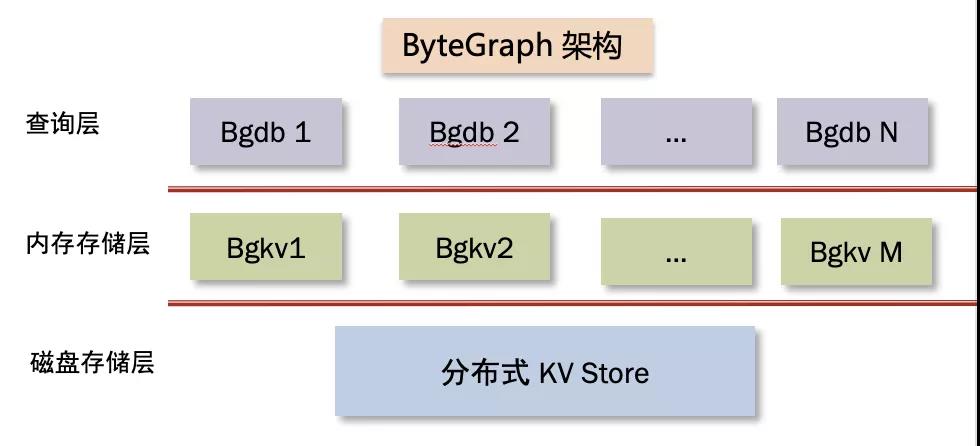
下面這張圖展示了 ByteGraph 的內(nèi)部架構(gòu),其中 bg 是 ByteGraph 的縮寫。
就像 MySQL 通常可以分為 SQL 層和引擎層兩層一樣,ByteGraph 自上而下分為查詢層 (bgdb)、存儲(chǔ)/事務(wù)引擎層(bgkv)、磁盤存儲(chǔ)層三層,每層都是由多個(gè)進(jìn)程實(shí)例組成。其中 bgdb 層與 bgkv 層混合部署,磁盤存儲(chǔ)層獨(dú)立部署,我們?cè)敿?xì)介紹每一層的關(guān)鍵設(shè)計(jì)。
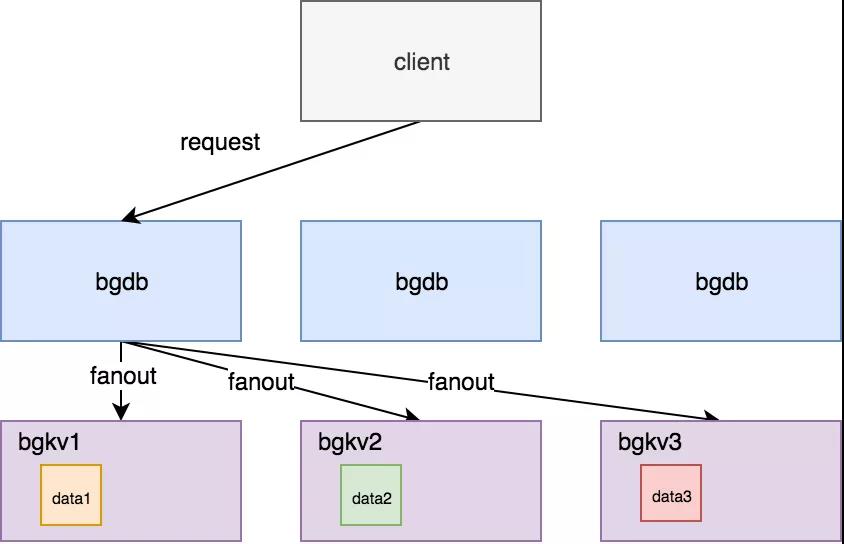
1)查詢層(bgdb)
bgdb 層和 MySQL 的 SQL 層一樣,主要工作是做讀寫請(qǐng)求的解析和處理;其中,所謂“處理”可以分為以下三個(gè)步驟:
- 將客戶端發(fā)來的 Gremlin 查詢語句做語法解析,生成執(zhí)行計(jì)劃;
- 并根據(jù)一定的路由規(guī)則(例如一致性哈希)找到目標(biāo)數(shù)據(jù)所在的存儲(chǔ)節(jié)點(diǎn)(bgkv),將執(zhí)行計(jì)劃中的讀寫請(qǐng)求發(fā)送給 多個(gè) bgkv;
- 將 bgkv 讀寫結(jié)果匯總以及過濾處理,得到最終結(jié)果,返回給客戶端。
bgdb 層沒有狀態(tài),可以水平擴(kuò)容,用 Go 語言開發(fā)。
2)存儲(chǔ)/事務(wù)引擎層(bgkv)
- bgkv 層是由多個(gè)進(jìn)程實(shí)例組成,每個(gè)實(shí)例管理整個(gè)集群數(shù)據(jù)的一個(gè)子集(shard / partition)。
- bgkv 層的實(shí)現(xiàn)和功能有點(diǎn)類似內(nèi)存數(shù)據(jù)庫,提供高性能的數(shù)據(jù)讀寫功能,其特點(diǎn)是:
接口不同:只提供點(diǎn)邊讀寫接口;
- 支持算子下推:通過把計(jì)算(算子)移動(dòng)到存儲(chǔ)(bgkv)上,能夠有效提升讀性能;
- 舉例:比如某個(gè)大 V 最近一年一直在漲粉,bgkv 支持查詢最近的 100 個(gè)粉絲,則不必讀出所有的百萬粉絲。
- 緩存存儲(chǔ)有機(jī)結(jié)合:其作為 KV store 的緩存層,提供緩存管理的功能,支持緩存加載、換出、緩存和磁盤同步異步 sync 等復(fù)雜功能。
從上述描述可以看出,bgkv 的性能和內(nèi)存使用效率是非常關(guān)鍵的,因此采用 C++ 編寫。
3)磁盤存儲(chǔ)層(KV Cluster)
為了能夠提供海量存儲(chǔ)空間和較高的可靠性、可用性,數(shù)據(jù)必須最終落入磁盤,我們底層存儲(chǔ)是選擇了公司自研的分布式 KV store。
4)如何把圖存儲(chǔ)在 KV 數(shù)據(jù)庫中
上一小節(jié),只是介紹了 ByteGraph 內(nèi)部三層的關(guān)系,細(xì)心的讀者可能已經(jīng)發(fā)現(xiàn),ByteGraph 外部是圖接口,底層是依賴 KV 存儲(chǔ),那么問題來了:如何把動(dòng)輒百萬粉絲的圖數(shù)據(jù)存儲(chǔ)在一個(gè) KV 系統(tǒng)上呢?
在字節(jié)跳動(dòng)的業(yè)務(wù)場景中,存在很多訪問熱度和“數(shù)據(jù)密度”極高的場景,比如抖音的大 V、熱門的文章等,其粉絲數(shù)或者點(diǎn)贊數(shù)會(huì)超過千萬級(jí)別;但作為 KV store,希望業(yè)務(wù)方的 KV 對(duì)的大小(Byte 數(shù))是控制在 KB 量級(jí)的,且最好是大小均勻的:對(duì)于太大的 value,是會(huì)瞬間打滿 I/O 路徑的,無法保證線上穩(wěn)定性;對(duì)于特別小的 value,則存儲(chǔ)效率比較低。事實(shí)上,數(shù)據(jù)大小不均勻這個(gè)問題困擾了很多業(yè)務(wù)團(tuán)隊(duì),在線上也會(huì)經(jīng)常爆出事故。
對(duì)于一個(gè)有千萬粉絲的抖音大 V,相當(dāng)于圖中的某個(gè)點(diǎn)有千萬條邊的出度,不僅要能存儲(chǔ)下來,而且要能滿足線上毫秒級(jí)的增刪查改,那么 ByteGraph 是如何解決這個(gè)問題的呢?
思路其實(shí)很簡單,總結(jié)來說,就是采用靈活的邊聚合方式,使得 KV store 中的 value 大小是均勻的,具體可以用以下四條來描述:
① 一個(gè)點(diǎn)(Vertex)和其所有相連的邊組成了一數(shù)據(jù)組(Group);不同的起點(diǎn)和及其終點(diǎn)是屬于不同的 Group,是存儲(chǔ)在不同的 KV 對(duì)的;比如用戶 A 的粉絲和用戶 B 的粉絲,就是分成不同 KV 存儲(chǔ);
② 對(duì)于某一個(gè)點(diǎn)的及其出邊,當(dāng)出度數(shù)量比較小(KB 級(jí)別),將其所有出度即所有終點(diǎn)序列化為一個(gè) KV 對(duì),我們稱之為一級(jí)存儲(chǔ)方式(后面會(huì)展開描述);
③ 當(dāng)一個(gè)點(diǎn)的出度逐漸增多,比如一個(gè)普通用戶逐漸成長為抖音大 V,我們則采用分布式 B-Tree 組織這百萬粉絲,我們稱之為二級(jí)存儲(chǔ);
④ 一級(jí)存儲(chǔ)和二級(jí)存儲(chǔ)之間可以在線并發(fā)安全的互相切換。
一級(jí)存儲(chǔ)格式
一級(jí)存儲(chǔ)格式中,只有一個(gè) KV 對(duì),key 和 value 的編碼:
- key: 某個(gè)起點(diǎn) id + 起點(diǎn) type + 邊 type
- value: 此起點(diǎn)的所有出邊(Edge)及其邊上屬性聚合作為 value,但不包括終點(diǎn)的屬性
二級(jí)存儲(chǔ)(點(diǎn)的出度大于閾值)
如果一個(gè)大 V 瘋狂漲粉,則存儲(chǔ)粉絲的 value 就會(huì)越來越大,解決這個(gè)問題的思路也很樸素:拆成多個(gè) KV 對(duì)。
但如何拆呢?ByteGraph 的方式就是把所有出度和終點(diǎn)拆成多個(gè) KV 對(duì),所有 KV 對(duì)形成一棵邏輯上的分布式 B-Tree,之所以說“邏輯上的”,是因?yàn)闃渲械墓?jié)點(diǎn)關(guān)系是靠 KV 中 key 來指向的,并非內(nèi)存指針;B-Tree 是分布式的,是指構(gòu)成這棵樹的各級(jí)節(jié)點(diǎn)是分布在集群多個(gè)實(shí)例上的,并不是單機(jī)索引關(guān)系。具體關(guān)系如下圖所示:
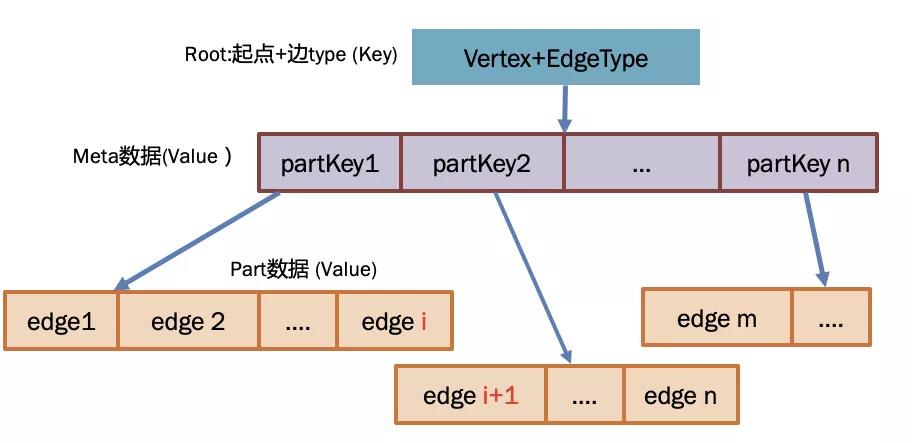
其中,整棵 B-Tree 由多組 KV 對(duì)組成,按照關(guān)系可以分為三種數(shù)據(jù):
- 根節(jié)點(diǎn):根節(jié)點(diǎn)本質(zhì)是一個(gè) KV 系統(tǒng)中的一個(gè) key,其編碼方式和一級(jí)存儲(chǔ)中的 key 相同
Meta 數(shù)據(jù):
- Meta 數(shù)據(jù)本質(zhì)是一個(gè) KV 中的 value,和根節(jié)點(diǎn)組成了 KV 對(duì);
- Meta 內(nèi)部存儲(chǔ)了多個(gè) PartKey,其中每個(gè) PartKey 都是一個(gè) KV 對(duì)中的 key,其對(duì)應(yīng)的 value 數(shù)據(jù)就是下面介紹的 Part 數(shù)據(jù)。
Part 數(shù)據(jù)
對(duì)于二級(jí)存儲(chǔ)格式,存在多個(gè) Part,每個(gè) Part 存儲(chǔ)部分出邊的屬性和終點(diǎn) ID。
每個(gè) Part 都是一個(gè) KV 對(duì)的 value,其對(duì)應(yīng)的 key 存儲(chǔ)在 Meta 中。
從上述描述可以看出,對(duì)于一個(gè)出度很多的點(diǎn)和其邊的數(shù)據(jù)(比如大 V 和其粉絲),在 ByteGraph 中,是存儲(chǔ)為多個(gè) KV 的,面對(duì)增刪查改的需求,都需要在 B-Tree 上做二分查找。相比于一條邊一個(gè) KV 對(duì)或者所有邊存儲(chǔ)成一個(gè) KV 對(duì)的方式,B-Tree 的組織方式能夠有效的在讀放大和寫放大之間做一些動(dòng)態(tài)調(diào)整。
但在實(shí)際業(yè)務(wù)場景下,粉絲會(huì)處于動(dòng)態(tài)變化之中:新誕生的大 V 會(huì)快速新增粉絲,有些大 V 會(huì)持續(xù)掉粉;因此,存儲(chǔ)方式會(huì)在一級(jí)存儲(chǔ)和二級(jí)存儲(chǔ)之間轉(zhuǎn)換,并且 B-Tree 會(huì)持續(xù)的分裂或者合并;這就會(huì)引發(fā)分布式的并發(fā)增刪查改以及分裂合并等復(fù)雜的問題,有機(jī)會(huì)可以再單獨(dú)分享下這個(gè)有趣的設(shè)計(jì)。
ByteGraph 和 KV store 的關(guān)系,類似文件系統(tǒng)和塊設(shè)備的關(guān)系,塊設(shè)備負(fù)責(zé)將存儲(chǔ)資源池化并提供 Low Level 的讀寫接口,文件系統(tǒng)在塊設(shè)備上把元數(shù)據(jù)和數(shù)據(jù)組織成各種樹的索引結(jié)構(gòu),并封裝豐富的 POSIX 接口,便于外部使用。
4、一些問題深入探討
第三節(jié)介紹了 ByteGraph 的內(nèi)在架構(gòu),現(xiàn)在我們更進(jìn)一步,來看看一個(gè)分布式存儲(chǔ)系統(tǒng),在面對(duì)字節(jié)跳動(dòng)萬億數(shù)據(jù)上億并發(fā)的業(yè)務(wù)場景下兩個(gè)問題的分析。
1)熱點(diǎn)數(shù)據(jù)讀寫解決
熱點(diǎn)數(shù)據(jù)在字節(jié)跳動(dòng)的線上業(yè)務(wù)中廣泛存在:熱點(diǎn)視頻、熱點(diǎn)文章、大 V 用戶、熱點(diǎn)廣告等等;熱點(diǎn)數(shù)據(jù)可能會(huì)出現(xiàn)瞬時(shí)出現(xiàn)大量讀寫。ByteGraph 在線上業(yè)務(wù)的實(shí)踐中,打磨出一整套應(yīng)對(duì)性方案。
2)熱點(diǎn)讀
熱點(diǎn)讀的場景隨處可見,比如線上實(shí)際場景:某個(gè)熱點(diǎn)視頻被頻繁刷新,查看點(diǎn)贊數(shù)量等。在這種場景下,意味著訪問有很強(qiáng)的數(shù)據(jù)局部性,緩存命中率會(huì)很高,因此,我們?cè)O(shè)計(jì)實(shí)現(xiàn)了多級(jí)的 Query Cache 機(jī)制以及熱點(diǎn)請(qǐng)求轉(zhuǎn)發(fā)機(jī)制;在 bgdb 查詢層緩存查詢結(jié)果, bgdb 單節(jié)點(diǎn)緩存命中讀性能 20w QPS 以上,而且多個(gè) bgdb 可以并發(fā)處理同一個(gè)熱點(diǎn)的讀請(qǐng)求,則系統(tǒng)整體應(yīng)對(duì)熱點(diǎn)度的“彈性”是非常充足的。
3)熱點(diǎn)寫
熱點(diǎn)讀和熱點(diǎn)寫通常是相伴而生的,熱點(diǎn)寫的例子也是隨處可見,比如:熱點(diǎn)新聞被瘋狂轉(zhuǎn)發(fā), 熱點(diǎn)視頻被瘋狂點(diǎn)贊等等。對(duì)于數(shù)據(jù)庫而言,熱點(diǎn)寫入導(dǎo)致的性能退化的背后原因通常有兩個(gè):行鎖沖突高或者磁盤寫入 IOPS 被打滿,我們分別來分析:
① 行鎖沖突高:目前 ByteGraph 是單行事務(wù)模型,只有內(nèi)存結(jié)構(gòu)鎖,這個(gè)鎖的并發(fā)量是每秒千萬級(jí),基本不會(huì)構(gòu)成寫入瓶頸。
② 磁盤 IOPS 被打滿:
IOPS(I/O Count Per Second)的概念:磁盤每秒的寫入請(qǐng)求數(shù)量是有上限的,不同型號(hào)的固態(tài)硬盤的 IOPS 各異,但都有一個(gè)上限,當(dāng)上游寫入流量超過這個(gè)閾值時(shí)候,請(qǐng)求就會(huì)排隊(duì),造成整個(gè)數(shù)據(jù)通路堵塞,延遲就會(huì)呈現(xiàn)指數(shù)上漲最終服務(wù)變成不可用。
Group Commit 解決方案:Group Commit 是數(shù)據(jù)庫中的一個(gè)成熟的技術(shù)方案,簡單來講,就是多個(gè)寫請(qǐng)求在 bgkv 內(nèi)存中匯聚起來,聚成一個(gè) Batch 寫入 KV store,則對(duì)外體現(xiàn)的寫入速率就是 BatchSize * IOPS。
對(duì)于某個(gè)獨(dú)立數(shù)據(jù)源來說,一般熱點(diǎn)寫的請(qǐng)求比熱點(diǎn)讀會(huì)少很多,一般不會(huì)超過 10K QPS,目前 ByteGraph 線上還沒有出現(xiàn)過熱點(diǎn)寫問題問題。
4)圖的索引
就像關(guān)系型數(shù)據(jù)庫一樣,圖數(shù)據(jù)庫也可以構(gòu)建索引。默認(rèn)情況下,對(duì)于同一個(gè)起點(diǎn),我們會(huì)采用邊上的屬性(時(shí)間戳)作為主鍵索引;但為了加速查詢,我們也支持其他元素(終點(diǎn)、其他屬性)來構(gòu)建二級(jí)的聚簇索引,這樣很多查找就從全部遍歷優(yōu)化成了二分查找,使得查詢速度大幅提升。
ByteGraph 默認(rèn)按照邊上的時(shí)間戳(ts)來排序存儲(chǔ),因此對(duì)于以下請(qǐng)求,查詢效率很高:
- 查詢最近的若干個(gè)點(diǎn)贊
- 查詢某個(gè)指定時(shí)間范圍窗口內(nèi)加的好友
方向的索引可能有些費(fèi)解,舉個(gè)例子說明下:給定兩個(gè)用戶來查詢是否存在粉絲關(guān)系,其中一個(gè)用戶是大 V,另一個(gè)是普通用戶,大 V 的粉絲可達(dá)千萬,但普通用戶的關(guān)注者一般不會(huì)很多;因此,如果用普通用戶作為起點(diǎn)大 V 作為終點(diǎn),查詢代價(jià)就會(huì)低很多。其實(shí),很多場景下,我們還需要用戶能夠根據(jù)任意一個(gè)屬性來構(gòu)建索引,這個(gè)也是我們正在支持的重要功能之一。
5、未來探索
過去的一年半時(shí)間里,ByteGraph 都是在有限的人力情況下,優(yōu)先滿足業(yè)務(wù)需求,在系統(tǒng)能力構(gòu)建方面還是有些薄弱的,有大量問題都需要在未來突破解決:
從圖存儲(chǔ)到圖數(shù)據(jù)庫:對(duì)于一個(gè)數(shù)據(jù)庫系統(tǒng),是否支持 ACID 的事務(wù),是一個(gè)核心問題,目前 ByteGraph 只解決了原子性和一致性,對(duì)于最復(fù)雜的隔離性還完全沒有觸碰,這是一個(gè)非常復(fù)雜的問題;另外,中國信通院發(fā)布了國內(nèi)圖數(shù)據(jù)庫功能白皮書,以此標(biāo)準(zhǔn),如果想做好一個(gè)功能完備的“數(shù)據(jù)庫”系統(tǒng),我們面對(duì)的還是星辰大海;
標(biāo)準(zhǔn)的圖查詢語言:目前,圖數(shù)據(jù)庫的查詢語言業(yè)界還未形成標(biāo)準(zhǔn)(GQL 即將在 2020 年發(fā)布),ByteGraph 選擇 Apache、AWS 、阿里云的 Gremlin 語言體系,但目前也只是支持了一個(gè)子集,更多的語法支持、更深入的查詢優(yōu)化還未開展;
Cloud Native 存儲(chǔ)架構(gòu)演進(jìn):現(xiàn)在 ByteGraph 還是構(gòu)建與 KV 存儲(chǔ)之上,獨(dú)占物理機(jī)全部資源;從資源彈性部署、運(yùn)維托管等角度是否有其他架構(gòu)演進(jìn)的探索可能,從查詢到事務(wù)再到磁盤存儲(chǔ)是否有深度垂直整合優(yōu)化的空間,也是一個(gè)沒有被回答的問題;
現(xiàn)在 ByteGraph 是在 OLTP 場景下承載了大量線上數(shù)據(jù),這些數(shù)據(jù)同時(shí)也會(huì)應(yīng)用到推薦、風(fēng)控等復(fù)雜分析和圖計(jì)算場景,如何把 TP 和輕量 AP 查詢?nèi)诤显谝黄穑邆洳糠?HTAP 能力,也是一個(gè)空間廣闊的藍(lán)海領(lǐng)域。
三、圖計(jì)算系統(tǒng)介紹與實(shí)踐
1、圖計(jì)算技術(shù)背景
1)圖計(jì)算簡介
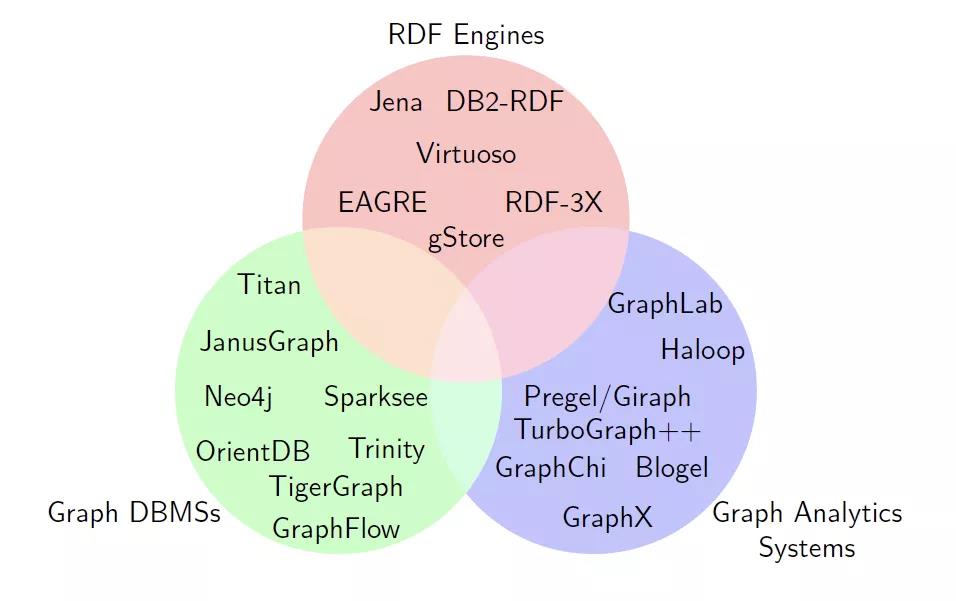
圖數(shù)據(jù)庫重點(diǎn)面對(duì) OLTP 場景,以事務(wù)為核心,強(qiáng)調(diào)增刪查改并重,并且一個(gè)查詢往往只是涉及到圖中的少量數(shù)據(jù);而圖計(jì)算與之不同,是解決大規(guī)模圖數(shù)據(jù)處理的方法,面對(duì) OLAP 場景,是對(duì)整個(gè)圖做分析計(jì)算,下圖(引用自 VLDB 2019 keynote 《Graph Processing: A Panaromic View and Some Open Problems》)描述了圖計(jì)算和圖數(shù)據(jù)庫的一些領(lǐng)域區(qū)分。
舉個(gè)圖計(jì)算的簡單例子,在我們比較熟悉的 Google 的搜索場景中,需要基于網(wǎng)頁鏈接關(guān)系計(jì)算每個(gè)網(wǎng)頁的 PageRank 值,用來對(duì)網(wǎng)頁進(jìn)行排序。網(wǎng)頁鏈接關(guān)系其實(shí)就是一張圖,而基于網(wǎng)頁鏈接關(guān)系的 PageRank 計(jì)算,其實(shí)就是在這張圖上運(yùn)行圖算法,也就是圖計(jì)算。
對(duì)于小規(guī)模的圖,我們可以用單機(jī)來進(jìn)行計(jì)算。但隨著數(shù)據(jù)量的增大,一般需要引入分布式的計(jì)算系統(tǒng)來解決,并且要能夠高效地運(yùn)行各種類型的圖算法。
2)批處理系統(tǒng)
大規(guī)模數(shù)據(jù)處理我們直接想到的就是使用 MapReduce / Spark 等批處理系統(tǒng),字節(jié)跳動(dòng)在初期也有不少業(yè)務(wù)使用 MapReduce / Spark 來實(shí)現(xiàn)圖算法。得益于批處理系統(tǒng)的廣泛使用,業(yè)務(wù)同學(xué)能夠快速實(shí)現(xiàn)并上線自己的算法邏輯。
批處理系統(tǒng)本身是為了處理行式數(shù)據(jù)而設(shè)計(jì)的,其能夠輕易地將工作負(fù)載分散在不同的機(jī)器上,并行地處理大量的數(shù)據(jù)。不過圖數(shù)據(jù)比較特殊,天然具有關(guān)聯(lián)性,無法像行式數(shù)據(jù)一樣直接切割。如果用批處理系統(tǒng)來運(yùn)行圖算法,就可能會(huì)引入大量的 Shuffle 來實(shí)現(xiàn)關(guān)系的連接,而 Shuffle 是一項(xiàng)很重的操作,不僅會(huì)導(dǎo)致任務(wù)運(yùn)行時(shí)間長,并且會(huì)浪費(fèi)很多計(jì)算資源。
3)圖計(jì)算系統(tǒng)
圖計(jì)算系統(tǒng)是針對(duì)圖算法的特點(diǎn)而衍生出的專用計(jì)算設(shè)施,能夠高效地運(yùn)行圖算法。因此隨著業(yè)務(wù)的發(fā)展,我們迫切需要引入圖計(jì)算系統(tǒng)來解決圖數(shù)據(jù)處理的問題。圖計(jì)算也是比較成熟的領(lǐng)域,在學(xué)術(shù)界和工業(yè)界已有大量的系統(tǒng),這些系統(tǒng)在不同場景,也各有優(yōu)劣勢。
由于面向不同的數(shù)據(jù)特征、不同的算法特性等,圖計(jì)算系統(tǒng)在平臺(tái)架構(gòu)、計(jì)算模型、圖劃分、執(zhí)行模型、通信模型等方面各有取舍。下面,我們從不同角度對(duì)圖計(jì)算的一些現(xiàn)有技術(shù)做些分類分析。
① 分布架構(gòu)
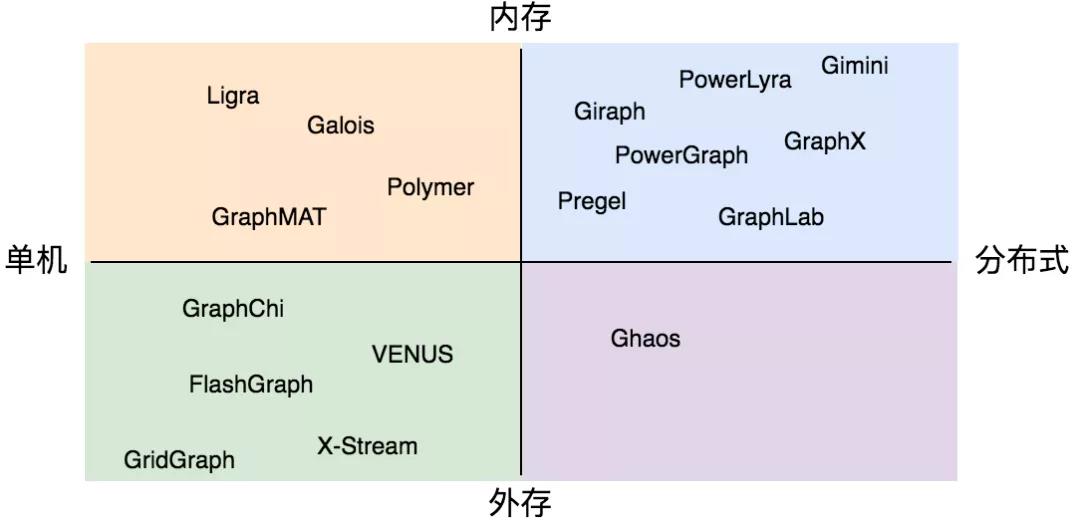
按照分布架構(gòu),圖計(jì)算可以分為單機(jī)或分布式、全內(nèi)存或使用外存幾種,常見的各種圖計(jì)算系統(tǒng)如下圖所示。單機(jī)架構(gòu)的優(yōu)勢在于無需考慮分布式的通信開銷,但通常難以快速處理大規(guī)模的圖數(shù)據(jù);分布式則通過通信或分布式共享內(nèi)存將可處理的數(shù)據(jù)規(guī)模擴(kuò)大,但通常也會(huì)引入巨大的額外開銷。
② 計(jì)算模型
按照計(jì)算對(duì)象,圖數(shù)據(jù)計(jì)算模型可以分為節(jié)點(diǎn)中心計(jì)算模型、邊中心計(jì)算模型、子圖中心計(jì)算模型等。
大部分圖計(jì)算系統(tǒng)都采用了節(jié)點(diǎn)中心計(jì)算模型(這里的節(jié)點(diǎn)指圖上的一個(gè)點(diǎn)),該模型來自 Google 的 Pregel,核心思想是用戶編程過程中,以圖中一個(gè)節(jié)點(diǎn)及其鄰邊作為輸入來進(jìn)行運(yùn)算,具有編程簡單的優(yōu)勢。典型的節(jié)點(diǎn)中心計(jì)算模型包括 Pregel 提出的 Pregel API 、 PowerGraph 提出的 GAS API 以及其他一些 API。
Pregel 創(chuàng)新性地提出了 "think like a vertex" 的思想,用戶只需編寫處理一個(gè)節(jié)點(diǎn)的邏輯,即可被拓展到整張圖進(jìn)行迭代運(yùn)算,使用 Pregel 描述的 PageRank 如下圖所示:
- def pagerank(vertex_id, msgs):
- // 計(jì)算收到消息的值之和
- msg_sum = sum(msgs)
- // 更新當(dāng)前PR值
- pr = 0.15 + 0.85 * msg_sum
- // 用新計(jì)算的PR值發(fā)送消息
- for nr in out_neighbor(vertex_id):
- msg = pr / out_degree(vertex_id)
- send_msg(nr, msg)
- // 檢查是否收斂
- if converged(pr):
- vote_halt(vertex_id)
GAS API 則是 PowerGraph 為了解決冪律圖(一小部分節(jié)點(diǎn)的度數(shù)非常高)的問題,將對(duì)一個(gè)節(jié)點(diǎn)的處理邏輯,拆分為了 Gather、Apply、Scatter 三階段。在計(jì)算滿足交換律和結(jié)合律的情況下,通過使用 GAS 模型,通信成本從 |E| 降低到了 |V|,使用 GAS 描述的 PageRank 如下圖所示:
- def gather(msg_a, msg_b):
- // 匯聚消息
- return msg_a + msg_b
- def apply(vertex_id, msg_sum):
- // 更新PR值
- pr = 0.15 + 0.85 * msg_sum
- // 判斷是否收斂
- if converged(pr):
- vote_halt(vertex_id)
- def scatter(vertex_id, nr):
- // 發(fā)送消息
- return pr / out_degree(vertex_id)
③ 圖劃分
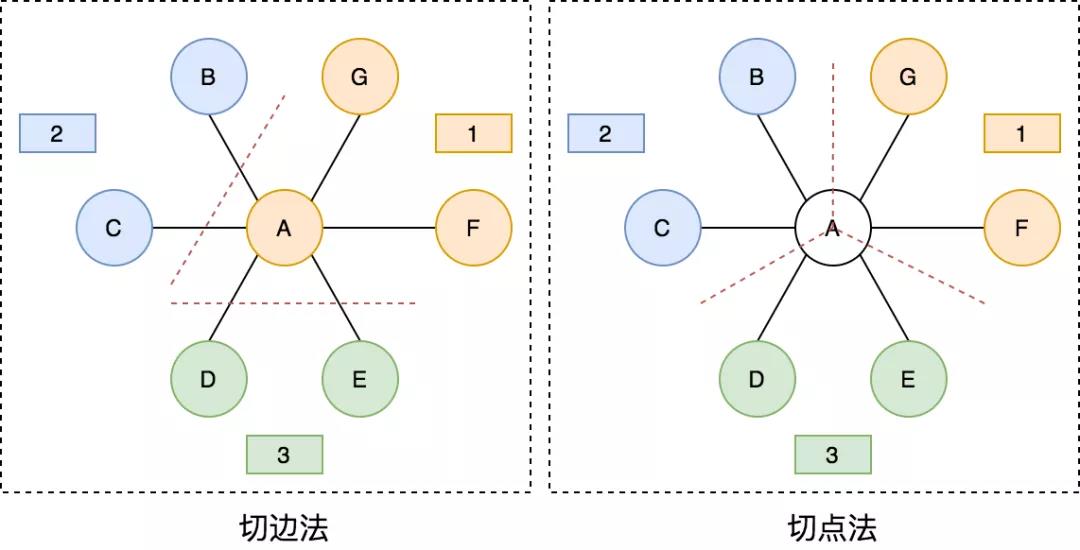
對(duì)于單機(jī)無法處理的超級(jí)大圖,則需要將圖數(shù)據(jù)劃分成幾個(gè)子圖,采用分布式計(jì)算方式,因此,會(huì)涉及到圖劃分的問題,即如何將一整張圖切割成子圖,并分配給不同的機(jī)器進(jìn)行分布式地計(jì)算。常見的圖劃分方式有切邊法(Edge-Cut)和切點(diǎn)法(Vertex-Cut),其示意圖如下所示:
切邊法顧名思義,會(huì)從一條邊中間切開,兩邊的節(jié)點(diǎn)會(huì)分布在不同的圖分區(qū),每個(gè)節(jié)點(diǎn)全局只會(huì)出現(xiàn)一次,但切邊法可能會(huì)導(dǎo)致一條邊在全局出現(xiàn)兩次。如上左圖所示,節(jié)點(diǎn) A 與節(jié)點(diǎn) B 之間有一條邊,切邊法會(huì)在 A 和 B 中間切開,A 屬于圖分區(qū) 1,B 屬于圖分區(qū) 2。
切點(diǎn)法則是將一個(gè)節(jié)點(diǎn)切開,該節(jié)點(diǎn)上不同的邊會(huì)分布在不同的圖分區(qū),每條邊全局只會(huì)出現(xiàn)一次,但切點(diǎn)法會(huì)導(dǎo)致一個(gè)節(jié)點(diǎn)在全局出現(xiàn)多次。如上圖右圖所示,節(jié)點(diǎn) A 被切分為 3 份,其中邊 AB 屬于分區(qū) 2,邊 AD 屬于圖分區(qū) 3。
圖劃分還會(huì)涉及到分圖策略,比如切點(diǎn)法會(huì)有各種策略的切法:按邊隨機(jī)哈希、Edge1D、Edge2D 等等。有些策略是可全局并行執(zhí)行分圖的,速度快,但負(fù)載均衡和計(jì)算時(shí)的通信效率不理想;有些是需要串行執(zhí)行的但負(fù)載均衡、通信效率會(huì)更好,各種策略需要根據(jù)不同的業(yè)務(wù)場景進(jìn)行選擇。
④ 執(zhí)行模型
執(zhí)行模型解決的是不同的節(jié)點(diǎn)在迭代過程中,如何協(xié)調(diào)迭代進(jìn)度的問題。圖計(jì)算通常是全圖多輪迭代的計(jì)算,比如 PageRank 算法,需要持續(xù)迭代直至全圖所有節(jié)點(diǎn)收斂才會(huì)結(jié)束。
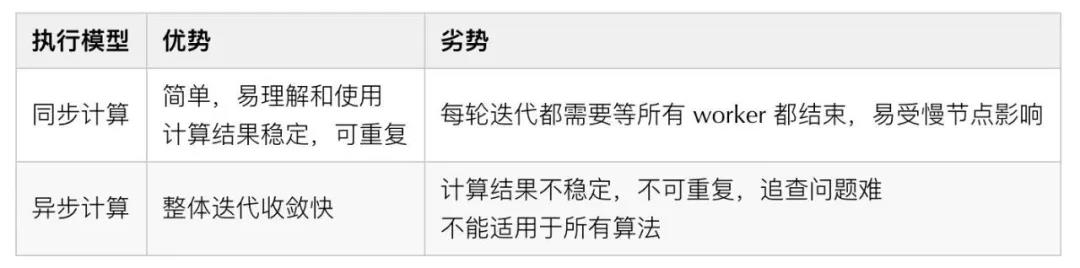
在圖劃分完成后,每個(gè)子圖會(huì)被分配到對(duì)應(yīng)的機(jī)器進(jìn)行處理,由于不同機(jī)器間運(yùn)算環(huán)境、計(jì)算負(fù)載的不同,不同機(jī)器的運(yùn)算速度是不同的,導(dǎo)致圖上不同節(jié)點(diǎn)間的迭代速度也是不同的。為了應(yīng)對(duì)不同節(jié)點(diǎn)間迭代速度的不同,有同步計(jì)算、異步計(jì)算、以及半同步計(jì)算三種執(zhí)行模型。
- 同步計(jì)算是全圖所有節(jié)點(diǎn)完成一輪迭代之后,才開啟下一輪迭代,因?yàn)橥ǔC總€(gè)節(jié)點(diǎn)都會(huì)依賴其他節(jié)點(diǎn)在上一輪迭代產(chǎn)生的結(jié)果,因此同步計(jì)算的結(jié)果是正確的。
- 異步計(jì)算則是每個(gè)節(jié)點(diǎn)不等待其他節(jié)點(diǎn)的迭代進(jìn)度,在自己計(jì)算完一輪迭代后直接開啟下一輪迭代,所以就會(huì)導(dǎo)致很多節(jié)點(diǎn)還沒有完全拿到上一輪的結(jié)果就開始了下一輪計(jì)算。
- 半同步計(jì)算是兩者的綜合,其思想是允許一定的不同步,但當(dāng)計(jì)算最快的節(jié)點(diǎn)與計(jì)算最慢的節(jié)點(diǎn)相差一定迭代輪數(shù)時(shí),最快的節(jié)點(diǎn)會(huì)進(jìn)行等待。同步計(jì)算和異步計(jì)算的示意圖如下圖:

同步計(jì)算和異步計(jì)算各有優(yōu)劣,其對(duì)比如下表所示,半同步是兩者折中。多數(shù)圖計(jì)算系統(tǒng)都采用了同步計(jì)算模型,雖然計(jì)算效率比異步計(jì)算弱一些,但它具有易于理解、計(jì)算穩(wěn)定、結(jié)果準(zhǔn)確、可解釋性強(qiáng)等多個(gè)重要的優(yōu)點(diǎn)。
⑤ 通信模型
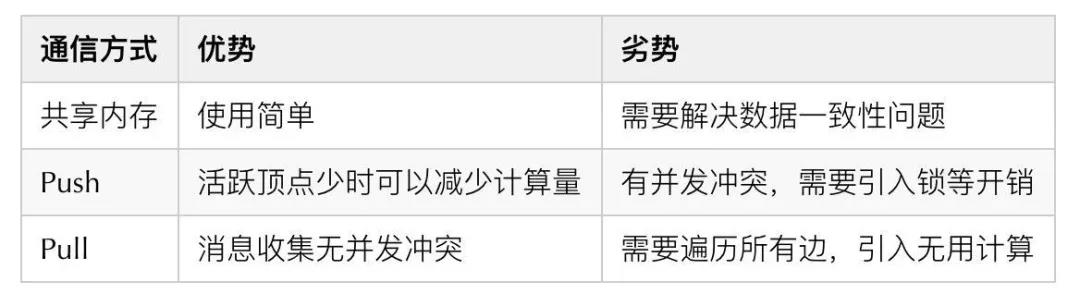
為了實(shí)現(xiàn)拓展性,圖計(jì)算采用了不同的通信模型,大致可分為分布式共享內(nèi)存、Push 以及 Pull。分布式共享內(nèi)存將數(shù)據(jù)存儲(chǔ)在共享內(nèi)存中,通過直接操作共享內(nèi)存完成信息交互;Push 模型是沿著出邊方向主動(dòng)推送消息;Pull 則是沿著入邊方向主動(dòng)收消息。三者優(yōu)劣對(duì)比如下表格所示:
2、技術(shù)選型
由于字節(jié)跳動(dòng)要處理的是世界級(jí)的超大規(guī)模圖,同時(shí)還對(duì)計(jì)算任務(wù)運(yùn)行時(shí)長有要求,因此主要考慮高性能、可拓展性強(qiáng)的圖計(jì)算系統(tǒng)。工業(yè)界使用比較多的系統(tǒng)主要有以下幾類:
1)Pregel & Giraph
Google 提出了 Pregel 來解決圖算法在 MapReduce 上運(yùn)行低效的問題,但沒有開源。Facebook 根據(jù) Pregel 的思路發(fā)展了開源系統(tǒng) Giraph,但 Giraph 有兩個(gè)問題:一是 Giraph 的社區(qū)不是很活躍;二是現(xiàn)實(shí)生活中的圖都是符合冪律分布的圖,即有一小部分點(diǎn)的邊數(shù)非常多,這些點(diǎn)在 Pregel 的計(jì)算模式下很容易拖慢整個(gè)計(jì)算任務(wù)。
2)GraphX
GraphX 是基于 Spark 構(gòu)建的圖計(jì)算系統(tǒng),融合了很多 PowerGraph 的思想,并對(duì) Spark 在運(yùn)行圖算法過程中的多余 Shuffle 進(jìn)行了優(yōu)化。GraphX 對(duì)比原生 Spark 在性能方面有很大優(yōu)勢,但 GraphX 非常費(fèi)內(nèi)存,Shuffle 效率也不是很高,導(dǎo)致運(yùn)行時(shí)間也比較長。
3)Gemini
Gemini 是 16 年發(fā)表再在 OSDI 的一篇圖計(jì)算系統(tǒng)論文,結(jié)合了多種圖計(jì)算系統(tǒng)的優(yōu)勢,并且有開源實(shí)現(xiàn),作為最快的圖計(jì)算引擎之一,得到了業(yè)界的普遍認(rèn)可。
正如《Scalability! But at what COST? 》一文指出,多數(shù)的圖計(jì)算系統(tǒng)為了拓展性,忽視了單機(jī)的性能,加之分布式帶來的巨大通信開銷,導(dǎo)致多機(jī)環(huán)境下的計(jì)算性能有時(shí)甚至反而不如單機(jī)環(huán)境。針對(duì)這些問題,Gemini 的做了針對(duì)性優(yōu)化設(shè)計(jì),簡單總結(jié)為:
- 圖存儲(chǔ)格式優(yōu)化內(nèi)存開銷:采用 CSC 和 CSR 的方式存儲(chǔ)圖,并對(duì) CSC/CSR 進(jìn)一步建立索引降低內(nèi)存占用;
- Hierarchical Chunk-Based Partitioning:通過在 Node、Numa、Socket 多個(gè)維度做區(qū)域感知的圖切分,減少通信開銷;
- 自適應(yīng)的 Push / Pull 計(jì)算:采用了雙模式通信策略,能根據(jù)當(dāng)前活躍節(jié)點(diǎn)的數(shù)量動(dòng)態(tài)地切換到稠密或稀疏模式。
- 兼顧單機(jī)性能和擴(kuò)展性,使得 Gemini 處于圖計(jì)算性能最前沿,同時(shí),Gemini 團(tuán)隊(duì)也成立了商業(yè)公司專注圖數(shù)據(jù)的處理。
3、基于開源的實(shí)踐
Tencent Plato 是基于 Gemini 思想的開源圖計(jì)算系統(tǒng),采用了 Gemini 的核心設(shè)計(jì)思路,但相比 Gemini 的開源版本有更加完善的工程實(shí)現(xiàn),我們基于此,做了大量重構(gòu)和二次開發(fā),將其應(yīng)用到生成環(huán)境中,這里分享下我們的實(shí)踐。
1)更大數(shù)據(jù)規(guī)模的探索
開源實(shí)現(xiàn)中有個(gè)非常關(guān)鍵的假設(shè):一張圖中的點(diǎn)的數(shù)量不能超過 40 億個(gè);但字節(jié)跳動(dòng)部分業(yè)務(wù)場景的數(shù)據(jù)規(guī)模遠(yuǎn)超出了這個(gè)數(shù)額。為了支持千億萬億點(diǎn)的規(guī)模,我們將產(chǎn)生內(nèi)存瓶頸的單機(jī)處理模塊,重構(gòu)為分布式實(shí)現(xiàn)。
① 點(diǎn) ID 的編碼
Gemini 的一個(gè)重要?jiǎng)?chuàng)新就是提出了基于 Chunk 的圖分區(qū)方法。這種圖分區(qū)方法需要將點(diǎn) id 從 0 開始連續(xù)遞增編碼,但輸入的圖數(shù)據(jù)中,點(diǎn) id 是隨機(jī)生成的,因此需要對(duì)點(diǎn) id 進(jìn)行一次映射,保證其連續(xù)遞增。具體實(shí)現(xiàn)方法是,在計(jì)算任務(wù)開始之前將原始的業(yè)務(wù) id 轉(zhuǎn)換為從零開始的遞增 id,計(jì)算結(jié)束后再將 id 映射回去,如下圖所示:
在開源實(shí)現(xiàn)中,是假設(shè)圖中點(diǎn)的數(shù)量不可超過 40 億,40 億的 id 數(shù)據(jù)是可以存儲(chǔ)在單機(jī)內(nèi)存中,因此采用比較簡單的實(shí)現(xiàn)方式:分布式計(jì)算集群中的每臺(tái)機(jī)器冗余存儲(chǔ)了所有點(diǎn) id 的映射關(guān)系。然而,當(dāng)點(diǎn)的數(shù)量從 40 億到千億級(jí)別,每臺(tái)機(jī)器僅 id 映射表就需要數(shù)百 GB 的內(nèi)存,單機(jī)存儲(chǔ)方案就變得不再可行,因此需要將映射表分成 shard 分布式地存儲(chǔ),具體實(shí)現(xiàn)方式如下:
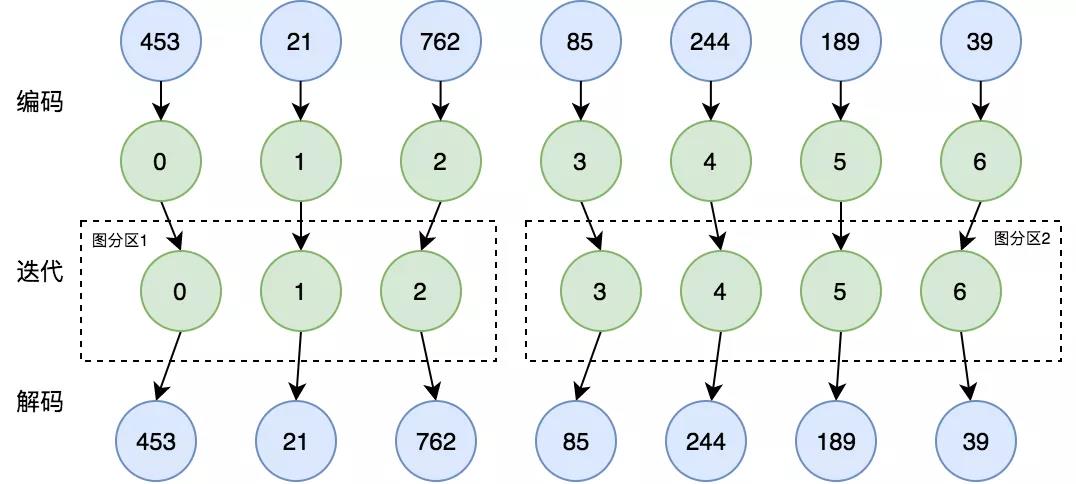
我們通過哈希將原始業(yè)務(wù)點(diǎn) id 打散在不同的機(jī)器,并行地分配全局從 0 開始連續(xù)遞增的 id。生成 id 映射關(guān)系后,每臺(tái)機(jī)器都會(huì)存有 id 映射表的一部分。隨后再將邊數(shù)據(jù)分別按起點(diǎn)和終點(diǎn)哈希,發(fā)送到對(duì)應(yīng)的機(jī)器進(jìn)行編碼,最終得到的數(shù)據(jù)即為可用于計(jì)算的數(shù)據(jù)。當(dāng)計(jì)算運(yùn)行結(jié)束后,需要數(shù)據(jù)需要映射回業(yè)務(wù) id,其過程和上述也是類似的。
上面描述的僅僅是圖編碼部分,40 億點(diǎn)的值域限制還廣泛存在于構(gòu)圖和實(shí)際計(jì)算過程中,我們都對(duì)此做了重構(gòu)。另外在我們的規(guī)模下,也碰到了一些任務(wù)負(fù)載不均,不夠穩(wěn)定,計(jì)算效率不高等問題,我們對(duì)此都做了部分優(yōu)化和重構(gòu)。
通過對(duì)開源實(shí)現(xiàn)的改造,字節(jié)跳動(dòng)的圖計(jì)算系統(tǒng)已經(jīng)在線上支撐了多條產(chǎn)品線的計(jì)算任務(wù),最大規(guī)模達(dá)到數(shù)萬億邊、數(shù)千億點(diǎn)的世界級(jí)超大圖,這是業(yè)內(nèi)罕見的。同時(shí),面對(duì)不斷增長的業(yè)務(wù),并且我們還在持續(xù)擴(kuò)大系統(tǒng)的邊界,來應(yīng)對(duì)更大規(guī)模的挑戰(zhàn)。
2)自定義算法實(shí)現(xiàn)
在常見圖計(jì)算算法之外,字節(jié)跳動(dòng)多元的業(yè)務(wù)中,有大量的其他圖算法需求以及現(xiàn)有算法的改造需求,比如需要實(shí)現(xiàn)更適合二分圖的 LPA 算法,需要改造 PageRank 算法使之更容易收斂。
由于當(dāng)前圖計(jì)算系統(tǒng)暴露的 API 還沒有非常好的封裝,使得編寫算法的用戶會(huì)直接感知到底層的內(nèi)部機(jī)制,比如不同的通信模式、圖表示方式等,這固然方便了做圖計(jì)算算法實(shí)現(xiàn)的調(diào)優(yōu),但也導(dǎo)致業(yè)務(wù)同學(xué)有一定成本;另外,因?yàn)樯婕俺笠?guī)模數(shù)據(jù)的高性能計(jì)算,一個(gè)細(xì)節(jié)(比如 hotpath 上的一個(gè)虛函數(shù)調(diào)用,一次線程同步)可能就對(duì)性能有至關(guān)重要的影響,需要業(yè)務(wù)同學(xué)對(duì)計(jì)算機(jī)體系結(jié)構(gòu)有一定了解。基于上述兩個(gè)原因,目前算法是圖計(jì)算引擎同學(xué)和圖計(jì)算用戶一起開發(fā),但長期來看,我們會(huì)封裝常用計(jì)算算子并暴露 Python Binding ,或者引入 DSL 來降低業(yè)務(wù)的學(xué)習(xí)成本。
4、未來展望
面對(duì)字節(jié)跳動(dòng)的超大規(guī)模圖處理場景,我們?cè)诎肽陜?nèi)快速開啟了圖計(jì)算方向,支持了搜索、風(fēng)控等多個(gè)業(yè)務(wù)的大規(guī)模圖計(jì)算需求,取得了不錯(cuò)的進(jìn)展,但還有眾多需要我們探索的問題:
1)從全內(nèi)存計(jì)算到混合存儲(chǔ)計(jì)算:為了支持更大規(guī)模的數(shù)據(jù)量,提供更加低成本的計(jì)算能力,我們將探索新型存儲(chǔ)硬件,包括 AEP / NVMe 等內(nèi)存或外存設(shè)備,擴(kuò)大系統(tǒng)能力;
2)動(dòng)態(tài)圖計(jì)算:目前的系統(tǒng)只支持靜態(tài)圖計(jì)算,即對(duì)完整圖的全量數(shù)據(jù)進(jìn)行計(jì)算。實(shí)際業(yè)務(wù)中的圖每時(shí)每刻都是在變化的,因此使用現(xiàn)有系統(tǒng)必須在每次計(jì)算都提供整張圖。而動(dòng)態(tài)圖計(jì)算能夠比較好地處理增量的數(shù)據(jù),無需對(duì)已經(jīng)處理過的數(shù)據(jù)進(jìn)行重復(fù)計(jì)算,因此我們將在一些場景探索動(dòng)態(tài)圖計(jì)算;
3)異構(gòu)計(jì)算:圖計(jì)算系統(tǒng)屬于計(jì)算密集型系統(tǒng),在部分場景對(duì)計(jì)算性能有極高的要求。因此我們會(huì)嘗試異構(gòu)計(jì)算,包括使用 GPU / FPGA 等硬件對(duì)計(jì)算進(jìn)行加速,以追求卓越的計(jì)算性能;
4)圖計(jì)算語言:業(yè)務(wù)直接接觸底層計(jì)算引擎有很多弊端,比如業(yè)務(wù)邏輯與計(jì)算引擎強(qiáng)耦合,無法更靈活地對(duì)不同算法進(jìn)行性能優(yōu)化。而通過圖計(jì)算語言對(duì)算法進(jìn)行描述,再對(duì)其編譯生成計(jì)算引擎的執(zhí)行代碼,可以將業(yè)務(wù)邏輯與計(jì)算引擎解耦,能更好地對(duì)不同算法進(jìn)行自動(dòng)地調(diào)優(yōu),將性能發(fā)揮到極致。
四、總結(jié)
隨著字節(jié)跳動(dòng)業(yè)務(wù)量級(jí)的飛速增長和業(yè)務(wù)需求的不斷豐富,我們?cè)诙虝r(shí)間內(nèi)構(gòu)建了圖存儲(chǔ)系統(tǒng)和圖計(jì)算系統(tǒng),在實(shí)際生產(chǎn)系統(tǒng)中解決了大量的問題,但同時(shí)仍面臨著巨大的技術(shù)挑戰(zhàn),我們將持續(xù)演進(jìn),打造業(yè)界頂尖的一棧式圖解決方案。未來已來,空間廣闊,希望更多有興趣的同學(xué)加入進(jìn)來,用有趣的分布式技術(shù)來影響幾億人的互聯(lián)網(wǎng)生活。