













阻塞隊列—DelayedWorkQueue源碼分析

前言
線程池運行時,會不斷從任務隊列中獲取任務,然后執行任務。如果我們想實現延時或者定時執行任務,重要一點就是任務隊列會根據任務延時時間的不同進行排序,延時時間越短地就排在隊列的前面,先被獲取執行。
隊列是先進先出的數據結構,就是先進入隊列的數據,先被獲取。但是有一種特殊的隊列叫做優先級隊列,它會對插入的數據進行優先級排序,保證優先級越高的數據首先被獲取,與數據的插入順序無關。
實現優先級隊列高效常用的一種方式就是使用堆。關于堆的實現可以查看《堆和二叉堆的實現和特性》
ScheduledThreadPoolExecutor線程池
ScheduledThreadPoolExecutor繼承自ThreadPoolExecutor,所以其內部的數據結構和ThreadPoolExecutor基本一樣,并在其基礎上增加了按時間調度執行任務的功能,分為延遲執行任務和周期性執行任務。
ScheduledThreadPoolExecutor的構造函數只能傳3個參數corePoolSize、ThreadFactory、RejectedExecutionHandler,默認maximumPoolSize為Integer.MAX_VALUE。
工作隊列是高度定制化的延遲阻塞隊列DelayedWorkQueue,其實現原理和DelayQueue基本一樣,核心數據結構是二叉最小堆的優先隊列,隊列滿時會自動擴容,所以offer操作永遠不會阻塞,maximumPoolSize也就用不上了,所以線程池中永遠會保持至多有corePoolSize個工作線程正在運行。
- public ScheduledThreadPoolExecutor(int corePoolSize,
- ThreadFactory threadFactory,
- RejectedExecutionHandler handler) {
- super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
- new DelayedWorkQueue(), threadFactory, handler);
- }
DelayedWorkQueue延遲阻塞隊列
DelayedWorkQueue 也是一種設計為定時任務的延遲隊列,它的實現和DelayQueue一樣,不過是將優先級隊列和DelayQueue的實現過程遷移到本身方法體中,從而可以在該過程當中靈活的加入定時任務特有的方法調用。
工作原理
DelayedWorkQueue的實現原理中規中矩,內部維護了一個以RunnableScheduledFuture類型數組實現的最小二叉堆,初始容量是16,使用ReentrantLock和Condition實現生產者和消費者模式。
源碼分析
定義
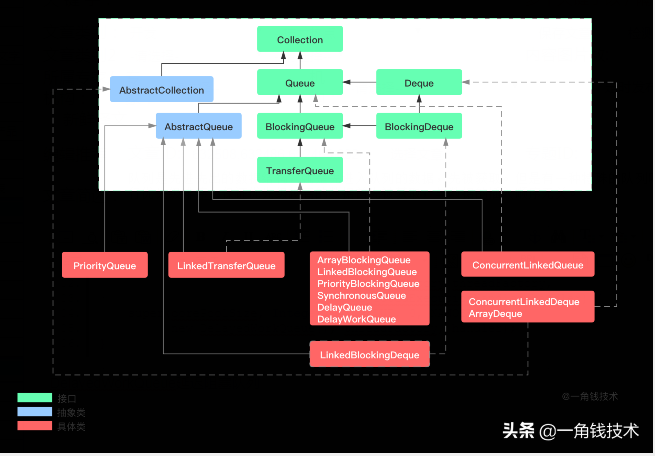
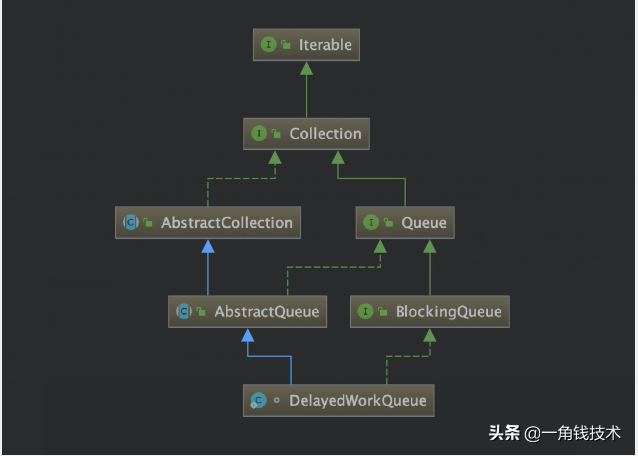
DelayedWorkQueue 的類繼承關系如下:
其包含的方法定義如下:
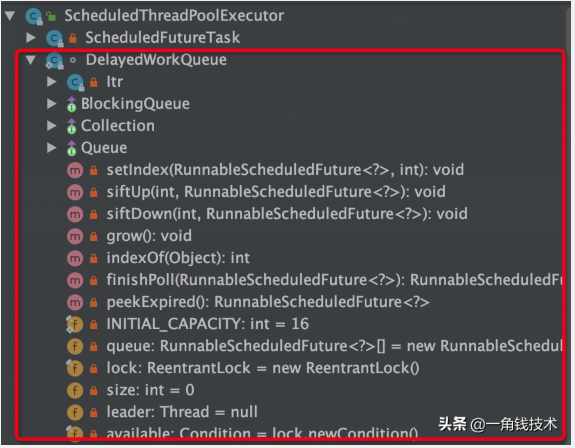
成員屬性
- // 初始時,數組長度大小。
- private static final int INITIAL_CAPACITY = 16;
- // 使用數組來儲存隊列中的元素。
- private RunnableScheduledFuture<?>[] queue = new RunnableScheduledFuture<?>[INITIAL_CAPACITY];
- // 使用lock來保證多線程并發安全問題。
- private final ReentrantLock lock = new ReentrantLock();
- // 隊列中儲存元素的大小
- private int size = 0;
- //特指隊列頭任務所在線程
- private Thread leader = null;
- // 當隊列頭的任務延時時間到了,或者有新的任務變成隊列頭時,用來喚醒等待線程
- private final Condition available = lock.newCondition();
DelayedWorkQueue是用數組來儲存隊列中的元素,核心數據結構是二叉最小堆的優先隊列,隊列滿時會自動擴容。
構造函數
DelayedWorkQueue 是 ScheduledThreadPoolExecutor 的靜態類部類,默認只有一個無參構造方法。
- static class DelayedWorkQueue extends AbstractQueue<Runnable>
- implements BlockingQueue<Runnable> {
- // ...
- }
入隊方法
DelayedWorkQueue 提供了 put/add/offer(帶時間) 三個插入元素方法。我們發現與普通阻塞隊列相比,這三個添加方法都是調用offer方法。那是因為它沒有隊列已滿的條件,也就是說可以不斷地向DelayedWorkQueue添加元素,當元素個數超過數組長度時,會進行數組擴容。
- public void put(Runnable e) {
- offer(e);
- }
- public boolean add(Runnable e) {
- return offer(e);
- }
- public boolean offer(Runnable e, long timeout, TimeUnit unit) {
- return offer(e);
- }
offer添加元素
ScheduledThreadPoolExecutor提交任務時調用的是DelayedWorkQueue.add,而add、put等一些對外提供的添加元素的方法都調用了offer。
- public boolean offer(Runnable x) {
- if (x == null)
- throw new NullPointerException();
- RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>)x;
- // 使用lock保證并發操作安全
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- int i = size;
- // 如果要超過數組長度,就要進行數組擴容
- if (i >= queue.length)
- // 數組擴容
- grow();
- // 將隊列中元素個數加一
- size = i + 1;
- // 如果是第一個元素,那么就不需要排序,直接賦值就行了
- if (i == 0) {
- queue[0] = e;
- setIndex(e, 0);
- } else {
- // 調用siftUp方法,使插入的元素變得有序。
- siftUp(i, e);
- }
- // 表示新插入的元素是隊列頭,更換了隊列頭,
- // 那么就要喚醒正在等待獲取任務的線程。
- if (queue[0] == e) {
- leader = null;
- // 喚醒正在等待等待獲取任務的線程
- available.signal();
- }
- } finally {
- lock.unlock();
- }
- return true;
- }
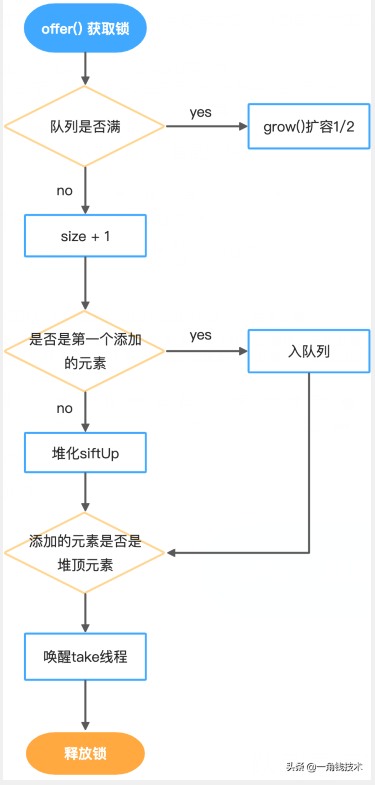
其基本流程如下:
- 其作為生產者的入口,首先獲取鎖。
- 判斷隊列是否要滿了(size >= queue.length),滿了就擴容grow()。
- 隊列未滿,size+1。
- 判斷添加的元素是否是第一個,是則不需要堆化。
- 添加的元素不是第一個,則需要堆化siftUp。
- 如果堆頂元素剛好是此時被添加的元素,則喚醒take線程消費。
- 最終釋放鎖。
offer基本流程圖如下:
擴容grow()
可以看到,當隊列滿時,不會阻塞等待,而是繼續擴容。新容量newCapacity在舊容量oldCapacity的基礎上擴容50%(oldCapacity >> 1相當于oldCapacity /2)。最后Arrays.copyOf,先根據newCapacity創建一個新的空數組,然后將舊數組的數據復制到新數組中。
- private void grow() {
- int oldCapacity = queue.length;
- // 每次擴容增加原來數組的一半數量。
- // grow 50%
- int newCapacity = oldCapacity + (oldCapacity >> 1);
- if (newCapacity < 0) // overflow
- newCapacity = Integer.MAX_VALUE;
- // 使用Arrays.copyOf來復制一個新數組
- queue = Arrays.copyOf(queue, newCapacity);
- }
向上堆化siftUp
新添加的元素先會加到堆底,然后一步步和上面的父親節點比較,若小于父親節點則和父親節點互換位置,循環比較直至大于父親節點才結束循環。通過循環,來查找元素key應該插入在堆二叉樹那個節點位置,并交互父節點的位置。
向上堆化siftUp的詳細過程可以查看《堆和二叉堆的實現和特性》
- private void siftUp(int k, RunnableScheduledFuture<?> key) {
- // 當k==0時,就到了堆二叉樹的根節點了,跳出循環
- while (k > 0) {
- // 父節點位置坐標, 相當于(k - 1) / 2
- int parent = (k - 1) >>> 1;
- // 獲取父節點位置元素
- RunnableScheduledFuture<?> e = queue[parent];
- // 如果key元素大于父節點位置元素,滿足條件,那么跳出循環
- // 因為是從小到大排序的。
- if (key.compareTo(e) >= 0)
- break;
- // 否則就將父節點元素存放到k位置
- queue[k] = e;
- // 這個只有當元素是ScheduledFutureTask對象實例才有用,用來快速取消任務。
- setIndex(e, k);
- // 重新賦值k,尋找元素key應該插入到堆二叉樹的那個節點
- k = parent;
- }
- // 循環結束,k就是元素key應該插入的節點位置
- queue[k] = key;
- setIndex(key, k);
- }
出隊方法
DelayedWorkQueue 提供了以下幾個出隊方法
- take(),等待獲取隊列頭元素
- poll() ,立即獲取隊列頭元素
- poll(long timeout, TimeUnit unit) ,超時等待獲取隊列頭元素
take消費元素
Worker工作線程啟動后就會循環消費工作隊列中的元素,因為ScheduledThreadPoolExecutor的keepAliveTime=0,所以消費任務其只調用了DelayedWorkQueue.take。take基本流程如下:
- 首先獲取可中斷鎖,判斷堆頂元素是否是空,空的則阻塞等待available.await()。
- 堆頂元素不為空,則獲取其延遲執行時間delay,delay <= 0說明到了執行時間,出隊列finishPoll。
- delay > 0還沒到執行時間,判斷leader線程是否為空,不為空則說明有其他take線程也在等待,當前take將無限期阻塞等待。
- leader線程為空,當前take線程設置為leader,并阻塞等待delay時長。
- 當前leader線程等待delay時長自動喚醒或者被其他take線程喚醒,則最終將leader設置為null。
- 再循環一次判斷delay <= 0出隊列。
- 跳出循環后判斷leader為空并且堆頂元素不為空,則喚醒其他take線程,最后是否鎖。
- public RunnableScheduledFuture<?> take() throws InterruptedException {
- final ReentrantLock lock = this.lock;
- lock.lockInterruptibly();
- try {
- for (;;) {
- RunnableScheduledFuture<?> first = queue[0];
- // 如果沒有任務,就讓線程在available條件下等待。
- if (first == null)
- available.await();
- else {
- // 獲取任務的剩余延時時間
- long delay = first.getDelay(NANOSECONDS);
- // 如果延時時間到了,就返回這個任務,用來執行。
- if (delay <= 0)
- return finishPoll(first);
- // 將first設置為null,當線程等待時,不持有first的引用
- first = null; // don't retain ref while waiting
- // 如果還是原來那個等待隊列頭任務的線程,
- // 說明隊列頭任務的延時時間還沒有到,繼續等待。
- if (leader != null)
- available.await();
- else {
- // 記錄一下當前等待隊列頭任務的線程
- Thread thisThread = Thread.currentThread();
- leader = thisThread;
- try {
- // 當任務的延時時間到了時,能夠自動超時喚醒。
- available.awaitNanos(delay);
- } finally {
- if (leader == thisThread)
- leader = null;
- }
- }
- }
- }
- } finally {
- if (leader == null && queue[0] != null) // 喚醒等待任務的線程
- available.signal();
- ock.unlock();
- }
- }
take基本流程圖如下:
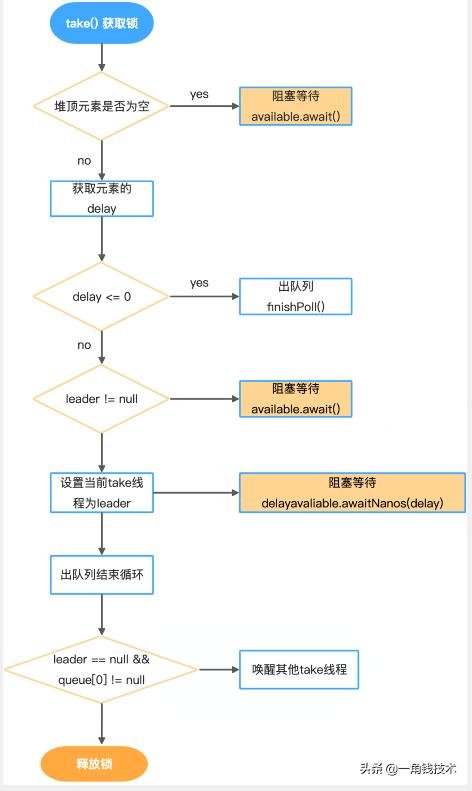
take線程阻塞等待
可以看出這個生產者take線程會在兩種情況下阻塞等待:
- 堆頂元素為空。
- 堆頂元素的delay > 0 。
finishPoll出隊列
堆頂元素delay<=0,執行時間到,出隊列就是一個向下堆化的過程siftDown。
- // 移除隊列頭元素
- private RunnableScheduledFuture<?> finishPoll(RunnableScheduledFuture<?> f) {
- // 將隊列中元素個數減一
- int s = --size;
- // 獲取隊列末尾元素x
- RunnableScheduledFuture<?> x = queue[s];
- // 原隊列末尾元素設置為null
- queue[s] = null;
- if (s != 0)
- // 因為移除了隊列頭元素,所以進行重新排序。
- siftDown(0, x);
- setIndex(f, -1);
- return f;
- }
堆的刪除方法主要分為三步:
- 先將隊列中元素個數減一;
- 將原隊列末尾元素設置成為隊列頭元素,再將隊列末尾元素設置為null;
- 調用setDown(O,x)方法,保證按照元素的優先級排序。
向下堆化siftDown
由于堆頂元素出隊列后,就破壞了堆的結構,需要組織整理下,將堆尾元素移到堆頂,然后向下堆化:
- 從堆頂開始,父親節點與左右子節點中較小的孩子節點比較(左孩子不一定小于右孩子)。
- 父親節點小于等于較小孩子節點,則結束循環,不需要交換位置。
- 若父親節點大于較小孩子節點,則交換位置。
- 繼續向下循環判斷父親節點和孩子節點的關系,直到父親節點小于等于較小孩子節點才結束循環。
向下堆化siftDown的詳細過程可以查看《堆和二叉堆的實現和特性》
- private void siftDown(int k, RunnableScheduledFuture<?> key) {
- // 無符號右移,相當于size/2
- int half = size >>> 1;
- // 通過循環,保證父節點的值不能大于子節點。
- while (k < half) {
- // 左子節點, 相當于 (k * 2) + 1
- int child = (k << 1) + 1;
- // 左子節點位置元素
- RunnableScheduledFuture<?> c = queue[child];
- // 右子節點, 相當于 (k * 2) + 2
- int right = child + 1;
- // 如果左子節點元素值大于右子節點元素值,那么右子節點才是較小值的子節點。
- // 就要將c與child值重新賦值
- if (right < size && c.compareTo(queue[right]) > 0)
- c = queue[child = right];
- // 如果父節點元素值小于較小的子節點元素值,那么就跳出循環
- if (key.compareTo(c) <= 0)
- break;
- // 否則,父節點元素就要和子節點進行交換
- queue[k] = c;
- setIndex(c, k);
- k = child;
- }
- queue[k] = key;
- setIndex(key, k);
- }
leader線程
leader線程的設計,是Leader-Follower模式的變種,旨在于為了不必要的時間等待。當一個take線程變成leader線程時,只需要等待下一次的延遲時間,而不是leader線程的其他take線程則需要等leader線程出隊列了才喚醒其他take線程。
poll()
立即獲取隊列頭元素,當隊列頭任務是null,或者任務延時時間沒有到,表示這個任務還不能返回,因此直接返回null。否則調用finishPoll方法,移除隊列頭元素并返回。
- public RunnableScheduledFuture<?> poll() {
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- RunnableScheduledFuture<?> first = queue[0];
- // 隊列頭任務是null,或者任務延時時間沒有到,都返回null
- if (first == null || first.getDelay(NANOSECONDS) > 0)
- return null;
- else
- // 移除隊列頭元素
- return finishPoll(first);
- } finally {
- lock.unlock();
- }
- }
poll(long timeout, TimeUnit unit)
超時等待獲取隊列頭元素,與take方法相比較,就要考慮設置的超時時間,如果超時時間到了,還沒有獲取到有用任務,那么就返回null。其他的與take方法中邏輯一樣。
- public RunnableScheduledFuture<?> poll(long timeout, TimeUnit unit)
- throws InterruptedException {
- long nanos = unit.toNanos(timeout);
- final ReentrantLock lock = this.lock;
- lock.lockInterruptibly();
- try {
- for (;;) {
- RunnableScheduledFuture<?> first = queue[0];
- // 如果沒有任務。
- if (first == null) {
- // 超時時間已到,那么就直接返回null
- if (nanos <= 0)
- return null;
- else
- // 否則就讓線程在available條件下等待nanos時間
- nanos = available.awaitNanos(nanos);
- } else {
- // 獲取任務的剩余延時時間
- long delay = first.getDelay(NANOSECONDS);
- // 如果延時時間到了,就返回這個任務,用來執行。
- if (delay <= 0)
- return finishPoll(first);
- // 如果超時時間已到,那么就直接返回null
- if (nanos <= 0)
- return null;
- // 將first設置為null,當線程等待時,不持有first的引用
- first = null; // don't retain ref while waiting
- // 如果超時時間小于任務的剩余延時時間,那么就有可能獲取不到任務。
- // 在這里讓線程等待超時時間nanos
- if (nanos < delay || leader != null)
- nanos = available.awaitNanos(nanos);
- else {
- Thread thisThread = Thread.currentThread();
- leader = thisThread;
- try {
- // 當任務的延時時間到了時,能夠自動超時喚醒。
- long timeLeft = available.awaitNanos(delay);
- // 計算剩余的超時時間
- nanos -= delay - timeLeft;
- } finally {
- if (leader == thisThread)
- leader = null;
- }
- }
- }
- }
- } finally {
- if (leader == null && queue[0] != null) // 喚醒等待任務的線程
- available.signal();
- lock.unlock();
- }
- }
remove刪除指定元素
刪除指定元素一般用于取消任務時,任務還在阻塞隊列中,則需要將其刪除。當刪除的元素不是堆尾元素時,需要做堆化處理。
- public boolean remove(Object x) {
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- int i = indexOf(x);
- if (i < 0)
- return false;
- //維護heapIndex
- setIndex(queue[i], -1);
- int s = --size;
- RunnableScheduledFuture<?> replacement = queue[s];
- queue[s] = null;
- if (s != i) {
- //刪除的不是堆尾元素,則需要堆化處理
- //先向下堆化
- siftDown(i, replacement);
- if (queue[i] == replacement)
- //若向下堆化后,i位置的元素還是replacement,說明四無需向下堆化的,
- //則需要向上堆化
- siftUp(i, replacement);
- }
- return true;
- } finally {
- lock.unlock();
- }
- }
總結
使用優先級隊列DelayedWorkQueue,保證添加到隊列中的任務,會按照任務的延時時間進行排序,延時時間少的任務首先被獲取。
- DelayedWorkQueue的數據結構是基于堆實現的;
- DelayedWorkQueue采用數組實現堆,根節點出隊,用最后葉子節點替換,然后下推至滿足堆成立條件;最后葉子節點入隊,然后向上推至滿足堆成立條件;
- DelayedWorkQueue添加元素滿了之后會自動擴容原來容量的1/2,即永遠不會阻塞,最大擴容可達Integer.MAX_VALUE,所以線程池中至多有corePoolSize個工作線程正在運行;
- DelayedWorkQueue 消費元素take,在堆頂元素為空和delay >0 時,阻塞等待;
- DelayedWorkQueue 是一個生產永遠不會阻塞,消費可以阻塞的生產者消費者模式;
- DelayedWorkQueue 有一個leader線程的變量,是Leader-Follower模式的變種。當一個take線程變成leader線程時,只需要等待下一次的延遲時間,而不是leader線程的其他take線程則需要等leader線程出隊列了才喚醒其他take線程。






















