介紹
數據科學(機器學習)項目為你提供了一種有前途的方式來啟動你在該領域的職業。你不僅可以通過應用它來學習數據科學,還可以在自己的簡歷上展示一些項目!
如今,招聘人員通過他/她的工作來評估應聘者的潛力,而不是將重點放在認證上。如果你沒有什么東西可以告訴他們,那也沒關系!這是大多數人掙扎和錯過的地方。
你以前可能曾處理過幾個問題,但是如果你無法使其表現得那么好且易于解釋,那么究竟有什么人會知道你的能力呢?這些項目將為你提供幫助。想想你將花費在這些項目上的時間,例如培訓課程。練習花費的時間越多,你就會變得更好!
我們確保為你提供不同領域的各種問題。我們認為,每個人都必須學習如何巧妙地處理大量數據,因此其中包括大型數據集。另外,我們確保所有數據集都是開放的并且可以自由訪問。

有用的信息
為了幫助你確定從何處開始,我們將該列表分為3個級別,即:
- 初級: 此級別包含相當容易使用的數據集,并且不需要復雜的數據科學技術。你可以使用基本回歸或分類算法來解決它們。而且,這些數據集有足夠的開放教程來幫助你入門。
- 中級:此級別包含本質上更具挑戰性的數據集。它由中型和大型數據集組成,需要一些認真的模式識別技能。此外,功能工程將在這里有所作為。機器學習技術的使用沒有限制;陽光下的一切都可以使用。
- 高級:此級別最適合理解高級主題(如神經網絡,深度學習,推薦系統等)的人員。此處還提供了高維數據集。另外,這是時候發揮創造力了。查看最佳數據科學家將其帶入他們的工作和代碼的創造力。
目錄
- 初級 虹膜數據 貸款預測數據 Bigmart銷售數據 波士頓住房數據 時間序列分析數據 葡萄酒質量數據 Turkiye學生評估數據 身高體重數據
- 中級 黑色星期五數據 人類活動識別數據 暹羅比賽數據 行程記錄數據 百萬首歌曲數據 人口普查收入數據 電影鏡頭數據 Twitter分類數據
- 高級 識別你的數字 城市聲音分類 Vox名人資料 ImageNet數據 芝加哥犯罪數據 印度演員數據的年齡檢測 推薦引擎數據 VisualQA數據
初級
1.虹膜數據集
這可能是模式識別文獻中最通用、最簡單、資源最豐富的數據集。沒有什么比虹膜數據集學習分類技術更簡單的了。如果你是全新的數據科學學習生,這將成為你的起點。數據只有150行4列。
問題:根據可用屬性預測花朵的類別。
開始:獲取數據:https://archive.ics.uci.edu/ml/datasets/Iris
教程:http://www.slideshare.net/thoi_gian/iris-data-analysis-with-r
讓我們看一下Iris數據,并在下面的“實時編碼”窗口中構建一個Logistic回歸模型。
https://id.analyticsvidhya.com/auth/login/?next=https://www.analyticsvidhya.com/blog/2018/05/24-ultimate-data-science-projects-to-boost-your-knowledge-and-skills
2.貸款預測數據集
在所有行業中,保險領域是分析和數據科學方法最大的用途之一。該數據集使你可以從保險公司的數據集中進行操作,那里面臨著哪些挑戰,使用了什么策略,哪些變量影響了結果等等。這是一個分類問題。數據有615行和13列。
問題:預測貸款是否會獲得批準。
開始:獲取數據:https://datahack.analyticsvidhya.com/contest/practice-problem-loan-prediction-iii/
教程:https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-learn-data-science-python-scratch-2/
讓我們看一下“貸款”數據并在下面的“實時編碼”窗口中構建一個Logistic回歸模型。
https://id.analyticsvidhya.com/auth/login/?next=https://www.analyticsvidhya.com/blog/2018/05/24-ultimate-data-science-projects-to-boost-your-knowledge-and-skills
3. Bigmart銷售數據集
零售是另一個廣泛使用分析來優化業務流程的行業。使用數據科學技術可以巧妙地處理諸如產品放置,庫存管理,自定義報價,產品捆綁等任務。顧名思義,該數據包含銷售商店的交易記錄。這是一個回歸問題。數據具有12個變量的8523行。
問題:預測商店的銷售額。
開始:獲取數據:https://datahack.analyticsvidhya.com/contest/practice-problem-big-mart-sales-iii/
教程:https://www.analyticsvidhya.com/blog/2016/02/bigmart-sales-solution-top-20/
讓我們看一下Big Mart銷售數據,并在下面的“實時編碼”窗口中構建線性回歸模型。
https://id.analyticsvidhya.com/auth/login/?next=https://www.analyticsvidhya.com/blog/2018/05/24-ultimate-data-science-projects-to-boost-your-knowledge-and-skills
4.波士頓住房數據集
這是模式識別文獻中另一個流行的數據集。數據集來自美國波士頓的房地產行業。這是一個回歸問題。數據具有506行和14列。因此,這是一個相當小的數據集,你可以在其中嘗試任何技術而不必擔心筆記本電腦的內存被過度使用。
問題:預測業主占有的房屋的價值中值。
開始:獲取數據:https://www.cs.toronto.edu/~delve/data/boston/bostonDetail.html
教程:https://www.analyticsvidhya.com/blog/2015/11/started-machine-learning-ms-excel-xl-miner/
5.時間序列分析數據集
時間序列是數據科學中最常用的技術之一。它具有廣泛的應用程序——天氣預報,預測銷售,分析逐年趨勢等。此數據集特定于時間序列,而此處的挑戰是以一種運輸方式預測交通量。數據具有行和列。
問題:以新的運輸方式預測交通量。
開始:獲取數據:https://datahack.analyticsvidhya.com/contest/practice-problem-time-series-2/
教程:https://trainings.analyticsvidhya.com/courses/course-v1:AnalyticsVidhya+TS_101+TS_term1/about
6.葡萄酒質量數據集
這是數據科學初學者中最受歡迎的數據集之一。它分為2個數據集。你可以對此數據執行回歸和分類任務。它將測試你在不同領域的理解能力——異常檢測,特征選擇和不平衡數據。該數據集中有4898行和12列。
問題:預測葡萄酒的質量。
開始:獲取數據:https://archive.ics.uci.edu/ml/datasets/Wine+Quality
教程:https://web.stanford.edu/~ilker/doc/wine_Stats315A.pdf
7. Turkiye學生評估數據集
該數據集基于學生針對不同課程填寫的評估表。它具有不同的屬性,包括出勤率,難度,每個評估問題的得分等。這是一個無監督的學習問題。數據集有5820行和33列。
問題:使用分類和聚類技術來處理數據。
開始:獲取數據:https://archive.ics.uci.edu/ml/datasets/Wine+Qualityhttps://archive.ics.uci.edu/ml/datasets/Turkiye+Student+Evaluation
教程:https://sanghosuh.github.io/research/LA_EdMining_SanghoSuh.pdf
8.身高和體重數據集
這是一個相當簡單的問題,非常適合剛開始使用數據科學的人們。這是一個回歸問題。數據集具有25,000行和3列(索引,高度和權重)。
問題:預測一個人的身高或體重。
開始:獲取數據:http://wiki.stat.ucla.edu/socr/index.php/SOCR_Data_Dinov_020108_HeightsWeights
教程:https://www3.nd.edu/~steve/computing_with_data/2_Motivation/motivate_ht_wt.html
中級
1.黑色星期五數據集
該數據集包含在零售商店捕獲的銷售交易。這是一個經典的數據集,可從多種購物體驗中探索和擴展你的特殊工程技能以及日常理解能力。這是一個回歸問題。數據集具有550,069行和12列。
問題: 預測購買金額。
開始:獲取數據:https://datahack.analyticsvidhya.com/contest/black-friday/
教程:https://discuss.analyticsvidhya.com/t/black-friday-data-hack-reveal-your-approach/5986
2.人類活動識別數據集
該數據集是從通過嵌入式智能慣性傳感器啟用的智能手機捕獲的30個人物的記錄中收集的。許多機器學習課程將這些數據用于教學目的。輪到你了。這是一個多分類問題。數據集有10,299行和561列。
問題:預測人類的活動類別。
開始:獲取數據:http://archive.ics.uci.edu/ml/datasets/Human+Activity+Recognition+Using+Smartphones
教程:https://rstudio-pubs-static.s3.amazonaws.com/291850_859937539fb14c37b0a311db344a6016.html
3.文本挖掘數據集

該數據集最初來自2007年舉行的暹羅文字采礦比賽。該數據包含描述某些飛行中出現的問題的航空安全報告。這是一個多分類的高維問題。它具有21,519行和30,438列。
問題:根據文檔的標簽對文檔進行分類。
開始:獲取數據:http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/multilabel.html#siam-competition2007
教程:https://wtlab.um.ac.ir/images/e-library/text_mining/Survey%20of%20Text%20Mining%202%20.pdf
4.行程歷史數據集
該數據集來自美國的自行車共享服務。此數據集要求你鍛煉專業數據處理技能。該數據從2010年第四季度開始按季度提供。每個文件有7列。這是一個分類問題。
問題:預測用戶類別。
開始:獲取數據:https://www.capitalbikeshare.com/trip-history-data
教程:https://www.analyticsvidhya.com/blog/2015/06/solution-kaggle-competition-bike-sharing-demand/
5.百萬首歌曲數據集
你知道數據科學也可以用于娛樂行業嗎?自己動手吧!該數據集提出了回歸任務。它由5,15,345個觀測值和90個變量組成。但是,這只是大約一百萬首歌曲的原始數據數據庫的一小部分 。
問題:預測歌曲的發行年份。
開始:獲取數據:http://archive.ics.uci.edu/ml/datasets/YearPredictionMSD
教程:http://www-personal.umich.edu/~yjli/content/projectreport.pdf
6.人口普查收入數據集
這是一個不平衡的分類,是一個經典的機器學習問題。你知道,機器學習已廣泛用于解決不平衡的問題,例如癌癥檢測,欺詐檢測等。現在是時候自己動手了。數據集具有48,842行和14列。
問題:預測美國人口的收入等級。
開始:獲取數據:http://archive.ics.uci.edu/ml/machine-learning-databases/census-income-mld/
教程:https://cseweb.ucsd.edu/~jmcauley/cse190/reports/sp15/048.pdf
7.電影鏡頭數據集
你是否已建立推薦系統?這是你的機會!該數據集是數據科學行業中最受歡迎和引用最多的數據集之一。它有各種尺寸。在這里,我使用了相當小的尺寸。它在4,000部電影中獲得6,000名用戶的100萬收視率。
問題:向用戶推薦新電影。
開始:獲取數據:http://grouplens.org/datasets/movielens/1m/
教程:https://www.analyticsvidhya.com/blog/2016/06/quick-guide-build-recommendation-engine-python/
8. Twitter分類數據集
使用Twitter數據已成為情感分析問題不可或缺的一部分。如果你想在這一領域為自己開拓一片天地,那么你將很樂于應對該數據集帶來的挑戰。數據集大小為3MB,具有31,962條推文。
問題:識別哪些是仇恨推特,哪些不是。
開始:獲取數據:https://datahack.analyticsvidhya.com/contest/practice-problem-twitter-sentiment-analysis/
教程:https://github.com/abdulfatir/twitter-sentiment-analysis
高級
1.確定你的位數數據集
該數據集使你可以研究,分析和識別圖像中的元素。這就是相機使用圖像識別來檢測你的臉的方式!現在輪到你構建和測試該技術了。這是一個數字識別問題。該數據集包含7,000張28 X 28大小的圖像,總計31MB。
問題:識別圖像中的數字。
開始:獲取數據:https://datahack.analyticsvidhya.com/contest/practice-problem-identify-the-digits/
教程:https://www.analyticsvidhya.com/blog/2016/10/an-introduction-to-implementing-neural-networks-using-tensorflow/
2.城市聲音分類
當你開始機器學習之旅時,你會遇到簡單的機器學習問題,例如泰坦尼克號生存預測。但是,對于現實生活中的問題,你仍然沒有足夠的練習。因此,此練習問題旨在向你介紹常規分類情況下的音頻處理。該數據集包含10個類別的8,732個城市聲音的聲音摘錄。
問題:從音頻中分類聲音的類型。
開始:獲取數據:https://datahack.analyticsvidhya.com/contest/practice-problem-urban-sound-classification/
教程:https://www.analyticsvidhya.com/blog/2017/08/audio-voice-processing-deep-learning/
3. Vox名人數據集
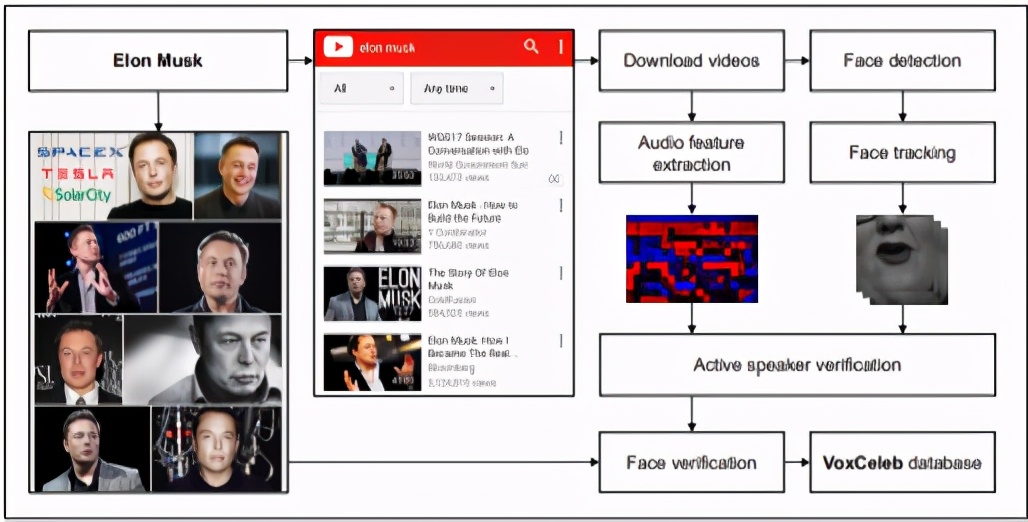
音頻處理正迅速成為深度學習的重要領域,因此這是另一個具有挑戰性的問題。此數據集用于大規模的說話人識別,包含從YouTube視頻中提取的名人所說的單詞。這是用于分離和識別語音的有趣用例。數據包含1,251位名人所說的100,000次講話。
問題:找出聲音屬于哪個名人。
開始:獲取數據:http://www.robots.ox.ac.uk/~vgg/data/voxceleb/
教程:https://www.robots.ox.ac.uk/~vgg/publications/2017/Nagrani17/nagrani17.pdf
4. ImageNet數據集
ImageNet提供了各種問題,包括對象檢測,定位,分類和屏幕解析。所有圖像均可免費獲得。你可以搜索任何類型的圖像并圍繞該圖像構建項目。截止到目前,該圖像引擎已經擁有超過1500萬張多種形狀的圖像,大小高達140GB。
問題:要解決的問題取決于你下載的圖像類型。
開始:獲取數據:http://image-net.org/download-imageurls
教程:http://image-net.org/download-imageurls
5.芝加哥犯罪數據集
如今,每位數據科學家都希望能夠處理大型數據集。當公司在整個數據集上具有計算能力時,他們不再喜歡使用樣本。該數據集為你提供了在本地計算機上處理大型數據集所需的實際經驗。問題很容易,但是數據管理才是關鍵!該數據集具有600萬個觀測值。這是一個多分類問題。
問題:預測犯罪類型。
開始:獲取數據: https://data.cityofchicago.org/Public-Safety/Crimes-2001-to-present/ijzp-q8t2
教程:http://nathanwayneholt.com/mathematicalmodeling/ChicagoCrimesReport.pdf
6.印度演員年齡數據集
對于任何深度學習愛好者來說,這都是一個吸引人的挑戰。數據集包含數千個印度演員的圖像,你的任務是確定他們的年齡。手動選擇所有圖像,并從視頻幀中裁剪所有圖像,這導致了比例,姿勢,表情,年齡,分辨率,遮擋和化妝具有高度的可變性。訓練集中有19,906張圖像,測試集中有6,636張圖像。
問題:預測演員的年齡。
開始:獲取數據:http://image-net.org/download-imageurls
教程:https://www.analyticsvidhya.com/blog/2017/06/hands-on-with-deep-learning-solution-for-age-detection-practice-problem/
7.推薦引擎數據集
這是一個高級推薦系統的挑戰。在這個實踐問題中,將為你提供程序員的數據和他們先前已解決的問題,以及他們解決該特定問題所花費的時間。作為數據科學家,你建立的模型將幫助在線評委決定下一級的問題推薦給用戶。
問題:根據用戶的當前狀態,預測解決問題所需的時間。
開始:獲取數據:https://datahack.analyticsvidhya.com/contest/practice-problem-recommendation-engine/
8. VisualQA數據集

VisualQA是一個數據集,其中包含有關圖像的開放式問題。這些問題需要有對計算機視覺和語言的理解。這個問題有一個自動的評估指標。數據集包含265,016張圖像,每張圖像3個問題,每個問題10個真實答案。
問題:使用深度學習技術回答有關圖像的開放性問題。
開始:獲取數據:http://www.visualqa.org/
教程:https://arxiv.org/abs/1708.02711
尾注
在上面列出的24個數據集中,你應該首先找到一個與你的技能組匹配的數據集。如果你是機器學習的初學者,請避免從一開始就使用高級數據集。不要咬一個超過你咀嚼能力的東西,不要對仍然要做的事情感到不知所措。相反,應專注于逐步取得進展。