用于代碼生成的基于語法的結構 CNN 解碼器
摘要
代碼生成將程序描述映射到可執行文件編程語言的源代碼。現有方法主要依靠遞歸神經網絡(RNN)編碼器。但是,我們發現一個程序包含比自然語言句子更多的標記,因此它可能不適合 RNN 捕獲如此長的序列。在本文提出了一種基于語法的結構卷積用于代碼生成的傳統神經網絡(CNN)。我們的模型通過預測語法規則來生成程序編程語言;我們設計了多個 CNN 模塊,包括基于樹的卷積和預卷積,其信息將由專門的參與者進一步匯總-活動池層。《爐石傳說》的實驗結果基準數據集顯示,我們的 CNN 代碼生成器明顯比以前的最新方法高 5 個百分比;在幾個語義解析任務上的其他實驗證明了我們模型的魯棒性。我們還進行深入的消融測試,以更好地了解每個模型的組成部分。
介紹
根據自然語言描述生成代碼是一種人工智能中艱巨而艱巨的任務。對 var-應用程序。例如,程序員想在 Python 中“打開文件,F1”,但不知道如何用編程語言來實現,他可以獲得目標代碼“f=open('F1','r')”通過代碼生成。隨著深度學習的繁榮,編解碼器框架成為流行的序列生成方法聯盟。特別是遞歸神經網絡(RNN)通常用作編碼器和解碼器;這樣的建筑師也稱為序列到序列(Seq2Seq)模型。當應用于代碼生成,它將程序描述作為輸入放置序列并生成所需的代碼作為輸出序列。
在深度學習社區中,研究人員正在展示對使用卷積神經網絡的興趣日益濃厚(CNN)作為解碼器,因為它的效率高且容易訓練的精神。我們進一步觀察到,一個程序大于自然語言的句子,而 RNN 則是即使有很長的短期記憶。相反,CNN 能夠有效地捕獲不同位置的特征通過滑動窗口區域。
為此,我們提出了一種基于語法的結構 CNN 用于代碼生成。我們的模型通過 AST 中的語法構造規則,例如 If→exprstmtstmt,遵循我們之前的框架工作。由于子節點的順序是通過一個預測步驟生成的,它可以使更多的契約預測比逐 token 生成。其他換句話說,我們的模型會預測語法規則的順序,最終形成一個完整的程序。
在我們的方法中,語法規則的預測是主要基于三種類型的信息:指定要生成的程序的頻率先前預測的語法規則,以及部分 AST 已生成。在這里,前一個是編碼器。后兩者使模型能夠自回歸解碼器,并且像往常一樣,解碼器還取決于編碼器。我們為結構設計了幾個不同的組件適用于程序生成的 CNN:(1)我們首先采用應用滑動窗口的基于樹的卷積思想在 AST 結構上。然后我們設計另一個 CNN 模塊,用于對節點中的節點進行遍歷部分 AST。這兩種 CNN 捕獲鄰居-不僅在序列中而且在樹中獲取信息結構體。(2)為了增強“自回歸”,我們應用了-其他 CNN 模塊到要生成的節點的祖先安裝,因此網絡知道在哪里生成在某個步驟。(3)我們設計了一個專心的集中池聚合與 CNN 互動的機制不同的神經模塊。特別是,我們發現它對考慮范圍名稱(例如,函數和方法名稱)在代碼生成過程中,請使用諸如幾個細心的池化層的 troller。
我們根據既定基準進行了實驗數據集《爐石傳說》,用于 python 代碼生成。實驗結果表明,我們基于 CNN 代碼生成器的性能優于以前的 RNN 方法很大程度上。我們在兩個方面進一步評估了我們的方法 Mantic 解析任務,其中目標程序較短比《爐石傳說》;我們的方法也取得了可比性結果與先前的最新方法一致,表明我們方法的魯棒性。我們進行了廣泛的消融測試,表明我們基于語法的結構設計 CNN 比單純使用 CNN 更好。
模型
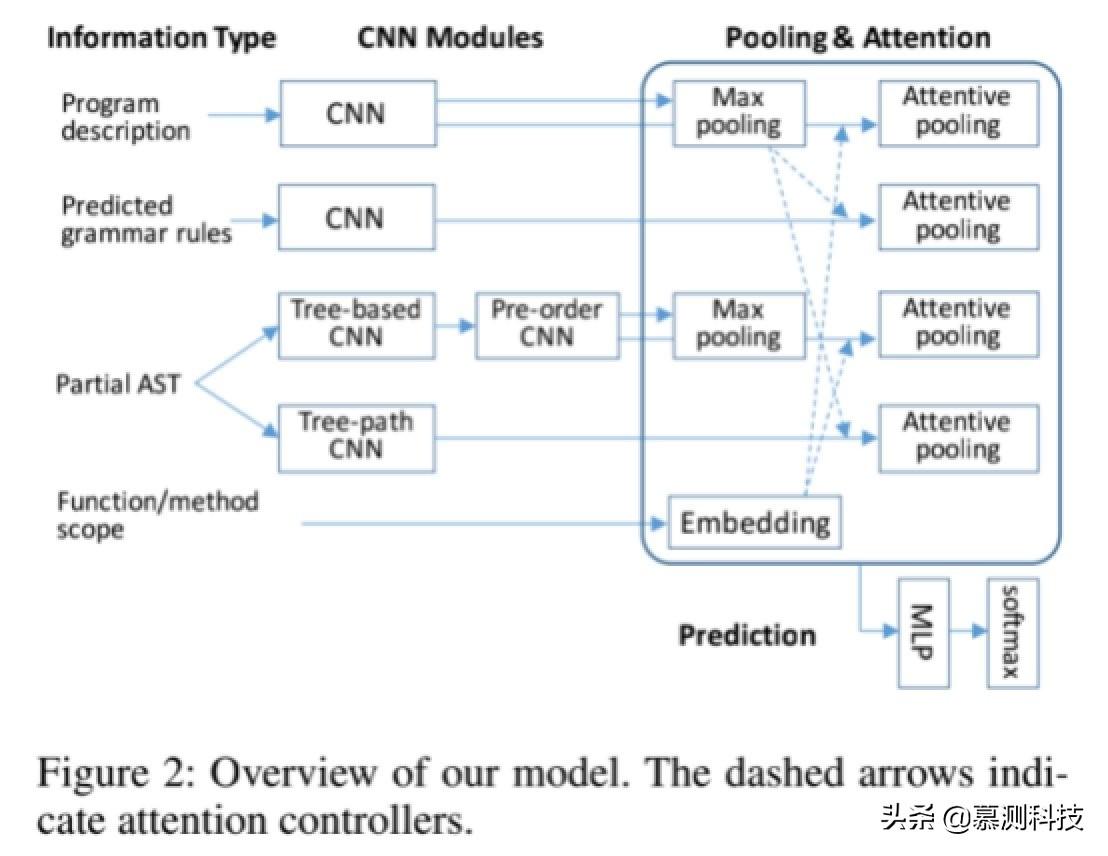
圖 2 顯示了我們網絡的整體結構。我們會首先描述基于語法的代碼生成過程,然后詳細介紹每個模塊。
基于語法的代碼生成
對于程序說明的輸入,我們的任務是生成一個符合描述的一段可執行代碼。在傳統的 Seq2Seq 模型中,可以表示一個程序作為 token 序列 x1,x2,···,xT,這些 token 是按順序生成。
另外,有效的程序可以用抽象語法樹(AST)。葉節點是表示為 x 終端的符號,x1,x2,···,xT。非葉節點是非終端符號 n1,···,nN,每個表示程序的抽象組件(例如,If 塊)。此外,子節點 n1,···,nk 源自它們的父節點 p 是通過應用一些語法規則 r 獲得的,表示為 p→n1···nk。在我們的工作中,不同的葉子節點用戶定義的變量被視為單獨的語法通過檢查訓練集來確定規則。我們以深度優先的順序遍歷樹,對于首先遇到非終結符,我們預測什么規則應該用來擴展它。換句話說,概率程序的分解為
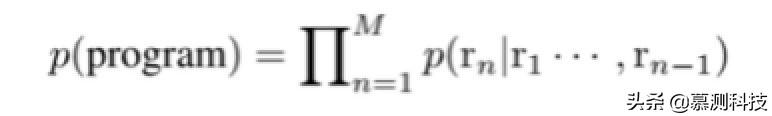
盡管典型的編程語言包含更多內容語法規則比不同的 AST 節點多,基于語法生成更加緊湊,因為子節點 c1,···,ck 通過對規則的單個預測而就位 p→c1···ck。而且,生成的程序保證在語法上正確。在本節的其余部分,我們將介紹 CNN 編碼器-解碼器模型,用于預測語法規則。
輸入的 CNN
我們模型的輸入是一段描述,它指定要生成的程序。用于卡片的代碼生成在《爐石傳說》中,輸入是半結構化數據,包含圖示卡片的名稱,屬性和說明在圖 4 中。對于其他任務,例如語義解析,則輸入可能是自然的量詞句。
形式上,提取的特征可以被計算
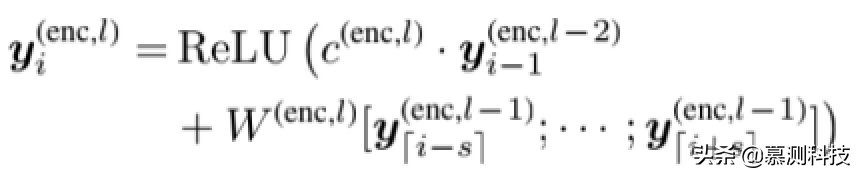
其中,W(enc,l)是編碼器的卷積權重 CNN,s 由 s=(k−1)/2 計算,k 是窗口大小(在我們的實驗中設置為 2),并且 l=1,···,L 表示 CNN 的深層。特別是 y(enc,0)是輸入嵌入 x(enc)。c(enc,l)=1 表示偶數層,0 表示奇數層層,指示是否存在以下快捷方式連接這一層。對于第一個和最后幾個詞,我們執行零填充。
預測規則的 CNN
我們跟蹤所有之前的規則,并建立一個深度神經網絡來提取此類信息信息。
令 r1,...,rn-1 為先前預測的規則。我們將它們嵌入為實值向量 r1,···,rn-1,其中嵌入是隨機初始化的,可以通過反向學習傳播。我們應用帶有快捷方式連接的深層 CNN 模塊規則嵌入 r1,···,rn-1 的注釋,提取特征 y。
預測的語法規則完全指定生成的(部分)程序以緊湊的方式,這是有益的用于精確的代碼生成。
但是,僅向解碼器提供預規定的自回歸規則,因為它們沒有提供該程序的具體/圖片視圖。為了減輕這個問題,我們增強了解碼器部分 AST,如下所述。
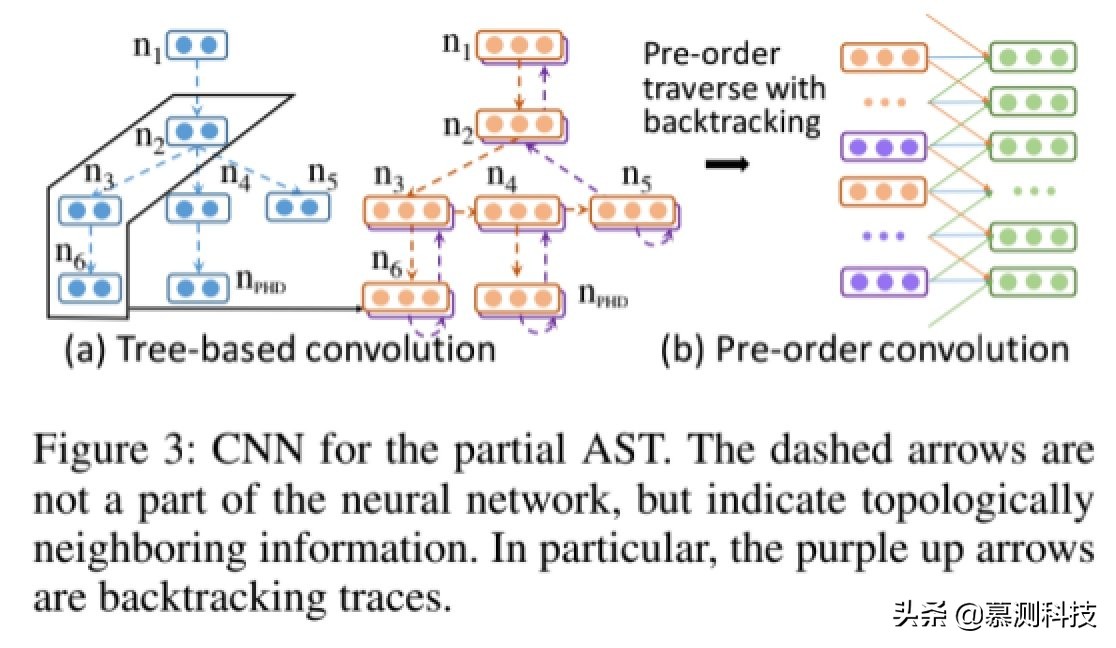
部分 AST 的 CNN
我們設計了一個深層的 CNN 模塊來捕獲 AST 的結構,文化信息。它包含基于樹的卷積層,預遍歷遍歷卷積層以及樹狀路徑 CNN 子模塊,通知網絡何處下一個語法規則被應用。
基于樹的 CNN。我們首先將基于樹的 CNN 應用于部分 AST。主要是設計一個固定深度的局部特征檢測器,在樹上滑動以提取結構特征。基于樹的 CNN 的輸入是具有以下內容的部分 AST:生成后,每個節點都由嵌入表示。我們也把一個占位符的節點至指示在哪里應用下一個語法規則。
假設節點 n 有一個父節點 p 和一個祖先節點 g。然后基于樹的 CNN 提取特征可以被計算為
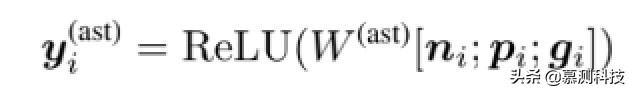
其中 W(ast)是基于樹的卷積 ker-內爾。我們為前兩個節點填充特殊 token 沒有父母和/或祖父母的圖層。
基于樹的卷積,因為我們有一個更深的窗口,但沒有考慮同級信息。這是因為我們的語法-基于世代的人通過申請一次獲得所有兄弟姐妹-遵循一定的規則,因此,兄弟姐妹的重要性降低-比祖先更坦誠。不幸的是,深度會成倍增長,而深度會變小易處理,而我們的基于樹的 CNN 變體會線性增長早。在卷積計算方面,我們采用類似感知器的互動方式。基于深度樹的卷積和快捷方式連接,如 ResNet 可以作為未來的工作來探索。
前序遍歷 CNN。獲得一組通過基于樹的 CNN 提取的向量,我們應用了預輸入 y(ast)進行遍歷卷積。也就是說,AST 節點是按照預先遍歷順序。
可以證明,簡單的預遍歷不是可以反轉為樹結構,即不同的樹結構可能產生相同的序列。為了解決這個問題,我們在預購遍歷期間跟蹤回溯跟蹤。T 是節點中的節點數 AST 和帶回溯的預遍歷可產生 2S 輸入單位。
請注意,基于樹的 CNN 和順序遍歷 CNN 捕獲不同的信息。預購遍歷產生的順序可解決順序鄰居生成期間 AST 節點的引擎蓋,而基于樹卷積可為以下節點提供信息融合在結構上相鄰。在圖 3 中,例如,節點 n4 是 n2 的子節點。但是,生成后有些程序的其他部分(即 n3 和 n6),節點 n2 和 n4 不再彼此靠近。基于樹的卷積直接為節點及其節點構建特征提取器祖先實現他們的互動。因此,我們相信這兩類 CNN 互為補充。
樹路徑 CNN。我們應該只考慮以上 CNN,該模型很難說出位置應用下一個語法規則的位置。例如,基于樹的 CNN 和預先遍歷的 CNN 如果我們將圖 3 中的 n4 或 n5 展開,將產生非常相似的特征,盡管有占位符,但我們還是為預購 CNN 引入了占位符。從技術上講,如果我們遵循最左邊的推導,那么應用下一條規則的位置將是明確的。但是這樣線索太隱含,應該更明確地建模。因此,我們提取了從根到節點的路徑,以 d 例如,如果我們要擴展 n4,則路徑應該是 n1,n2,n4。我們稱這種樹路徑卷積。
集合和注意機制
CNN 提取與尺寸或形狀相同的一組特征輸入。為了促進用于代碼生成的 softmax 預測,我們需要將信息匯總到一個或幾個固定的大小向量,與輸入大小無關。
傳統上,人使用最高匯集對于 CNN 以及基于樹的 CNN。但是,這使得潛在的 CNN 模塊分離且無法通信在信息聚合過程中。因此,我們納入了 CNN 的關注機制池。本質上,注意機制計算候選集的加權和功能(由 CNN 提取),其中權重由由控制向量放置(例如,最大池另一個 CNN 模塊的向量)。形式上,給定一個控制向量 c 和一組候選卷積特征 y1,···,yD 通過一個 CNN 模塊(D 是特征向量的數量)。
將這樣一個細心的池化層應用于我們的底層 CNN,我們將一些關鍵信息視為控制權-向量。(1)輸入描述指定程序生成,然后用它來控制語法規則 CNN 和樹路徑 CNN。特別是,我們應用最大池層將輸入的 CNN 功能匯總為固定大小控制向量,用于計算注意力樹路徑 CNN 的權重和預測語法規則。(2)我們注意到作用域名稱(即函數名稱或方法名稱)提供照明信息關于它的后代。此類信息未被捕獲 AST 節點類型,因此我們將范圍名稱嵌入為向量并使用它來控制預遍歷 CNN 和輸入的 CNN。應該注意的是,如果當前程序段位于兩個或多個范圍內(一個函數和一個方法),我們僅將最接近的范圍視為曳向量。如果代碼段不屬于任何函數或類,然后將范圍嵌入設置為零向量。除了針對基于樹的層級,將另一個最大池化層應用于預訂遍歷 CNN 功能。我們的經驗發現這是因為控制范圍內的嵌入使相應的 AST 節點的注意力也達到最高峰,匯總信息不足。盡管控制向量,另一個最大池-信息層也可以保留更多信息。
我們還要指出的是,注意機制設計的選擇及其含義在具有多個神經網絡的深層神經網絡中拖曳連接模塊。例如,我們最好將 CNN 用于遵循以下控制原則把所有其他模塊的輸入在編碼器-解碼器框架。但是,我們的初步實驗表明,這樣的設計產生了更低的性能,因此我們采用了當前的體系結構。
訓練和推論
我們將所有最大池化層和激活池化層連接在一起。它們被輸入到兩層感知器,最后一個層具有 softmax 激活函數,可預測下一個語法規則。
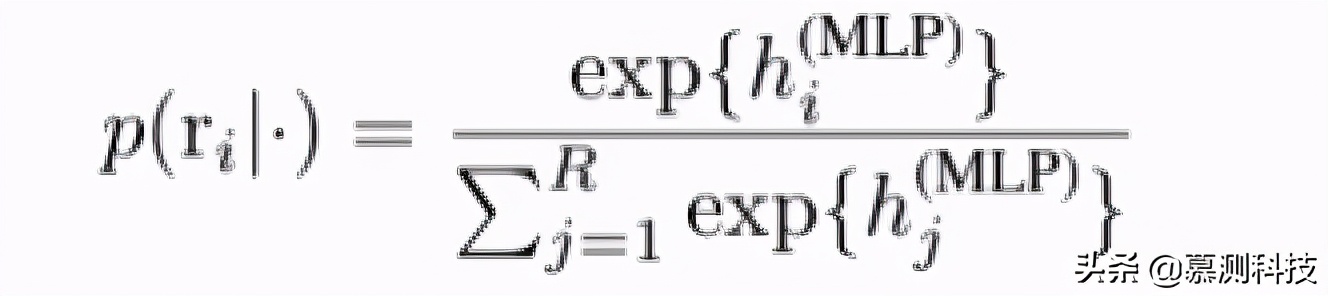
我們的模型是通過針對地面程序。由于我們的整個模型是不同的可靠,所有參數都是通過基于梯度的更新來學習的。
為了進行推斷,我們尋求一系列的語法規則,最大化以輸入為條件的概率。遞歸如果規則中的每個葉子節點都終止了對規則的密集預測(部分)樹是終端符號。我們使用光束搜索近似于全局推斷,并且波束大小為 5in 我們的實驗。特定節點類型的無效規則是推理期間不考慮。例如,p2→c1c2,如果 p1 不等于 p2,則不能應用于節點 p1。
評估
在本部分中,我們介紹了 CNN 的實驗結果基于代碼的生成。我們在兩個方面評估了我們的方法任務:(1)用 Python 代碼生成《爐石傳說》游戲,以及(2)用于生成可執行邏輯表單語義解析。
實驗一《爐石傳說》代碼生成
數據集。我們的第一個實驗基于建立基準數據集《爐石傳說》。數據集包含 665 個不同的《爐石傳說》游戲;每個數據點的輸入都是半字段的結構化描述,例如卡名,費用,攻擊,描述和其他屬性;輸出是可實現以下功能的 Python 代碼段。
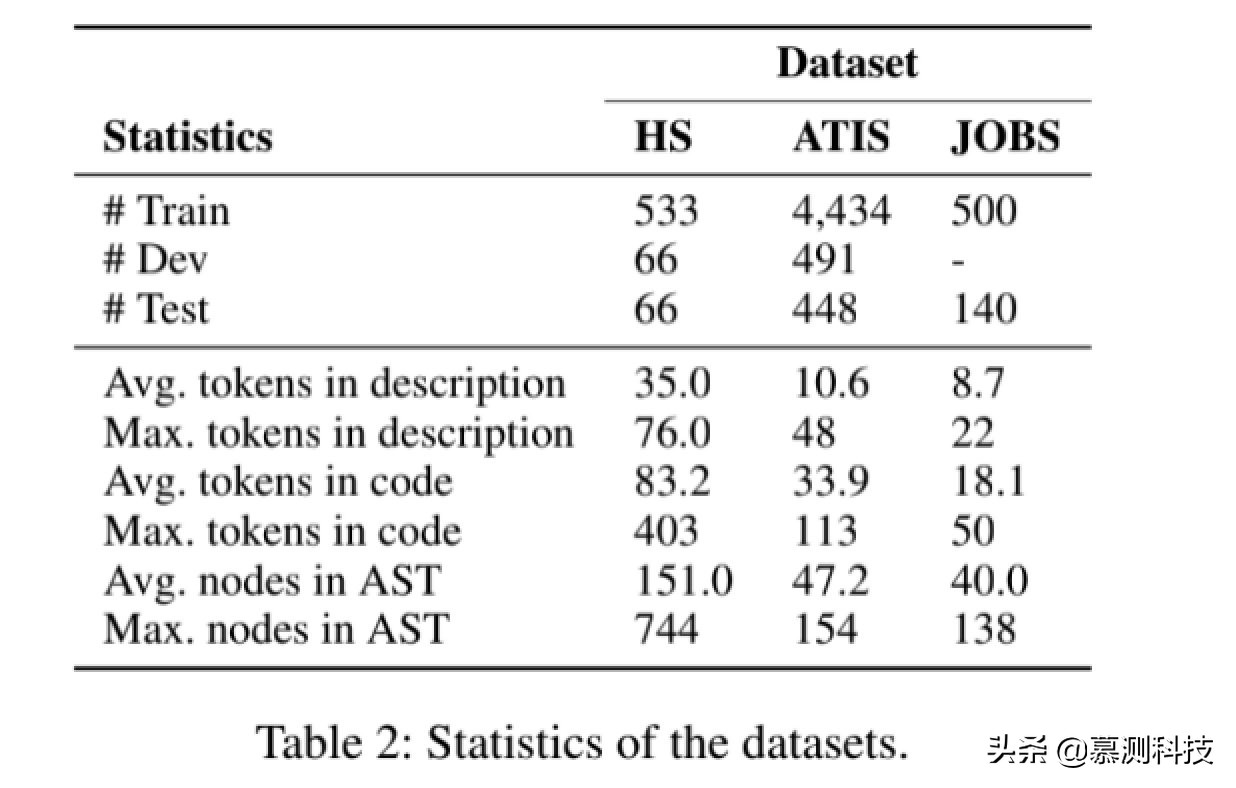
指標。表 2 中的《爐石傳說》列列出了相關的數據集的統計信息。指標。我們通過準確性評估了我們的方法,BLEU 得分。理想情況下,精度應計入分數功能上正確的程序的位置,不幸的是不是圖靈可計算的。我們還發現,幾個生成的程序使用不同的變量名稱,但實現了正確的功能,并且有時函數調用中的參數名稱是或未指定。雖然與參考程序不同,但經過人工檢查,它們顯然是正確的程序,我們用 Acc 表示人為調整的精度。在這里,我們沒有執行非 ob 檢查算法的 Vious 替代實現,因此 Acc 仍然是功能精度的下界。
生成的代碼的質量由 BLEU 評分作為輔助度量進一步評估,該度量計算生成的代碼與地面真相代碼的接近程度。
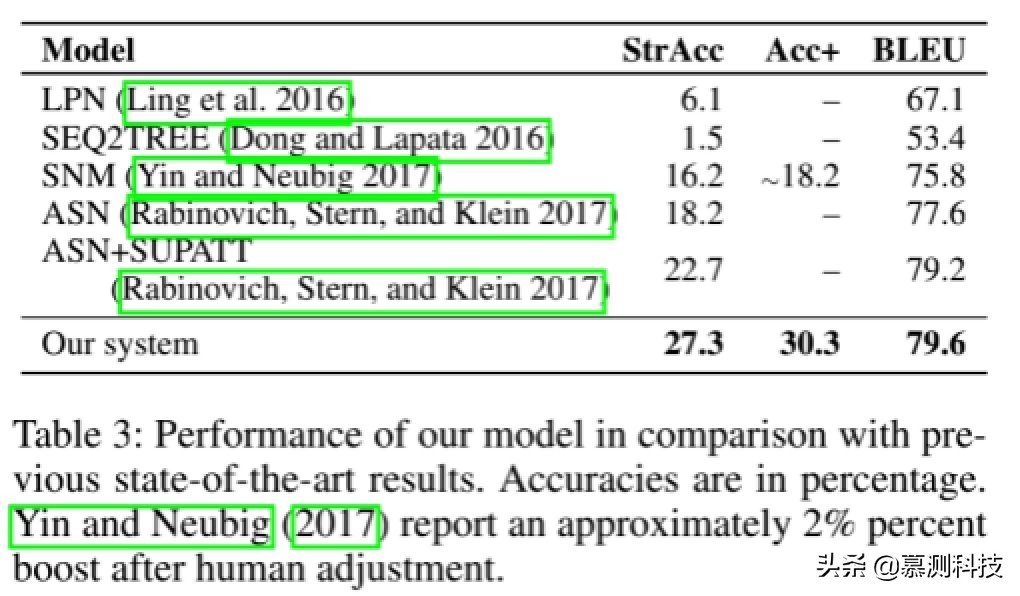
總體結果。表 3 列出了我們的 CNN-基于代碼的生成,與之前的狀態相比最先進的模型:(1)潛在預測網絡,一種增強的序列到序列模型,具有多個 token 級別的預測器;(2)SEQ2TREE,基于 AST 的序列到序列模型;(3)句法神經模型,基于 AST 結構的 LSTM 解碼器;和(4)Abstract 語法網絡,另一個基于 AST 的序列到序列模型,它建立了兩個 LSTM 水平預測規則和垂直方向。如圖所示,我們的模型優于之前的所有結果準確性和 BLEU 分數。特別是,我們的準確性大大高于以前的狀態弦樂方面的最新成果大約降低了 5 個百分點。生成的代碼示例。
準確性。對于人工調整的精度(Acc+),報告顯示,在我們的場景中觀察到類似的現象,并且我們的 Acc+得分達到了 30.3%,表明我們的方法具有有效性。我們發現一個有趣的事實,即先前的幾種方法可以達到與我們的方法類似的 BLEU 分數,但是精度要低得多。例如,ASN 模型 BLEU 分數為 79.2,與我們的 79.6 分相當模型。但是,ASN 只能達到 22.7%的字符串精度,而我們的是 27.3%。這是因為 BLEU 指標僅測量程序的相似度。預先以前的方法(例如 ASN)似乎可以生成合理的代碼,實際上在細節上是不正確的。因此,我們僅考慮 BLEU 得分(在之前的作品)作為次要指標。主要指標即準確性,表明我們的方法產生了更多的交流策劃程序比以前的模型。
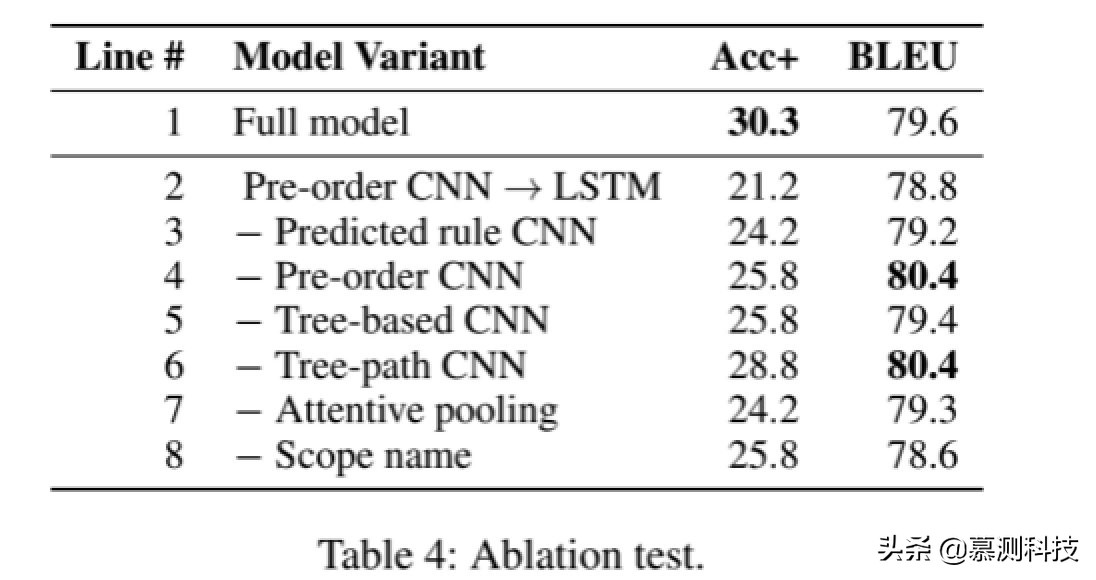
消融測試。我們進行了廣泛的消融測試分析每個組成部分的貢獻。雖然我們網絡的發展從簡單的基準開始然后我們逐步添加了有用的組件,相對測試是以相反的方式進行的:它從完整的模型,我們要么刪除了一個組件或用一些合理的替代品。我們在表 4 中報告了消融測試的結果。
我們首先通過替代 CNN 來分析 CNN 的效果基于 LSTM 的 RNN 的組件。自從主要信息在于部分 AST 中顯示的年齡,而不是預測語法規則中,我們僅將預遍歷 CNN 替換為 LSTM 在此對照實驗中。RNN 應用于如此長的序列可能很難訓練,實現顯著惡化性能。
我們還分析了模型的其他組成部分,包括為 CNN 預測規則,基于樹的卷積常規層,樹路徑卷積,池化層機制,以及合并的范圍控制器。我們看到上述每個組件都包含以自己的方式為整個模型做出貢獻,準確度提高了 3–6%。這些結果表明我們有設計了神經體系結構的合理組成部分,適合于代碼生成任務。
實驗二
數據集和設置。語義解析旨在生成邏輯形式給出自然語言描述。它可以被認為是針對特定領域的代碼生成,因為邏輯形式是可執行文件,所以一種正式語言。但是,語義解析的樣式與 python 代碼生成明顯不同。自從我們模型主要是在《爐石傳說》數據集上開發的,該實驗用作對泛化性的附加評估我們的模型。
我們在兩個語義解析數據集上評估了我們的模型,其中輸入的是自然語言句子。ATIS 的輸出是 λ 微積分形式,而對于 JOBS,它采用 Prolog 樣式。從表 2 的統計數據可以看出語義解析的邏輯形式包含節點少于《爐石傳說》Python 代碼。
我們采用了與《爐石傳說》基本相同的網絡層進行語義解析。網絡層數是 7。我們沒有建立一個單獨的不同的節點類型的網絡,因為我們的網絡容易對于如此小的數據集過擬合。此外,我們介紹了指針網絡進行復制變量名稱。
結果。我們通過準確性來評估我們的方法。它計算精確匹配的分數,除了我們調整連接和分離子句的順序以避免虛假錯誤,就像以前的所有工作一樣。我們沒有測量 BLEU,因為它沒有用于現有的研究。
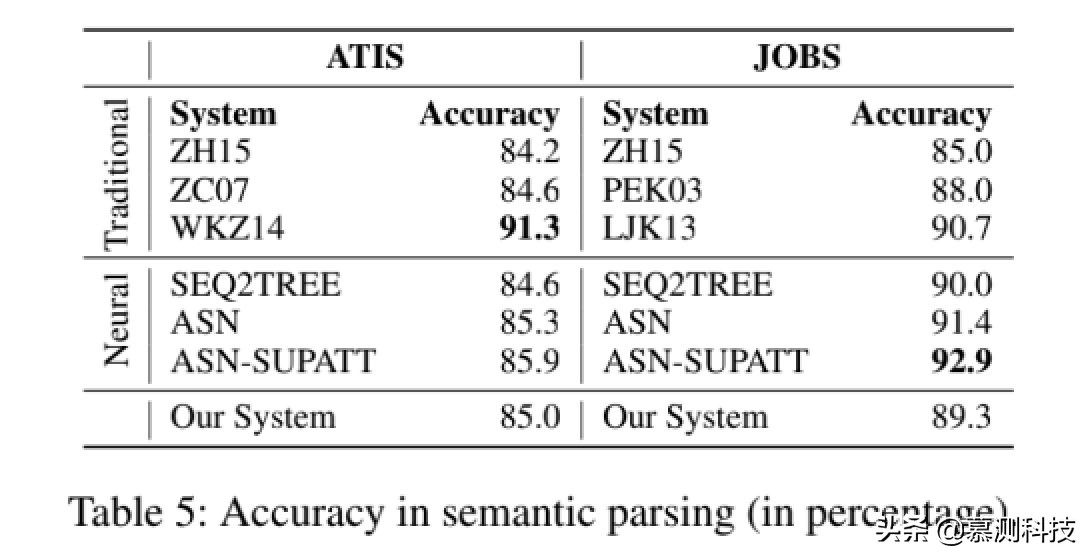
表 5 顯示了我們模型的性能。我們還看到我們基于語法的結構 CNN 編碼器可達到與最新的神經網絡相似的結果拉爾模型。還應該指出,在語義上解析,我們無法像《爐石傳說》代碼生成。這可能是因為語義解析的邏輯形式通常很短,包含像《爐石傳說》中一樣只處理 1/4–1/3 個 token,因此 RNN 和 CNN 適合生成邏輯表格。這個實驗提供了泛化的其他證據,自從我們創建 CNN 代碼以來,我們的能力和靈活性模型基本上是為長程序設計的(例如《爐石傳說》)但也可以與語義解析一起很好地工作。
結論
在本文中,我們提出了一種基于語法的結構 CNN 用于代碼生成。我們的模型利用了抽象程序的語法樹(AST),并通過規定語法規則。我們解決了基于 RNN 的傳統方法可能不適合于克生成,可能是由于大量的程序中的 kens/nodes。因此,我們設計了 CNN 編碼器-基于 AST 結構的解碼器模型。我們在《爐石傳說》數據集上的主要實驗顯示我們取得了比以前的基于 RNN 的方法。的其他實驗兩個語義解析任務證明了魯棒性我們的方法。我們還進行了深度消融測試,以驗證模型中每個組件的有效性。
致謝
本文由南京大學軟件學院 iSE 實驗室 2020 級碩士研究生張晶翻譯轉述。