













明明加了索引,為什么查詢還是慢?
原創【51CTO.com原創稿件】小李今天剛上班就收到客戶的反饋,說查詢用戶信息會非常的慢,有時甚至會出現超時的現象。
圖片來自 Pexels
小李這就納悶了分明已經給表加上了索引為什么還這么慢呢。小李分析了好久都沒分析出原因,于是只能找到同部門的掃地僧大林子。
大林子一邊聽著小李的描述一邊看著項目,就在小李剛把問題描述完大林子就對小李說:“問題解決了”,小李震驚不已,問道:“這么 6,是什么原因導致的呢?分明我已經加了索引了啊?”
大林子說:“這是很多開發人員很容易忽視的問題......”聽完大林子的講解小李瞬間茅塞頓開。那么具體什么原因呢,下面我就給大家講解一下。
原因講解
首先,我們來創建一個存儲引擎為 InnoDB 的 User 表,這個表包含三個字段分別是 id,name 和 age。
其中 id 為主鍵 name 上添加了一個普通索引名字叫 n,接著我們像這條表中插入 10 億條數據。
表和數據都創建完了,下面我們就來說說為什么加上了索引還是查詢很慢,以及解決方案。
MySQL 會根據語句的執行時間來判斷 SQL 語句是否是慢查詢語句。
當一個 SQL 語句在執行時,MySQL 把語句執行時間和系統參數 long_query_time(這個參數的默認值是 10 秒,但是在實際項目中我們會將這個參數值設置為1秒甚至更短的時間) 作比較。
如果執行時間大于這個參數的值,那么就把這個語句記錄到慢查詢日志中。那么在語句執行過程中我們如何得知是否使用了索引呢?
這時我們就可以使用 explain 語句來查看數據結果中 Key 的值是否 null ,如果是 null 則說明沒有使用索引。
下面我們來看一個例子:
- explain select * from user;
- explain select * from user where id=1;
- explain select name from user;
上面三個 explain 語句返回的 key 如下表所示:
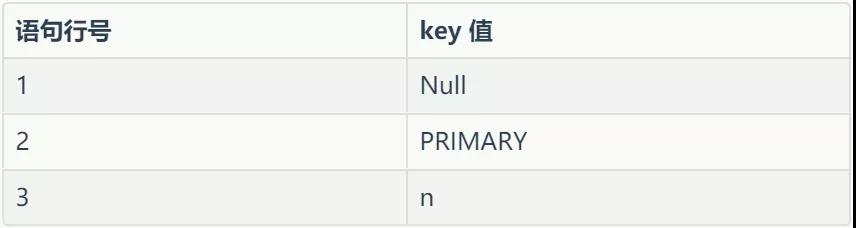
從上表我們可以看出第一個語句沒有使用索引,第二個使用了主鍵索引,第三個語句使用 n 這個索引。
我們的 user 表有 10 億條數據,可想而知第一條查詢語句執行效率肯定低,第二個查詢語句看似執行效率高,其實在極端環境下(比如 CPU 高負載)也會出現查詢效率低的問題。
最后一個查詢語句呢雖然使用了 n 這個索引,但是它實際上執行了掃描整個索引樹的操作,因此查詢效率也高不到哪去。
綜上所述,我們可知索引是否使用和是否被記錄到慢查詢中幾乎沒有聯系,索引只是 SQL 的一個執行過程,SQL 的執行時間才是決定是否被記錄到慢查詢中的關鍵。
前面一小節我們只是簡單的分析了一下問題,下面我們進一步看這個問題。我們知道 InnoDB 是索引組織表,所有數據都存儲在索引樹上。
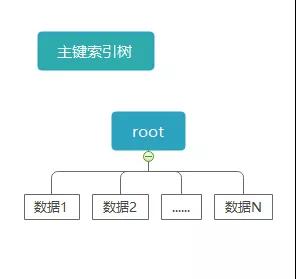
在 InnoDB 中數據放在主鍵索引里,因此理論上來說所有在 InnoDB 表中的查詢至少使用了一個索引。
比如這個 SQL 查詢語句 select * from user where id > 1000,很明顯它使用主鍵索引,并且這個語句一定執行了整個索引樹的掃描。
在 InnoDB 中只有一種情況叫不使用索引,就是從主鍵索引的最左邊的葉子結點開始向右掃描整個索引樹。
到目前為止我們已經知道了全索引掃描會造成查詢變慢,下面我們就來說一下另一個知識點過濾性 。
假如我們要查詢 user 表中 age 在 70 歲以上 80 歲以下的人員信息,你一定會在 age 字段上加入索引來避免全局掃描。
不錯,這是個好的想法,但是當你運行查詢語句時就會發現它依然執行的很慢,這是為什么呢?
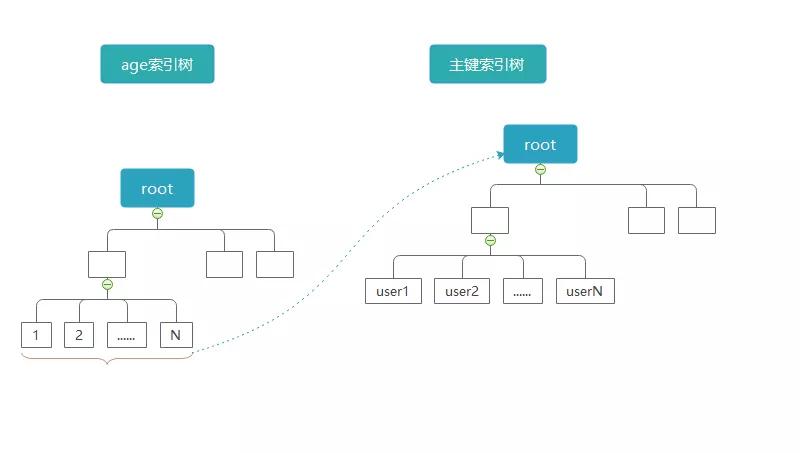
要解答這個問題我們先來看一下 SQL 查詢語句的執行流程:
- 搜索 age 索引樹,獲取到第一個 age 為 70 的記錄。
- 拿到主鍵值,根據主鍵值去主鍵索引樹上獲取對應的信息,并將信息加入結果集。
- 在 age 索引樹上向右側掃描,獲取到下一個主鍵值,執行第二部的操作。
- 不斷執行上面的步驟,直到遇到第一個 age 大于 80 的記錄為止。
從上面的步驟中我們可以看出雖然使用了索引,但是查詢過程中掃描了上萬行甚至上億行。
因此我們可以得出結論:對于這種數據非常多的表,我們所要做的不僅僅是加入索引,還要保證索引的過濾性足夠優秀。
假如說我們把索引的過濾性也處理好了,是不是查詢時要掃描的行數就一定會表少呢?
這個答案是否定的,比如說我們的 user 表中的 name 和 age 字段共同組成了聯合索引并處理好了過濾性,這時當我們查詢姓李的并且年齡是 60 歲的數據時查詢效率依然很低。

我們先來看一下查詢語句的執行流程:
- 首先從聯合索引上找到姓名字段是李字開頭的數據記錄。
- 拿到主鍵值,根據主鍵值在主鍵索引書上去除匹配的數據。
- 接著根據 age 字段去判斷年齡是否等于 60,如果符合就加入結果集。
- 然后再聯合所以上向右側遍歷,并不斷做回表和判斷,直到遇到 name 的第一個字不是李的為止。
Tip:所謂的回表就是根據主鍵值去主鍵索引樹上查找對應的數據。
從上面的步驟中我們可以看出最耗時的就是回表,如果姓李的數據有 2 億條那么就要回表 2 億次,并且 SQL 在定位第一行數據時只能使用最左前綴原則。
這種耗時的回表操作步驟在 MySQL 5.6 及其以后的版本中已經做了 index condition pushdown 優化。
優化后的流程很簡單:
- 首先從聯合索引上找到姓名字段是李字開頭的數據記錄,并判斷這個記錄里 age 是不是 60,如果是就執行回表取出數據假如結果集。
- 重復步驟1,直到配當第一個字不是李字的記錄為止。
優化后和優化前的區別是把 age 的對比步驟放在了遍歷聯合索引樹上,減少了回表次數。
但是雖然減少了回表次數,聯合索引樹的遍歷去沒有減少依然要遍歷 2 億次,那么有沒有更好的優化方案呢?答案是有的,我們可以實虛擬列來進行處理。
首先我們需要把 name 的第一個字和 age 做一個聯合索引,讓虛擬列的值總是等于 name 字段的前兩個字節,這里需要注意的是虛擬列不隨著 insert 和 update 變化,它的值是自定義生成的。
語句如下:
- alter table user add name_first varchar(2) generated (left(name,1)),add index(name_first,age);
經過上述的優化后聯合索引樹的查詢次數也降低了,本質上就是創建一個緊湊的索引加快查詢。
總結
這篇文章主要介紹了查詢優化的基本思路,只要記住優化查詢的過程都是減少掃描行數的過程,就可以做到在 SQL 查詢面前百戰百勝。
作者:朱鋼,筆名喵叔
簡介:.NET 高級開發人員,2019 年度博客之星 20 強,長期從事電子政務系統和AI客服系統的設計與開發,目前就職于國內某 BIM 大廠從事招投標軟件的開發。
編輯:陶家龍
征稿:有投稿、尋求報道意向技術人請聯絡 editor@51cto.com
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】























