14個必須掌握的數據庫面試題(附答案)
一、為什么使用數據索引能提高效率
- 數據索引的存儲是 有序的
- 在有序的情況下, 通過索引查詢一個數據是無需遍歷索引記錄的
- 極端情況下,數據索引的查詢效率為二分法查詢效率,趨近于log2(N)
二、B+樹索引和哈希索引的區別
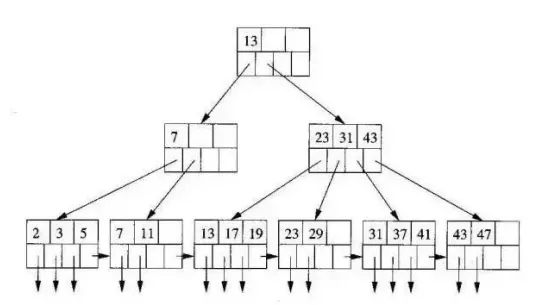
B+樹是一個平衡的多叉樹,從根節點到每個葉子節點的高度差值不超過1,而且同層級的節點間有指針相互鏈接,是有序的,如下圖:
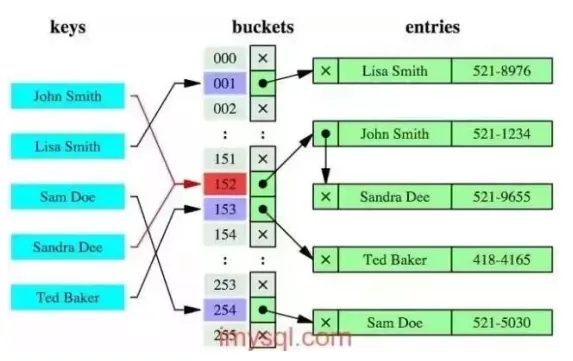
哈希索引就是采用一定的哈希算法,把鍵值換算成新的哈希值,檢索時不需要類似B+樹那樣從根節點到葉子節點逐級查找,只需一次哈希算法即可,是無序的,如下圖所示:
三、哈希索引的優勢:
等值查詢,哈希索引具有絕對優勢(前提是:沒有大量重復鍵值,如果大量重復鍵值時,哈希索引的效率很低,因為存在所謂的哈希碰撞問題。
四、哈希索引不適用的場景:
- 不支持 范圍查詢
- 不支持索引完成排序
- 不支持聯合索引的最左前綴匹配規則
五、什么是表分區?
表分區,是指根據一定規則,將數據庫中的一張表分解成多個更小的,容易管理的部分。從邏輯上看,只有一張表,但是底層卻是由多個物理分區組成
六、表分區與分表的區別?
分表:指的是通過一定規則, 將一張表分解成多 張不同的表。比如將用戶訂單記錄根據時間成多個表。
分表與分區的區別在于:分區從邏輯上來講只有一張表 ,而分表則是將一張表分解成多張表。
七、表分區有什么好處?
- 存儲更多數據。分區表的數據可以分布在不同的物理設備上,從而高效地利用多個硬件設備。和單個磁盤或者文件系統相比,可以存儲更多數據
- 優化E詢。在where語句中包含分區條件時,可以只掃描一個或多 個分區表來提高查詢效率;涉及sum和count語句時,也可以在多個分區上并行處理,最后匯總結果。
- 分區表更容易維護。例如:想批量刪除大量數據可以清除整個分區。
- 避免某些特殊的瓶頸,例如InnoDB的單個索引的互斥訪問, ext3問價你系統的inode鎖競爭等。
八、在MVCC并發控制中,讀操作可以分成兩類:
快照讀(snapshot read):讀取的是記錄的可見版本(有可能是歷史版本),不用加鎖(共享讀鎖s鎖也不加,所以不會阻塞其他事務的寫)
當前讀(currentread):讀取的是記錄的最新版本,并且,當前讀返回的記錄,都會加上鎖,保證其他事務不會再并發修改這條記錄
九、行級鎖定的優點:
- 當在許多線程中訪問不同的行時只存在少量鎖定沖突。
- 回滾時只有少量的更改
- 可以長時間鎖定單一的行。
十、行級鎖定的缺點:
比頁級或表級鎖定占用更多的內存。當在表的大部分中使用時,比頁級或表級鎖定速度慢,因為你必須獲取更多的鎖。 如果你在大部分數據上經常進行GROUP BY操作或者必須經常掃描整個表,比其它鎖定明顯慢很多。 用高級別鎖定,通過支持不同的類型鎖定,你也可以很容易地調節應用程序,因為其鎖成本小于行級鎖定。
十一、MySQL優化
- 開啟查詢緩存,優化查詢
- explain你的select查詢, 這可以幫你分析你的查詢語句或是表結構的性能瓶頸。EXPLAIN的查詢結果還會告訴你你的索引 主鍵被如何利用的,你的數據表是如何被搜索和排序的
- 當只要一行數據時使用limit 1, MySQL數據庫引擎會在找到一條數據后停止搜索,而不是繼續往后查少下一條符合記錄的數據
- 為搜索字段建索引
- 使用ENUM而不是VARCHAR
- Prepared StatementsPrepared Statements很像存儲過程,是一種運行在后臺的SQL語句集合,我們可以從使用
prepared statements獲得很多好處,無論是性能問題還是安全問題。
Prepared Statements可以檢查一些你綁定好的變量,這樣可以保護你的程序不會受到“SQL注入式” 攻擊
- 垂直分表
- 選擇正確的存儲引擎
十二、key和index的區別
key是數據庫的物理結構,它包含兩層意義和作用,一是約束(偏 重于約束和規范數據庫的結構完整性) ,二是索引(輔助查詢 用的)。包括primary key, unique key, foreign key等
index是數據庫的物理結構,它只是輔助查詢的,它創建時會在另外的表空間(mysql中的innodb表空間) 以-個類似目錄的結 構存儲。索引要分類的話,分為前綴索引、全文本索引等;
十三、Mysql 中MyISAM和InnoDB的區別有哪些?
- InnoDB支持事務, MyISAM不支持
- InnoDB支持外鍵,而MylSAM不支持。對一個包含外鍵的InnoDB表轉為MYISAM會失敗;
- InnoDB是聚集索引,數據文件是和索引綁在一起,必須要有主鍵,通過主鍵索引效率高。
- InnoDB不保存 表的具體行數,執行select count(*) from table時需要全表掃描。
- Innodb不支持全文索引,而MyISAM支持全文索引,查詢效率上MyISAM要高;
十四、數據庫表創建注意事項
1、字段名及字段配制合理性
- 剔除關系不密切的字段; 1字段命名要有規則及相對應的含義(不要一部分英文,一部分拼音,還有類似a.b.c這樣不明含義的字段) ;
- 字段命名盡量不要使用縮寫(大多數縮寫都不能明確字段含義) ;
- 字段不要大小寫混用(想要具有可讀性,多個英文單詞可使用下劃線形式連接) ;
- 字段名 不要使用保留字或者關鍵字;
- 保持字段名和類型的一致性;
- 慎重選擇數字類型; 給文本字段留足余量;
2、系統特殊字段處理及建成后建議
- 添加刪除標記(例如操作人、刪除時間) ;
- 建立版本機制;
3、表結構合理性配置
- 多型字段的處理 ,就是表中是否存在字段能夠分解成更小獨立的幾部分(例如:人可以分為男人和女人) ;
- 多值字段的處理,可以將表分為三張表,這樣使得檢索和排序更加有調理,且保證數據的完整性!
4、其它建議
- 對于大數據字段,獨立表進行存儲,以便影響性能(例如:簡介字段) ;
- 使用varchar類 型代替char,因為varchar 會動態分配長度,char指定長度是固定的; 給表創建主鍵,對于沒有主鍵的表,在查詢和索引定義上有一定的影響;
- 避免表字段運行為null,建議設置默認值(例如: int類型設置默認值為0) 在索引查詢上,效率立顯; 1建立索引,最好建立在唯-和非空的字段上,建立太多的索引對后期插入、更新都存在一定的影響(考慮實際情況來創建) ;