













手把手教Linux驅動8-Linux IO模型
什么是IO?
IO模型中,先討論下什么是IO?
在計算機系統中I/O就是輸入(Input)和輸出(Output)的意思,針對不同的操作對象,可以劃分為磁盤I/O模型,網絡I/O模型,內存映射I/O, Direct I/O、數據庫I/O等,只要具有輸入輸出類型的交互系統都可以認為是I/O系統,也可以說I/O是整個操作系統數據交換與人機交互的通道,這個概念與選用的開發語言沒有關系,是一個通用的概念。
在如今的系統中I/O卻擁有很重要的位置,現在系統都有可能處理大量文件,大量數據庫操作,而這些操作都依賴于系統的I/O性能,也就造成了現在系統的瓶頸往往都是由于I/O性能造成的。因此,為了解決磁盤I/O性能慢的問題,系統架構中添加了緩存來提高響應速度;或者有些高端服務器從硬件級入手,使用了固態硬盤(SSD)來替換傳統機械硬盤;一個系統的優化空間,往往都在低效率的I/O環節上,很少看到一個系統CPU、內存的性能是其整個系統的瓶頸。
那么數據被Input到哪,Output到哪呢?
Input(輸入)數據到內存中,Output(輸出)數據到IO設備(磁盤、網絡等需要與內存進行數據交互的設備)中;
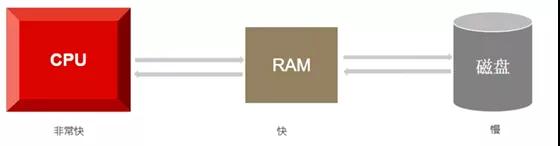
主存(通常時DRAM)的一塊區域,用來緩存文件系統的內容,包含各種數據和元數據。
IO接口
IO設備與內存直接的數據傳輸通過IO接口,操作系統封裝了IO接口,我們編程時可以直接使用;
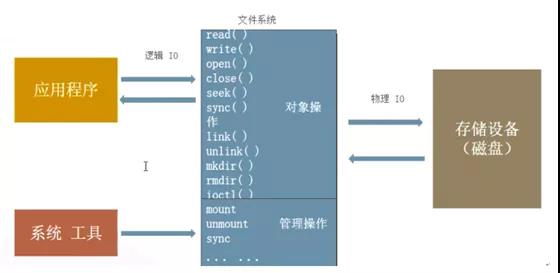
對于用來講,如果要和外設通信,只需要通過這些系統調用即可實現。
無處不在的緩存
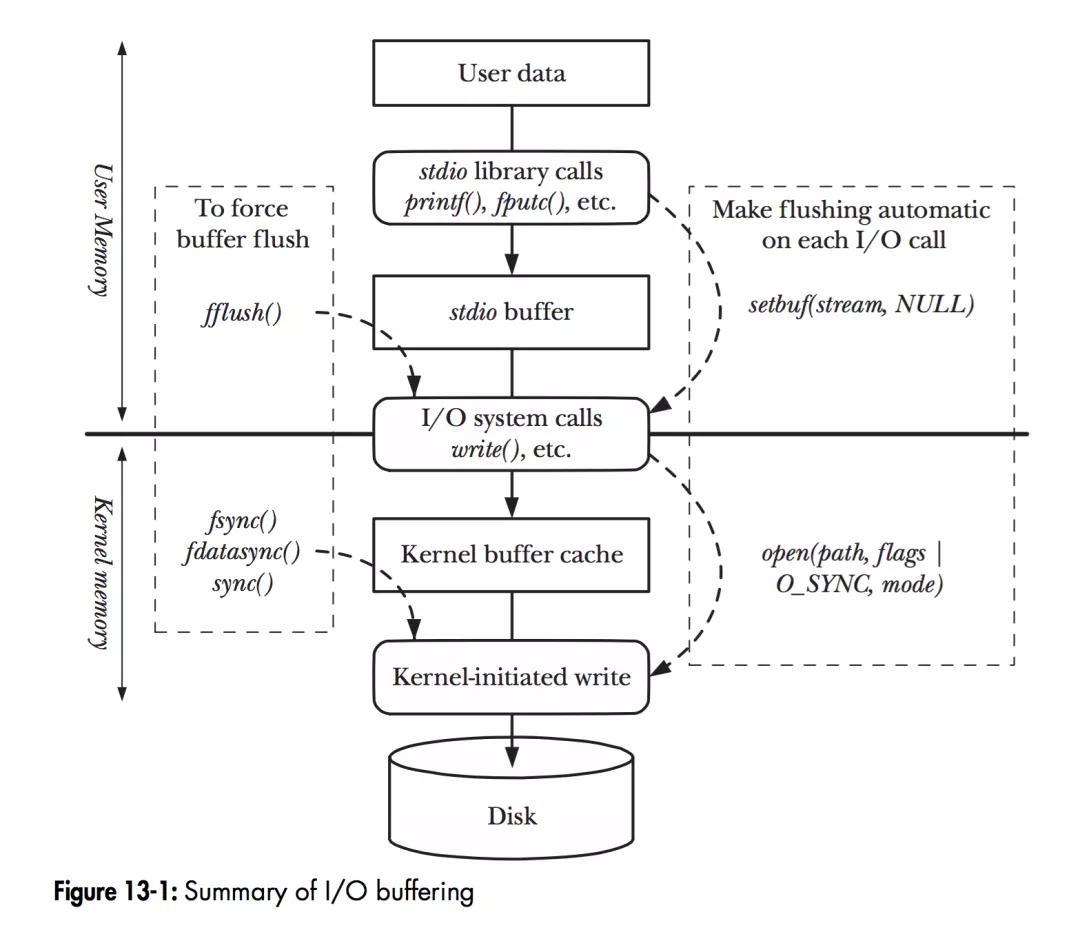
- 如圖,當程序調用各類文件操作函數后,用戶數據(User Data)到達磁盤(Disk)的流程如圖所示。圖中描述了Linux下文件操作函數的層級關系和內存緩存層的存在位置。中間的黑色實線是用戶態和內核態的分界線。
- 從上往下分析這張圖,首先是C語言stdio庫定義的相關文件操作函數,這些都是用戶態實現的跨平臺封裝函數。stdio中實現的文件操作函數有自己的stdio buffer,這是在用戶態實現的緩存。此處使用緩存的原因很簡單——系統調用總是昂貴的。如果用戶代碼以較小的size不斷的讀或寫文件的話,stdio庫將多次的讀或者寫操作通過buffer進行聚合是可以提高程序運行效率的。stdio庫同時也支持fflush(3)函數來主動的刷新buffer,主動的調用底層的系統調用立即更新buffer里的數據。特別地,setbuf(3)函數可以對stdio庫的用戶態buffer進行設置,甚至取消buffer的使用。
- 系統調用的read(2)/write(2)和真實的磁盤讀寫之間也存在一層buffer,這里用術語Kernel buffer cache來指代這一層緩存。在Linux下,文件的緩存習慣性的稱之為Page Cache,而更低一級的設備的緩存稱之為Buffer Cache. 這兩個概念很容易混淆,這里簡單的介紹下概念上的區別:Page Cache用于緩存文件的內容,和文件系統比較相關。文件的內容需要映射到實際的物理磁盤,這種映射關系由文件系統來完成;Buffer Cache用于緩存存儲設備塊(比如磁盤扇區)的數據,而不關心是否有文件系統的存在(文件系統的元數據緩存在Buffer Cache中)。
- 綜上,既然討論Linux下的IO操作,自然是跳過stdio庫的用戶態這一堆東西,直接討論系統調用層面的概念了。對stdio庫的IO層有興趣的同學可以自行去了解。從上文的描述中也介紹了文件的內核級緩存是保存在文件系統的Page Cache中的。所以后面的討論基本上是討論IO相關的系統調用和文件系統Page Cache的一些機制。
Linux IO棧
雖然我們通過系統調用就可以簡單的實現對外設的數據讀取,實際上這得益于Linux完整的IO棧架構。
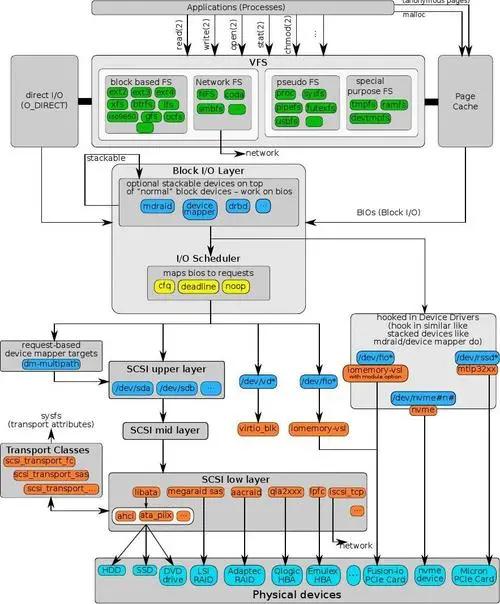
由圖可見,從系統調用的接口再往下,Linux下的IO棧致大致有三個層次:
- 文件系統層,以 write(2) 為例,內核拷貝了write(2)參數指定的用戶態數據到文件系統Cache中,并適時向下層同步
- 塊層,管理塊設備的IO隊列,對IO請求進行合并、排序(還記得操作系統課程學習過的IO調度算法嗎?)
- 設備層,通過DMA與內存直接交互,完成數據和具體設備之間的交互
結合這個圖,想想Linux系統編程里用到的Buffered IO、mmap(2)、Direct IO。
這些機制怎么和Linux IO棧聯系起來呢?
上面的圖有點復雜,畫一幅簡圖,把這些機制所在的位置添加進去:
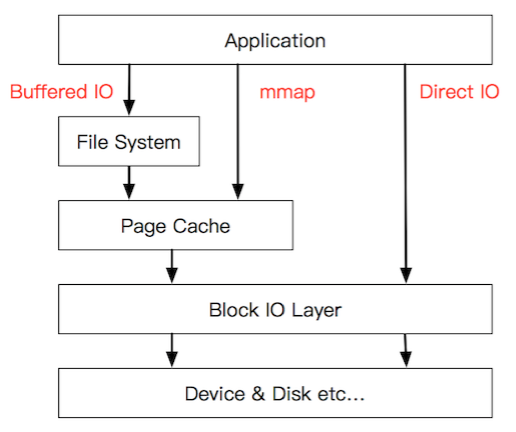
傳統的Buffered IO使用read(2)讀取文件的過程什么樣的?
假設要去讀一個冷文件(Cache中不存在),open(2)打開文件內核后建立了一系列的數據結構,接下來調用read(2),到達文件系統這一層,發現Page Cache中不存在該位置的磁盤映射,然后創建相應的Page Cache并和相關的扇區關聯。然后請求繼續到達塊設備層,在IO隊列里排隊,接受一系列的調度后到達設備驅動層,此時一般使用DMA方式讀取相應的磁盤扇區到Cache中,然后read(2)拷貝數據到用戶提供的用戶態buffer中去(read(2)的參數指出的)。
整個過程有幾次拷貝?
從磁盤到Page Cache算第一次的話,從Page Cache到用戶態buffer就是第二次了。
而mmap(2)做了什么?
mmap(2)直接把Page Cache映射到了用戶態的地址空間里了,所以mmap(2)的方式讀文件是沒有第二次拷貝過程的。
那Direct IO做了什么?
這個機制更狠,直接讓用戶態和塊IO層對接,直接放棄Page Cache,從磁盤直接和用戶態拷貝數據。
好處是什么?
寫操作直接映射進程的buffer到磁盤扇區,以DMA的方式傳輸數據,減少了原本需要到Page Cache層的一次拷貝,提升了寫的效率。
對于讀而言,第一次肯定也是快于傳統的方式的,但是之后的讀就不如傳統方式了(當然也可以在用戶態自己做Cache,有些商用數據庫就是這么做的)。
除了傳統的Buffered IO可以比較自由的用偏移+長度的方式讀寫文件之外,mmap(2)和Direct IO均有數據按頁對齊的要求,Direct IO還限制讀寫必須是底層存儲設備塊大小的整數倍(甚至Linux 2.4還要求是文件系統邏輯塊的整數倍)。所以接口越來越底層,換來表面上的效率提升的背后,需要在應用程序這一層做更多的事情。所以想用好這些高級特性,除了深刻理解其背后的機制之外,也要在系統設計上下一番功夫。
阻塞/非阻塞與同步/異步
了解了IO的概念,現在我們來講解什么是阻塞、非阻塞、同步、異步。
阻塞/非阻塞
針對的對象是調用者自己本身的情況
阻塞
指調用者在調用某一個函數后,一直在等待該函數的返回值,線程處于掛起狀態。
非阻塞
指調用者在調用某一個函數后,不等待該函數的返回值,線程繼續運行其他程序(執行其他操作或者一直遍歷該函數是否返回了值)
同步/異步
針對的對象是被調用者的情況
同步
指的是被調用者在被調用后,操作完函數所包含的所有動作后,再返回返回值
異步
指的是被調用者在被調用后,先返回返回值,然后再進行函數所包含的其他動作。
五種IO模型
下面以recvfrom/recv函數為例,這兩個函數都是操作系統的內核函數,用于從(已連接)socket上接收數據,并捕獲數據發送源的地址。
recv函數原型:
- ssize_t recv(int sockfd, void *buff, size_t nbytes, int flags)
- sockfd:接收端套接字描述符
- buff:用來存放recv函數接收到的數據的緩沖區
- nbytes:指明buff的長度
- flags:一般置為0
網絡IO的本質是socket的讀取,socket在linux系統被抽象為流,IO可以理解為對流的操作。對于一次IO訪問(以read舉例),數據會先被拷貝到操作系統內核的緩沖區中,然后才會從操作系統內核的緩沖區拷貝到應用程序的地址空間。
所以說,當一個recv操作發生時,它會經歷兩個階段:
- 第一階段:等待數據準備 (Waiting for the data to be ready)。
- 第二階段:將數據從內核拷貝到進程中 (Copying the data from the kernel to the process)。
對于socket流而言:
- 第一步:通常涉及等待網絡上的數據分組到達,然后被復制到內核的某個緩沖區。
- 第二步:把數據從內核緩沖區復制到應用進程緩沖區。
阻塞IO(Blocking IO)
指調用者在調用某一個函數后,一直在等待該函數的返回值,線程處于掛起狀態。好比你去商場試衣間,里面有人,那你就一直在門外等著。(全程阻塞)
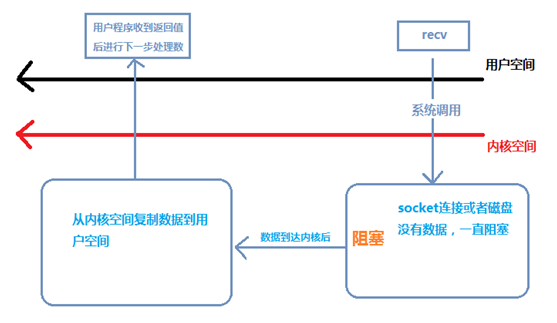
BIO程序流
當用戶進程調用了recv()/recvfrom()這個系統調用,kernel就開始了IO的第一個階段:準備數據(對于網絡IO來說,很多時候數據在一開始還沒有到達。比如,還沒有收到一個完整的UDP包。這個時候kernel就要等待足夠的數據到來)。這個過程需要等待,也就是說數據被拷貝到操作系統內核的緩沖區中是需要一個過程的。而在用戶進程這邊,整個進程會被阻塞(當然,是進程自己選擇的阻塞)。
第二個階段:當kernel一直等到數據準備好了,它就會將數據從kernel中拷貝到用戶內存,然后kernel返回結果,用戶進程才解除block的狀態,重新運行起來。
所以,blocking IO的特點就是在IO執行的兩個階段都被block了。
優點:
1. 能夠及時返回數據,無延遲;
2. 對內核開發者來說這是省事了;
缺點:
對用戶來說處于等待就要付出性能的代價了;
非阻塞IO
指調用者在調用某一個函數后,不等待該函數的返回值,線程繼續運行其他程序(執行其他操作或者一直遍歷該函數是否返回了值)。好比你要喝水,水還沒燒開,你就隔段時間去看一下飲水機,直到水燒開為止。(復制數據時阻塞)
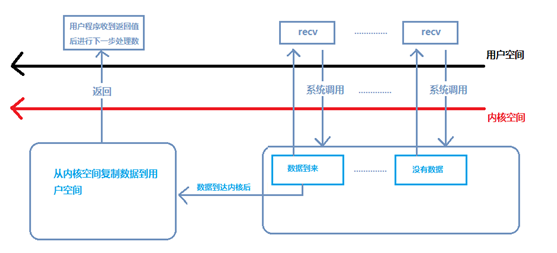
非阻塞IO程序流
當用戶進程發出read操作時,如果kernel中的數據還沒有準備好,那么它并不會block用戶進程,而是立刻返回一個error。從用戶進程角度講,它發起一個read操作后,并不需要等待,而是馬上就得到了一個結果。用戶進程判斷結果是一個error時,它就知道數據還沒有準備好,于是它可以再次發送read操作。一旦kernel中的數據準備好了,并且又再次收到了用戶進程的system call,那么它馬上就將數據拷貝到了用戶內存,然后返回。
所以,nonblocking IO的特點是用戶進程需要不斷的主動詢問kernel數據好了沒有。
同步非阻塞方式相比同步阻塞方式:
優點:
能夠在等待任務完成的時間里干其他活了(包括提交其他任務,也就是 “后臺” 可以有多個任務在同時執行)。
缺點:
任務完成的響應延遲增大了,因為每過一段時間才去輪詢一次read操作,而任務可能在兩次輪詢之間的任意時間完成。這會導致整體數據吞吐量的降低。
IO多路復用
I/O是指網絡I/O,多路指多個TCP連接(即socket或者channel),復用指復用一個或幾個線程。意思說一個或一組線程處理多個連接。比如課堂上學生做完了作業就舉手,老師就下去檢查作業。(對一個IO端口,兩次調用,兩次返回,比阻塞IO并沒有什么優越性;關鍵是能實現同時對多個IO端口進行監聽,可以同時對多個讀/寫操作的IO函數進行輪詢檢測,直到有數據可讀或可寫時,才真正調用IO操作函數。)
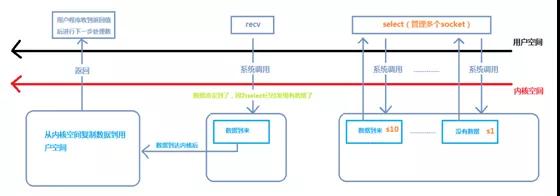
IO多路復用程序流
這種模型其實和BIO是一模一樣的,都是阻塞的,只不過在socket上加了一層代理select,select可以通過監控多個socekt是否有數據,通過這種方式來提高性能。
一旦檢測到一個或多個文件描述有數據到來,select函數就返回,這時再調用recv函數(這塊也是阻塞的),數據從內核空間拷貝到用戶空間,recv函數返回。
多路復用的特點是通過一種機制一個進程能同時等待IO文件描述符,內核監視這些文件描述符(套接字描述符),其中的任意一個進入讀就緒狀態,select, poll,epoll函數就可以返回。對于監視的方式,又可以分為 select, poll, epoll三種方式。
IO多路復用是阻塞在select,epoll這樣的系統調用之上,而沒有阻塞在真正的I/O系統調用如recvfrom之上。
在I/O編程過程中,當需要同時處理多個客戶端接入請求時,可以利用多線程或者I/O多路復用技術進行處理。I/O多路復用技術通過把多個I/O的阻塞復用到同一個select的阻塞上,從而使得系統在單線程的情況下可以同時處理多個客戶端請求。與傳統的多線程/多進程模型比,I/O多路復用的最大優勢是系統開銷小,系統不需要創建新的額外進程或者線程,也不需要維護這些進程和線程的運行,降底了系統的維護工作量,節省了系統資源,I/O多路復用的主要應用場景如下:
1. 服務器需要同時處理多個處于監聽狀態或者多個連接狀態的套接字。
2. 服務器需要同時處理多種網絡協議的套接字。
在用戶進程進行系統調用的時候,他們在等待數據到來的時候,處理的方式不一樣,直接等待,輪詢,select或poll輪詢,兩個階段過程:
第一個階段有的阻塞,有的不阻塞,有的可以阻塞又可以不阻塞。
第二個階段都是阻塞的。
從整個IO過程來看,他們都是順序執行的,因此可以歸為同步模型(synchronous)。都是進程主動等待且向內核檢查狀態。
信號驅動IO
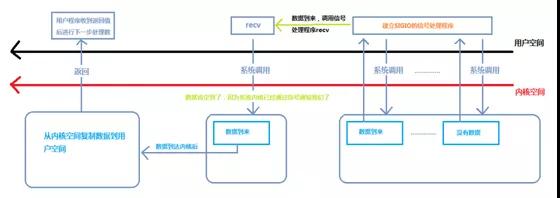
信號驅動IO程序流
在用戶態程序安裝SIGIO信號處理函數(用sigaction函數或者signal函數來安裝自定義的信號處理函數),即recv函數。然后用戶態程序可以執行其他操作不會被阻塞。
一旦有數據到來,操作系統以信號的方式來通知用戶態程序,用戶態程序跳轉到自定義的信號處理函數。
在信號處理函數中調用recv函數,接收數據。數據從內核空間拷貝到用戶態空間后,recv函數返回。recv函數不會因為等待數據到來而阻塞。
這種方式使異步處理成為可能,信號是異步處理的基礎。
在 Linux 中,通知的方式是信號:
如果這個進程正在用戶態忙著做別的事,那就強行打斷之,調用事先注冊的信號處理函數,這個函數可以決定何時以及如何處理這個異步任務。由于信號處理函數是突然闖進來的,因此跟中斷處理程序一樣,有很多事情是不能做的,因此保險起見,一般是把事件 “登記” 一下放進隊列,然后返回該進程原來在做的事。
如果這個進程正在內核態忙著做別的事,例如以同步阻塞方式讀寫磁盤,那就只好把這個通知掛起來了,等到內核態的事情忙完了,快要回到用戶態的時候,再觸發信號通知。
如果這個進程現在被掛起了,例如無事可做 sleep 了,那就把這個進程喚醒,下次有 CPU 空閑的時候,就會調度到這個進程,觸發信號通知。
異步 API 說來輕巧,做來難,這主要是對 API 的實現者而言的。Linux 的異步 IO(AIO)支持是 2.6.22 才引入的,還有很多系統調用不支持異步 IO。Linux 的異步 IO 最初是為數據庫設計的,因此通過異步 IO 的讀寫操作不會被緩存或緩沖,這就無法利用操作系統的緩存與緩沖機制。
很多人把 Linux 的 O_NONBLOCK 認為是異步方式,但事實上這是前面講的同步非阻塞方式。需要指出的是,雖然 Linux 上的 IO API 略顯粗糙,但每種編程框架都有封裝好的異步 IO 實現。操作系統少做事,把更多的自由留給用戶,正是 UNIX 的設計哲學,也是 Linux 上編程框架百花齊放的一個原因。
異步IO
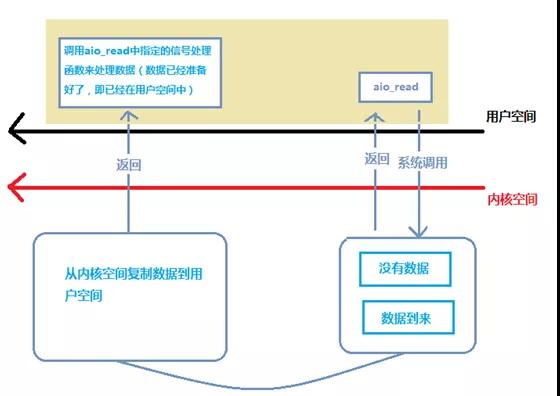
異步IO程序流
異步IO的效率是最高的。
異步IO通過aio_read函數實現,aio_read提交請求,并遞交一個用戶態空間下的緩沖區。即使內核中沒有數據到來,aio_read函數也立刻返回,應用程序就可以處理其他的事情。
當數據到來后,操作系統自動把數據從內核空間拷貝到aio_read函數遞交的用戶態緩沖區。拷貝完成以信號的方式通知用戶態程序,用戶態程序拿到數據后就可以執行后續操作。
異步IO和信號驅動IO的不同?
在于信號通知用戶態程序時數據所處的位置。異步IO已經把數據從內核空間拷貝到用戶空間了;而信號驅動IO的數據還在內核空間,等著recv函數把數據拷貝到用戶態空間。
異步IO主動把數據拷貝到用戶態空間,主動推送數據到用戶態空間,不需要調用recv方法把數據從內核空間拉取到用戶態空間。異步IO是一種推數據的機制,相比于信號處理IO拉數據的機制效率更高。
推數據是直接完成的,而拉數據是需要調用recv函數,調用函數會產生額外的開銷,故效率低。
本文轉載自微信公眾號「一口Linux」,可以通過以下二維碼關注。轉載本文請聯系一口Linux公眾號。














