如何建立公平的AI系統?
人工智能正在各行各業的企業中迅速部署,預計企業在未來三年內將在人工智能系統上的支出增加一倍。但是,AI并不是最容易部署的技術,即使功能齊全的AI系統也可能帶來業務和客戶風險。

近期在信貸、招聘和醫療保健應用中有關AI的新聞報道中強調的主要風險之一是存在潛在的偏見。因此,其中一些公司受到政府機構的監管,以確保其AI模型是公平的。
機器學習模型在實際示例中進行訓練,以模仿未見數據的歷史結果。訓練數據可能由于多種原因而產生偏見,包括代表受保護群體的數據項數量有限以及在整理數據過程中人為偏見潛伏的可能性。不幸的是,對有偏見的數據進行訓練的模型通常會使他們做出的決策中的偏見永存。
確保業務流程的公平性不是一個新的范例。例如,美國政府在1970年代禁止通過公平貸款法(例如《平等信貸機會法》(ECOA)和《公平住房法》(FHAct))對信貸和房地產交易進行歧視。此外,《同酬法》、《民權法》、《康復法》、《就業年齡歧視法》和《移民改革法》都提供了廣泛的保護措施,以防止歧視某些受保護群體。
構建公平的AI需要兩步過程:理解偏見和解決潛在偏差。在本文中,我們將重點討論第一個主題。
了解偏見
在解決問題之前,您需要首先確定其存在。沒有一家公司會以惡意的意圖將其AI系統偏向用戶。取而代之的是,由于模型開發生命周期中缺乏意識和透明性,導致了無意間引入了偏見。
以下列出了最佳實踐,以更好地理解和減少ML開發生命周期中的偏見。
(1) 獲得主要利益相關者的支持
不公平的系統類似于會產生重大業務影響的安全風險。實施公平治理流程需要物質資源。沒有領導團隊的支持,必要的實現該流程所需的任務可能無法獲得超過其他業務優先級的足夠開發能力。因此,強大的以公平為中心的AI流程始于AI所有利益相關者的認同系統,包括管理團隊。
(2) 任命“內部捍衛者”
確保買入后,任命負責建立公平程序的冠軍。倡導者在包括法律和合規代表在內的各個團隊之間進行溝通,以草擬與公司領域(例如,醫療保健、招聘等)和團隊的特定用例(例如,建議重新住院、確定保險費、評估信用度)相關的準則等。有幾種偏見度量標準,例如機會均等、人口統計均等。公平性度量標準的選擇取決于用例,并由從業者掌握。
在最終確定指導方針之后,“捍衛者”將對相關團隊進行培訓。為了使其可行,AI公平工作流程可確保數據和模型偏差。另外,它要求訪問被評估公平性的受保護屬性,例如性別和種族。在大多數情況下,很難收集受保護的屬性,在大多數情況下,直接在模型中使用它們是非法的。
但是,即使未將受保護的屬性用作模型功能,也可能存在代理偏差,另一個數據字段(如郵政編碼)可能會與受保護的屬性(如種族)相關聯。如果沒有保護屬性并對其進行衡量,則很難識別偏差。團隊解決這一差距的一種方法是推斷受保護的屬性,例如在貸款承保模型的情況下使用普查數據推斷性別和種族。
測量偏差
接下來,我們需要測量偏差。不幸的是,許多類型的機器學習模型固有的不透明性使得測量其偏差變得困難。人工智能的可解釋性是一項最新的研究進展,它解鎖了人工智能的黑匣子,使人們可以了解人工智能模型內部發生的事情。這導致對偏差的透明評估,以確保由AI驅動的決策是負責任和可信賴的。
以下是ML模型的公平報告示例:
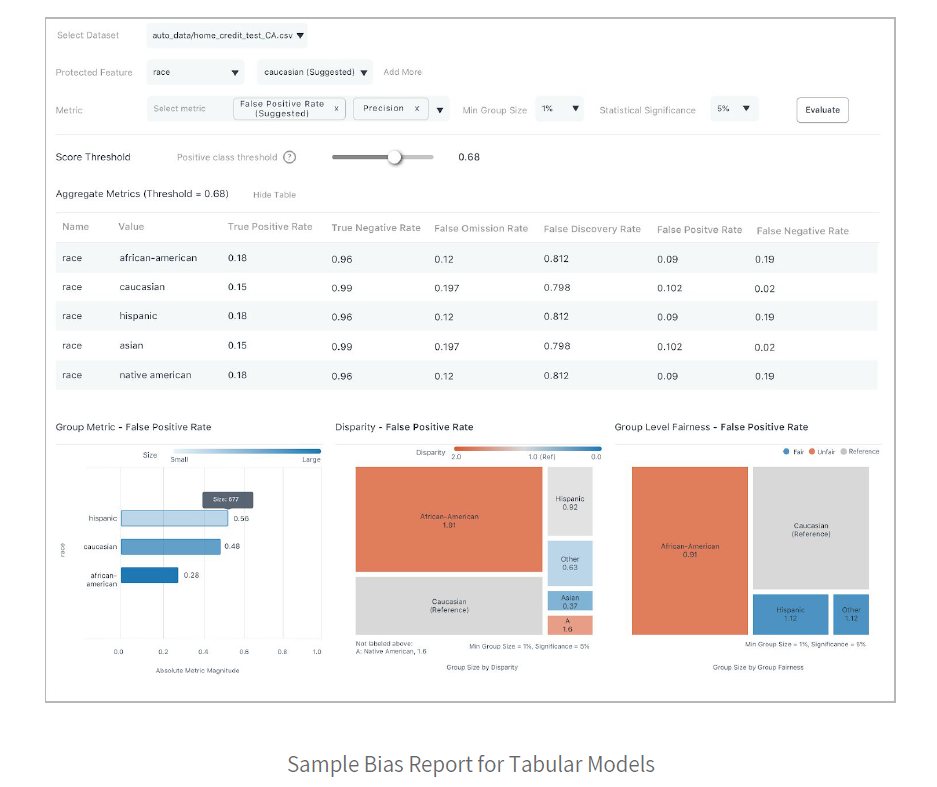
該特定報告是用于評估風險以做出貸款決策的模型。它在受保護的“種族”屬性上具有其他元數據。使用此報告,用戶可以使用各種公平性指標來查看組公平性和不同的影響。建議您根據用例的領域需求,專注于特定指標(例如,“誤報率”)和特定特權類別(例如,白種人)來衡量偏見。
除了上面的貸款模型之類的表格模型外,文本和圖像模型中也會出現偏差。例如,下圖顯示了一個文本模型,該文本模型正在測量用戶生成的注釋的毒性。
下面的樣本偏見報告顯示了該模型如何評估跨種族和宗教階層的毒性。
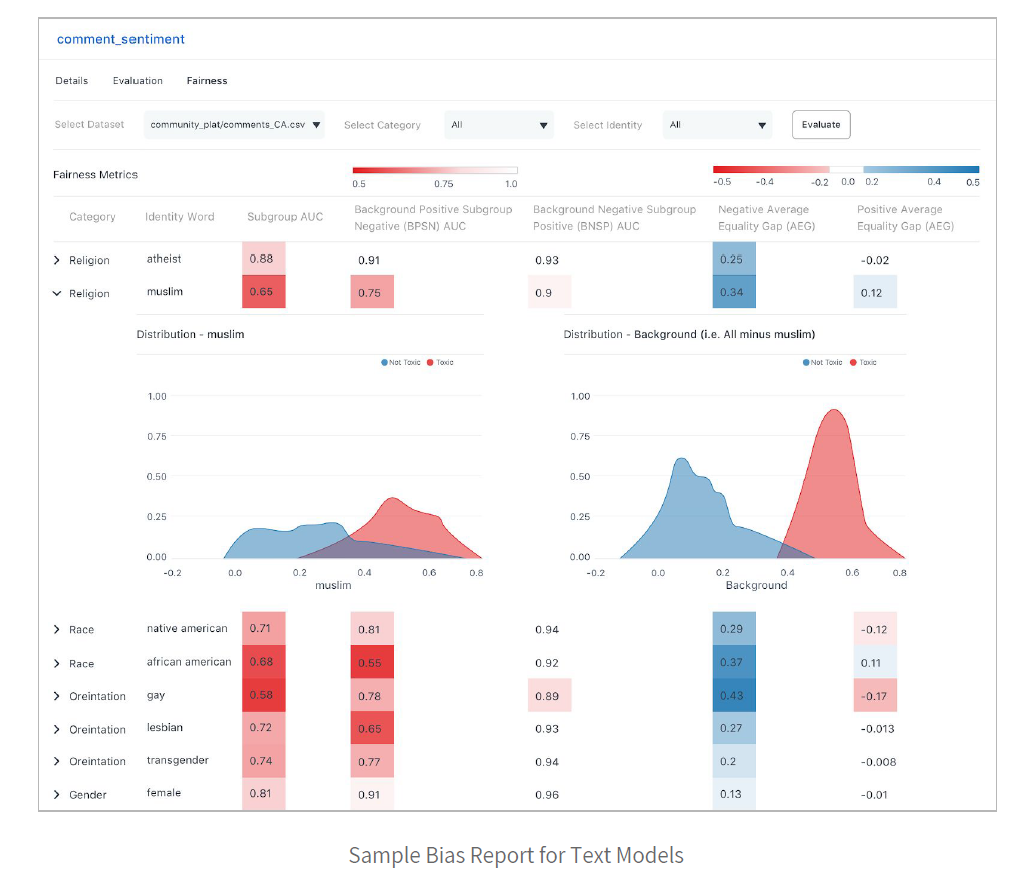
請注意,熱圖如何表明該模型相對于“女性”和“無神論者”身份群體的偏見要小得多。在這種情況下,ML開發人員可能希望將有偏見的身份組的更多代表性示例添加到訓練集中。
生產模型的公平考慮
無論在部署之前是否存在偏差,一旦模型為實時流量提供服務,就有可能發生偏差。偏差的變化通常是由于向部署的模型提供了輸入數據而導致的,這些輸入數據在統計上不同于用于訓練模型的數據。因此,最佳實踐是在部署后監視模型中的相關偏差指標。下面的屏幕截圖描繪了監視模型準確性指標(用于跟蹤潛在偏差的相關指標之一)的外觀。
總之,人工智能為量化和解決迄今為止由人主導和不透明的決策系統中的偏差提供了獨特的機會。