













日均TB級數據,攜程支付統一日志框架
一、背景
支付中心作為攜程集團公共部門,主要負責的業務包括交易、實名綁卡、賬戶、收單等,由于涉及到交易相關的資金流轉以及用戶實名認證,部分用戶操作環節的中間數據應內控/審計要求需要長時間保存。當前研發應用多,日志量大、格式各異,對于日志的存儲和使用產生較大的挑戰,故支付數據與研發團隊群策群力,共同開發了一套統一日志框架。
二、總體架構圖
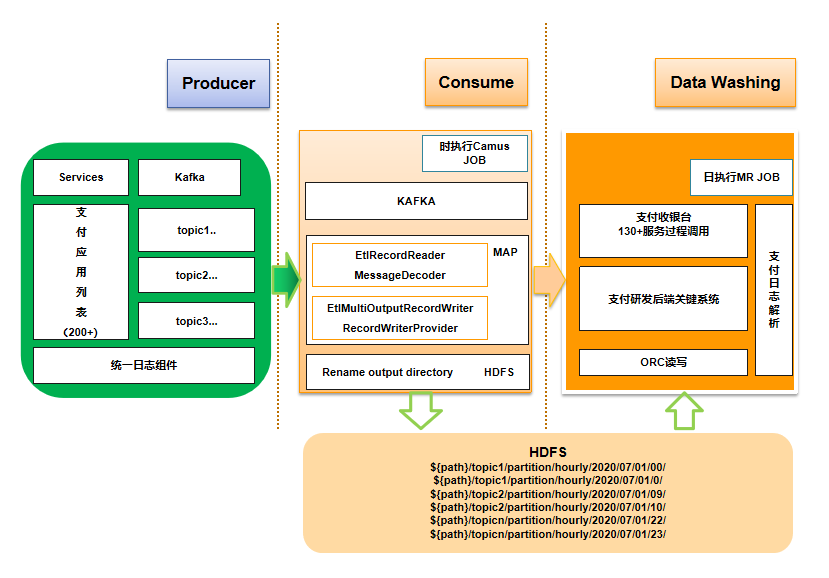
核心模塊包括:日志生產、日志采集、日志解析,其中調用流程如下:
- 研發應用/服務接入基于log4j2擴展的統一日志組件,將日志拋送至kafka。
- 周期性啟動消費kafka topic的camus job將日志寫入hdfs。
- T+1啟動MR job讀取camus寫入的hdfs內容并load到hive表。
三、日志生產-統一日志組件
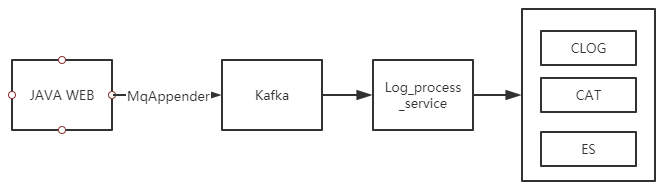
支付研發基于log4j2自定義了多個Appender,將應用日志以服務調用形式拋送至kafka,并被log_process_service 服務統一處理并提交至攜程常用基礎日志框架如:CLOG、CAT、ES,各應用無需關心公司日志框架,統一由日志平臺處理。
其優點:
- 不同日志框架對應著不同的Appender,方便進行日志框架接入的擴展。
- 采用AOP編程,對于接入的業務侵入性小,接入簡單。
- 定義了豐富的java注解,便于日志配置化輸出,其中可打印日志包括但不限于:類名、方法名、方法入參、返回值、異常等,支持敏感字段脫敏。
存在的問題:
- 日志格式不規范:研發應用數百個,研發人員較多,日志格式差異大,給數據分析和使用帶來巨大挑戰。
- 存儲時長短:當前公司在線CLOG存儲系統只能查詢最近幾天數據、ES保存稍長一段時間數據且不支持批量查詢,基礎離線CLOG hive表由于數據量巨大,僅能做到T+2,無法滿足T+1的報表需求。
故支付數據團隊在研發團隊統一日志組件的基礎上,結合數據分析和數據存儲生命周期開發了統一日志框架。
3.1 統一日志-埋點設計
支付研發團隊負責數百個服務或應用,支持的業務包括:路由、鑒權、免密、卡服務、訂單、錢包實名、電子支付等,不同的業務又可拆分app、h5、online、offline等項目,整合這些數據是個極大的挑戰。如果各系統研發埋點任意指定,會給BI數據分析帶來極大的困難,數據分析準確性難以得到保障,故支付數據基于業務特點定義了一套統一日志埋點規范。
字段定義主要是基于日常分析需求,致力于簡化數據的使用,故總體原則為json形式,當前原始日志有兩部分組成:tag/message,其中tag數據結構為Map,關鍵數據一般是通過tag內的數據進行檢索,明細數據通過message進行檢索,tag與message的組成格式為:[[$tag]]$message,目前標準字段包括兩類:規范性字段和通用性字段。
3.1.1 規范性字段格式
規范性字段需要應用研發一定程度的參與,提供符合字段命名的類和方法。部分字段名稱及定義如下:
- 字段名稱字段類型描述serviceNamestring調用服務名稱tagMapkeyvalue信息messagestring原始日志requeststring接口請求參數responsestring接口返回值requesttimestring日志請求時間responsetimestring日志請求時間
其中tag可以靈活填充,主要擴展字段如下:
- 名稱字段類型描述versionstringapp版本號platstring平臺信息refnostring流水號
3.1.2 通用字段格式
- 日志框架能夠自動獲取屬性,無需研發編碼,即可打印。
- 字段名稱字段類型描述applicationidstring攜程應用唯一識別號logtimestring日志生成時間
3.2 分區/分桶字段的定義
當前離線數據分析基于hive引擎,hive的分區分桶設計極大的影響了查詢性能,特別是在日志量巨大的場景下,分區字段的選擇尤為關鍵。如:用戶進入支付收銀臺可能會有上百個場景,而每種場景下會有多次服務調用,其中不同場景下服務調用頻率差異很大,占用的空間差異也較大,故針對每種場景分配一個唯一的場景號,通過場景號進行分區,可以高效的進行數據分析,而過多的分區也可能導致較多的小文件,對hadoop namenode產生較大的影響,此時結合分桶能夠達到優化查詢效率且避免分區無限制野蠻增長產生眾多過多小文件的問題。
四、日志采集
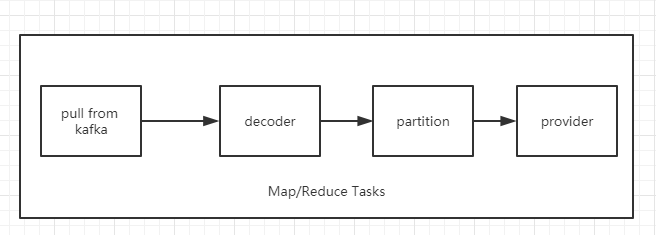
日志采集框架基于LinkedIn的開源項目Camus,Camus使用MapReduce讀取kafka數據然后寫入hdfs,由于無reduce階端,所有數據處理及寫入都在Map側,很少會發生數據傾斜,Camus具有接入簡單,方便擴展,故我們進行了二次開發,以滿足當前業務的需要:
- 自定義decoder/partitioner,原生的decoder/partitioner支持的hdfs落地路徑主要基于日期,較為粗糙,無法適應業務的需要。故自定義decoder 抽取原始日志分區字段,然后代入partitioner中,生成具有業務含義的hdfs輸出路徑,為特定時間范圍數據回刷提供了高效的解決方案。
- 自定義provider,原生的StringRecordWriterProver僅支持text文件方式落地,占用空間大、壓縮后無法并行切分,容易錯列錯行,而orc格式數據,有效的節約了hdfs占用空間,查詢效率高且可以切分,有利于日志解析job的高效執行。其中在配置Camus job過程中需要關注如下問題:
4.1 camus 任務執行
執行頻率設置
- Error: java.io.IOException: target exists.the file size(614490 vs 616553) is not the same.
由于kafka消息保存天數有限和單個分區size有限(Server 配置:log.retention.bytes),攜程側為3天和10G,如果camus同步kafka頻率較低時,可能會出現數據丟失,故需要根據日志量大小,設置camus 調度任務的執行頻率,防止數據丟失。
任務重疊執行
- Error: java.io.IOException: target exists.the file size(614490 vs 616553) is not the same.
camus從kafka 讀取數據,任務要以單例形式執行,任務執行完成后才會更新kafka的offset,若一個任務執行了多次,就會導致數據大小無法對齊,此時需要刪除配置路徑下的所有數據后重新啟動任務,即可完成修復。
4.2 如何控制camus落地文件的大小
當kafka各partition數據寫入量不平衡時,由于各partition會寫入一個hdfs文件中,如果研發日志集中寫入kafka某個partition,會導致這個partition對應的hdfs文件占用空間特別大,如果恰巧這個文件是不可切分的,極端情況下會導致只有一個線程去解析這個大文件,降低了數據讀寫的并發度,拉長了數據解析時間,遇到這種問題的解決辦法是:
- 臨時解決方案:研發日志分散寫入kafka partition,不要導致某類數據集中寫入一個partition;
- 高效解決方案:數據側采用可切分的輸入格式,進行數據切分;
4.3 寫入orc文件格式注意事項
orc寫入timeout
- AttemptID:attempt_1587545556983_2611216_m_000001_0 Timed out after 600 secs
orc文件寫入速度較text文件會慢很多,如果同時寫入的的文件較多或者內存回收占用時間較長,會導致map方法在600秒內沒有讀、寫或狀態更新,job會被嘗試終結,解決方法是調高默認的task超時時間,由10分鐘調高到20分鐘。
- mapreduce.task.timeout=1200000
OOM 內存溢出
- beyond physical memory limits. Current usage: 2.5 GB of 2.5 GB physical memory used; 4.2 GB of 5.3 GB virtual memory used. Killing container.
在orc寫文件的時候如果出行較多的OOM,此時需要加大map執行的內存。
- mapreduce.map.memory.mb=8096
- mapreduce.map.java.opts=-Xmx6000m
五、統一日志-解析

鑒于日志解析工作主要集中在MapReduce的Map側,而Map側通過參數調整能夠很容易控制map的個數,以提高數據解析的并發度,MapReduce主要分為:intputformat、map、shuffle、reduce等幾個核心階段,通過優化各階段的執行時間,可以顯著提高日志解析的速度。
5.1 inputsplit優化
MR job中影響map的個數主要有:
- 文件個數:如果不采用CombineFileInputFormat,那么不會進行小文件合并,每個文件至少有一個map處理,當小文件太多時,頻繁啟動和回收線程也會對性能產生影響,同時對集群其它job資源分配產生影響。
- 文件屬性:當文件較大且可切分時,系統會生成多個map處理大文件,inputsplit塊按照MR最小單元進行文件切割(split),并且一個split對應一個MapTask。
前期日志解析程序的性能較高,一天的全量日志解析約25分鐘,中間有段時間任務執行時間從25分鐘延遲到4個小時,原因是研發將大量訂單號為空的日志寫入到指定的partition中,日志量巨大,導致其中少量map在讀取大文件時執行時間特別長。
經過分析發現text+snappy 文件無法切分,只能夠被一個map處理,將camus落地數據格式從text+snappy換為orc+snappy格式,同時開發了支持orc文件格式的CombineFileInputFormat,既減少了小文件對hadoop計算資源果斷的占用也提高了job的并發程度。
5.2 shuffle優化
使map的輸出能夠更加均勻的映射到reduce側,由于默認的分區策略是對map的輸出key hash取reduce個數的模,容易導致數據傾斜,解決辦法是在key上面增加時間戳或者重寫partition函數。
5.3 批量日志解析
當前MR的輸出會作為hive外表的數據源,hive表會按照業務過程進行分區,所有數據的解析結果路徑為:日期+業務過程,而業務過程可能有數百個,采用了MultipleInputs/MultipleOutputs 能夠在一個mapreduce job中實現多輸入多輸出的功能,以適應業務自定義解析,并歸一化后統一拋到reduce側。
5.3.1 空文件生產
在使用的過程中會出現生成眾多臨時小文件及生成size 為0的小文件,增加了hdfs namenode內存壓力,同時空文件也會導致spark表查詢失敗,可通過LazyOutputFormat進行修復。
5.3.2 文件重復創建
MultipleOutputs輸出文件一般以name-r-nnnnn的格式進行命名,其中name與程序指定的文件名有關,nnnnn表示reduce任務號。在處理數據較多時,可能會存在reduce側反復創建已存在的文件,導致任務長時間運行而不能成功,中間生成了大量小文件,對hadoop namenode產生較大壓力,影響整個集群響應時間。
解決方案為:在reduce側進行數據寫入時,需要對exception進行捕捉,一旦出現數據寫入exception,即將對應的寫入reduce文件刪除并終止程序,由于MR支持高可用,當一個reduce taks 失敗后會自動重試,重試一定次數依然不能夠成功就會導致整個任務失敗,每次重試避免了不停的重復創建已存在的文件,引起NN響應時間極速下降。
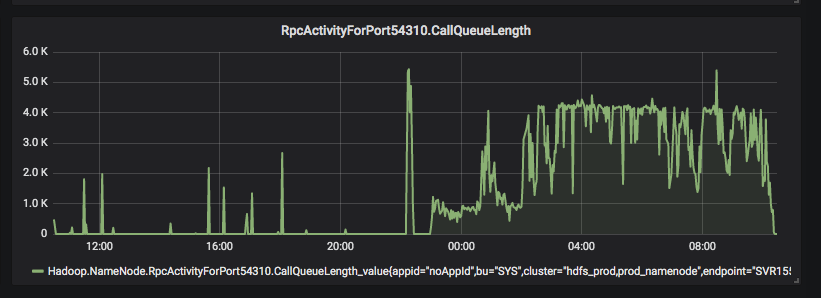
5.4 reduce個數調整
目前日志解析的reduce側主要用于orc數據寫入,當reduce個數較少時,會導致reduce內存溢出,而reduce個數較多時,可能會導致非常多的小文件且占用集群過多資源,可以通過計算map側輸入文件的個數及總占用空間,動態計算需要的reduce個數,以達到合理利用資源的目的。
六、日志治理
日志落地導致的一個問題是存儲空間增長迅速,當前支付中心日均新增ORC壓縮原始數據量TB級別且還在持續增長中。
支付數據側根據研發、產品的需求對不同類型日志進行分級,對于不同類別的日志設置不同的存儲周期,主要劃分為:研發排障日志、審計日志、數據分析日志等;同時在camus將日志寫入hdfs時,由于按照業務分區進行落地,導致生成了大量小文件,需要對這些小文件進行合并并且設置TTL,避免對hadoop namenode產生較大的影響。
七、總結與展望
目前日均TB級數據解析時間在30分鐘內完成,后期計劃將日志系統導入clickhouse等對實時要求高的場景共運營使用,以支持業務精細化運營和分析。
【作者簡介】英明,攜程數據研發專家,負責支付離線數據倉庫建設及BI業務需求,對并行計算、大數據處理及建模等有濃厚興趣。






















