如何管理Kubernetes集群的容量與資源
譯文【51CTO.com快譯】眾所周知,系統資源并非無限的。在那些大型集群即服務的場景中,我們需要認真地布局和規劃集群資源的配比。不過,在各種軟件項目中,開發人員往往會錯誤地認為虛擬化和容器化能夠讓資源看起來更像個巨大的池子,可用隨意使用。例如,他們在嘗試運行某個需要大量資源的應用,尤其是在啟用了自動擴展功能的群集上時,就可能看到如下圖所示的情況:
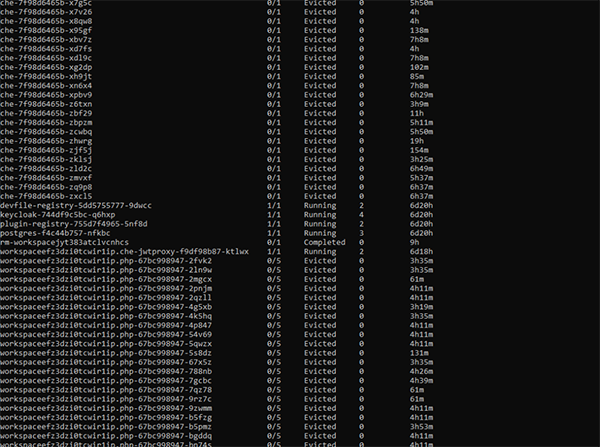
顯然,通過kubectl get,我們發現有數十個evicted pod,而實際上可能只想運行5個pod。此時,您可能非常希望通過對Kubernetes集群資源的管理,來自動實現對于容量和資源的分配。
兩個示例
如上圖所示,假設我們手頭有一個帶有16個虛擬CPU和64GB RAM的Kubernetes集群。那么,我們可以在它上面流暢地運行一個需要20GB內存的AI容器嗎?
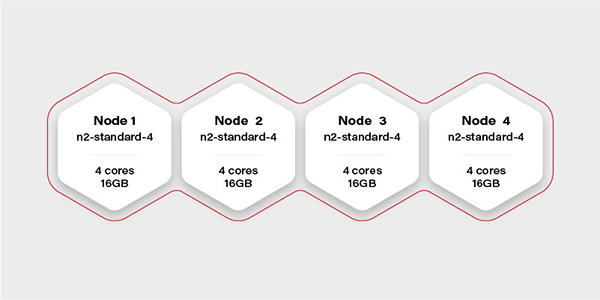
假設該集群中有4個worker,每個都需要有16GB的可用內存(實際上,DaemonSet和系統服務都需要運行一個節點,并占用少量的資源,因此真實可用內存可能會更少一些)。那么,在這種情況下,如果我們只分配16GB內存給容器的話,我們將無法保證其流暢運行。
其實,不僅此類大容器的部署,我們在進行其他復雜的部署,甚至是采用Helm chart(請參見-- https://grapeup.com/blog/asp-net-core-ci-cd-on-azure-pipelines-with-kubernetes-and-helm/)之類開箱即用的產品時,都必須始終考慮到資源的限制問題。
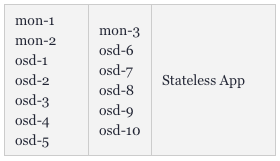
讓我們來看另一個示例--將Ceph部署到同一個集群中。我們的實現目標是將1TB的存儲空間分成10個OSD(object storage daemons,對象存儲守護程序)和3個ceph MON(監視器)。我們希望將其放置在兩個節點上,其余兩個則留給需要使用該存儲的部署。這將是一個高度可擴展的架構。
一般用戶首先能夠想到的做法是將OSD的數量設置為10,MON設置為3,將tolerations添加到Ceph的pod中,以及將taint匹配上Node 1和Node 2。而所有的ceph部署和pod都將nodeSelector設置為僅針對Node 1和2。
如下圖所示,Kubernetes會讓mon-1、mon-2和5個osd運行在第一個worker上,讓mon-3和另5個osds運行在第二個worker上。應用程序可以快速地將大量的大體積文件保存到Ceph上。
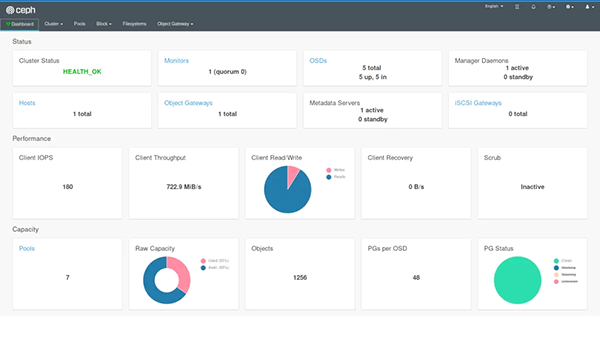
如果我們還部署了儀表板,并創建了一個復制池,那么還可以直觀地看到1TB的可用存儲空間和10個OSD的狀態。
不過,在運行了一段時間后,我們會發現真正可用的存儲空間只剩下了400GB,出現了許多evicted OSD pods,而且有4個OSDs正在同時運行。對此,我們需要重新審視初始時的部署配置。
極限和范圍
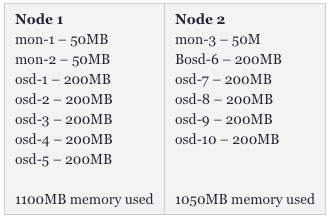
平時,就算我們運行了13個Pod(其中可能有3個監控器),也不會占用過多的資源,但是OSD則不然。由于Ceph在內存中緩存了很大量的數據,那么我們使用得越頻繁,它需要的資源也就越多。同時,各種存儲容器的數據復制和平衡也需要消耗一定的空間。因此,在初次化部署之后,內存的分配情況會如下圖所示:
而在數小時的持續運行之后,該集群就會出現如下狀況:
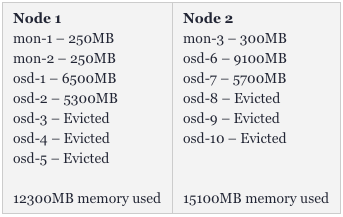
可見,我們損失了幾乎50%的pod。而且這并非是最終狀態,如果高吞吐量將目標指向剩余的容器,那么我們很快會失去得更多。那么,這是否意味著我們需要給Ceph集群配置超過32GB的內存呢?非也。只要我們正確地設置了限制(請參見--https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#resource-requests-and-limits-of-pod-and-container),單個OSD就不能從其他pod處搶奪所有的可用內存。
也就是說,在這種情況下,我們最簡單的方法是:為mon整體分配并保留2GB的內存,其中每個的極限為650MB;將一共30GB的內存除以10個OSD(請見下圖):

由于我們為OSD分配了15GB的內存,并為每個Pod配置了650MB的內存,因此第一個節點會需要:15 + 2 * 0.65 = 16.3GB。此外,我們同樣需要考慮到在同一節點上運行的DaemonSet日志。因此,修正值應該是:

服務質量
如果我們還為Pod設置了一個與限制完全匹配的請求,那么Kubernetes將會以不同的方式來對待此類Pod,如下圖所示:

該配置將Kubernetes中的QoS設置為Guaranteed(否則是Burstable)。有Guaranteed的Pod是永遠不會被evicte的。通過設置相同的請求和限制,我們可以確保Pod的資源使用情況,而無需顧及Kubernetes對其進行移動或管理。此舉雖然降低了調度程序(scheduler)的靈活性,但是能夠讓整個部署方式更具有一定的彈性。
自動擴展環境中的資源
對于關鍵性任務系統(mission-critical systems,請參見--https://grapeup.com/)而言,光靠估算所需的資源,來匹配群集的大小,并做好相關限制是遠遠不夠的。有時候,我們需要通過更加復雜的配置,以及非固定的集群容量,來實現水平擴展和調整可用的worker數量。
假設資源會呈線性擴展的話,那么我們可以同時規劃最小和最大群集的容量。而如果pod能夠被允許在群集擴展時,跟蹤那些按比例在水平方向和垂直方向的擴展的話,那么它在按等比收縮時,則可能會“逐出”其他的pod。為了緩解該問題,Kubernetes提出了兩個主要概念:Pod Priority和Pod Disruption Budget。
下面,讓我們從創建測試場景開始討論。這次我們不需要大量的節點,只需要創建一個具有兩個節點組的集群:一個由常規實例組成(稱為持久性),一個由可搶占(preemptible/spot)實例組成。如下圖所示,當VM(現有節點)的CPU使用率超過0.7(即70%)時,可搶占節點組將進行擴展。
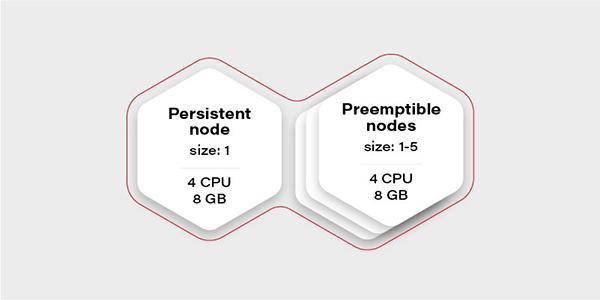
可搶占實例的優勢在于它們比具有相同性能的常規VM要容易實現得多。而唯一缺點是無法保證其生命周期。也就是說,當云提供商出于維護目的,或在24小時之后決定在其他地方需要實例時,該實例就可能會被“逐出”。因此,我們只能在其中運行那些可容錯的無狀態負載。
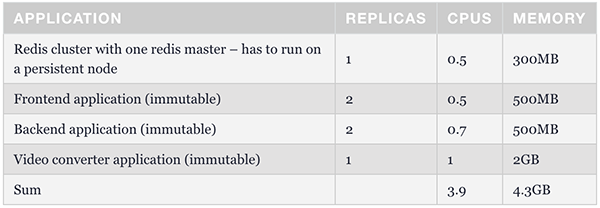
那么,集群中為什么只有一個持久性節點呢?這是為極端情況做準備的。當所有可搶占節點均未運行時,它將維護一個最少的容器集,以管理和保障應用程序的可操作性。下表展示了此類例程的結構。我們可以使用節點選擇器將redis master配置為能夠在持久性節點上運行。
Pod Priority
下面,我們來看一個水平pod自動擴展器(Horizontal Pod Autoscaler,HPA)的例子。
前端:

后端:
視頻轉換器:

作為一款視頻轉換器,它的目標是降低平均資源的占有率。也就是說,通過檢查擴展策略,當有多個轉換隊列時,其CPU平均使用率可能會迅速達到25%,那么它就會產生新的自動化擴展。例如:如果在大約10分鐘的時間內,需要進行50次視頻轉換,那么該轉換器就會擴展出25個實例。那么,為了避免集群中的其他容器被evicte,我們可以創建一種優先級類別(請參見-- https://kubernetes.io/docs/concepts/configuration/pod-priority-preemption):優先級較高的pod對于調度程序而言,具有更高的價值;而優先級較低的pod,則可以被evicte。

因此,如果我們給予轉換器較低的優先級,那么就是默認了前端和后端Pod更為重要。在最壞的情況下,該視頻轉換器可以從群集中逐出。
Pod Disruption Budget
作為更好的pod控制與調度方法,Pod Disruption Budget(PDB)使我們可以一次性配置最少數量的pod。由于有效地阻止了節點資源被耗盡,因此它比僅使用Pod Priority要更加嚴格。如果其他worker上沒有足夠的空間用來重新調度pod,它會保證副本的數量不少于可分配的預定。

上表展示了最基本的配置。其中,前端副本數不低于2。我們可以據此為所有Pod分配一個最小值,并確保始終至少有1到2個pod可以處理請求。
這是確保pod能夠自動擴展、集群可以伸縮的最簡單、也是最安全的方法。只要我們配置了帶有中斷預定的最少容器集,就能夠在不會影響整體穩定性的基礎上,滿足最小集群容量、以及各種請求的最低處理要求。
至此,我們已擁有了創建穩定方案所需的全部必需組件。我們可以將HPA配置為與PDB相同的最小副本數,以簡化調度程序的工作。同時,我們需要根據最大群集數,來確保限制數與請求數不但相同,且不會evicte pod。具體配置如下表所示:
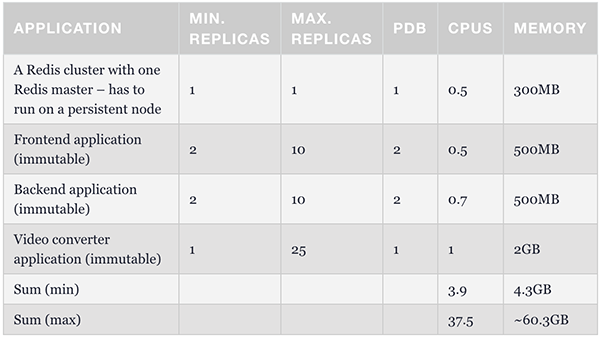
基于上述調度程序的靈活性,在前端和后端的負載過低,卻有大量數據需要轉換時,該轉換器會自動擴展出19-21個實例。
自動擴展的注意事項
關于自動擴展,我們需要注意如下兩個方面:
首先,由于我們無法確定云服務提供商的虛擬機啟動時長(可能幾秒鐘,也可能需要幾分鐘),因此我們無法保障自動擴展肯定能夠解決峰值負載的問題。
其次,在集群縮減時,對于那些正在運行組件,我們需要通過反復測試,讓調度程序能夠快速地將負載移至其他worker處,以實現在不破壞應用操作的前提下,有效地關閉虛擬機。
原標題:Kubernetes Cluster Management: Size and Resources,作者:Adam Kozlowski
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】