如何用Python探究你喜愛(ài)的歌手的音樂(lè)風(fēng)格?
本文轉(zhuǎn)載自公眾號(hào)“讀芯術(shù)”(ID:AI_Discovery)。
2019年5月, Tones and I發(fā)行了她的第二張單曲《Dance Monkey》,這首歌一直在世界各地流行,你肯定曾經(jīng)隨著這首歌的節(jié)奏搖擺過(guò)!
我第一次知道這首歌是在某節(jié)課上,我朋友一直唱著它。一開(kāi)始,筆者感覺(jué)他好像一遍又一遍地重復(fù)同樣的歌詞:“dance for me, dance for me, dancefor me”。聽(tīng)了原曲后,我注意到它確實(shí)有一些重復(fù)的歌詞。筆者接著聽(tīng)了她的另一首熱門歌曲《Never Seen The Rain》,也發(fā)現(xiàn)了類似的模式。
筆者決定以這個(gè)小項(xiàng)目為基礎(chǔ),探究藝術(shù)家在選擇歌詞措辭時(shí)有自己的風(fēng)格。
我將使用基本的python技能來(lái)分析Tones and I的兩首熱門歌曲:《Dance Monkey》和《Never Seen The Rain》,查看它們之間是否存在任何相似之處,以及她如何通過(guò)歌詞的重復(fù)創(chuàng)建自己的音樂(lè)風(fēng)格,比如使用語(yǔ)音單詞(例如“oh”和“ah”)等。
1. 收集和清理數(shù)據(jù)
筆者從Metro Lyrics獲得了這兩首歌的歌詞并對(duì)其進(jìn)行了編輯,確保歌詞之間沒(méi)有逗號(hào)或多余的空格,還將諸如“You’ve”改為“You have”以保持一致性。之后,筆者將其作為字符串上傳到JupyterNotebook上,并為其分配了一個(gè)變量(dm&nstr)。
- #Dance Monkey Lyrics
- dm = "They say oh my god I see the way you shine Take your hand my...makeyou do it all again All again"
- dmdm = dm.lower()#Never Seen The Rain Lyrics
- nstr = "All your life no You could...never felt the rain rain rain"
- nstrnstr = nstr.lower()
dm.lower()函數(shù)更改了單詞以確保它們?nèi)繛樾憽H绻贿@樣做,程序會(huì)認(rèn)為“You”與“you”有所區(qū)別,認(rèn)為它們是不同的詞。打印后,結(jié)果將如下所示:

由于目的之一是找出歌詞中總共有多少個(gè)單詞,所以當(dāng)所有單詞都在一個(gè)字符串中時(shí),就無(wú)法做到這一點(diǎn)。為了分隔它們,筆者使用了以下代碼:
- split_dm = dm.split(' ')
- print(split_dm)

我對(duì)Never Seen The Rain的歌詞也進(jìn)行了同樣的處理。
2. 分類數(shù)據(jù)
下一步是計(jì)算單詞和唯一單詞的總數(shù)。為了計(jì)算單詞總數(shù),筆者在初始變量上使用了LEN()函數(shù):
- len(split_dm)
總共453個(gè)單詞。然后,為了計(jì)算用于創(chuàng)作歌曲的單個(gè)詞的數(shù)量,筆者在split_dm變量上使用了SET()函數(shù)。
- unique_dm = set(split_dm)
- print(unique_dm)
此函數(shù)確保列出至少使用一次的單詞,因此結(jié)果如下所示:
為了計(jì)算新列表中的單詞數(shù),筆者使用了LEN()函數(shù):
- len(unique_dm)
總共有72個(gè)唯一單詞,指的是是只有這些單詞才被用于這首歌的創(chuàng)作。
3. 最常用的詞
在要使用的單詞中,筆者想確定前10個(gè)單詞(重復(fù)最多的單詞)以及僅使用一次的單詞。下面使用的代碼顯示了每個(gè)單詞及其用法計(jì)數(shù):
- word_dm = {}
- for word in unique_dm:
- word_dm[word] = 0for word insplit_dm:
- word_dm[word] = word_dm[word] + 1
- print(word_dm)

為了更易于閱讀,筆者使用以下代碼將單詞和值綁定在一起:
- dm_count = sorted(word_dm.items(),key = lambda t:t[1], reverse =True)
- print(dm_count)

然后,使用此代碼檢索前10個(gè)最常用的單詞:
- dm_top_10 = dm_count[0:10]
- dm_top_10
合并后的數(shù)據(jù)如下所示:
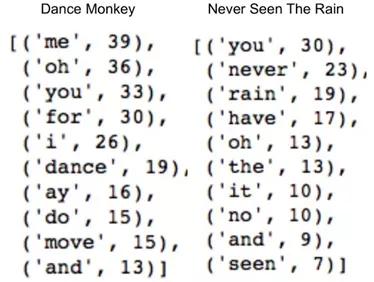
筆者可以肯定地說(shuō),“Tones and I”的獨(dú)特風(fēng)格(在她的所有歌曲中都絕對(duì)可以聽(tīng)到)就是在歌曲中使用“oh”和“ay”之類的原聲單詞,這兩個(gè)詞的數(shù)量在她的兩首歌曲中均排在前10位。
4. 只使用了一次的單詞
圖源:unsplash
使用類似于上面的代碼,筆者還發(fā)現(xiàn)只使用了一次的單詞:
- dm_least_used = dm_count[49:72]
- len(dm_least_used)
只有23個(gè)只使用了一次的單詞。另一首歌曲也運(yùn)用了相同的函數(shù)。
5. 重復(fù)字?jǐn)?shù)
下一個(gè)目標(biāo)是找出不止被重復(fù)一次的單詞數(shù):
- len(unique_dm)-len(dm_least_used)
這首歌里重復(fù)了49個(gè)單詞。為了找到重復(fù)的次數(shù),筆者使用了以下代碼:
- len(split_dm)-len(dm_least_used)
這49個(gè)單詞共被重復(fù)了430次!同樣,在另一首歌里也執(zhí)行相同的代碼。
6. 可視化
筆者將兩首歌曲中的數(shù)據(jù)合并到excel的表格中,然后在筆記本上讀取。
- table = pd.read_csv('song_values.csv')

比較數(shù)據(jù)的最有效方法是使用條形圖:
- x = table.Name
- y1 = table.words_in_song
- y2 = table.words_in_lyrics
- y3 = table.Words_used_once
- y4 = table.Words_used_more_than_once
- y5 = table.Number_of_times_words_repeatedfig = go.Figure(data=[
- go.Bar(name='Total number of words insong', xx=x, y=y1),
- go.Bar(name='Total Number of RepeatedWords', xx=x, y=y5),
- go.Bar(name='Number of words used inLyric', xx=x, y=y2),
- go.Bar(name='Words used once', xx=x,y=y3),
- go.Bar(name='Words used more thanonce', xx=x, y=y4)])#Change the bar mode
- fig.update_layout(barmode='group', title ="Comparison Between The TwoSongs")
- fig.show()
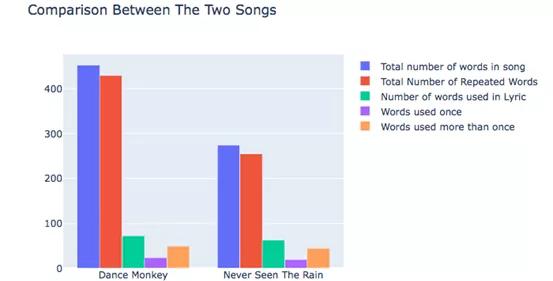
查看圖表,我們可以得出以下結(jié)論:
- 兩首歌曲在歌詞中使用一次的單詞和重復(fù)一次以上的單詞數(shù)量相對(duì)一致,盡管“Dance Monkey”中的單詞數(shù)略微多一些。
- 盡管如此,“Dance Monkey”中重復(fù)單詞的次數(shù)要比“Never Seen The Rain”的重復(fù)次數(shù)高得多。
- 在構(gòu)成歌詞的單詞中,只有不到一半的單詞僅使用過(guò)一次。
7. 最后的想法
在進(jìn)一步處理數(shù)據(jù)時(shí),筆者發(fā)現(xiàn)一個(gè)非常有趣的現(xiàn)象,即標(biāo)題中的兩個(gè)單詞是如何頻繁使用的:“Dance”使用了19次,而“Monkey”在整首歌曲中僅使用了一次。
令人驚訝的是,用于創(chuàng)作歌詞的單個(gè)單詞的數(shù)量非常少(大約占15%-20%),其中約85%的單個(gè)詞被重復(fù)使用以組成歌曲。
圖源:unsplash
做完這個(gè)項(xiàng)目,我?guī)缀跻籇ance Monkey這首歌洗腦了。同樣的方法去試試探索你所喜愛(ài)的歌手,說(shuō)不定能挖出他不為人知的創(chuàng)作習(xí)慣。