機器學習如何看世界 對抗機器學習詮釋人工智能和人類思維的不同
對于人類觀察者來說,以下兩個圖像是相同的。但是Google的研究人員在2015年發(fā)現(xiàn),一種流行的物體檢測算法將左圖像分類為“熊貓”,而將右圖像分類為“長臂猿”。奇怪的是,它對長臂猿的形象更有信心。
有問題的算法是GoogLeNet,這是一種卷積神經(jīng)網(wǎng)絡體系結構,贏得了2014年ImageNet大規(guī)模視覺識別挑戰(zhàn)賽(ILSVRC 2014)。
對抗性例子使機器學習算法愚蠢地犯了錯誤
正確的圖像是“對抗示例”。它經(jīng)歷了微妙的操縱,而人眼卻沒有注意到它,同時使其與機器學習算法的數(shù)字眼完全不同。
對抗性示例利用了人工智能算法的工作方式來破壞人工智能算法的行為。在過去的幾年中,隨著AI在我們使用的許多應用程序中的作用不斷增強,對抗性機器學習已成為研究的活躍領域。人們越來越擔心,機器學習系統(tǒng)中的漏洞可能被用于惡意目的。
對抗性機器學習的工作產(chǎn)生了各種結果,從有趣,良性和令人尷尬的結果(例如跟隨烏龜被誤認為是步槍)到潛在的有害示例,例如無人駕駛汽車誤將停車標志視為限速。
Labsix的研究人員展示了一種改良的玩具烏龜如何使愚蠢的深度學習算法歸類為步槍(來源:labsix.org)
機器學習如何“看”世界
在了解對抗性示例如何工作之前,我們必須首先了解機器學習算法如何解析圖像和視頻。考慮一個圖像分類器AI,就像本文開頭提到的那樣。
在能夠執(zhí)行其功能之前,機器學習模型經(jīng)歷了“訓練”階段,在該階段中,將向其提供許多圖像及其相應的標簽(例如,熊貓,貓,狗等)。該模型檢查圖像中的像素并調(diào)整其許多內(nèi)部參數(shù),以便能夠?qū)⒚總€圖像與其關聯(lián)的標簽鏈接起來。訓練后,該模型應該能夠檢查之前從未見過的圖像,并將其鏈接到正確的標簽上。基本上,您可以將機器學習模型視為一個數(shù)學函數(shù),該函數(shù)以像素值作為輸入并輸出圖像標簽。
人工神經(jīng)網(wǎng)絡(一種機器學習算法)特別適合處理雜亂和非結構化的數(shù)據(jù),例如圖像,聲音和文本文檔,因為它們包含許多參數(shù),并且可以靈活地將自己調(diào)整為訓練數(shù)據(jù)中的不同模式。當相互堆疊在一起時,人工神經(jīng)網(wǎng)絡將成為“深度神經(jīng)網(wǎng)絡”,并且它們進行分類和預測任務的能力也會提高。
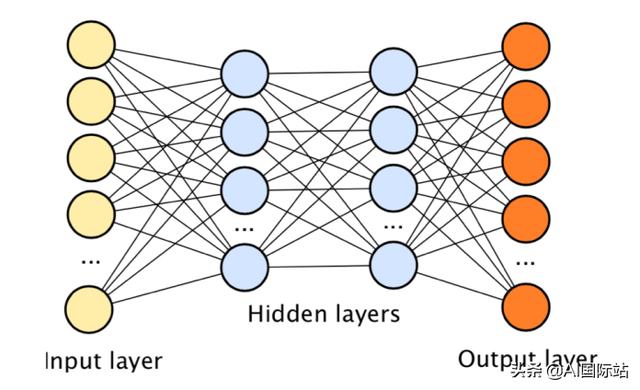
深度神經(jīng)網(wǎng)絡由幾層人工神經(jīng)元堆疊而成
深度學習是使用深度神經(jīng)網(wǎng)絡的機器學習的一個分支,目前是人工智能的前沿。深度學習算法通常在人類以前無法完成的任務(例如計算機視覺和自然語言處理)上與人類相匹配,有時甚至勝過人類。
但是,值得注意的是,深度學習和機器學習算法的核心是數(shù)字運算機器。他們可以在像素值,單詞序列和聲波中找到微妙而復雜的圖案,但他們卻不像人類那樣看待世界。
這就是對抗性例子進入畫面的地方。
對抗性范例的運作方式
當您要求人類描述她如何在圖像中檢測到熊貓時,她可能會尋找諸如圓耳朵,眼睛周圍的黑色斑點,鼻子,鼻子和毛茸茸的皮膚等身體特征。她可能還會提供其他背景信息,例如她希望看到熊貓的棲息地以及熊貓所采取的姿勢。
對于人工神經(jīng)網(wǎng)絡,只要通過方程式運行像素值提供正確答案,就可以確信所看到的確實是熊貓。換句話說,通過正確調(diào)整圖像中的像素值,您可以使AI誤以為它沒有看到熊貓。
在本文開頭看到的對抗示例中,AI研究人員在圖像上添加了一層噪點。人眼幾乎看不到這種噪音。但是,當新的像素數(shù)通過神經(jīng)網(wǎng)絡時,它們會產(chǎn)生長臂猿圖像所期望的結果。
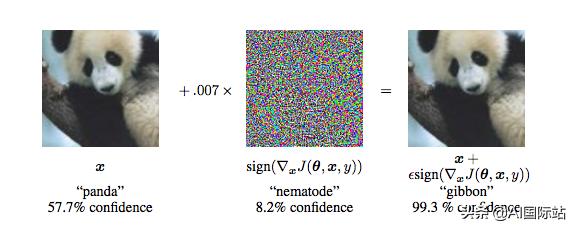
在左側(cè)的熊貓圖像上添加一層噪點,使其成為一個對抗性示例
創(chuàng)建對抗性機器學習示例是一個反復試驗的過程。許多圖像分類器機器學習模型都提供了輸出列表及其置信度(例如,熊貓= 90%,長臂猿= 50%,黑熊= 15%等)。創(chuàng)建對抗性示例需要對圖像像素進行細微調(diào)整,然后通過AI重新運行它,以查看修改如何影響置信度得分。進行足夠的調(diào)整后,您可以創(chuàng)建噪聲圖,從而降低對一個類別的信心,而對另一個類別進行增強。此過程通常可以自動化。
在過去的幾年中,在對抗性機器學習的工作和效果方面進行了大量的工作。2016年,卡內(nèi)基梅隆大學的研究人員表明,戴上特殊眼鏡可能會使人臉識別神經(jīng)網(wǎng)絡蒙騙,使他們誤以為是名人。
在另一種情況下,三星和華盛頓大學,密歇根大學以及加州大學伯克利分校的研究人員表明,通過進行細微調(diào)整以停止標志,可以使它們對自動駕駛汽車的計算機視覺算法不可見。黑客可能會利用這種對抗性攻擊迫使無人駕駛汽車以危險的方式行事,并可能導致事故。
AI研究人員發(fā)現(xiàn),通過添加黑白小貼紙來停止標志,可以使它們對計算機視覺算法不可見(來源:arxiv.org)
超越圖像的對抗性例子
對抗性示例不僅適用于處理視覺數(shù)據(jù)的神經(jīng)網(wǎng)絡。也有針對文本和音頻數(shù)據(jù)的對抗性機器學習的研究。在2018年,加州大學伯克利分校的研究人員設法通過對抗性例子來操縱自動語音識別系統(tǒng)(ASR)的行為。諸如Amazon Alexa,Apple Siri和Microsoft Cortana之類的智能助手使用ASR來解析語音命令。
例如,可以修改媒體上發(fā)布的歌曲,使其播放時可以向附近的智能揚聲器發(fā)送語音命令。聽眾不會注意到變化。但是智能助手的機器學習算法會選擇并執(zhí)行該隱藏命令。
對抗性示例也適用于處理文本文檔的自然語言處理系統(tǒng),例如過濾垃圾郵件,阻止社交媒體上的仇恨言論并檢測產(chǎn)品評論中的情緒的機器學習算法。
在2019年,IBM Research,亞馬遜和德克薩斯大學的科學家創(chuàng)建了對抗性示例,這些示例可能愚弄文本分類器機器學習算法,例如垃圾郵件過濾器和情感檢測器。基于文本的對抗性示例(也稱為“釋義攻擊”)會修改一段文本中的單詞序列,以在機器學習算法中引起錯誤分類錯誤,同時保持與人類讀者一致的含義。

強制AI算法更改其輸出的釋義內(nèi)容示例
防范對抗性例子
保護機器學習模型不受對抗性示例攻擊的主要方法之一是“對抗性訓練”。在對抗訓練中,機器學習算法的工程師在對抗示例上對模型進行了重新訓練,以使其對數(shù)據(jù)擾動具有魯棒性。
但是對抗訓練是一個緩慢而昂貴的過程。必須對每個訓練示例進行對抗性弱點的探索,然后必須在所有這些示例上對模型進行重新訓練。科學家正在開發(fā)方法,以優(yōu)化發(fā)現(xiàn)和修補機器學習模型中對抗性弱點的過程。
同時,AI研究人員也在尋找可以在更高層次上解決深度學習系統(tǒng)中對抗性漏洞的方法。一種方法涉及組合并行神經(jīng)網(wǎng)絡并隨機切換它們,以使模型對對抗攻擊更具魯棒性。另一種方法涉及從其他幾個網(wǎng)絡構建廣義神經(jīng)網(wǎng)絡。通用架構不太可能被對抗性例子所愚弄。對抗性的例子清楚地提醒了人工智能和人類思維的不同。