













我研究了最熱門的200種AI工具,卻發現這個行業有點飽和
在 LinkedIn 上,很多你申請的機器學習職位都有超過 200 名競爭者。在 AI 工具上人們也有這么多選擇嗎?
為了完整了解機器學習技術應用的現狀,畢業于斯坦福大學,曾就職于英偉達的工程師 Chip Huyen 決定評測目前市面上所有能找到的 AI / 機器學習工具。
在搜索各類深度學習全棧工具列表,接受人們的推薦之后,作者篩選出了 202 個較為熱門的工具進行評測。最近,她的統計結果讓機器學習社區感到有些驚訝。
首先要注意的是:
這一列表是在 2019 年 11 月列出的,最近開源社區可能會有新工具出現。
有些科技巨頭的工具列表龐大,無法一一列舉,比如 AWS 就已經提供了超過 165 種機器學習工具。
有些創業公司已經消失,其提出的工具不為人們所知。
作者認為泛化機器學習的生產流程包括 4 個步驟:
項目設置
數據 pipeline
建模和訓練
服務
作者依據所支持的工作步驟將工具進行分類。項目設置這一步沒有算在內,因為它需要項目管理工具,而不是機器學習工具。由于一種工具可能不止用于一個步驟,所以分類并不簡單。「我們突破了數據科學的極限」,「將 AI 項目轉變為現實世界的商務成果」,「允許數據像您呼吸的空氣一樣自由移動」,以及作者個人最喜歡的「我們賴以生存和呼吸的數據科學」,這些模棱兩可的表述并沒有讓問題變得更簡單。
工具的時間演變歷程
作者追溯了每種工具發布的年份。如果是開源項目,則查看首次提交,以查看項目開始公開的時間。如果是一家公司,則查看該公司在 Crunchbase 上的創辦年份。然后她繪制了隨著時間的推移,每個類別中工具數量的變化曲線。具體如下圖所示:
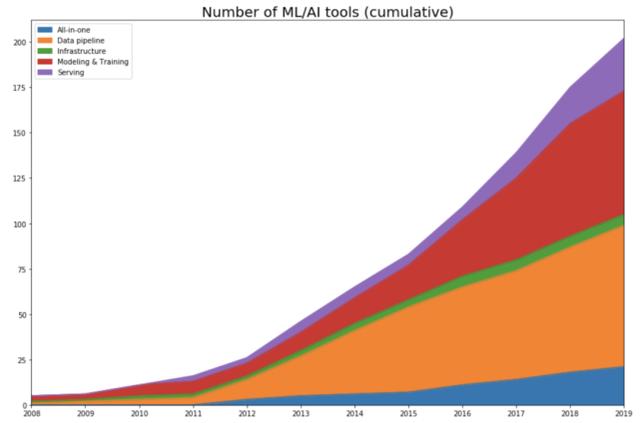
不出所料,數據表明,隨著 2012 年深度學習的復興,該領域才開始呈爆炸式增長。
AlexNet 之前(2012 年之前)
直到 2011 年,該領域仍然以建模訓練工具為主導,有些框架(比如 scikit-learn)仍然非常流行,有些則對當前的框架(Theano)產生了影響。2012 年以前開發出來且至今仍在使用的一些工具要么完成 IPO(如 Cloudera、Datadog 和 Alteryx),要么被收購(Figure Eight),要么成為受社區歡迎并積極開發的開源項目(如 Spark、Flink 和 Kafka)。
開發階段(2012-2015)
隨著機器學習社區采用「let’s throw data at it」的方法,機器學習空間就變成了數據空間。當調查每個類別中每年開發出的工具數量時,這一點更加明顯。2015 年,57%(82 個工具中有 42 個)的工具都是數據 pipeline 工具。具體如下圖所示:
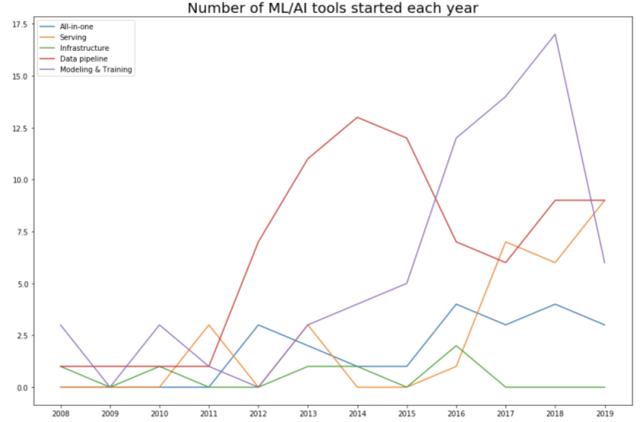
生產階段(2016 年至今)
每個人都知道越基礎的研究越重要,但大多數公司都無法支持研究人員進行純技術方向的探索——除非能夠看到短期商業利益。隨著機器學習研究、數據和已訓練模型數量的增多,開發者和機構的需求增加,市場對于機器學習工具的需求也有了巨大的增長。
2016 年,谷歌宣布將神經機器學習技術應用到谷歌翻譯中,這是深度學習在現實世界里首次落地的重要標志。
這一全景圖仍不完整
AI 創業公司現在已經有很多了,但它們大多數都面向技術的落地(提供面向消費者的應用),而不是提供開發工具(如向其他公司售賣框架和軟件開發包)。用風險投資的術語來說,大多數初創公司都是垂直 AI 領域里的。在福布斯 2019 年公布的 50 大 AI 初創公司里,只有 7 家是以機器學習開發工具為主業的。
對于大多數人來說,應用更為直觀。你可以走進一家公司說:「我們可以讓你們的一半客服工作實現自動化。」工具實現的價值總是間接的,但又深入整個生態系統。在一個市場中,很多公司都可以提供相同的應用,但其背后用到的工具卻只有寥寥幾種。
經過大量搜索和比對,在這里作者只列出了 200 余個 AI 工具,相對于傳統計算機軟件工程來說這個數字很小。如果你想評測傳統的 Python 應用開發,你可以用谷歌幾分鐘內找出至少 20 個工具,但如果你想試試機器學習模型,事情就完全不一樣了。
機器學習工具面臨的問題
很多傳統的軟件工具都可以用于開發機器學習應用。但是在機器學習應用中,也有很多挑戰是獨有的,需要特殊的工具。
在傳統軟件開發流程中,寫代碼是最難的一步,但在機器學習工作中,寫代碼只是整個流程中耗費精力較小的一部分。開發一個可以帶來很大性能提升,并且在現實世界中可以落地的新模型非常耗費時間和資金。大多數公司都會選擇不去開發新模型,而是直接拿來就用。
對于機器學習來說,使用最多 / 最好數據的應用總會獲勝。所以與其專注于提升深度學習算法,大多數公司都會花費大量時間提升數據的質量。因為數據的變化總是很快,機器學習應用也需要快速的開發和部署。在很多例子中,你甚至需要每天都部署新的模型。
此外,ML 算法的規模也是一個問題。預訓練的大規模 BERT 模型具有 3.4 億參數,大小為 1.35GB。即使 BERT 模型可以擬合手機等消費類設備,但在新樣本上運行推理所耗費的大量時間就使其對于現實世界的眾多應用毫無用處。
試想,如果自動補全模型提示下一個字符所花費的時間比用戶自己鍵入的時間還要長,那么有什么必要用這個模型呢?
Git 通過逐行的差異比較實現了版本控制,因而對大多數傳統軟件工程程序的效果很好。但是,Git 并不適用于數據庫或者模型檢查點的版本控制。Panda 對大多數傳統數據框操作的效果很好,但在 GPU 上不起作用。
CSV 等基于行的數據格式對于使用較少數據的應用有很好的效果。但是,如果你的樣本具有很多特征,并且你只想利用其中的一個子特征,則使用基于行的數據格式依然需要你加載所有的特征。PARQUET 和 OCR 等柱狀文件格式針對這種用例進行了優化。
ML 應用面臨的一些問題如下所示:
監測:怎么知道你的數據分布已經改變以及需要重新訓練模型?
數據標注:如何快速地標注新數據,或者為新模型重新標注現有數據?
CI/CD 測試:由于你不能花幾天的時間等著模型訓練和收斂,所以如何運行測試以確保每次改變后模型像期望地那樣運行?
部署:如何封裝和部署新模型或者替換現有模型?
模型壓縮:如何壓縮 ML 模型使其擬合消費類設備?
推理優化:如果加速模型的推理時間?是否可以將所有操作融合在一起?是否可以采用更低精度?縮小模型或許可以加速推理過程。
邊緣設備:硬件運行 ML 算法速度快且成本低。
隱私:如何在保護隱私的同時利用用戶數據來訓練模型?如何使流程符合《通用數據保護條例》(GDPR)?
在下圖中,作者根據開發工具能夠解決的主要問題列出了它們的數量:
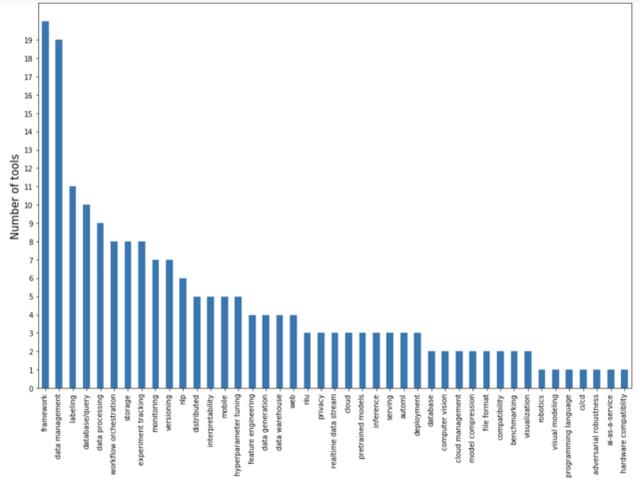
一大部分集中在數據 pipeline,包括數據管理、貼標簽、數據庫 / 查詢、數據處理和數據生成。數據 pipeline 工具可能也想成為一體化平臺(all-in-one platform)。由于數據處理是項目中最耗費資源的階段,一旦有人在你的平臺上放置他們的數據,那就很有可能給他們提供預構建或預訓練的模型。
建模和訓練工具大多是框架。當前深度學習框架之爭有所平靜,主要集中在 PyTorch 和 TensorFlow 這兩者之間,以及基于這兩者解決 NLP、NLU 和多模態問題等特定任務的更高級的框架。分布式訓練領域也有一些框架。還有一個出自谷歌的新框架 JAX,每個討厭 TensorFlow 的谷歌員工都力捧這個框架。
存在一些用于實驗追蹤的獨立工具,一些流行深度學習框架還有內置的實驗追蹤功能。超參數調整很重要,所以出現專門用于超參數調整的工具并不奇怪,但是它們似乎沒有一個流行起來。因為超參數調整的瓶頸不是設置,而是運行它所需的算力。
尚未解決但最令人興奮的問題在部署和服務空間中。缺少服務方法的原因之一是研究人員與生產工程師之間缺乏溝通。在有能力進行人工智能研究的公司(常常是大公司),研究團隊與部署團隊是分開工作的,兩個團隊僅通過 P 打頭的經理:產品經理、程序經理、項目經理互相交流進行溝通。而員工可以看到整個堆棧的小公司就會受到即時產品需求的限制。
只有少數幾家初創公司能夠縮小差距,這些公司通常是由已有成就的研究人員創建,并且有足夠的資金雇傭優秀的工程師。而這樣的初創公司將會占據人工智能工具市場很大一部分。
開源和開放內核(open-core)
作者選擇的 202 種工具中有 109 種是開源軟件(Open Source Software, OSS),并且沒有開源的工具也常常與其他開源工具綁在一起。
開源軟件的出現和發展由多種原因促成,以下是所有開源軟件支持者談論數年的一些原因,包括透明度、協作、靈活性以及合乎倫理道德。客戶可能不希望使用無法獲取源代碼的新工具。否則,如果不開放源代碼的工具無法使用,則必須重寫代碼。這是初創公司經常出現的狀況。
開源軟件并不意味著非盈利和免費,開發者有其更深遠的目的。需要看到,開源軟件的維護耗時且花費不菲。傳聞 TensorFlow 團隊的成員數接近 1000 人。一家企業提供開源軟件肯定有其商業目的,舉例而言,越來越多的人使用某家公司的開源軟件,那么該公司的名頭就會越來越響,人們也就更加信任這家公司的專業技術,最終可能會購買他們的專有工具,甚至加入他們的團隊。
這樣的例子比比皆是。谷歌不遺余力地推廣他們的工具,其目的是想用戶使用其云服務。英偉達維護 cuDF,旨在售賣更多的 GPU。Databricks 免費提供 MLflow,但也售賣他們的數據分析平臺。
此外,網飛公司最近成立了專門的機器學習團隊,并推出了自己的 Metaflow 框架,從而也加入到了機器學習(ML)的發展大潮中,以吸引人才。Explosion 免費提供 SpaCy,但同時對 Prodigy 收費。HuggingFace 是一個特例,它免費提供 transformer,但不清楚究竟如何盈利。
隨著軟件開源成為一種標準,初創公司找到一種行之有效的商業模式變得很困難。任何剛起步的工具類公司都必須與現有開源工具競爭。所以,如果初創公司選擇開源內核的商業模式,則必須決定開源軟件中涵蓋哪些功能,付費版本中包含哪些內容才不顯得貪得無厭,以及如何讓免費使用工具的用戶開始付費。
未來展望
關于 AI 泡沫是否破裂的討論此起彼伏。很大一部分的 AI 投資流向了自動駕駛汽車,但我們已了解完全自動駕駛的車輛離落地應用還有很長的路要走,一些人猜測投資者將會對 AI 完全喪失信心。
谷歌暫停了 ML 研究人員的招聘,優步也解雇了 AI 團隊中一半的研究人員。這些決策都是在新冠肺炎爆發之前做出的。此外,有傳言稱,由于選擇攻讀機器學習的人數太多了,市場上 ML 的工作需求卻遠遠少于掌握 ML 技術的人才。
那么問題來了,現在進入 ML 領域還是好時機嗎?不可否認,AI 炒作確實存在,在某種程度上,這種熱度需要「降溫」。這一點可能已經發生了。然而,作者并不認為 ML 會消失。可能越來越少的企業能夠支撐得起 ML 研究,但依然會有企業需要工具將它們的 ML 付諸生產。
由此,如果必須在工程和 ML 兩者之間選擇,作者建議選擇工程。優秀的工程師學習 ML 知識更加容易,但 ML 專家想要成為優秀的工程師就比較困難了。如果可以成為一位能夠構建優秀 ML 工具的工程師,那真是再好不過了!




















