一個HTTP,真有這么難嗎?
HTTP 是瀏覽器中最重要且使用最多的協議,是瀏覽器和服務器之間的通信語言。隨著瀏覽器的發展,HTTP 為了能適應新的形式也在持續進化。已經歷經0.9,1.0,1.1,2.0等幾個階段, 以及未來的3.0。
開頭先講個小故事,看完你可能滿臉黑人問號,但是別著急,等你把文章全讀完再回頭品一品這個小故事
我有多幢房子需要還貸。(多狀緩代)
但是突然有人來要錢,我手持水管虛晃了幾個動作就被他按在地上打哭了。(持管虛動安哭)
然后我不服,跟他進行了慢競賽,結果我被他多了一耳光又退縮了 (慢競塞)(多優推縮)
之后我和他對視到眼睛都僵了(隊延僵)
結果他更加狠的多我的臉 (功加多握)
HTTP 0.9
出現時間
1991年
出現原因
用來在網絡之間傳遞 HTML 超文本的內容。
實現
采用了基于請求響應的模式,從客戶端發出請求,服務器返回數據。
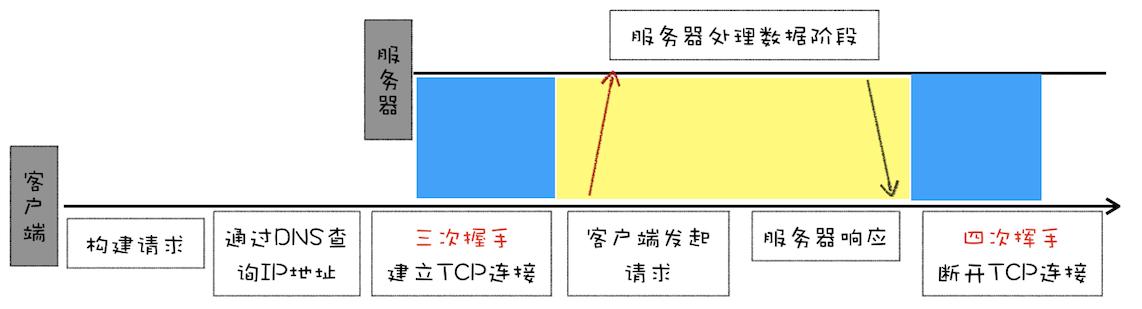
流程
- 因為 HTTP 都是基于 TCP 協議的,所以客戶端先要根據 IP 地址、端口和服務器建立 TCP 連接,而建立連接的過程就是 TCP 協議三次握手的過程。
- 建立好連接之后,會發送一個 GET 請求行的信息,如GET /index.html用來獲取 index.html。
- 服務器接收請求信息之后,讀取對應的 HTML 文件,并將數據以 ASCII 字符流返回給客戶端。
- HTML 文檔傳輸完成后,斷開連接。
圖示
特點
- 只有一個請求行,并沒有 HTTP 請求頭和請求體因為只需要一個請求行就可以完整表達客戶端的需求了。
- 服務器也沒有返回頭信息。這是因為服務器端并不需要告訴客戶端太多信息,只需要返回數據就可以了。
- 返回的文件內容是以 ASCII 字符流來傳輸的
HTTP 1.0
出現時間
1994年
出現原因
隨著瀏覽器的發展在瀏覽器中展示的不單是 HTML 文件了,還包括了 JavaScript、CSS、圖片、音頻、視頻等不同類型的文件。因此需要支持多種類型的文件下載
文件格式不僅僅局限于 ASCII 編碼,還有很多其他類型編碼的文件。
圖示:
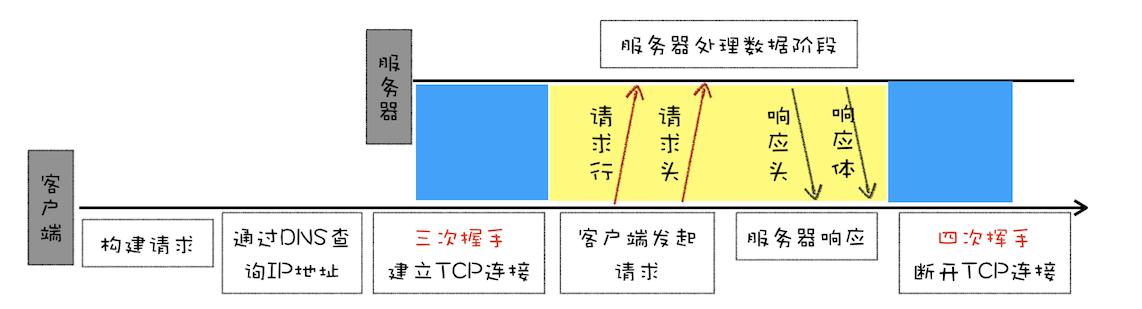
新增特性:(多狀緩代)
對多文件提供良好的支持,支持多種不同類型的數據。HTTP/1.0 的方案是通過請求頭和響應頭來進行協商,在發起請求時候會通過 HTTP 請求頭告訴服務器它期待服務器返回什么類型的文件、采取什么形式的壓縮、提供什么語言的文件以及文件的具體編碼。
- accept: text/html // 返回類型
- accept-encoding: gzip, deflate, br // 壓縮方式
- accept-Charset: ISO-8859-1,utf-8 // 編碼格式
- accept-language: zh-CN,zh // 語言
引入狀態碼,有的請求服務器可能無法處理,或者處理出錯,這時候就需要告訴瀏覽器服務器最終處理該請求的情況,狀態碼是通過響應行的方式來通知瀏覽器的。
提供了 Cache 機制,用來緩存已經下載過的數據以減輕服務器的壓力
加入了用戶代理的字段以統計客戶端的基礎信息,比如 Windows 和 macOS 的用戶數量分別是多少。
記憶:多狀緩代(你有多幢(狀)房子需要還(緩)貸(代))
HTTP 1.1
出現時間
1999年
出現原因
隨著技術的繼續發展,需求也在不斷迭代更新,很快 HTTP/1.0 也不能滿足需求了。
新增特性:
- 改進持久連接。
- 由于http1.0是短連接,所以HTTP/1.0 每進行一次 HTTP 通信,都需要經歷建立 TCP 連接、傳輸 HTTP 數據和斷開 TCP 連接三個階段。這樣做會增加大量的開銷。為解決這個問題,HTTP/1.1 中增加了持久連接的方法,它的特點是在一個 TCP 連接上可以傳輸多個 HTTP 請求,只要瀏覽器或者服務器沒有明確斷開連接,那么該 TCP 連接會一直保持。持久連接在 HTTP/1.1 中是默認開啟的,如不想采用持久連接,可以在 HTTP 請求頭中加上Connection: close。
- 目前瀏覽器中對于同一個域名,默認允許同時建立 6 個 TCP 持久連接。(TODO: 在此添加對比圖)
- 使用 CDN 的實現域名分片機制
- 不成熟的 HTTP 管線化
HTTP/1.1 中的管線化是指將多個 HTTP 請求整批提交給服務器的技術,雖然可以整批發送請求,不過服務器依然需要根據請求順序來回復瀏覽器的請求。由于持久連接雖然能減少 TCP 的建立和斷開次數,但是它需要等待前面的請求返回之后,才能進行下一次請求。如果 TCP 通道中的某個請求因為某些原因沒有及時返回,那么就會阻塞后面的所有請求,這就是著名的隊頭阻塞的問題。HTTP/1.1 試圖用管線化解決隊頭阻塞問題。
- 提供虛擬主機的支持
在 HTTP/1.0 中,每個域名綁定了一個唯一的 IP 地址,因此一個服務器只能支持一個域名。但是隨著虛擬主機技術的發展,需要實現在一臺物理主機上綁定多個虛擬主機,每個虛擬主機都有自己的單獨的域名,這些單獨的域名都公用同一個 IP 地址。因此,HTTP/1.1 的請求頭中增加了 Host 字段,用來表示當前的域名地址,這樣服務器就可以根據不同的 Host 值做不同的處理。
- 對動態生成的內容提供了完美支持
HTTP/1.0 時,需要在響應頭中設置完整的數據大小,如Content-Length: 901,這樣瀏覽器就可以根據設置的數據大小來接收數據。不過隨著服務器端的技術發展,很多頁面的內容都是動態生成的,因此在傳輸數據之前并不知道最終的數據大小,這就導致了瀏覽器不知道何時會接收完所有的文件數據。
HTTP/1.1 通過引入 Chunk transfer 機制(分塊傳輸編碼機制)來解決這個問題,服務器會將數據分割成若干個任意大小的數據塊,每個數據塊發送時會附上上個數據塊的長度,最后使用一個零長度的塊作為發送數據完成的標志。這樣就提供了對動態內容的支持。
- 客戶端 Cookie、安全機制
HTTP/1.1 還引入了客戶端 Cookie 機制和安全機制
記憶:持管虛動安哭,手持水管虛晃了幾個動作就被人安在地上打哭了
HTTP 2.0
出現時間
2015年,大多數主流瀏覽器也于當年年底支持該標準
出現原因
雖然HTTP/1.1 采取了很多優化資源加載速度的策略,也取得了一定的效果,但是 HTTP/1.1對帶寬的利用率卻并不理想。主要是由于以下幾個原因
- TCP 的慢啟動
一旦一個 TCP 連接建立之后,就進入了發送數據狀態,剛開始 TCP 協議會采用一個非常慢的速度去發送數據,然后慢慢加快發送數據的速度,直到發送數據的速度達到一個理想狀態,我們把這個過程稱為慢啟動。慢啟動是 TCP 為了減少網絡擁塞的一種策略,我們是沒有辦法改變的。因為頁面中常用的一些關鍵資源文件本來就不大,如 HTML 文件、CSS 文件和 JavaScript 文件,通常這些文件在 TCP 連接建立好之后就要發起請求的,但這個過程是慢啟動,所以耗費的時間比正常的時間要多很多,這樣就增加了首次渲染頁面的時長了。
同時開啟了多條 TCP 連接,那么這些連接會競爭固定的帶寬
系統同時建立了多條 TCP 連接,當帶寬充足時,每條連接發送或者接收速度會慢慢向上增加,而一旦帶寬不足時,這些 TCP 連接又會減慢發送或者接收的速度。這樣就會出現一個問題,因為有的 TCP 連接下載的是一些關鍵資源,如 CSS 文件、JavaScript 文件等,而有的 TCP 連接下載的是圖片、視頻等普通的資源文件,但是多條 TCP 連接之間又不能協商讓哪些關鍵資源優先下載,這樣就有可能影響那些關鍵資源的下載速度了。
- HTTP/1.1 隊頭阻塞的問題
在 HTTP/1.1 中使用持久連接時,雖然能公用一個 TCP 管道,但在一個管道中同一時刻只能處理一個請求,在當前的請求沒有結束之前,其他的請求只能處于阻塞狀態。這意味著我們不能隨意在一個管道中發送請求和接收內容。這是一個很嚴重的問題,因為阻塞請求的因素有很多,并且都是一些不確定性的因素,假如有的請求被阻塞了 5 秒,那么后續排隊的請求都要延遲等待 5 秒,在這個等待的過程中,帶寬、CPU 都被白白浪費了。并且隊頭阻塞使得數據不能并行請求,所以隊頭阻塞是很不利于瀏覽器優化的。
- 記憶:慢競塞 慢跑競賽
實現思路
HTTP/2 的思路就是一個域名只使用一個 TCP 長連接來傳輸數據,這樣整個頁面資源的下載過程只需要一次慢啟動,同時也避免了多個 TCP 連接競爭帶寬所帶來的問題。另外隊頭阻塞的問題,等待請求完成后才能去請求下一個資源,這種方式無疑是最慢的,所以 HTTP/2 需要實現資源的并行請求,也就是任何時候都可以將請求發送給服務器,而并不需要等待其他請求的完成,然后服務器也可以隨時返回處理好的請求資源給瀏覽器。即一個域名只使用一個 TCP 長連接和消除隊頭阻塞問題
圖示:
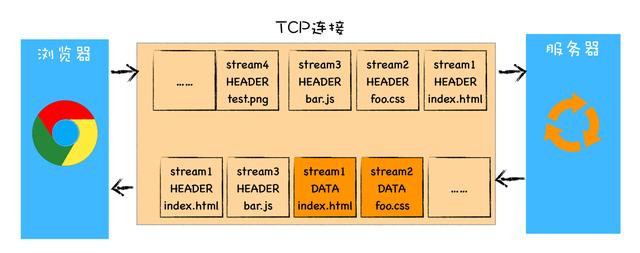
新增特性
- 多路復用,通過引入二進制分幀層,就實現了 HTTP 的多路復用技術。
- 首先,瀏覽器準備好請求數據,包括了請求行、請求頭等信息,如果是 POST 方法,那么還要有請求體這些數據經過二進制分幀層處理之后,會被轉換為一個個帶有請求 ID 編號的幀,通過協議棧將這些幀發送給服務器。服務器接收到所有幀之后,會將所有相同 ID 的幀合并為一條完整的請求信息。然后服務器處理該條請求,并將處理的響應行、響應頭和響應體分別發送至二進制分幀層。同樣,二進制分幀層會將這些響應數據轉換為一個個帶有請求 ID 編號的幀,經過協議棧發送給瀏覽器。瀏覽器接收到響應幀之后,會根據 ID 編號將幀的數據提交給對應的請求。
- 設置請求的優先級
我們知道瀏覽器中有些數據是非常重要的,但是在發送請求時,重要的請求可能會晚于那些不怎么重要的請求,如果服務器按照請求的順序來回復數據,那么這個重要的數據就有可能推遲很久才能送達瀏覽器。為了解決這個問題,HTTP/2 提供了請求優先級,可以在發送請求時,標上該請求的優先級,這樣服務器接收到請求之后,會優先處理優先級高的請求。
- 服務器推送
除了設置請求的優先級外,HTTP/2 還可以直接將數據提前推送到瀏覽器。
- 頭部壓縮
HTTP/2 對請求頭和響應頭進行了壓縮,你可能覺得一個 HTTP 的頭文件沒有多大,壓不壓縮可能關系不大,但你這樣想一下,在瀏覽器發送請求的時候,基本上都是發送 HTTP 請求頭,很少有請求體的發送,通常情況下頁面也有 100 個左右的資源,如果將這 100 個請求頭的數據壓縮為原來的 20%,那么傳輸效率肯定能得到大幅提升。
記憶: 多優推縮 多了一耳光之后又(優)退(推)縮(縮)了
HTTP 3.0
出現原因
- TCP層面依舊存在隊頭阻塞
在 TCP 傳輸過程中,由于單個數據包的丟失會造成的阻塞。隨著丟包率的增加,HTTP/2 的傳輸效率也會越來越差。有測試數據表明,當系統達到了 2% 的丟包率時,HTTP/1.1 的傳輸效率反而比 HTTP/2 表現得更好。
- TCP 建立連接的延時
TCP 的握手過程也是影響傳輸效率的。我們知道 HTTP/1 和 HTTP/2 都是使用 TCP 協議來傳輸的,而如果使用 HTTPS 的話,還需要使用 TLS 協議進行安全傳輸,而使用 TLS 也需要一個握手過程,這樣就需要有兩個握手延遲過程。總之,在傳輸數據之前,我們需要花掉 3~4 個 RTT,若服務器相隔較遠,那么 1 個 RTT 就可能需要 100 毫秒以上了,這種情況下整個握手過程需要 300~400 毫秒,這時用戶就能明顯地感受到“慢”了。
- TCP 協議僵化
中間設備的僵化:如果我們在客戶端升級了 TCP 協議,但是當新協議的數據包經過這些中間設備時,它們可能不理解包的內容,于是這些數據就會被丟棄掉。這就是中間設備僵化,它是阻礙 TCP 更新的一大障礙。
操作系統也是導致 TCP 協議僵化的另外一個原因, 因為 TCP 協議都是通過操作系統內核來實現的,應用程序只能使用不能修改。通常操作系統的更新都滯后于軟件的更新,因此要想自由地更新內核中的 TCP 協議也是非常困難的。
記憶:隊延僵 對視到眼睛都僵了
實現思路
HTTP/3 選擇了一個折衷的方法——UDP 協議,基于 UDP 實現了類似于 TCP 的多路數據流、傳輸可靠性等功能,我們把這套功能稱為 QUIC 協議。
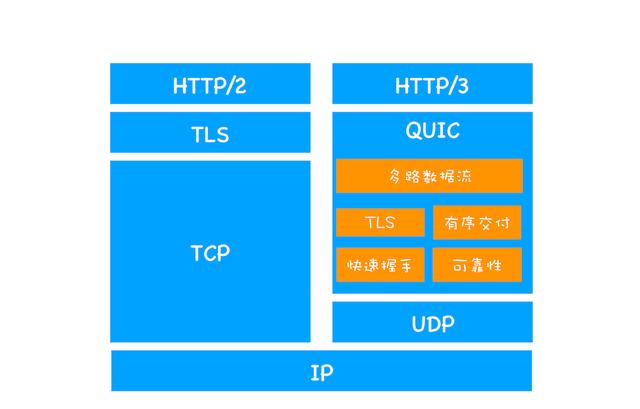
HTTP/2 和 HTTP/3 協議棧
特性
- 實現了類似 TCP 的流量控制、傳輸可靠性的功能
雖然 UDP 不提供可靠性的傳輸,但 QUIC 在 UDP 的基礎之上增加了一層來保證數據可靠性傳輸。它提供了數據包重傳、擁塞控制以及其他一些 TCP 中存在的特性。
- 集成了 TLS 加密功能
目前 QUIC 使用的是 TLS1.3,相較于早期版本 TLS1.3 有更多的優點,其中最重要的一點是減少了握手所花費的 RTT 個數。
- 實現了 HTTP/2 中的多路復用功能
和 TCP 不同,QUIC 實現了在同一物理連接上可以有多個獨立的邏輯數據流。實現了數據流的單獨傳輸,就解決了 TCP 中隊頭阻塞的問題。
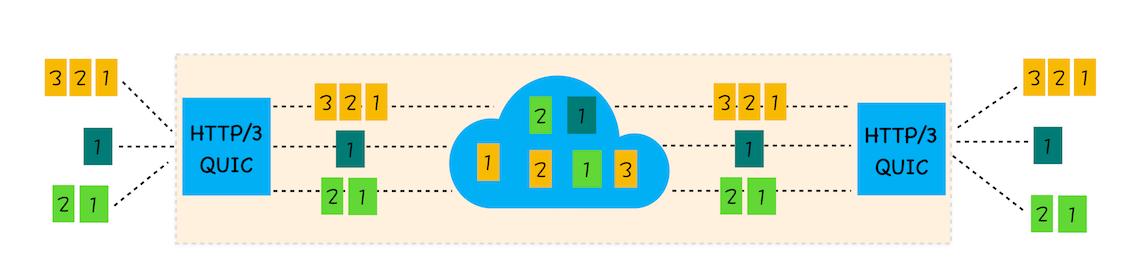
- 實現了快速握手功能
由于 QUIC 是基于 UDP 的,所以 QUIC 可以實現使用 0-RTT 或者 1-RTT 來建立連接,這意味著 QUIC 可以用最快的速度來發送和接收數據,這樣可以大大提升首次打開頁面的速度。
記憶: 功加多握 (更(功)加(加)狠的多(多)我(握)的臉)
面對的問題
服務器和瀏覽器端都沒有對 HTTP/3 提供比較完整的支持
系統內核對 UDP 的優化遠遠沒有達到 TCP 的優化程度,這也是阻礙 QUIC 的一個重要原因。
中間設備僵化的問題。這些設備對 UDP 的優化程度遠遠低于 TCP,據統計使用 QUIC 協議時,大約有 3%~7% 的丟包率。
未來
從標準制定到實踐再到協議優化還需要走很長一段路;并且因為動了底層協議,所以 HTTP/3 的增長會比較緩慢,這和 HTTP/2 有著本質的區別。但是騰訊等公司已經嘗試在生產中落地http3的使用,例如QQ興趣部落。
2020年五月初,微軟宣布開源自己的內部 QUIC 庫 -- MsQuic,將全面推薦 QUIC 協議替換 TCP/IP 協議。
所以總體來說http3未來可期
作者:一只菜鳥攻城獅啊
來源:https://www.cnblogs.com/suihang/p/13265136.html