













Pandas數據合并與拼接的5種方法
作者:Python之王
Pandas數據處理功能強大,可以方便的實現數據的合并與拼接,具體是如何實現的呢?
Pandas數據處理功能強大,可以方便的實現數據的合并與拼接,具體是如何實現的呢?
一、DataFrame.concat:沿著一條軸,將多個對象堆疊到一起
語法:
- concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
- keys=None, levels=None, names=None, verify_integrity=False, copy=True):
pd.concat()只是單純的把兩個表拼接在一起,參數axis是關鍵,它用于指定合并的軸是行還是列,axis默認是0。
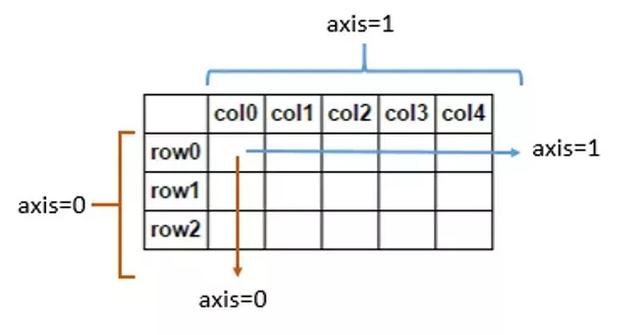
- axis=0代表縱向合并;
- axis=1代表橫向合并。
參數介紹:
- objs:需要連接的對象集合,一般是列表或字典;
- axis:連接軸向;
- join:參數為‘outer’或‘inner’;
- ignore_index=True:重建索引
舉例:
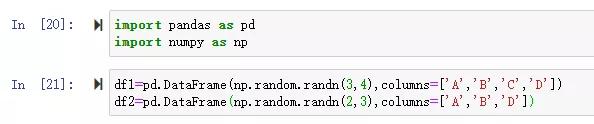
默認縱向拼接

橫向全拼接(默認索引全保留)

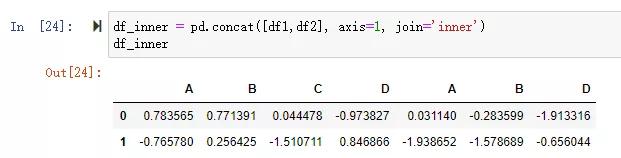
橫向關聯拼接(只保留左右都存在的索引行)
二、DataFrame.merge:類似 vlookup
語法:
- merge(left, right, how='inner', on=None, left_on=None, right_on=None,
- left_index=False, right_index=False, sort=True,
- suffixes=('_x', '_y'), copy=True, indicator=False)
類似于關系型數據庫的連接方式,可以根據一個或多個鍵將不同的DatFrame連接起來。該函數的典型應用場景是,針對同一個主鍵存在兩張不同字段的表,根據主鍵整合到一張表里面。
參數介紹:
- left和right:兩個不同的DataFrame;
- how:連接方式,有inner、left、right、outer,默認為inner;
- on:指的是用于連接的列索引名稱,必須存在于左右兩個DataFrame中,如果沒有指定且其他參數也沒有指定,則以兩個DataFrame列名交集作為連接鍵;
- left_on:左側DataFrame中用于連接鍵的列名,這個參數左右列名不同但代表的含義相同時非常的有用;
- right_on:右側DataFrame中用于連接鍵的列名;
- left_index:使用左側DataFrame中的行索引作為連接鍵;
- right_index:使用右側DataFrame中的行索引作為連接鍵;
- sort:默認為True,將合并的數據進行排序,設置為False可以提高性能;
- suffixes:字符串值組成的元組,用于指定當左右DataFrame存在相同列名時在列名后面附加的后綴名稱,默認為('_x', '_y');
- copy:默認為True,總是將數據復制到數據結構中,設置為False可以提高性能;
- indicator:顯示合并數據中數據的來源情況
舉例:
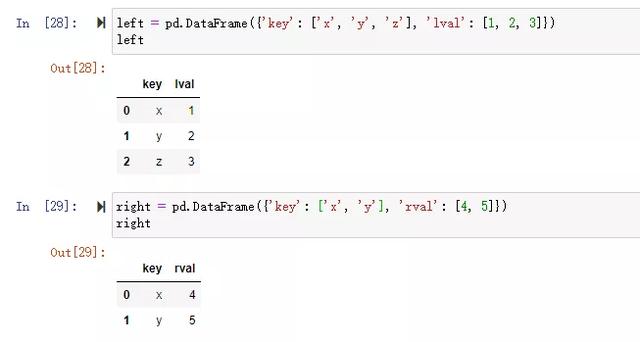
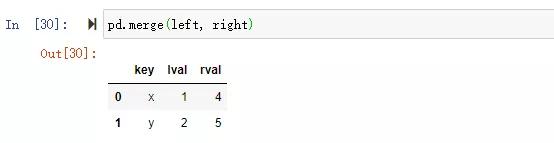
沒有指定連接鍵,默認用重疊列名,沒有指定連接方式,默認inner內連接(取key的交集)
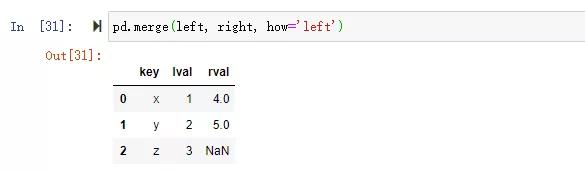
通過how,指定連接方式
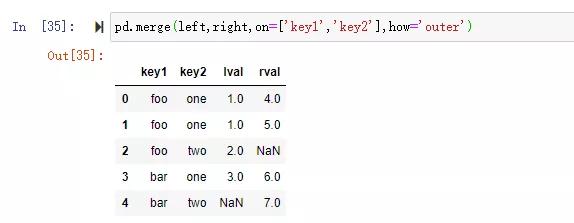
多鍵連接時將連接鍵組成列表傳入,例:pd.merge(df1,df2,on=['key1','key2']

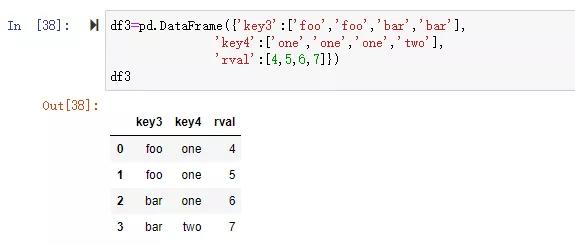
如果兩個對象的列名不同,可以使用left_on,right_on分別指定

三、DataFrame.join:主要用于索引上的合并
語法:
- join(self, other, on=None, how='left', lsuffix='', rsuffix='',sort=False):
其參數的意義與merge方法中的參數意義基本一樣。該方法最為簡單,主要用于索引上的合并。
舉例:
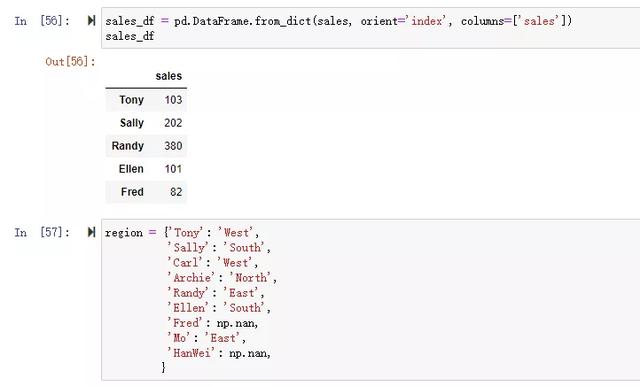
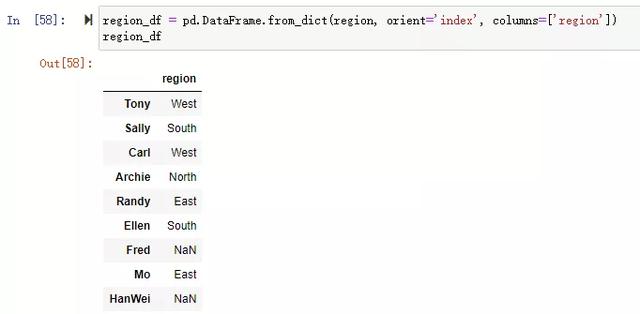
使用join,默認使用索引進行關聯
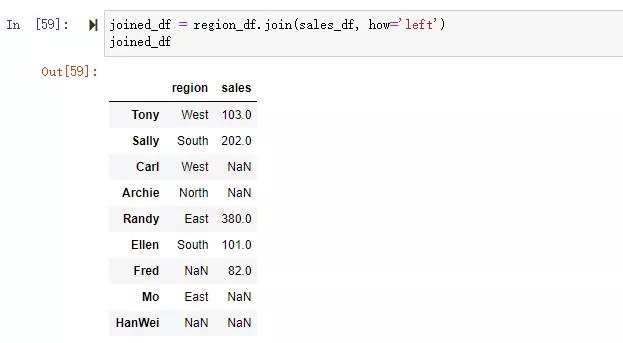
使用merge,指定使用索引進行關聯,代碼更復雜
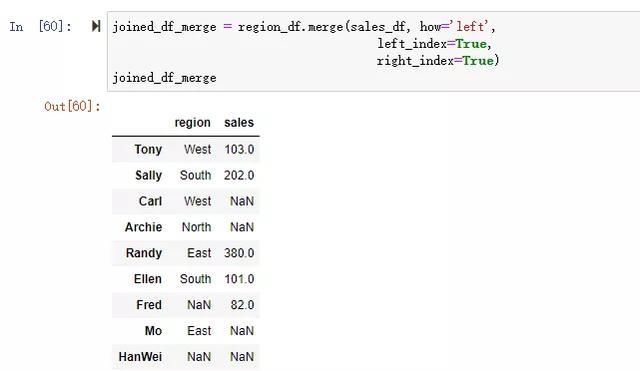
使用concat,默認索引全部保留

四、Series.append:縱向追加Series
語法:
- (self, to_append, ignore_index=False, verify_integrity=False)
舉例:
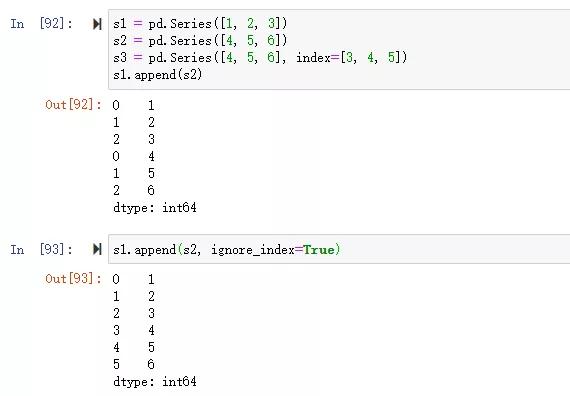
五、DataFrame.append:縱向追加DataFrame
語法:
- (self, other, ignore_index=False, verify_integrity=False, sort=False)
舉例:

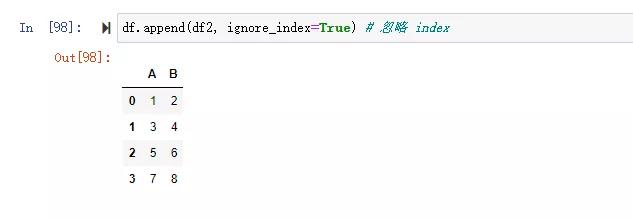
總結
- join 最簡單,主要用于基于索引的橫向合并拼接
- merge 最常用,主要用于基于指定列的橫向合并拼接
- concat最強大,可用于橫向和縱向合并拼接
- append,主要用于縱向追加
責任編輯:未麗燕
來源:
今日頭條











