請務必講清楚你項目里使用的消息中間件(MQ),如何選擇的?
- MQ 為什么在系統中使用?一定要在分布式系統中使用嗎?
- MQ 有哪些中間件?他們有哪些特點?
- MQ 給系統帶來好處的同時有沒有帶來什么問題?如何解決?
在阿里的面試中,面試官問到關于 MQ 的幾個問題:
你的項目中 MQ 的作用?
為什么選擇這款 MQ 作為消息中間件?
重復消費怎么辦?
如何確保消息被消費?
有遇到其他問題嗎?
那么接下來帶著問題先思考下,有好的想法可以在評論區留言,大家一起分享。
消息中間件在系統中的使用
MQ 在系統中到底有哪些作用呢?拋開基本的消息發布訂閱不說,還有以下幾點:
- 分布式系統解耦
- 不需要立即返回的業務異步處理
- 削峰填谷,不直接訪問服務,緩解服務壓力,增加性能
- 日志記錄
分布式系統解耦
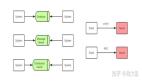
在分布式系統中,要么是通過 rest 調用,要么是通過 dubbo 等 RPC 調用,但是有些場景需要解耦設計,不能直接調用。 比如消息驅動的系統中,消息發送者完成本地業務,發送消息,多平臺的消息消費者服務需要收到推送的消息,然后繼續處理其他業務。
看這兩個架構圖,第一種 BC 都直接依賴 A 服務,那么如果 A 中的接口修改,BC 都要跟著做修改,耦合度高。 第二種,通過 MQ 來作為中間件收發消息,BC 只依賴收到的消息而不是具體的接口,這樣即使 A 服務修改或者增加其他服務,都只要訂閱MQ就行。
不要求實時的業務異步處理
用戶注冊業務流程為例:
- 用戶注冊入庫
- 用戶驗證郵件發送
- 用戶驗證短信發送
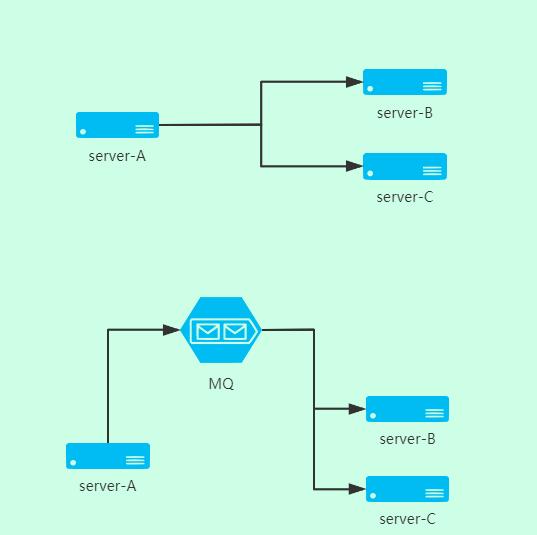
原來的系統設計,這樣的服務流程會串行處理,即先 1-2-3 ;但是這里可以思考下,如果單個服務單臺機器的情況下,注冊用戶特別多,系統能不能抗住?
這里假設各個階段的時間 1 = 50ms , 2 = 50ms , 3 = 50ms,那么一個請求下來就是 all = 150ms; 這里再假設,這個服務器 CPU = 1 , 且只能處理單線程,那么以這種單臺服務器單線程的 QPS 來算;QPS = 1000/150 ≈ 7
現在我要讓這個 QPS * 3 提升三倍,這個時候引入 MQ 服務作為中間件
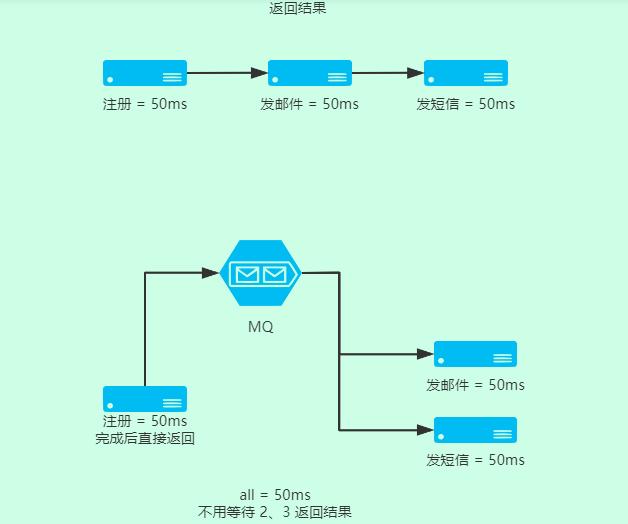
如圖可見,我在 A 服務用戶注冊完成后,就直接返回了,這個時候 MQ 用來發送異步處理消息,B,C 服務分別處理。
A 不用等待 B、C 的返回結果 ,這樣用戶體驗就是只有 50ms 等待時間。而在郵件、短信這個階段,因為網絡延遲原因,用戶可以接受一定時間的等待。
削峰填谷
一般的服務,我們的請求訪問到系統都是直接請求,這樣的模式在用戶訪問量不大的情況下,問題不是很大。 但是如果用戶請求達到了一定的瓶頸或者產生了一些問題,我們就需要考慮優化我們的架構設計,MQ 中間件正是解決辦法之一。
下面以秒殺系統為例分析問題 秒殺系統瞬間百萬并發,怎么處理?一般秒殺系統會進行請求過濾,無效、重復都會被過濾一遍,剩下的才真正進入到秒殺服務、訂單服務。 但即使這樣并發仍然很高,如果網關把全部請求都轉發到下游訂單服務,一樣會壓垮下游系統,造成服務不可用甚至雪崩。
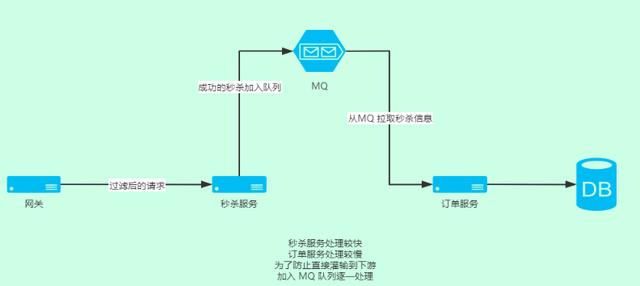
真實的秒殺系統更復雜 ,包含 Nginx 、網關、注冊中心、redis 緩存、mysql 集群、消息隊列集群
解決方式就是將上游處理的較快的任務,加入到隊列處理,下游逐一消費隊列,直到所有隊列消費完成。 假如秒殺服務處理請求數:1000/s,
下游訂單服務處理請求書:10/s,
為了不給下游訂單服務造成壓力,秒殺后的信息發送到隊列,訂單服務就可以從容淡定的每秒處理十個,而不是直接塞 1000 個請求
也不管人家愿意不愿意。
到這里,可以總結下秒殺系統的過濾方式:
頁面按鈕點擊一次置灰
每秒透過請求數限制,例如 100/s,可以使用 Nginx ,sentinel
過濾同一用戶的重復請求,通過用戶唯一標識、商品信息,
通過消息隊列存儲成功的秒殺信息,下游訂單系統處理
日志
所有服務都將日志發送到 MQ 服務用來作為日志存儲。 MQ 作為中間件對日志進行持久化、轉發 大數據服務對 MQ 讀取和進行日志分析
MQ 怎么選
有人上來就是一通性能比較,然后說 RabbitMQ 是世界上最好的 MQ…
你把挑選 MQ 比作挑老婆吧,上來就要全套,膚白貌美、前凸后翹、性感火辣、勤勞能干。。。 真是缺乏社會的教育啊,兄弟 養得起嗎?動不動一套保養套餐,1W/月 守得住嗎?隔壁老王經常來你家吃飯吧,瘋狂腦補。。。 吃的消嗎?紅棗+枸杞+腎寶片,怕是心有余力不足吧
言歸正傳,其實我覺得這是一個思考題,首先我們要看的應該是條件是哪些?
1. 用途?是用來做日志、解耦、還是異步處理
2. 公司情況?人員是否充足,現有人員技術棧情況,人員的技術棧實力
3. 項目情況?項目周期,人員,用戶量,架構設計,是否老項目
4. 主流 MQ 現狀?穩定可靠度,社區活躍度,文檔全面性,云服務支持情況
上圖的例子日志消息就是使用的 kafka,為什么是kafka? Kafka是LinkedIn開源的分布式發布-訂閱消息系統,屬于 Apache 頂級項目,社區活躍。
Kafka主要特點是基于Pull的模式來處理消息消費,追求高吞吐量,一開始的目的就是用于日志收集和傳輸。 后來版本開始支持復制,不支持事務,對消息的重復、丟失、錯誤沒有嚴格要求,適合產生大量數據的互聯網服務的數據收集業務。 但是 kafka 相對來說很重,需要依賴 zookeeper,大公司里使用沒問題,也少不了專人維護。
RocketMQ 是阿里開源的一套可靠消息系統,已經捐贈 Apache 成為頂級項目。剛開始定位于非日志的可靠消息傳輸,其實在日志處理方面性能也不錯。
目前支持的客戶端包括 java,c++,GO ,社區比較活躍,文檔還算全面。但是涉及到核心的要修改還是有難度的,畢竟阿里云靠賣這個服務賺錢呢。
所以如果公司實力不自信還是慎重選擇吧,實在不行可以直接購買云服務,省心省力,還是那句話,看實際情況。
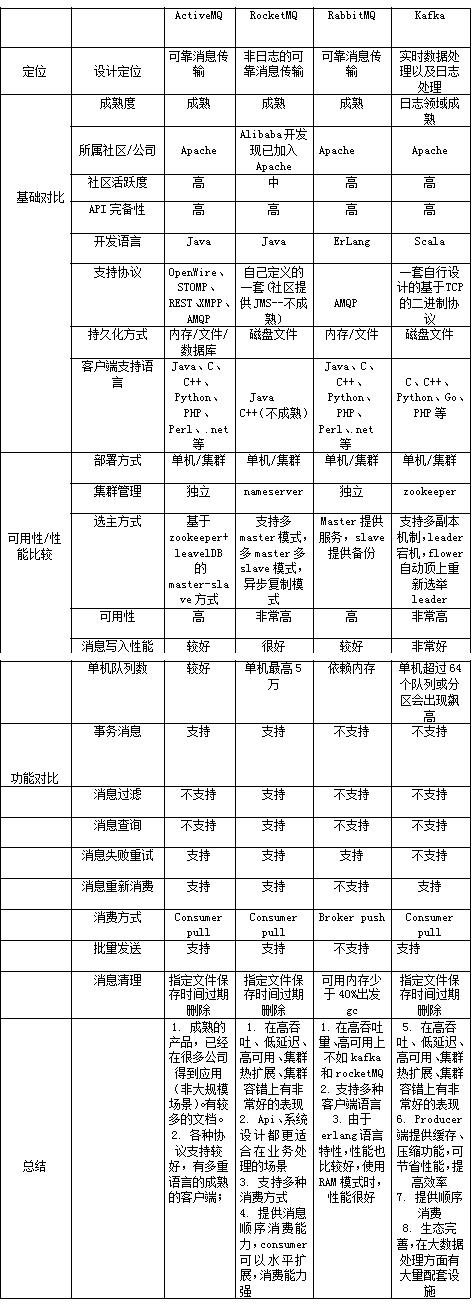
主流 MQ 的特點 下圖是來源網絡的圖片,部分描述已經過時,但是基本不差,僅供參考:
如何確保消息不被重復消費
這里簡單說說,后面專門針對這個問題進行書寫招供。 大致就是一些特殊原因例如網絡原因,服務重啟造成消息消費未被記錄,造成重復消費的可能。 一般的處理方式就是保證接口設計的冪等性,主旨通過唯一標識判斷是否存在。
1. redis 緩存使用,唯一性 token 保存redis,每次消費后刪除 token
2. 唯一主鍵判斷,數據庫判斷是否存在該主鍵記錄,存在則更新,不存在則插入