K8S 集群優(yōu)化之監(jiān)控平臺(tái)的建立之運(yùn)維進(jìn)階
本文轉(zhuǎn)載自微信公眾號(hào)「 twt企業(yè)IT社區(qū)」,作者twt社區(qū) 。轉(zhuǎn)載本文請(qǐng)聯(lián)系twt企業(yè)IT社區(qū)公眾號(hào)。
優(yōu)化首先需要建立起一個(gè)目標(biāo),到底優(yōu)化要達(dá)到一個(gè)什么樣的目標(biāo),期望滿足什么樣的需求,解決業(yè)務(wù)增加過(guò)程中發(fā)生的什么問(wèn)題。監(jiān)控平臺(tái)的建立是為Kubernetes集群及運(yùn)行的業(yè)務(wù)系統(tǒng)得出系統(tǒng)的真實(shí)性能,有了現(xiàn)有系統(tǒng)當(dāng)前的真實(shí)性能就可以設(shè)定合理的優(yōu)化指標(biāo),基本基線指標(biāo)才能合理評(píng)估當(dāng)前Kubernetes容器及業(yè)務(wù)系統(tǒng)的性能。本文介紹了如何建立有效的監(jiān)控平臺(tái)。
1. 監(jiān)控平臺(tái)建設(shè)
所有的優(yōu)化指標(biāo)都是建立在對(duì)系統(tǒng)的充分了解上的,常規(guī)基于Kubernetes的監(jiān)控方案有以下大概有3種,我們就采用比較主流的方案,也降低部署成本和后期集成復(fù)雜度。
主流也是我們選取的方案是Prometheus +Grafana +cAdvisor +(要部署:Prometheus-operator, met-ric-server),通過(guò)Prometheus提供相關(guān)數(shù)據(jù),Prometheus定期獲取數(shù)據(jù)并用Grafana展示,異常告警使用AlertManager進(jìn)行告警。實(shí)際部署過(guò)程中實(shí)施也可以考慮使用Kube-prometheus項(xiàng)目(參見(jiàn)注釋1)整體部署節(jié)省大量工作,以下是官方架構(gòu)圖,涉及到組件如下:
- Prometheus Operator
- Prometheus
- Alertmanager
- Prometheus node-exporter
- Prometheus Adapter for KubernetesMetrics APIs
- kube-state-metrics
- Grafana
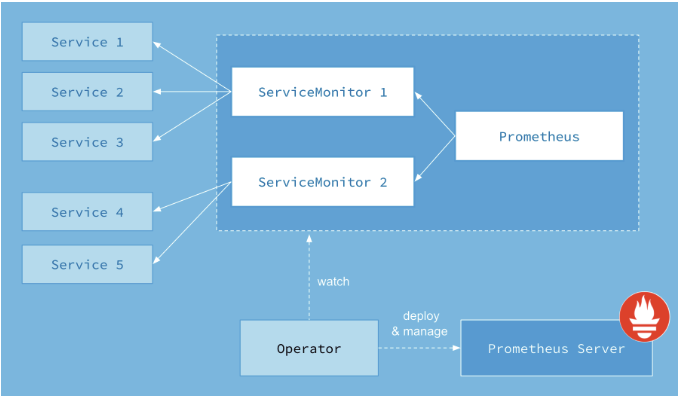
上圖中的Service和ServiceMonitor都是Kubernetes的資源,一個(gè)ServiceMonitor可以通過(guò)labelSelector的方式去匹配一類Service,Prometheus也可以通過(guò)labelSelector去匹配多個(gè)ServiceMonitor。
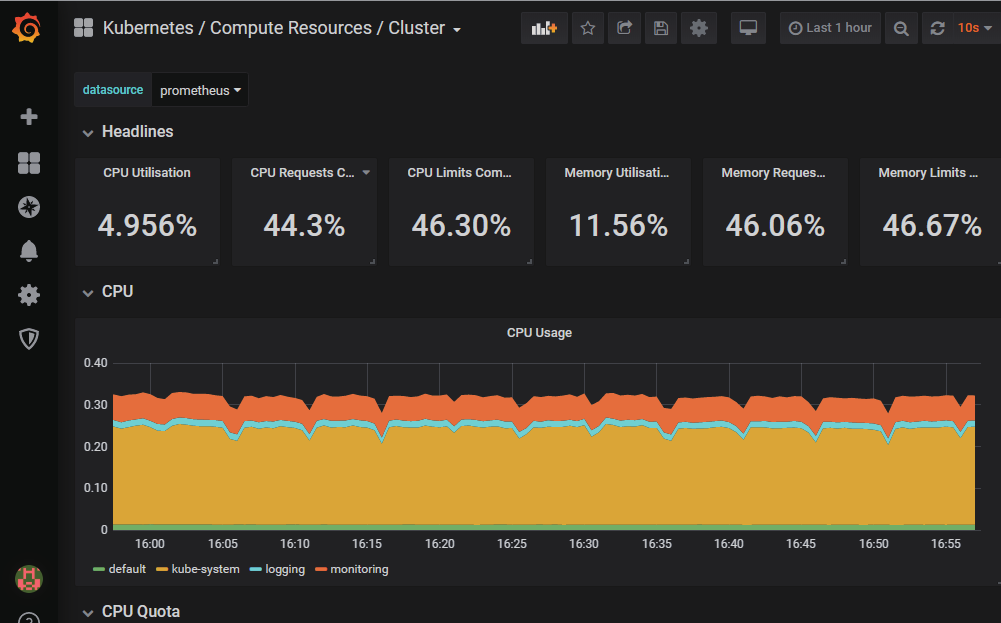
主要監(jiān)控范圍分為:資源監(jiān)控,性能監(jiān)控,任務(wù)監(jiān)控,事件告警監(jiān)控等,因?yàn)楸酒饕v的是性能優(yōu)化,所以側(cè)重點(diǎn)放在性能監(jiān)控上,但是優(yōu)化是全方位的工作所以也會(huì)涉及到資源,健康度,事件,日志等,另外就針對(duì)每種監(jiān)控類型的告警管理。
*注釋1:項(xiàng)目地址如下,就部署方式可參見(jiàn)項(xiàng)目介紹在此就不贅述:
https://github.com/coreos/kube-prometheus
2.數(shù)據(jù)采集
各維度的數(shù)據(jù)采集主要通過(guò)以下方式:
- 部署cAdvisor(參見(jiàn)注釋2)采集容器相關(guān)的性能指標(biāo)數(shù)據(jù),并通過(guò)metrics接口用Prometheus抓取;
- 也可根據(jù)需求可將各種監(jiān)控,日志采集的Agent部署在獨(dú)立的容器中,跟隨Pod 中的容器一起啟動(dòng)監(jiān)督采集各種數(shù)據(jù),具體可根據(jù)實(shí)際需求;
- 通過(guò)Prometheus-node-exporter采集主機(jī)的性能指標(biāo)數(shù)據(jù),并通過(guò)暴露的metrics接口用Prometheus抓取
- 通過(guò)exporter采集應(yīng)用的網(wǎng)絡(luò)性能(Http、Tcp等)數(shù)據(jù),并通過(guò)暴露的metrics接口用Prometheus抓取
- 通過(guò)kube-state-metrics采集k8S資源對(duì)象的狀態(tài)指標(biāo)數(shù)據(jù),并通過(guò)暴露的metrics接口用Prometheus抓取
- 通過(guò)etcd、kubelet、kube-apiserver、kube-controller-manager、kube-scheduler自身暴露的metrics獲取節(jié)點(diǎn)上與k8S集群相關(guān)的一些特征指標(biāo)數(shù)據(jù)。
*注釋2:
node-exporter:負(fù)責(zé)采集主機(jī)的信息和操作系統(tǒng)的信息,以容器的方式運(yùn)行在監(jiān)控主機(jī)上。
cAdvisor:負(fù)責(zé)采集容器的信息,以容器的方式運(yùn)行在監(jiān)控主機(jī)上。
3. 資源監(jiān)控說(shuō)明
資源監(jiān)控主要分為這幾大類:如:CPU,內(nèi)存,網(wǎng)絡(luò),磁盤等信息的監(jiān)控(其它還有對(duì)GPU等監(jiān)控),另外就是對(duì)各種組件服務(wù)的資源使用情況,自定義告警閾值等(簡(jiǎn)單的告警獲可以沿用內(nèi)部已有的,復(fù)雜的告警指標(biāo)需自己根據(jù)集群和業(yè)務(wù)特征通過(guò)獲取參數(shù)進(jìn)行計(jì)算或撰寫PromQL獲取),建立全方位的監(jiān)控指標(biāo)(主要監(jiān)控指標(biāo)項(xiàng)可參見(jiàn)Kube-prometheus部署后的相關(guān)信息,在此就不贅述),主要監(jiān)控項(xiàng)如下;
- 容器 CPU,Mem,Disk, Network等資源占用等情況;
- Node、Pod相關(guān)的性能指標(biāo)數(shù)據(jù);
- 容器內(nèi)進(jìn)程自己主動(dòng)暴露的各項(xiàng)指標(biāo)數(shù)據(jù);
- 各個(gè)組件的性能指標(biāo)涉及組件如:ECTD,API Server, Controller Manager, Scheduler, Kubelet等;
4. 主要指標(biāo)監(jiān)控
主要的監(jiān)控指標(biāo),是依據(jù)Google提出的四個(gè)指標(biāo):延遲(Latency)、流量(Traffic)、錯(cuò)誤數(shù)(Errors)、飽和度(Saturation)。實(shí)際操作中可以使用USE或RED(詳見(jiàn)注釋3和4)方法作為衡量方法,USE用于資源,RED用于服務(wù),它們?cè)诓煌谋O(jiān)控場(chǎng)景有不同維度描述,相結(jié)合能夠描述大部分監(jiān)控場(chǎng)景指標(biāo),合理的使用以下監(jiān)控指標(biāo),有助用戶判斷當(dāng)前K8S集群的實(shí)際運(yùn)行情況,可根據(jù)指標(biāo)變化反復(fù)優(yōu)化各個(gè)參數(shù)和服務(wù),使其達(dá)到更加的狀態(tài),更詳細(xì)的監(jiān)控指標(biāo)信息,可參見(jiàn)Kube-prometheus相關(guān)監(jiān)控信息。
4.1 Cadvisor指標(biāo)采集
cAdvisor(詳見(jiàn)參考1)提供的Container指標(biāo)最終是底層Linux cgroup提供的。就像Node指標(biāo)一樣,但是我們最關(guān)心的是CPU/內(nèi)存/網(wǎng)絡(luò)/磁盤。
1.CPU(利用率)
對(duì)于Container CPU利用率,K8S提供了每個(gè)容器的多個(gè)指標(biāo):
#過(guò)去10秒容器CPU的平均負(fù)載
container_cpu_load_average_10s
#累計(jì)用戶消耗CPU時(shí)間(即不在內(nèi)核中花費(fèi)的時(shí)間)
container_cpu_user_seconds_total
#累計(jì)系統(tǒng)CPU消耗的時(shí)間(即在內(nèi)核中花費(fèi)的時(shí)間)
container_cpu_system_seconds_total
#累計(jì)CPU消耗時(shí)間
container_cpu_usage_seconds_total
#容器的CPU份額
container_spec_cpu_quota
#容器的CPU配額
container_spec_cpu_shares
#查詢展示每個(gè)容器正在使用的CPU
sum(
rate(container_cpu_usage_seconds_total [5m]))
by(container_name)
# 過(guò)去10秒內(nèi)容器CPU的平均負(fù)載值
container_cpu_load_average_10s{container="",id="/",image="",name="",namespace="",pod=""}
#累計(jì)系統(tǒng)CPU消耗時(shí)間
sum(rate(container_cpu_usage_seconds_total{name=~".+"}[1m])) by (name) * 100
#全部容器的CPU使用率總和,將各個(gè)CPU使用率進(jìn)行累加后相除
sum(rate(container_cpu_usage_seconds_total{container_name="webapp",pod_name="webapp-rc-rxli1"}[1m])) / (sum(container_spec_cpu_quota{container_name="webapp",pod_name="webapp-rc-rxli1"}/100000))
2.CPU(飽和度)
sum(
rate(container_cpu_cfs_throttled_seconds_total[5m]))
by (container_name)
3.內(nèi)存
cAdvisor中提供的內(nèi)存指標(biāo)是從可參見(jiàn)官方網(wǎng)站,以下是內(nèi)存指標(biāo)(如無(wú)特殊說(shuō)明均以字節(jié)位單位):
#高速緩存(Cache)的使用量
container_memory_cache
# RSS內(nèi)存,即常駐內(nèi)存集,是分配給進(jìn)程使用實(shí)際物理內(nèi)存,而不是磁盤上緩存的虛擬內(nèi)存。RSS內(nèi)存包括所有分配的棧內(nèi)存和堆內(nèi)存,以及加載到物理內(nèi)存中的共享庫(kù)占用的內(nèi)存空間,但不包括進(jìn)入交換分區(qū)的內(nèi)存
container_memory_rss
#容器虛擬內(nèi)存使用量。虛擬內(nèi)存(swap)指的是用磁盤來(lái)模擬內(nèi)存使用。當(dāng)物理內(nèi)存快要使用完或者達(dá)到一定比例,就可以把部分不用的內(nèi)存數(shù)據(jù)交換到硬盤保存,需要使用時(shí)再調(diào)入物理內(nèi)存
container_memory_swap
#當(dāng)前內(nèi)存使用情況,包括所有使用的內(nèi)存,不管是否被訪問(wèn) (包括 cache, rss, swap等)
container_memory_usage_bytes
#最大內(nèi)存使用量
container_memory_max_usage_bytes
#當(dāng)前內(nèi)存工作集(working set)使用量
container_memory_working_set_bytes
#內(nèi)存使用次數(shù)達(dá)到限制
container_memory_failcnt
#內(nèi)存分配失敗的累積數(shù)量
container_memory_failures_total
#內(nèi)存分配失敗次數(shù)
container_memory_failcnt
4.內(nèi)存(利用率)
通過(guò)PromQL特定條件查詢?nèi)萜鲀?nèi)job內(nèi)存使用情況:
container_memory_usage_bytes{instance="10.10.2.200:3002",job="panamax", name="PMX_UI"}18
kubelet 通過(guò)container_memory_working_set_bytes 來(lái)判斷是否OOM, 所以用 working set來(lái)評(píng)價(jià)容器內(nèi)存使用量更合理,以下查詢中我們需要通過(guò)過(guò)濾“POD”容器,它是此容器的父級(jí)cgroup,將跟蹤pod中所有容器的統(tǒng)計(jì)信息。
sum(container_memory_working_set_bytes {name!~“ POD”})by name
5.內(nèi)存(飽和度)
OOM的異常獲取沒(méi)有直接的指標(biāo)項(xiàng),因?yàn)镺OM后Container會(huì)被殺掉,可以使用如下查詢來(lái)變通獲取,這里使用label_join組合了 kube-state-metrics 的指標(biāo):
sum(container_memory_working_set_bytes) by (container_name) / sum(label_join(kube_pod_con-tainer_resource_limits_memory_bytes,"container_name", "", "container")) by (container_name)
6.磁盤(利用率)
在處理磁盤I/O時(shí),我們通過(guò)查找和讀寫來(lái)跟蹤所有磁盤利用率,Cadvisor有以下指標(biāo)可以做位基本指標(biāo):
#容器磁盤執(zhí)行I/O的累計(jì)秒數(shù)
container_fs_io_time_seconds_total
#容器磁盤累計(jì)加權(quán)I/O時(shí)間
container_fs_io_time_weighted_seconds_total
#查詢?nèi)萜魑募到y(tǒng)讀取速率(字節(jié)/秒)
sum(rate(container_fs_writes_bytes_total{image!=""}[1m]))without (device)
#查詢?nèi)萜魑募到y(tǒng)寫入速率(字節(jié)/秒)
sum(rate(container_fs_writes_bytes_total{image!=""}[1m]))without (device)
最基本的磁盤I/O利用率是讀/寫的字節(jié)數(shù), 對(duì)這些結(jié)果求和,以獲得每個(gè)容器的總體磁盤I/O利用率:
sum(rate(container_fs_reads_bytes_total[5m])) by (container_name,device)
7.網(wǎng)絡(luò)(利用率)
容器的網(wǎng)絡(luò)利用率,可以選擇以字節(jié)為單位還是以數(shù)據(jù)包為單位。網(wǎng)絡(luò)的指標(biāo)有些不同,因?yàn)樗芯W(wǎng)絡(luò)請(qǐng)求都在Pod級(jí)別上進(jìn)行,而不是在容器上進(jìn)行以下的查詢將按pod名稱顯示每個(gè)pod的網(wǎng)絡(luò)利用率:
#接收時(shí)丟包累計(jì)計(jì)數(shù)
container_network_receive_bytes_total
#發(fā)送時(shí)丟包的累計(jì)計(jì)數(shù)
container_network_transmit_packets_dropped_total
#接收字節(jié)(1m)
sum(rate(container_network_receive_bytes_total{id="/"}[1m])) by (id)
#上傳字節(jié)(1m)
sum(rate(container_network_transmit_bytes_total{id="/"}[1m])) by (id)
8.網(wǎng)絡(luò)(飽和度)
在無(wú)法得知準(zhǔn)確的網(wǎng)絡(luò)帶寬是多少的情況下,網(wǎng)絡(luò)的飽和度無(wú)法明確定義,可以考慮使用丟棄的數(shù)據(jù)包代替,表示當(dāng)前已經(jīng)飽和,參見(jiàn)以下參數(shù):
#接收時(shí)丟包累計(jì)計(jì)數(shù)
container_network_receive_packets_dropped_total
#發(fā)送時(shí)丟包的累計(jì)計(jì)數(shù)
container_network_transmit_packets_dropped_total
*注釋3:
在對(duì)于cAdvisor 容器資源,USE方法指標(biāo)相對(duì)簡(jiǎn)單如下:
Utilization:利用率
Saturation:飽和度
Error:錯(cuò)誤
*注釋4:
USE 方法的定義:
Resource:所有服務(wù)器功能組件(CPU,Disk,Services等)
Utilization:資源忙于服務(wù)工作的平均時(shí)間
Saturation:需要排隊(duì)無(wú)法提供服務(wù)的時(shí)間
Errors:錯(cuò)誤事件的計(jì)數(shù)
RED 方法的解釋:
Rate:每秒的請(qǐng)求數(shù)。
Errors:失敗的那些請(qǐng)求的數(shù)量。
參考 1:
更詳細(xì)關(guān)于cAdvisor的參數(shù)信息大家可以一下地址獲取,也可以自己組合更加適用于自己集群的監(jiān)控指標(biāo):
https://github.com/google/cadvisor/blob/master/docs/storage/prometheus.md
參考2:
關(guān)于Node_exporter,大家有興趣可以參考Prometheus項(xiàng)目中關(guān)于Node_exporter里面說(shuō)明如下:
https://github.com/prometheus/node_exporter
5. 事件告警監(jiān)控
監(jiān)控Event 轉(zhuǎn)換過(guò)程種的變化信息,以下只是部份告警信息,Kube-Prometheus項(xiàng)目中有大部分告警指標(biāo),也可以從第三方導(dǎo)入相關(guān)告警事件:
#存在執(zhí)行失敗的Job:
kube_job_status_failed{job=”kubernetes-service-endpoints”,k8s_app=”kube-state-metrics”}==1
#集群節(jié)點(diǎn)狀態(tài)錯(cuò)誤:
kube_node_status_condition{condition=”Ready”,status!=”true”}==1
#集群節(jié)點(diǎn)內(nèi)存或磁盤資源短缺:
kube_node_status_condition{condition=~”OutOfDisk|MemoryPressure|DiskPressure”,status!=”false”}==1
#集群中存在失敗的PVC:
kube_persistentvolumeclaim_status_phase{phase=”Failed”}==1
#集群中存在啟動(dòng)失敗的Pod:
kube_pod_status_phase{phase=~”Failed|Unknown”}==1
#最近30分鐘內(nèi)有Pod容器重啟:
changes(kube_pod_container_status_restarts[30m])>0
6. 日志監(jiān)控
日志也是K8S集群和容器/應(yīng)用服務(wù)的很重要的數(shù)據(jù)來(lái)源,日志中也能獲取各種指標(biāo)和信息,主流的方式采用常駐的Agent采集日志信息,將相關(guān)發(fā)送到Kafka集群最后寫入ES,也通過(guò)Grafana進(jìn)行統(tǒng)一展示各項(xiàng)指標(biāo)。
6.1 日志采集
- 一種方式將各個(gè)容器的日志都寫入宿主機(jī)的磁盤,容器掛載宿主機(jī)本地Volume,采用Agent(Filebeat或Fluentd )采集這個(gè)部署在宿主機(jī)上所有容器轉(zhuǎn)存的日志,發(fā)送到遠(yuǎn)端ES集群進(jìn)行加工處理;
- 另一種是對(duì)于業(yè)務(wù)組(或者說(shuō)Pod)采集容器內(nèi)部日志,系統(tǒng)/業(yè)務(wù)日志可以存儲(chǔ)在獨(dú)立的Volume中,可以采用Sidecar模式獨(dú)立部署日志采集容器,來(lái)對(duì)進(jìn)行日志采集,對(duì)于DaemonSet和Sidecar這兩種日志采集模式,大家可以根據(jù)實(shí)際需要選擇部署;
- 通過(guò)部署在每個(gè)Node上的Agent進(jìn)行日志采集,Agent會(huì)把數(shù)據(jù)匯集到Logstash Server集群,再由Logstash加工清洗完成后發(fā)送到Kafka集群,再將數(shù)據(jù)存儲(chǔ)到Elasticsearch,后期可通過(guò)Grafana或者Kibana做展現(xiàn),這也是比較主流的一個(gè)做法。
6.2 日志場(chǎng)景
主要需要采集的各種日志分為以下場(chǎng)景:
1.主機(jī)系統(tǒng)內(nèi)核日志采集:
- 一方面是主機(jī)系統(tǒng)內(nèi)核日志,主機(jī)內(nèi)核日志可以協(xié)助開(kāi)發(fā)/運(yùn)維進(jìn)行一些常見(jiàn)的問(wèn)題分析診斷,如:Linux Kernel Panic涉及的(Attempted to kill the idle task,Attempted to kill init,killing interrupt handler)其它致命異常,這些情況要求導(dǎo)致其發(fā)生的程序或任務(wù)關(guān)閉,通常異常可能是任何意想不到的情況;
- 另一方面是各種Driver 驅(qū)動(dòng)異常,比如:Driver內(nèi)核對(duì)象出現(xiàn)異常或者說(shuō)使用GPU的一些場(chǎng)景,各種硬件的驅(qū)動(dòng)異常可能是比較常見(jiàn)的錯(cuò)誤;
- 再就是文件系統(tǒng)異常,一些特定場(chǎng)景(如:虛機(jī)化,特定文件格式),實(shí)際上是會(huì)經(jīng)常出現(xiàn)問(wèn)題的。在這些出現(xiàn)問(wèn)題后,開(kāi)發(fā)者是沒(méi)有太好的辦法來(lái)去進(jìn)行監(jiān)控和診斷的。這一部分,其實(shí)是可以主機(jī)內(nèi)核日志里面來(lái)查看到一些異常。
2.組件日志采集:
K8S集群中各種組件是集群非常重要的部份,既有內(nèi)部組件也有外部的如:API Server, Controller-man-ger,Kubelet , ECTD等, 它們會(huì)產(chǎn)生大量日志可用于各種錯(cuò)誤分析和性能優(yōu)化,也能幫助用戶很好分析K8S集群各個(gè)組件資源使用情況分析,異常情況分析;還有各種第三方插件的日志(尤其是一些廠商貢獻(xiàn)的網(wǎng)絡(luò)插件或算法),也是優(yōu)化分析的重點(diǎn);
3.業(yè)務(wù)日志采集:
業(yè)務(wù)日志分析也是優(yōu)化的很重要的環(huán)節(jié),業(yè)務(wù)系統(tǒng)自身的特性(如:web類,微服務(wù)類,API 接口類,基礎(chǔ)組件類)都需要日志來(lái)分析,結(jié)合后面的資源預(yù)測(cè)和業(yè)務(wù)部署章節(jié)能否更好把握業(yè)務(wù)特性,創(chuàng)建合理的發(fā)布配置和Pod配置,根據(jù)日志分析業(yè)務(wù)訪問(wèn)量,活動(dòng)周期,業(yè)務(wù)峰值,調(diào)用關(guān)系等優(yōu)化整個(gè)過(guò)程。