“算透”用戶,抖音為什么讓人沉迷?_IT技術周刊第631期
誰不愛看可愛的小狗與頑皮的小貓?特別是在全球受新冠疫情影響而進行全面隔離的當下,我們更需要歡樂的視頻來調劑自己的心情。
但這并不足以解釋抖音為什么能獲得如此之多的青睞。在不到兩年時間里,它從一個只有少數粉絲的“對口型”應用,發展成今年月均近8億活躍用戶的“病毒式”應用。甚至,帶有“新冠病毒”標簽的抖音視頻在應用中被播放了足足530億次。
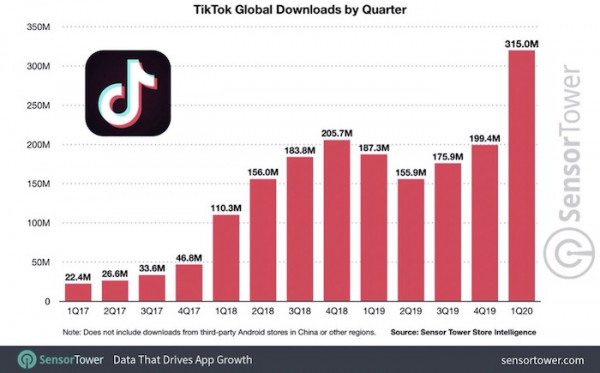
▲ 抖音成為2020年1月美國下載數量最高的應用 ▲ 抖音全球下載量
抖音最顯著的特色,在于各類洗腦歌曲加上有趣的啞劇式短視頻。
用戶每天平均在這款應用上耗費52分鐘,相比之下,Snapchat、Instagram以及Facebook的日均使用時長分別為26分鐘、29分鐘與37分鐘。
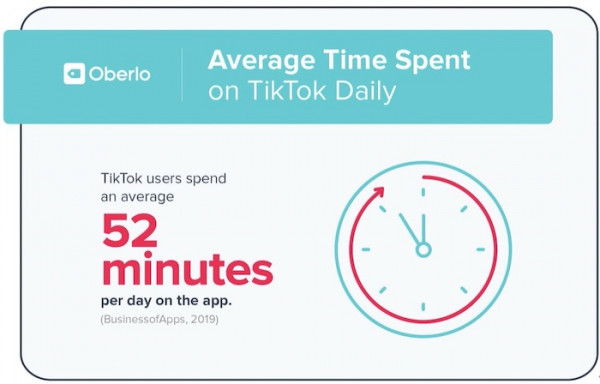
▲ Oberlo統計的使用時長報告
此外,這款只支持60秒短視頻的應用中還充斥著模因、喜劇、舞蹈及無數才華橫溢的用戶。憑借著業內最強大的推薦引擎之一,我們無需搜索或擁有明確的訴求,就能很快找到符合自己口味的內容。點擊一下,引擎會幫你生成個性化建議。
這種無窮無盡的快速刺激帶來了輕松快樂的使用感受,最終讓用戶沉迷其中、無法自拔。有人將抖音稱為浪費時間的終極殺手,并表示“在抖音上感覺過了5分鐘,實際上已經過了1個小時。”
而在今天的文章中,我們將探討抖音如何使用機器學習技術通過交互機制分析用戶的興趣與偏好,并據此為用戶展示不同的個性化推薦內容。
對于數據科學社區來說,推薦引擎早已不是什么新鮮事物。但由于一直缺少圖像識別或者語言生成等抓人眼球的最新“特效”,不少人傾向于將其劃入傳統AI系統一類。
盡管如此,推薦引擎仍是一類重要AI系統,而且幾乎遍布各類在線服務與平臺。從youtube視頻推薦、到亞馬遜發布的廣告郵件、再到Kindle書城中的熱點圖書,一切都是推薦引擎的功勞。
根據Gomez-Uribe與Netflix公司街道口負責人Neil Hunt發表的研究論文,個性化與推薦的綜合作用每年可為Netflix節約超過10億美元。此外,有80%的訂閱者會從引擎提供的推薦列表中選擇視頻。
那么,抖音的獨門絕技是什么?
1.關于推薦引擎
[ 如果您對推薦引擎的基本概念已經非常熟悉,可以直接閱讀下一章節 ]
目前網絡上關于推薦引擎的說明文章及在線課程所在多有,因此這里只給大家提供兩條相關學習資源鏈接:
-
從零開始構建推薦引擎的綜合指南[注1](閱讀時長大約需要35分鐘,重現其中的Python代碼約需要40到60分鐘)
-
來自吳恩達的推薦引擎指南[注2](視頻時長約1個小時)
除了這些必要基礎之外,工業級推薦引擎還需要強大的后端與架構設計以實現全面集成。下面來看相關示例:
▲ 推薦引擎(由Catherine Wang創建,版權所有)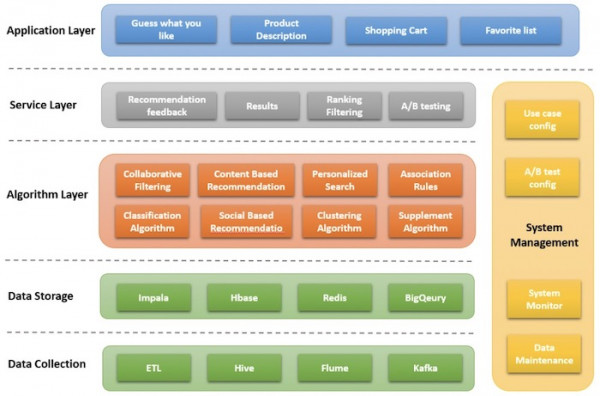
實時系統應具備堅實的數據基礎(用于收集與存儲),支持頂端多個抽象層(算法層、服務層與應用層),借此解決不同的業務問題。
2.抖音推薦系統設計原型 “以用戶為中心的設計”正是抖音的原型核心。簡單來說,抖音只會推薦當前用戶喜歡的內容,并從應用冷啟動開始不斷貫徹這種對用戶偏好的跟蹤與強化。
如果你點開了舞蹈視頻,那么系統會初步將你的偏好定制為娛樂類,而后持續跟蹤你的行為以進一步分析,最終為你提供高度貼合喜好的精確推薦。
下面說說高級工作流。
▲ 三大核心組件(由Catherine Wang創建,版權所有)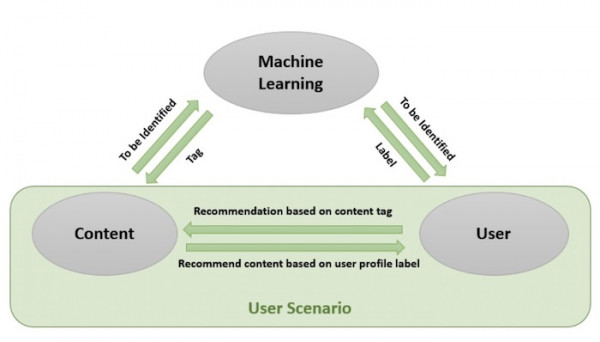
在抖音的原型體系中,包含三大核心組件:1)標記內容;2)創建用戶資料與用戶場景;3)訓練并提供推薦算法。
下面,我們將具體對這三大組件做出說明。
2.1 數據與特征
首先是數據。如果用更正式的語言描述推薦模型,那它實際上是一項負責將用戶滿意度與“用戶生成內容”匹配起來的函數。要實現這個目標,我們需要從三個維度輸入數據。
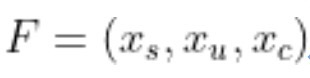
-
內容數據——抖音是一個包含大量用戶生成內容的平臺。每種類型的內容都有其特征,而系統需要能夠識別并區分各類內容以實現可靠的推薦效果。
-
用戶數據——其中包括興趣標簽、職業、年齡、性別、人口統計信息等等,也包含基于ML的客戶集群內潛在特征。
-
場景數據——這部分數據用于跟蹤用戶在不同場景下的個人偏好變化。例如,用戶在工作、旅行或者通勤時,分別更喜歡看到哪些類型的視頻。
在收集到相關數據之后,系統就會導出四種類型的關鍵工程特征,并將其輸入至推薦引擎當中。
-
關聯特征:表示內容屬性與用戶標簽之間的關聯,包括關鍵字匹配、分類標簽、源匹配、主題標簽以及用戶與內容間矢量距離等潛在特征。
-
用戶場景特征:根據場景數據進行工程處理,包括地理位置、當前時間與事件標簽等等。
-
趨勢特征:基于用戶交互并表現為全局趨勢、熱門話題、熱門關鍵字、趨勢主題等等。
-
協同特征:基于協同過濾技術,負責在狹窄推薦(偏見)與協同推薦(概括)之間尋求平衡。更準確地說,其不信會考慮單一用戶的歷史記錄,同時還會分析相似用戶組之間的協同行為(點擊、贊、關鍵字、主題等)。而推薦引擎模型,將通過學習上述特征以預測特定內容在特定場景中是否適合特定用戶。
2.2 隱性目標
在推薦模型當中,點擊率、觀看時長、贊、評論與轉發等都屬于明確可量化的目標。我們可以使用模型或算法對這些指標進行擬合,而后做出結論性的預測。
但除此之外,還存在其他一些無法通過這些可量化指標進行評估的隱性目標。
例如,為了維護健康的社區與生態系統,抖音一直努力控制與暴力、詐騙、色情及謠言相關的內容,希望保證平臺上發布的內容更加貼近事實。
為此,自然需要在可量化模型目標之外定義新的邊界控制框架(內容審核系統)。
2.3 算法
推薦目標可以指定為經典的機器學習問題,而后通過協同過濾模型、邏輯回歸模型、分解機、GBD以及深度學習等多種算法對問題求解。
▲ 協同過濾示意圖
工業級的推薦系統往往需要靈活且可擴展的機器學習平臺以構建實驗管道,借此快速訓練各類模型,而后將不同模型疊加起來進行實時服務。(例如將強化學習、DNN、SVM以及CNN結合使用)
除了主推薦算法之外,抖音還需要訓練內容分類算法與用戶偏好算法。下面來看在實現內容分析方面,抖音建立起的多層級分類架構。
▲ 多層級分類樹(由Catherine Wang創建,版權所有)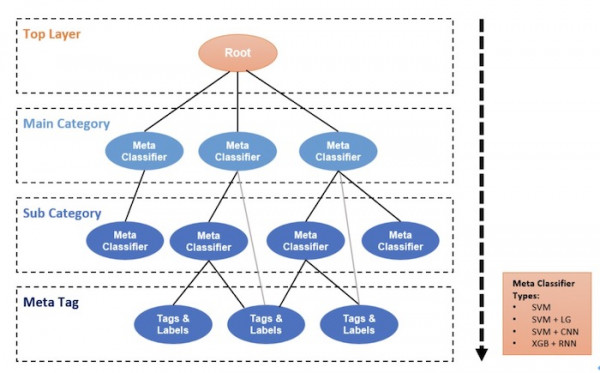
我們從主root起步,一層層下探。首先是主類別與子類別。與獨立的分類器相比,這種多層級分類機制能夠更好地解決數據偏斜的問題。
2.4 訓練機制
抖音使用實時在線訓練協議,因此能夠以較少的計算資源需求提供更快的反饋速度。這兩點對于流媒體與信息流產品無疑非常重要。
訓練系統會即時捕捉用戶的行為與動作,并將其反饋給模型以在下一次響應中有所體現。(例如,當您點擊新的視頻時,饋送內容會根據您的最新操作而快速更改)
據個人推測,抖音很可能是使用Storm Cluster處理實時樣本數據,包括點擊、展示、收藏、贊、評論與共享等。
他們還構建起模型參數與特征服務器(分別存儲特征與模型),借此進一步提升系統性能。其中特征存儲可保存并交付數千萬項原始特征與工程矢量,而模型存儲則負責模型與經調優參數的維護與交付。
▲ 在線訓練機制(簡化版)(由Catherine Wang創建,版權所有)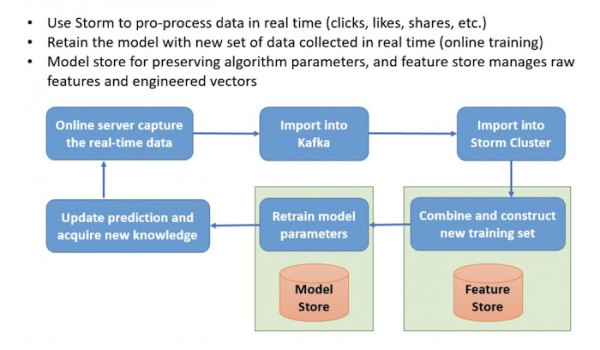
下面我們對訓練流程做出總結:1)在線服務器捕捉實時數據,并將其存儲在Kafka當中;2)Storm Cluster使用Kafka數據并生成特征;3)特征存儲負責收集新特征與推薦標簽,并據此構建起新的訓練集;4)在線訓練管道重新訓練模型參數,并將參數保存在模型存儲中;5)更新客戶端推薦列表,捕捉新的反饋(用戶操作)并再次循環。
3.抖音的推薦工作流
抖音一直未向公眾或技術界公開其核心算法。但通過該公司發布的零散信息,以及極客社區通過逆向工程發現的蛛絲馬跡,我們初步得出以下結論。(免責聲明——以下內容皆為作者個人的解釋與推斷,可能與抖音的實際情況有所出入)
▲ 推薦工作流(由Catherine Wang創建,版權所有)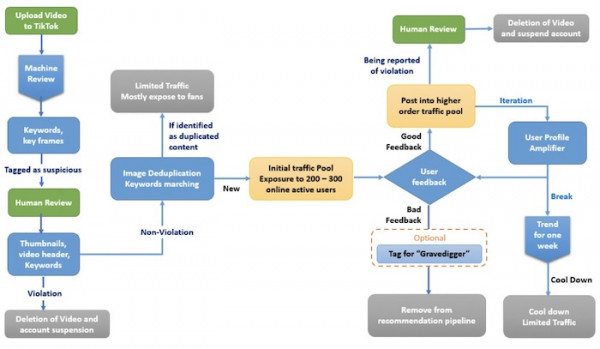
步驟0:用戶生成內容雙審核系統 (UGC)
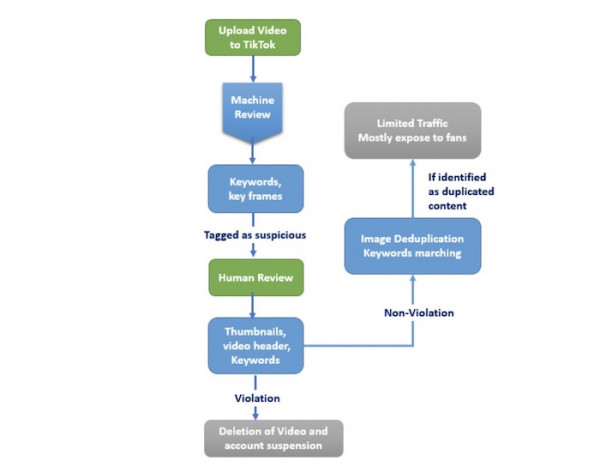
在抖音,每天有數百萬用戶上傳自己制作的內容。惡意內容很可能從單一機器審核系統中發現漏洞并成功漏網,而過于龐大的上傳量也讓手動審核變得不切實際。為此,雙審核成為抖音公司的主要視頻內容篩選算法。
-
機器審核:總體來看,雙審核模型(基于計算機視覺)可以識別用戶上傳內容中的視頻圖像與關鍵字。它主要提供兩大核心功能:1)檢查剪輯內容中是否存在違規并檢查文本信息。如果懷疑存在問題,內容將被攔截并標記為黃色或紅色,以供人工審核員進行復核。2)提取視頻中的圖片與關鍵幀,抖音的雙審核算法隨后將這些內容與龐大的歸檔內容庫進行匹配。這些副本將被渲染為低精度版本,借此降低流量占用并減輕推薦引擎的處理負擔。
-
手動審核:主要關注三個問題:視頻標題、封面縮略圖與視頻關鍵幀。對于被雙審核模型標記為可疑的內容,技術人員將進一步做出手動檢查。如果確定違規,則刪除該視頻并凍結上傳賬戶。
步驟1:冷啟動
抖音推薦機制的核心在于信息流漏斗。在內容通過雙審核過濾之后,將被放入冷啟動流量池內。例如,當用戶的新視頻成功通過審核流程,抖音會為其分配200到300個活躍用戶的初始流量,保證你的內容初步獲得向用戶展示的機會。
在這種機制下,新創作者可以與意見領袖們(可能已經擁有成千上萬關注者)站上相同的起點,完全依靠作品質量展開正面競爭。
步驟2:基于指標的權重機制
通過初始流量池,我們的視頻已經獲得了幾千次瀏覽,而這些數據將被進一步收集與分析。分析中考量的指標主要包括贊、觀看、完整觀看、評論、關注、轉發與分享等數據。
接下來,推薦引擎會根據這些初始指標與賬戶得分(無論您是否身為高水平創作者)對內容進行權重評分。
根據評分結果,前10%的視頻將獲得額外10000到100000次推薦展示的機會。
步驟3:用戶偏好放大器
來自步驟2內流量池階段的反饋將接受進一步分析,幫助系統判斷是否使用用戶偏好放大器。在這一步中,高質量的內容將被投放至特定的用戶組(例如體育迷、時尚愛好者)中并得到進一步加強與放大。
這類似于“猜你喜歡什么”的概念。推薦引擎將建立用戶個人偏好庫,以便在內容與用戶組之間找到最佳匹配。
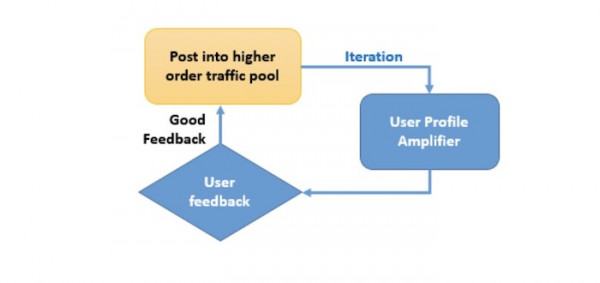
步驟4:精品趨勢池
只有低于1%的內容最終能夠進入趨勢池。趨勢池中的內容將獲得遠超其他視頻的曝光量,包括以無差別方式推薦給所有用戶。
其他步驟:延遲曝光
部分抖音用戶可能會注意到,自己的內容在發布數周之后,才突然獲得了巨大的關注與點擊——在此之前,觀看量與轉發量都一樣比較平均。這是怎么回事?
這主要有兩個原因:
-
首先,抖音使用一種昵稱為“掘墓人”的算法,可以回溯舊有內容并挖掘出高質量的曝光對象。如果您的內容被這種算法選中,則表明您的賬戶中擁有足夠的垂直視頻以獲得清晰的定位標簽。換言之,建立明確的標簽能夠幫助您的內容得到“掘墓人”算法的青睞。
-
第二是“時尚效應”。換句話說,如果您的某條內容獲得了數百萬次觀看,那么觀看者會主動前往您的主頁,查看您之前發布過的其他內容。這是個主動探索并發現寶藏的過程,也在一定程度上增加了用戶的成就感。
局限性:流量峰值
如果某段內容通過信息流漏洞(雙審核、權重迭代與放大),那么創建者的賬戶將獲得大量展示機會、用戶交互與關注群體。
但根據研究,這種高曝光時間窗口極窄。通常,該窗口只會持續一周左右;在此之后,內容與賬戶將快速“涼涼”,連隨后發布的內容也無法得到人們的關注。
為什么會這樣?
這主要是因為抖音希望盡量為內容制作者們提供更公平的發布環境,消除算法中的意外偏見。通過這種設計,推薦引擎不會偏向于特定類型的內容,這將保證各類新內容都有平等的機會成為新的爆款。
【注】:
1.https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-recommendation-engine-python/
【參考資料】:
1.https://www.businessofapps.com/data/tik-tok-statistics/
2.https://mediakix.com/blog/top-tik-tok-statistics-demographics/
3.https://en.wikipedia.org/wiki/TikTok
4.http://shop.oreilly.com/product/9780596529321.do
5.https://sensortower.com/
6.https://www.nytimes.com/2020/06/03/technology/tiktok-is-the-future.html