MESI協議,JMM,線程常見方法等
本文轉載自微信公眾號「 學習Java的小姐姐」,轉載本文請聯系 學習Java的小姐姐公眾號。
前言
我們在找工作時,經常在招聘信息上看到有這么一條:要求多線程并發經驗。無論是初級程序員,中級程序員,高級程序員,也無論是大廠,小廠,并發編程肯定是少不了的。
但是網上很多博文直接上來就講JUC,沒有從基礎出發,所以該篇旨在講明并發基礎,主要為計算機原理,線程常見方法,Java虛擬機方法的知識,為后面的學習保駕護航,話不多說,開始吧。
緩存一致性——MESI協議
CPU多級緩存官方概念
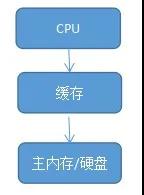
CPU在摩爾定律的指導下以每18個月翻一番的速度在發展,然而內存和硬盤的發展速度遠遠不及CPU,所以才引入了緩存的概念。我們可以從下圖看出在CPU和主內存之間加了一個緩存,用來提升交互速度。
隨著CPU的速率越來越快,人們對計算機性能要求越來越高,傳統的緩存已經滿足不了,所以引入了多級緩存,包括一級緩存,二級緩存,三級緩存,具體如圖所示。
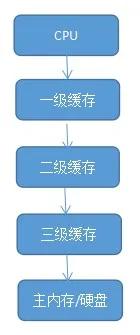
一級緩存:基本上都是內置在cpu內部,和cpu一個速度運行,能有效的提升cpu的工作效率。當然數量越多,cpu工作效率就會越高,但是由于cpu的內部結構限制了其大小,所以一級緩存的數據并不大。
二級緩存:主要作用是協調一級緩存和內存之間的工作效率。cpu首先用的是一級內存,當cpu的速度慢慢提升之后,一級緩存就不夠cpu的使用量了,這就需要用到二級內存。
三級緩存:和一級緩存與二級緩存的關系差不多,是為了在讀取二級緩存不夠用的時候而設計的一種緩存手段,在有三級緩存cpu之中,只有大約百分之五的數據需要在內存中調取使用,這能提升cpu不少的效率,從而cpu能夠高速的工作。
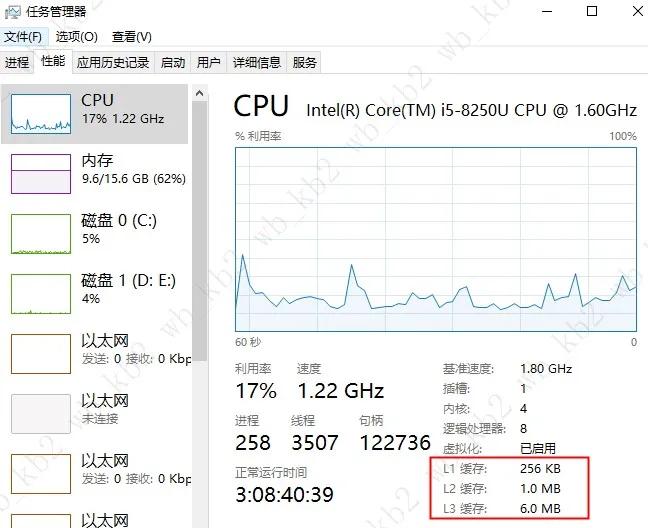
我們可以看下本機的緩存情況。
CPU多級緩存白話翻譯
只有一級緩存情況:
我們可以將CPU當做我們本人,緩存區當做超市,主內存當做工廠,如果想要買東西(取數據)就先去超市(緩存區)買(取),如果超市(緩存區)沒有,就去工廠(主內存)里面買(取)。
多級緩存情況:
我們可以將CPU當做本人,一級緩存當做樓下小區里面的小賣部,二級緩存當做普通超市,三級緩存當做大型超市,主內存當做工廠,如果想買東西先去樓下小賣部(一級緩存),小賣部(一級緩存)沒有的話,就去普通超市(二級緩存),如果普通超市(二級緩存)還沒有,就去大型超市(三級緩存),如果大型超市(三級緩存)還沒有,就直接去工廠(主內存)取。這些緩存的出現使得我們不必每次都去工廠(主內存)買東西(取數據),節省了時間,提升了速度。
為什么需要CPU緩存
CPU速率太快,快到內存跟不上,在處理器處理周期內,CPU常常等待內存,造成資源的浪費。
緩存的意義
時間局限性:如果某個數據被訪問,在將來的某個時間也可能被訪問。(白話翻譯就是如果我今天買了薯片,那么以后我可能還會買薯片,畢竟是吃貨O(∩_∩)O)
空間局限性:如果某個數據被訪問,那么他相鄰的數據也有可能被訪問。(白話翻譯就是如果我今天買了薯片,那么我可以還會買其他膨化食品,畢竟他們兩挨在一起)
帶來的問題
對于多核系統來說, 每個核中緩存數據不一致的問題。
解決方式一——總線加鎖(性能太低)
CPU從主內存讀取數據到緩存區,并在總線對這個數據進行加鎖,其他CPU無法去讀寫這個數據,直到這個CPU使用完數據,鎖被釋放了才訪問。就比如我想去超市買一個辣條,但是張三也想買,在我買的過程中,就給辣條加了鎖,張三根本碰不到辣條,我買的過程非常慢,那張三不急死啦嘛。
解決方式二——MESI協議(重點)
針對上面緩存數據不一致的情況,提出了MESI協議用以保證多個CPU緩存中共享數據的一致性,定義了緩存行Cache Line四個狀態,分表是M(Modified),E(Exclusive),S(Share),I(Invalid)四種。
- M(Modified修改):該行數據有效,數據被修改了,和內存中的數據不一致,數據只能存在于本緩沖區中。
- E(Exclusive獨占):這行數據有效,數據和內存中的數據一致,數據只存在于本Cache中。
- S(Shared共享):這行數據有效,數據和內存中的數據一致,數據存在于很多Cache中。
- I(Invalid無效):這行數據無效
MESI狀態之間的遷移:
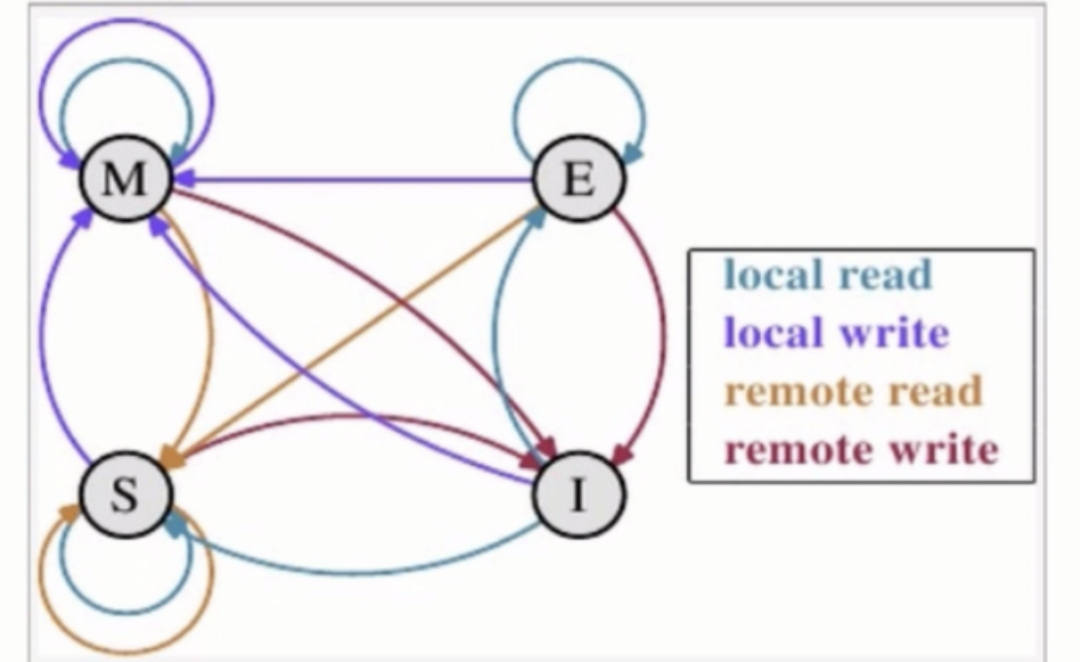
這圖一看是很懵逼的,咱慢慢來看哈,慢慢體會這些變化哈。
當前狀態是Modified
- 內核讀取本地緩存中的值(local read):從緩存區中讀取數據,狀態不變,還是修改M
- 本地內核寫本地緩存中的值(local write):從緩存區中修改數據,狀態不變,還是修改M
- 其它內核讀取其他緩存中的值(remote read):數據被寫入內存,其他內存讀取到最新數據,即為共享S
- 其它內核更改其他緩存中的值(remote write):數據被寫入內存,其他內存讀取到最新數據,并修改和提交,此緩存區的狀態為無效I
當前狀態是Exclusive
- 內核讀取本地緩存中的值(local read):從緩存區中讀取數據,狀態不變,還是獨占E
- 本地內核寫本地緩存中的值(local write):從緩存區中修改數據,即為修改M
- 其它內核讀取其他緩存中的值(remote read):數據被寫入內存,其他內存讀取到數據,即為共享S
- 其它內核更改其他緩存中的值(remote write):數據被寫入內存,其他內存讀取到數據,并修改提交,即為無效I
當前狀態是Share
- 內核讀取本地緩存中的值(local read):從緩存區中讀取數據,狀態不變,還是共享S
- 本地內核寫本地緩存中的值(local write):在緩存區中修改數據,即為修改M
- 其它內核讀取其他緩存中的值(remote read):數據被寫入內存,其他內存讀取數據,即為共享S
- 其它內核更改其他緩存中的值(remote write):數據被寫入內存,其他內存讀取數據,并修改提交,即為無效I
當前狀態是Invalid
- 內核讀取本地緩存中的值(local read):如果其他緩存里面沒有這個值,狀態即為獨享E;如果其他緩存里有這個值,狀態即為共享S
- 本地內核寫本地緩存中的值(local write):在緩存區中修改數據,即為修改M
- 其它內核讀取其他緩存中的值(remote read):其他核的操作與他無關,即為無效I
- 其它內核更改其他緩存中的值(remote write):其他核的操作與他無關,即為無效I
并行和并發的區別
并發:同一時刻只能有一個指令執行,但多個指令被CPU輪換執行,因為時間間隔很短,會造成同時執行的錯覺。
并行:同一時刻多條指令在多個處理器同時執行,不管是微觀,還是宏觀上,都是同時執行的。
舉個例子,并發就是一個家庭主婦既要燒飯,也要帶娃,也要打掃房間,如果每個事情只做一分鐘,然后輪換,從宏觀上來說,會造成同時執行的錯覺。并行就是該家庭主婦請了兩個保姆,一個專職負責燒飯,一個專職負責帶娃,自己專職負責打掃衛生,不管從宏觀還是微觀上來看,他們都是同時執行的。
某位大佬曾經說兩者的區別,并發是同一時間應對多件事情的能力,并行是同一時間去做多件事情的能力。作為一個工科生,不知道如何夸大佬,只知道喊666。
進程和線程的關系
進程是用來加載指令,管理內存,執行語句的。
線程是進程的一部分,一個進程可以分為1個或多個線程。
網易云音樂的打開,就是開啟了一個進程,而播放,查找,評論等都是線程。
線程之間的通信
線程之間的通信比較簡單,可以通過他們的共享內存通信,具體可以看下面Java內存模式部分。
進程之間的通信
進程之間的通信比較復雜,對于同一臺計算機而言,其通信稱為IPC;對于不同計算機,其通信需要網絡并遵循彼此約定的協議,如HTTP等。這部分偏硬件,咱也不敢說,咱也不敢問。
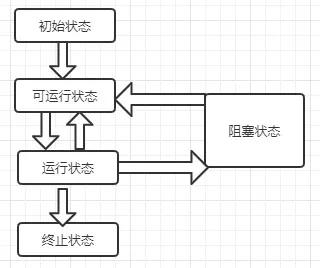
線程的狀態(從硬件層面)
初始狀態:新建new一個線程,還沒有進行任何步驟,還未和硬件關聯上。
可運行狀態:當調用start方法,即進行可運行狀態(就緒狀態),但是這個時候還沒獲取到時間片,具體什么時候運行取決于硬件。
運行狀態:當CPU分配的時間片到某個線程了,該線程即可進入運行狀態。
阻塞狀態:當線程調用阻塞API,線程并沒有用到CPU,其進入阻塞狀態。
終止狀態:當一個線程運行結束了,即進入終止狀態。
一些常見的線程操作
創建線程的三種方式
線程和任務合并
- Thread thread=new Thread(){
- public void run(){
- System.out.println("開始");
- }
- };
線程和任務分開
- Runnable runnable=new Runnable() {
- @Override
- public void run() {
- System.out.println("開始");
- }
- };
- Thread thread=new Thread(runnable);
FutureTask返回執行結果
- FutureTask<String> futureTask=new FutureTask<String>(new Callable<String>() {
- @Override
- public String call() throws Exception {
- return "線程的返回值";
- }
- });
- Thread thread=new Thread(futureTask);
線程啟動start
- thread.start();
這里start是進入就緒狀態,即可運行狀態,具體什么時候要看CPU。
等待線程運行結束join
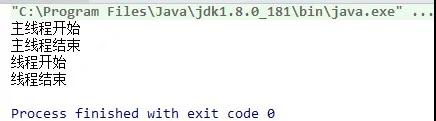
未加join情況:
- Runnable runnable=new Runnable() {
- @Override
- public void run() {
- System.out.println("線程開始");
- try {
- sleep(4000L);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println("線程結束");
- }
- };
- //創建線程
- Thread thread=new Thread(runnable);
- //啟動線程
- System.out.println("主線程開始");
- thread.start();
- System.out.println("主線程結束");
運行結果:
使用join的情況:
- Runnable runnable=new Runnable() {
- @Override
- public void run() {
- System.out.println("線程開始");
- try {
- sleep(4000L);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println("線程結束");
- }
- };
- //創建線程
- hread thread=new Thread(runnable);
- //啟動線程
- System.out.println("主線程開始");
- thread.start();
- thread.join();
- System.out.println("主線程結束");
運行結果:
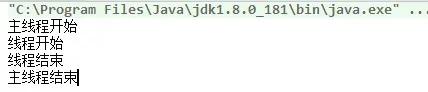
沒有用join方法的第一情況,主線程開始和主線程結束都在前面,并靠在一起,而線程開始和線程結束則在后面,因為他們是兩個不同的線程,彼此互不干擾。而用了join方法的第二種情況,主線程結束在最后一行,因為join方法需要等待子線程結束后才能繼續執行后面代碼。
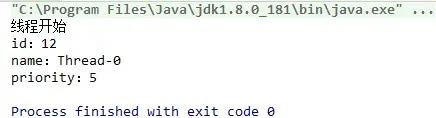
獲取線程id,name,priority
- //創建線程 Thread thread=new Thread(){
- public void run(){
- System.out.println("線程開始");
- }
- };
- //啟動線程
- thread.start();
- System.out.println("id:"+thread.getId());
- System.out.println("name:"+thread.getName());
- System.out.println("priority:"+thread.getPriority());
運行結果:
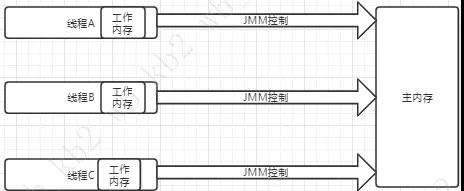
Java內存模型——JMM
內存模型
跟多級緩存差不多意思,每個線程里面都有工作內存,其存儲的是主內存中數據的副本,如下圖。那如果主內存中有變量a=1,現在線程A,B,C都存了a=1的副本,線程A對其進行加1操作,并刷新到主內存。可是線程B,C并不知道這種情況,那么就出問題啦。那如何解決這個問題呢?下面將慢慢說,不急。
8種原子操作(概念)
下面羅列的是8種原子操作,大家大概看看,下面將詳細描述。
- read(讀取):從主內存中讀取數據
- load(載入):將主內存讀取到的數據寫入工作內存
- user(使用):從工作內存讀取數據來計算
- assign(賦值):將計算好的值重新賦值到工作內存中
- store(存儲):將工作內存數據寫入主內存
- write(寫入):將store過去的變量值賦值給主內存中的變量
- lock(鎖定):將主內存變量加鎖,標識為線程獨占狀態
- unlock(解鎖):將主內存變量解鎖,解鎖后其他線程可以鎖定該變量
8種原子操作(舉例)
咱以上面的例子畫了個圖,請原諒偶我笨,畫的丑了點。
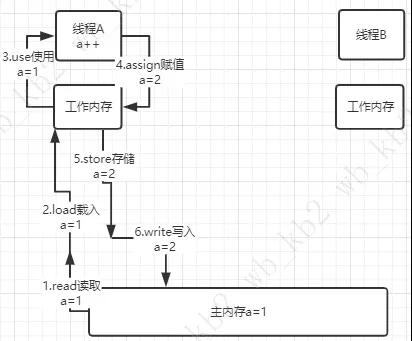
1.read讀取:將主內存中的a=1讀取出來。
2.load載入:將從主內存中a=1載入到線程A的工作內存中。
3.use使用:將線程A工作內存的a=1讀取到,并進行自增操作。
4.assign賦值:將a=2寫入到線程A的工作內存中。
5.store存儲:將a=2存儲到主內存中。
6.write寫入:將a=2寫入到主內存的a變量中。
7.lock鎖定:在上面CPU緩存解決不一致的方法一中,線程A操作的時候,對主內存a變量進行加鎖操作(lock),線程B根本讀不了a變量。
8.unlock解鎖:線程A操作解鎖之后,對主內存a變量進行解鎖操作(unlock),線程B可以讀到a變量并對其操作。
注意:lock和unlock存在著一個性能問題,我們發現寫的代碼明明是多線程并發操作,但是底層還是串行化,并沒有真正實現并發。
可見性原理
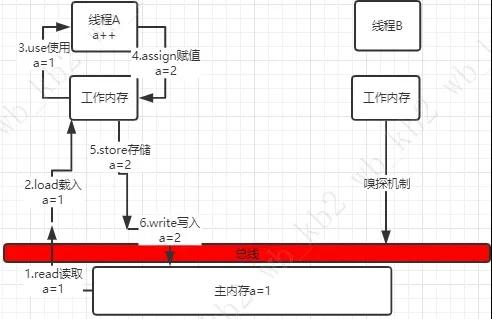
上面說的MESI協議是在總線那邊實踐的,線程A,B可以同時獲取主內存a的值,a進行自增操作之后在進行操作6write寫入的時候,會經過總線。線程B一直使用嗅探監控總線中自己感興趣的變量a,一旦發現a值有修改,立刻將自己工作內存中a置為無效Invalid(利用MESI協議),并立刻從主內存中讀取a值,這個時候總線中a還沒有寫入內存,所以有個短暫的lock過程,等到a寫入內存了,進行unlock操作,線程B即可讀取新的a值。
該過程雖然也有lock與unlock操作,但是鎖的粒度降低啦。
并發的風險與優勢
優勢:
- 速度方面:同時處理多個請求,響應更快,復雜的操作可以分成多個進程同時進行。
- 設計方面:程序設計在某些情況下更簡單,也可以有更多的選擇。
- 資源利用方面:CPU能夠在等待IO的時候做一些其他的事情。
風險:
- 安全性方面:多個線程共享數據時可能會產生與期望不相符的結果。
- 活躍性方面:某個操作無法繼續進行下去時,就會發生活躍性問題,比如死鎖,節等問題。
- 性能方面:線程過多時會使得:CPU頻繁切換,調度時間增多;同步機制;消耗過多內存。
結語
看到這里的都是真愛,先行謝過。此篇是并發系列的基礎,主要聊了硬件的MESI協議,原子的八種操作,線程和進程的關系,線程的一些基礎操作,JMM的基礎等。