Ceph如何擴(kuò)展到超過(guò)十億個(gè)對(duì)象?
越來(lái)越多的組織被要求管理數(shù)十億個(gè)文件和幾百上千PB的數(shù)據(jù)。無(wú)論是在公共云還是本地環(huán)境中,Ceph對(duì)象存儲(chǔ)都是值得考慮的一個(gè)選項(xiàng)。本篇文章將通過(guò)七部分的精選內(nèi)容為下面這些問(wèn)題提供答案。
- 每個(gè)RGW實(shí)例的最佳CPU /線程分配比率是多少?
- 建議的Rados網(wǎng)關(guān)(RGW)部署策略是什么?
- 固定大小的群集的最大性能是什么?
- 當(dāng)集群接近10億個(gè)對(duì)象時(shí),集群性能和穩(wěn)定性會(huì)受到哪些影響?
- 存儲(chǔ)桶分片如何提高存儲(chǔ)桶的可伸縮性,以及對(duì)性能有何影響?
- RGW的新Beast前端與Civetweb相比如何?
- RHCS 2.0 FileStore和RHCS 3.3 BlueStore之間的性能差異是多少?
- EC Fast_Read與常規(guī)讀取的性能影響?
1、構(gòu)建健壯的對(duì)象存儲(chǔ)基礎(chǔ)架構(gòu)
本部分主要介紹如何結(jié)合使用Red Hat Ceph Storage,Dell EMC存儲(chǔ)服務(wù)器和網(wǎng)絡(luò)來(lái)構(gòu)建健壯的對(duì)象存儲(chǔ)基礎(chǔ)架構(gòu)。
環(huán)境搭建
本環(huán)境是Dell EMC實(shí)驗(yàn)室中使用其硬件以及英特爾提供的硬件進(jìn)行的
硬件配置
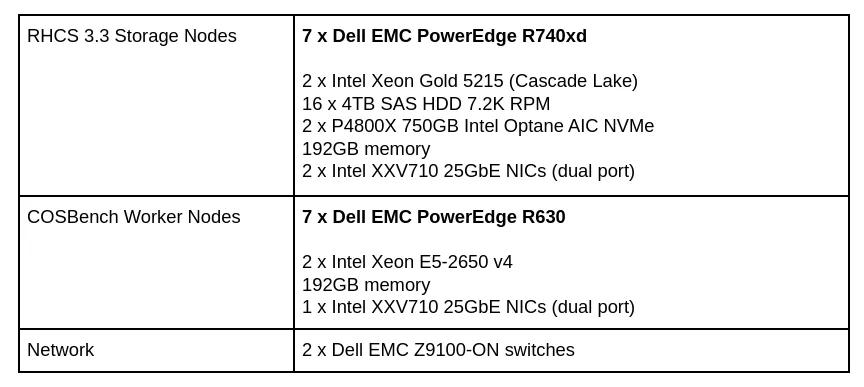
表1:硬件配置
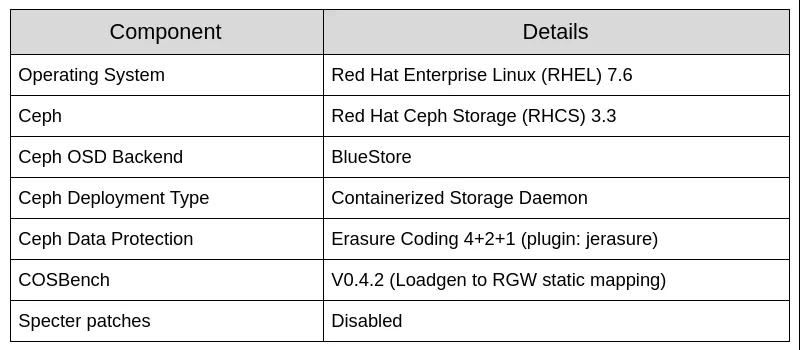
表2:軟件配置
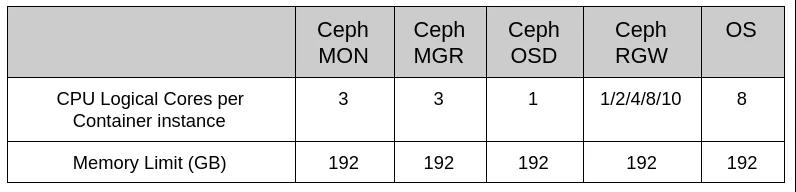
表3:資源限制
機(jī)架設(shè)計(jì)
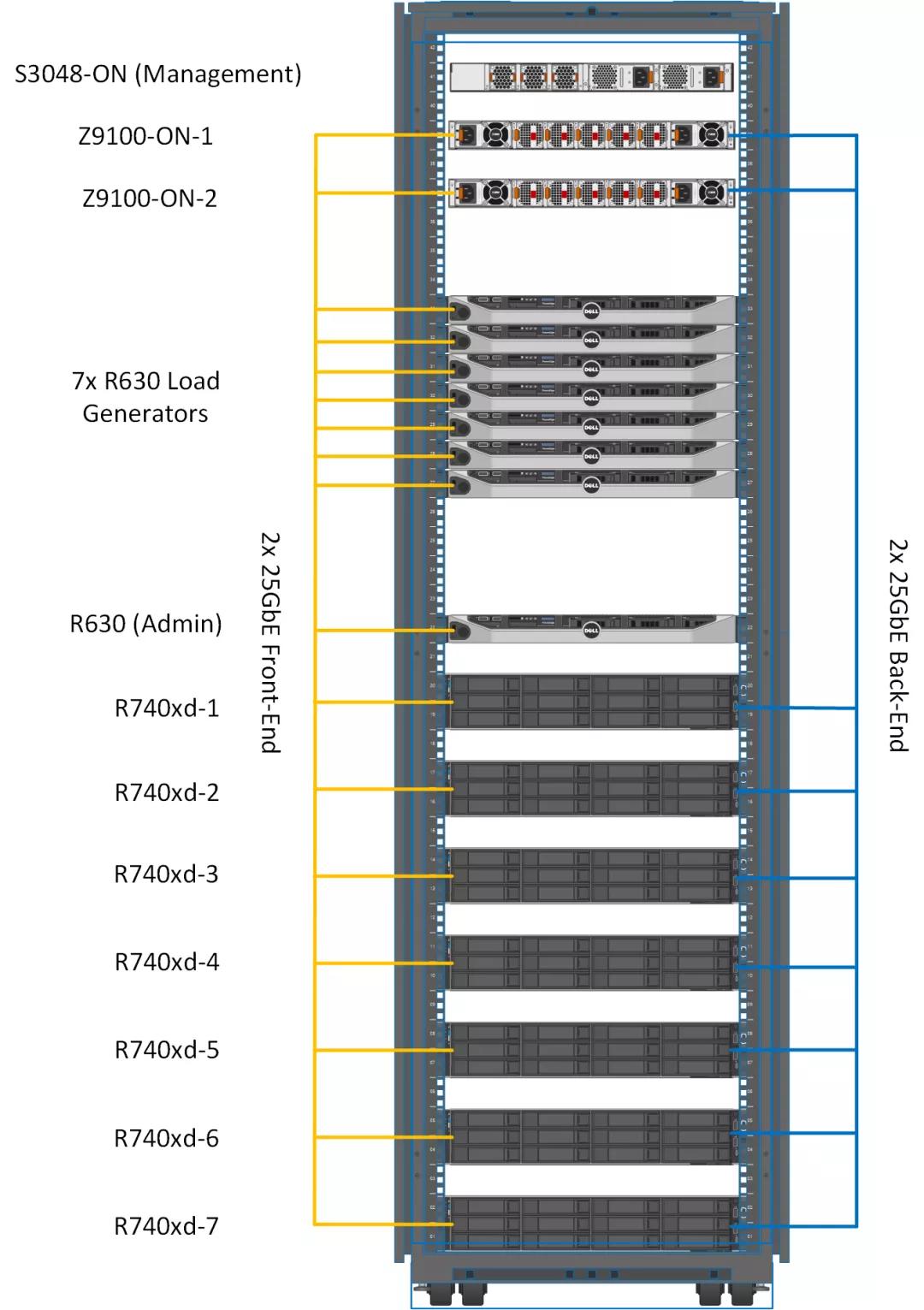
圖1:實(shí)驗(yàn)室機(jī)架設(shè)計(jì)
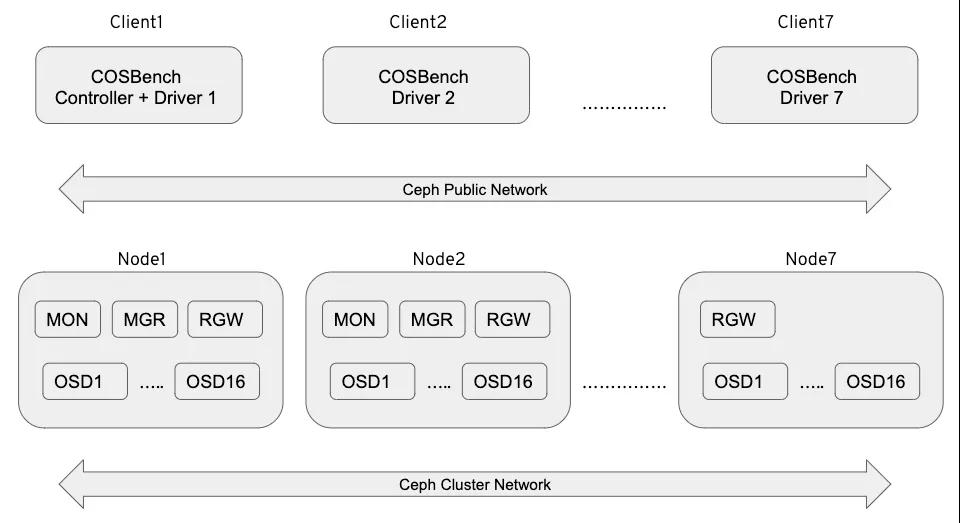
圖2:測(cè)試實(shí)驗(yàn)室邏輯設(shè)計(jì)
有效負(fù)載選擇
對(duì)象存儲(chǔ)的有效負(fù)載差異很大,有效負(fù)載大小是設(shè)計(jì)基準(zhǔn)測(cè)試用例時(shí)的關(guān)鍵考慮因素。在理想的基準(zhǔn)測(cè)試用例中,有效負(fù)載大小應(yīng)代表實(shí)際的應(yīng)用程序工作負(fù)載。與通常只讀取或?qū)懭霂浊ё止?jié)的塊存儲(chǔ)工作負(fù)載測(cè)試不同,其中對(duì)象存儲(chǔ)工作負(fù)載進(jìn)行測(cè)試需要涵蓋各種有效負(fù)載大小。以下是本次實(shí)驗(yàn)對(duì)象有效負(fù)載的大小。
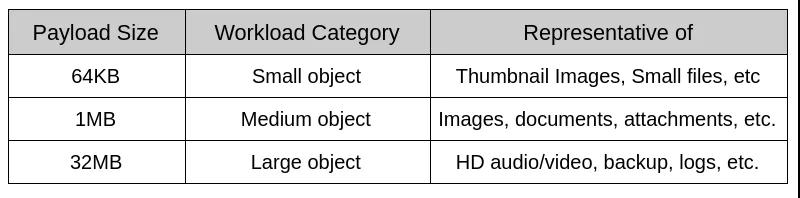
表4:經(jīng)過(guò)測(cè)試的有效負(fù)載
數(shù)據(jù)處理應(yīng)用程序傾向于在較大的文件上運(yùn)行,根據(jù)我們的測(cè)試,我們發(fā)現(xiàn)32MB是COSBench在我們的測(cè)試范圍內(nèi)可以可靠處理的最大對(duì)象大小。
執(zhí)行摘要
紅帽Ceph Storage能夠在多種行業(yè)標(biāo)準(zhǔn)的硬件配置上運(yùn)行。對(duì)于那些不熟悉系統(tǒng)硬件和Ceph軟件組件的人來(lái)說(shuō),這種靈活性可能會(huì)令人生畏。設(shè)計(jì)和優(yōu)化Ceph集群需要仔細(xì)分析應(yīng)用程序,它們所需的容量和工作負(fù)載配置文件。紅帽Ceph存儲(chǔ)集群通常在多租戶環(huán)境中使用,承受著各種各樣的工作負(fù)載。紅帽,戴爾EMC和英特爾精心挑選了我們認(rèn)為會(huì)對(duì)性能產(chǎn)生深遠(yuǎn)影響的系統(tǒng)組件。測(cè)試評(píng)估了三大類的工作負(fù)載:
- 大對(duì)象工作負(fù)載(吞吐量)
紅帽測(cè)試顯示,通過(guò)添加Rados Gateway(RGW)實(shí)例,可以實(shí)現(xiàn)讀寫吞吐量的近乎線性的可擴(kuò)展性,直到由于OSD節(jié)點(diǎn)磁盤爭(zhēng)用而達(dá)到峰值為止。因此,我們?yōu)樽x寫工作負(fù)載測(cè)量了超過(guò)6GB/s的聚合帶寬。
- 小對(duì)象工作負(fù)載(每秒操作數(shù))
與大對(duì)象工作負(fù)載相比,元數(shù)據(jù)I/O對(duì)小對(duì)象工作負(fù)載的影響更大。客戶端寫操作按次線性擴(kuò)展,最高為6.3K OPS,平均響應(yīng)時(shí)間為8.8 ms,直到被OSD節(jié)點(diǎn)磁盤爭(zhēng)用飽和為止。客戶端讀取操作達(dá)到3.9K OPS,這可能是由于BlueStore OSD后端缺少Linux頁(yè)面緩存所致。
- 對(duì)象數(shù)量更多的工作負(fù)載(十億個(gè)對(duì)象或更多)
隨著存儲(chǔ)桶中對(duì)象總數(shù)的增長(zhǎng),需要管理的索引元數(shù)據(jù)的數(shù)量也相應(yīng)增加。索引元數(shù)據(jù)分布在許多分片上,以確保可以有效地訪問(wèn)它。當(dāng)存儲(chǔ)桶中的對(duì)象數(shù)量大于使用當(dāng)前分片數(shù)量可以有效管理的數(shù)量時(shí),Red Hat Ceph Storage將動(dòng)態(tài)增加分片數(shù)量。在我們的測(cè)試過(guò)程中,我們發(fā)現(xiàn)動(dòng)態(tài)分片事件對(duì)目的地為動(dòng)態(tài)分片的存儲(chǔ)桶的請(qǐng)求的吞吐量具有短暫有害的影響。如果開(kāi)發(fā)人員具有將存儲(chǔ)桶增長(zhǎng)到給定數(shù)量的經(jīng)驗(yàn)知識(shí),則可以創(chuàng)建該存儲(chǔ)桶或?qū)⑵涫謩?dòng)更新為能夠有效容納元數(shù)據(jù)量的多個(gè)分片。
在大型和小型對(duì)象大小的工作負(fù)載測(cè)試中,相對(duì)于以前的性能和規(guī)模分析,Red Hat Ceph Storage都顯著提高了性能。我們認(rèn)為,這些改進(jìn)可以歸因于BlueStore OSD后端,RGW的新Beast Web前端,BlueStore WAL和block.db使用Intel Optane SSD以及Intel Cascade Lake提供的最新一代處理能力的結(jié)合處理器。
體系結(jié)構(gòu)
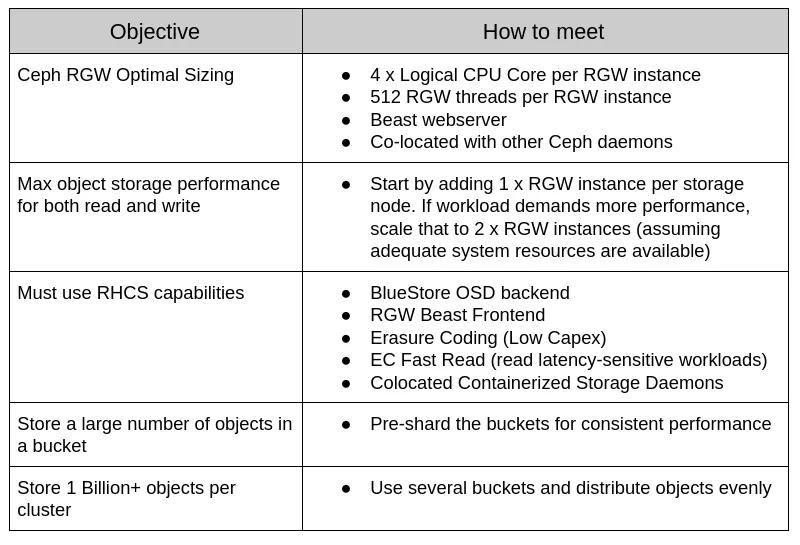
表5:體系結(jié)構(gòu)摘要
Ceph基準(zhǔn)性能測(cè)試
為了記錄本機(jī)Ceph集群的性能,我們使用了Ceph基準(zhǔn)測(cè)試工具(CBT),一種用于自動(dòng)化Ceph群集基準(zhǔn)測(cè)試的開(kāi)源工具。目的是找到集群總吞吐量的高水位線。該水位線是吞吐量保持不變或降低的點(diǎn)。
使用Ceph-Ansible playbook部署了Ceph集群。Ceph-Ansible使用默認(rèn)設(shè)置創(chuàng)建一個(gè)Ceph集群。因此,基線測(cè)試是使用默認(rèn)的Ceph配置完成的,沒(méi)有進(jìn)行任何特殊調(diào)整。使用CBT,每個(gè)基準(zhǔn)場(chǎng)景運(yùn)行了7次迭代。第一次迭代從單個(gè)客戶端執(zhí)行基準(zhǔn)測(cè)試,第二次從兩個(gè)客戶端執(zhí)行基準(zhǔn)測(cè)試,第三次從三個(gè)客戶端并行執(zhí)行,以此類推等等。
使用了以下CBT配置:
- 工作量:順序?qū)憸y(cè)試,然后順序讀測(cè)試
- 塊大小:4MB
- 片長(zhǎng):300秒
- 每個(gè)客戶端的并發(fā)線程數(shù):128
- 每個(gè)客戶端的RADOS基準(zhǔn)實(shí)例:1
- 池?cái)?shù)據(jù)保護(hù):Ec 4 + 2刪除或3x復(fù)制
- 客戶總數(shù):7
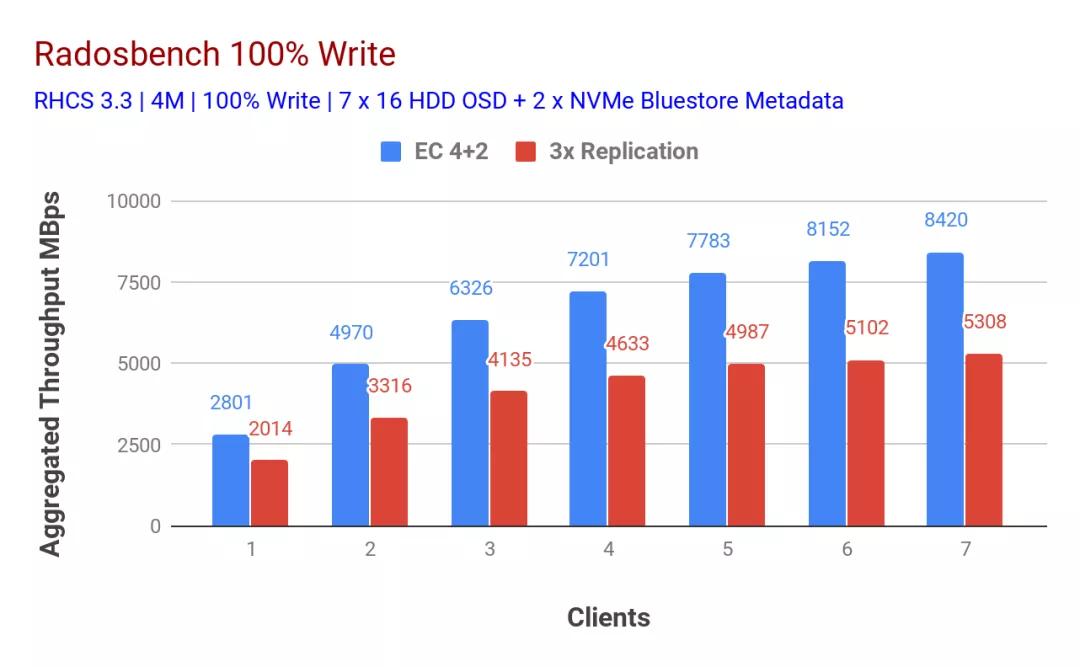
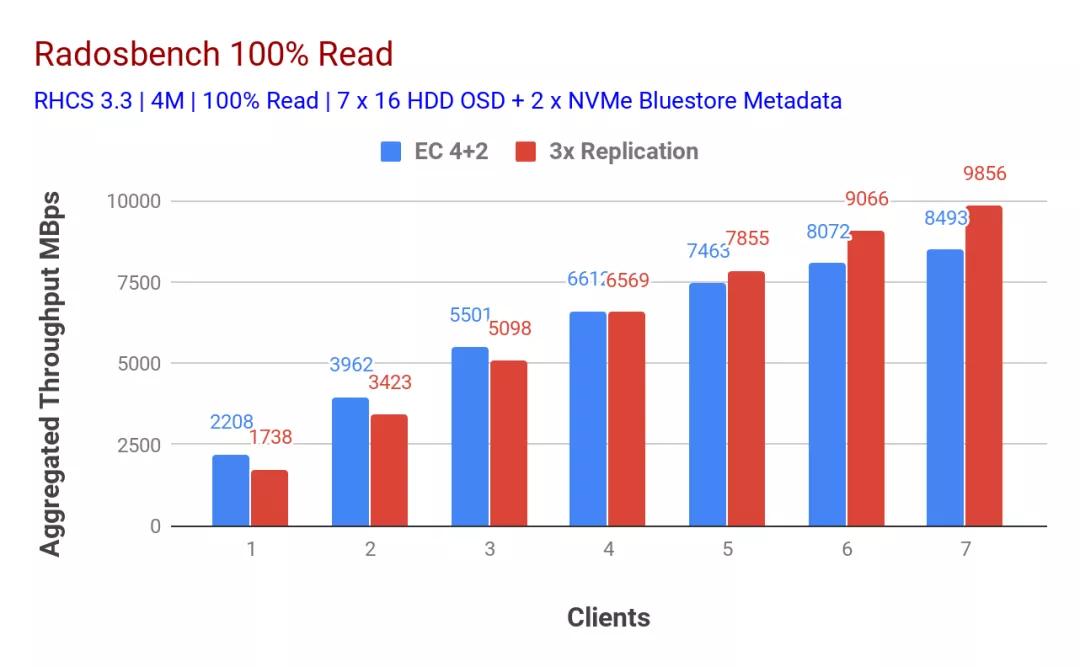
如表1和表2所示,隨著客戶端數(shù)量的增加,寫入和讀取工作負(fù)載的性能都呈線性下降。有趣的是,使用擦除編碼數(shù)據(jù)保護(hù)方案的配置為讀寫吞吐量提供了幾乎對(duì)稱的8.4GBps。在以前的研究中沒(méi)有觀察到這種對(duì)稱性,我們認(rèn)為這可以歸因于BlueStore和Intel Optane SSD的組合。在任何RADOS基準(zhǔn)測(cè)試中,我們都無(wú)法確定任何系統(tǒng)級(jí)資源飽和。如果有其他客戶端節(jié)點(diǎn)可用來(lái)進(jìn)一步給現(xiàn)有群集施加壓力,我們可能會(huì)觀察到更高的性能,并有可能使基礎(chǔ)存儲(chǔ)介質(zhì)飽和。
總結(jié)
在本文中,我們?cè)敿?xì)介紹了實(shí)驗(yàn)室體系結(jié)構(gòu),包括硬件和軟件配置,分享了來(lái)自基礎(chǔ)集群基準(zhǔn)測(cè)試的一些結(jié)果,并提供了高級(jí)執(zhí)行和體系結(jié)構(gòu)的相關(guān)摘要。
2、Ceph RGW 部署策略和大小調(diào)整
從Red Hat Ceph Storage 3.0開(kāi)始,Red Hat添加了對(duì)容器化存儲(chǔ)守護(hù)程序(CSD)的支持,該支持使軟件定義的存儲(chǔ)組件(Ceph MON,OSD,MGR,RGW等)可以在容器中運(yùn)行。CSD避免了具有專用于存儲(chǔ)服務(wù)的節(jié)點(diǎn)的需求,因此通過(guò)并置存儲(chǔ)容器化守護(hù)進(jìn)程減少了CAPEX和OPEX。
Ceph-Ansible提供了將資源防護(hù)放入每個(gè)存儲(chǔ)容器的必需機(jī)制,這對(duì)于在一個(gè)物理節(jié)點(diǎn)上運(yùn)行多個(gè)存儲(chǔ)守護(hù)程序容器很有用。在這部分內(nèi)容中,我們將介紹部署RGW容器的策略及其資源調(diào)整指南。在探討性能之前,讓我們了解部署RGW的不同方法是什么。
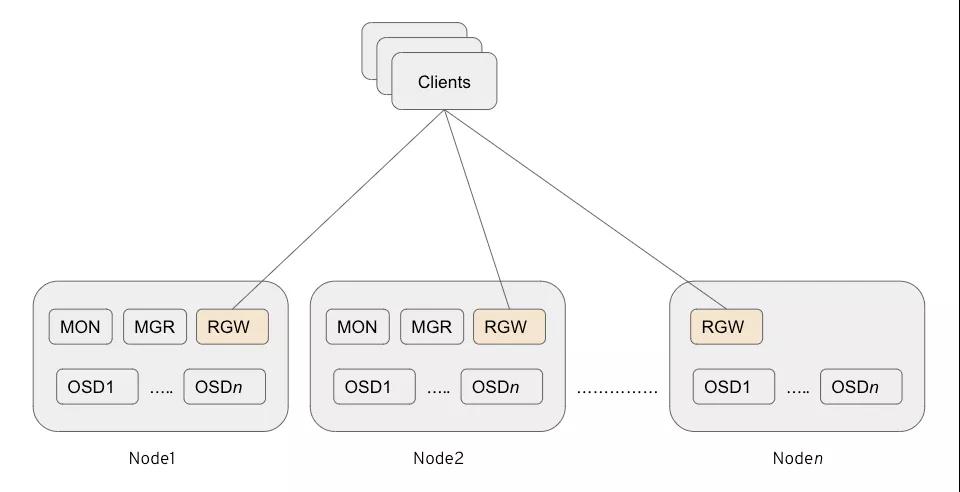
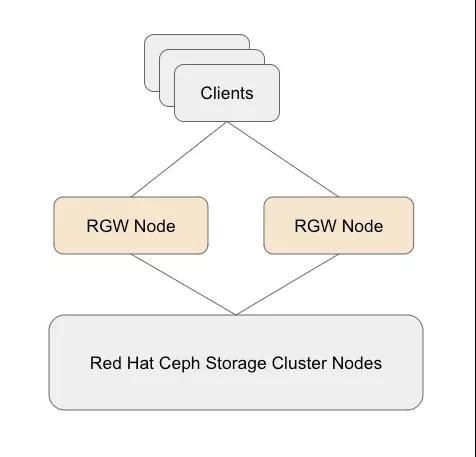
并置的RGW
- 不需要用于RGW的專用節(jié)點(diǎn)(可以減少CAPEX和OPEX)。
- Ceph RGW容器的單個(gè)實(shí)例放置在與其他存儲(chǔ)容器共存的存儲(chǔ)節(jié)點(diǎn)上。
- 從Ceph Storage 3.0開(kāi)始,這是部署RGW的首選方法。
多主機(jī)RGW
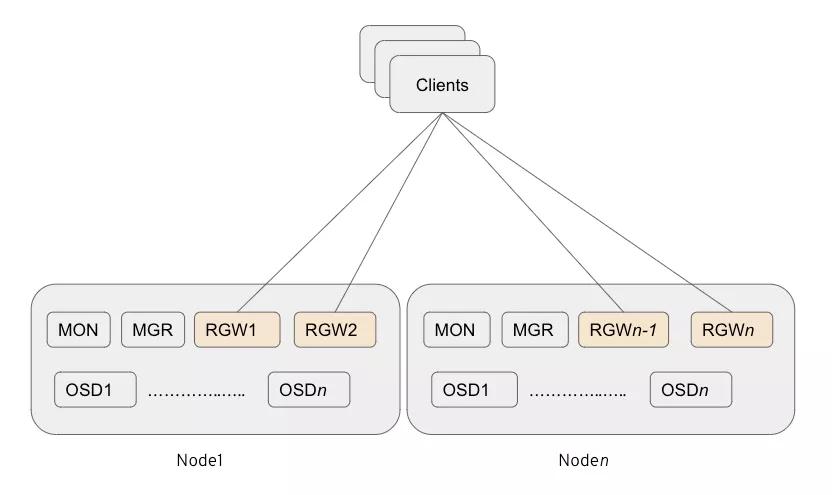
- 不需要用于RGW的專用節(jié)點(diǎn)(可以幫助減少CAPEX和OPEX)。
- 與其他存儲(chǔ)容器共存的多個(gè)Ceph RGW實(shí)例(每個(gè)存儲(chǔ)節(jié)點(diǎn)當(dāng)前測(cè)試2個(gè)實(shí)例)。
- 我們的測(cè)試表明,該選項(xiàng)可提供最高的性能,而不會(huì)產(chǎn)生額外的開(kāi)銷。
獨(dú)立RGW
- 需要用于RGW的專用節(jié)點(diǎn)。
- Ceph RGW組件被部署在專用的物理/虛擬節(jié)點(diǎn)上。
- 從Ceph Storage 3.0開(kāi)始,這不再是部署RGW的首選方法。
表現(xiàn)摘要
(一)RGW部署和規(guī)模調(diào)整指南
在上一節(jié)中,我們研究了部署Ceph RGW的不同方法。我們將比較每種方法之間的性能差異。為了評(píng)估性能,我們通過(guò)調(diào)節(jié)RGW部署策略以及跨不同的讀寫和工作負(fù)載的RGW CPU內(nèi)核數(shù)執(zhí)行了多個(gè)測(cè)試。結(jié)果如下。
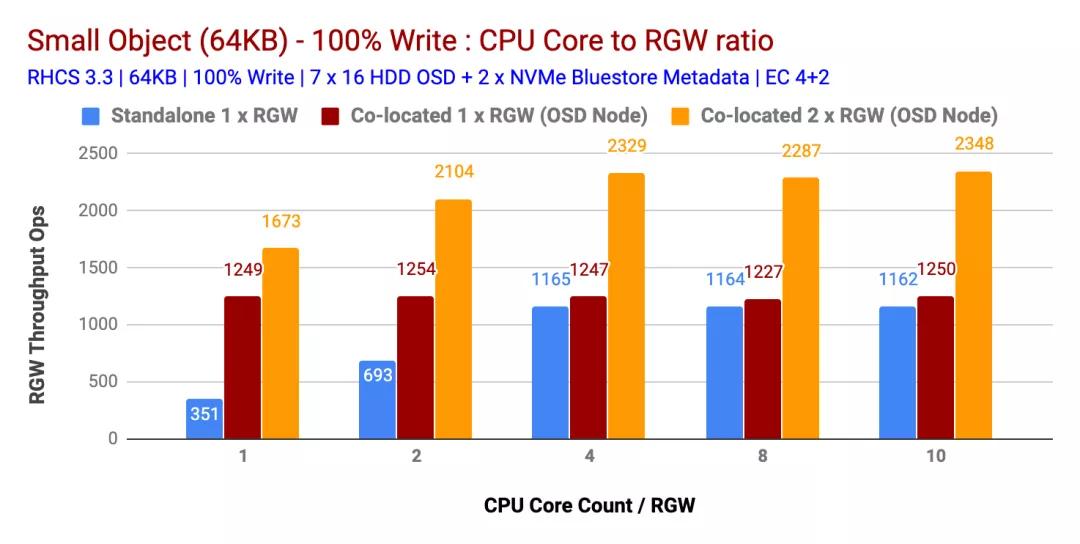
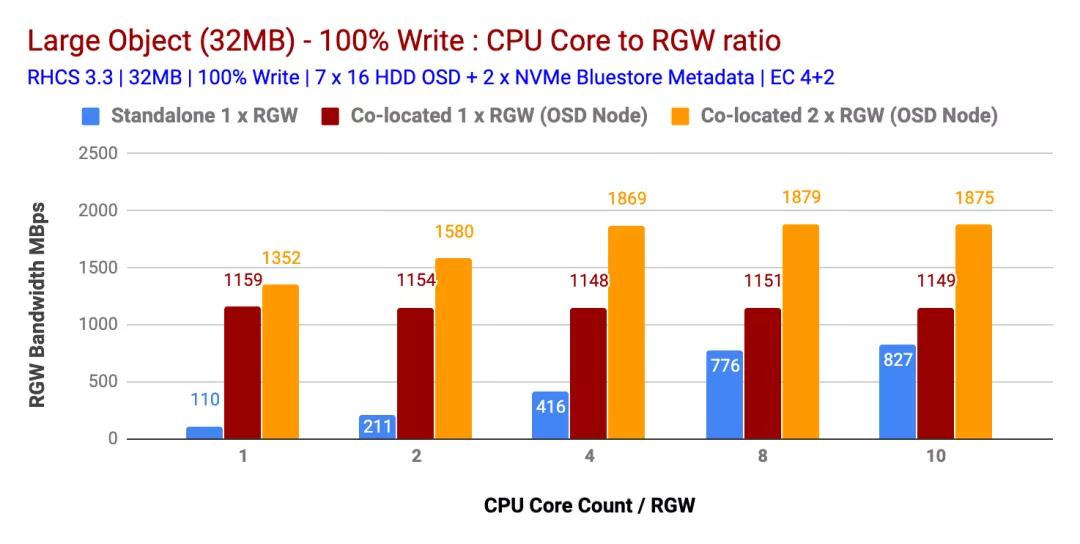
100%寫入工作量
如圖1和圖2所示
- 并置(1x)RGW實(shí)例在小型和大型對(duì)象方面均優(yōu)于獨(dú)立RGW部署。
- 同樣,多個(gè)共存(2x)RGW實(shí)例的性能優(yōu)于共存(1x)RGW實(shí)例的部署。這樣,多個(gè)共存(2x)RGW實(shí)例分別為小型和大型對(duì)象提供了 2328 Ops和1879 MBps的性能。
- 在多個(gè)測(cè)試中,發(fā)現(xiàn) 4 CPU Core / RGW實(shí)例是CPU資源與RGW實(shí)例之間的最佳比率。向RGW實(shí)例分配更多的CPU內(nèi)核并不能提供更高的性能
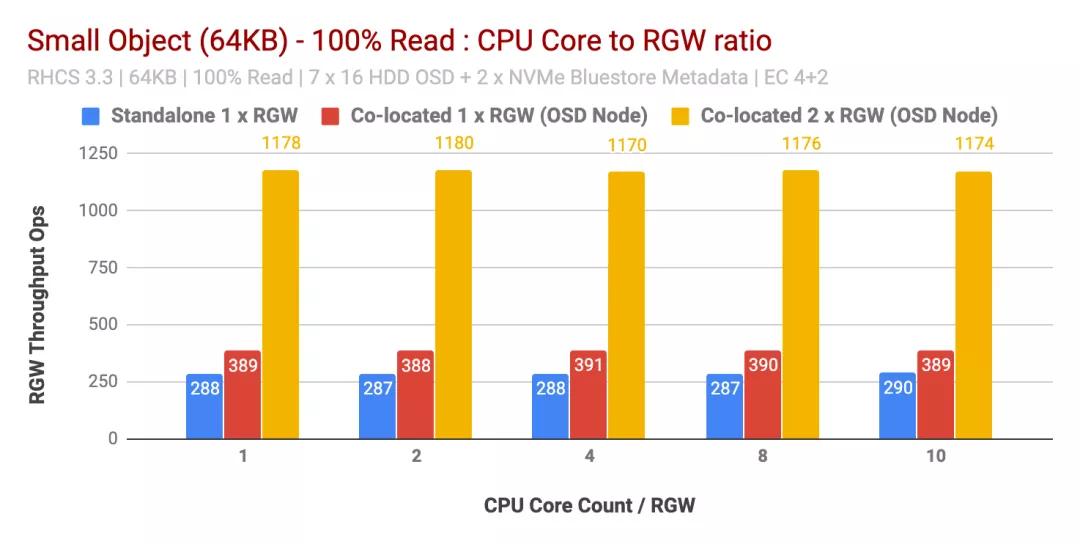
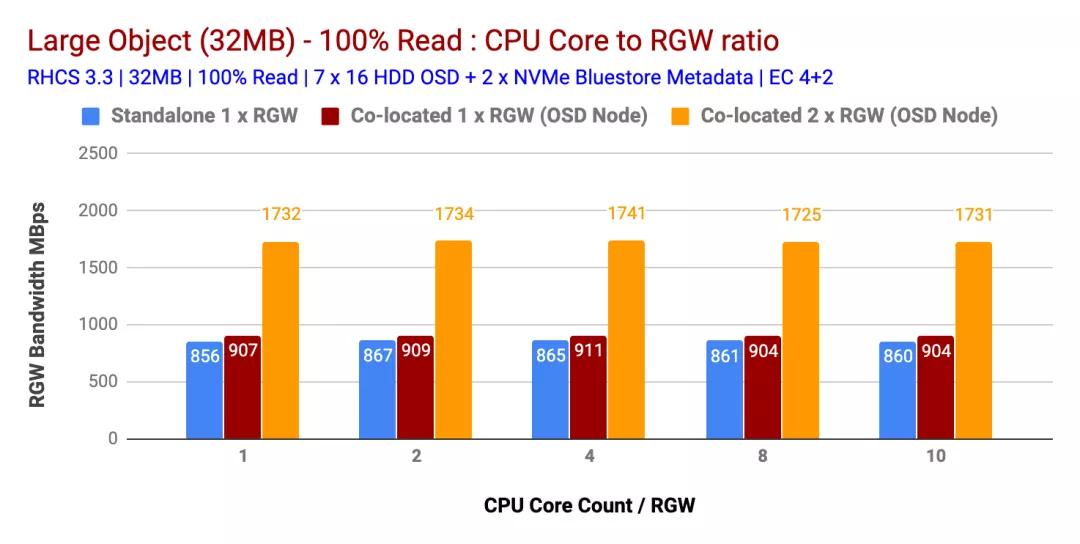
100%讀取工作負(fù)載性能
有趣的是,對(duì)于讀取工作負(fù)載,每個(gè)RGW實(shí)例增加的CPU核心數(shù)量并不能提高不同大小對(duì)象的性能。因此,每個(gè)RGW實(shí)例1個(gè)CPU內(nèi)核的結(jié)果與每個(gè)RGW實(shí)例10個(gè)CPU內(nèi)核的結(jié)果幾乎相似。
實(shí)際上,根據(jù)我們之前的測(cè)試,我們觀察到類似的結(jié)果,即讀取工作負(fù)載不會(huì)消耗大量CPU,這可能是因?yàn)镃eph使用了系統(tǒng)擦除編碼,并且在讀取過(guò)程中不需要解碼塊。因此,我們發(fā)現(xiàn)如果RGW工作負(fù)載是讀取密集型的,則過(guò)度分配CPU并沒(méi)有幫助。
比較獨(dú)立RGW與共置(1x)RGW測(cè)試的結(jié)果非常相似。但是,僅添加一個(gè)并置的RGW(2x),在小對(duì)象的情況下,性能提高了約200%,在大對(duì)象的情況下,性能提高了約90%。
這樣,如果工作負(fù)載是讀取密集型的,則運(yùn)行多個(gè)并置(2x)RGW實(shí)例可以顯著提高整體讀取性能。
(二)RGW線程池大小調(diào)整準(zhǔn)則
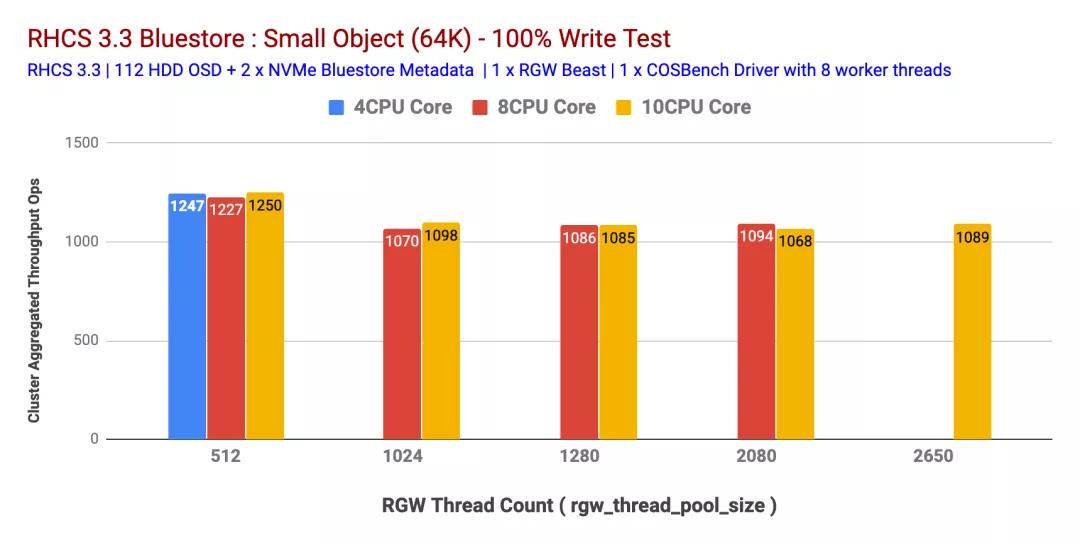
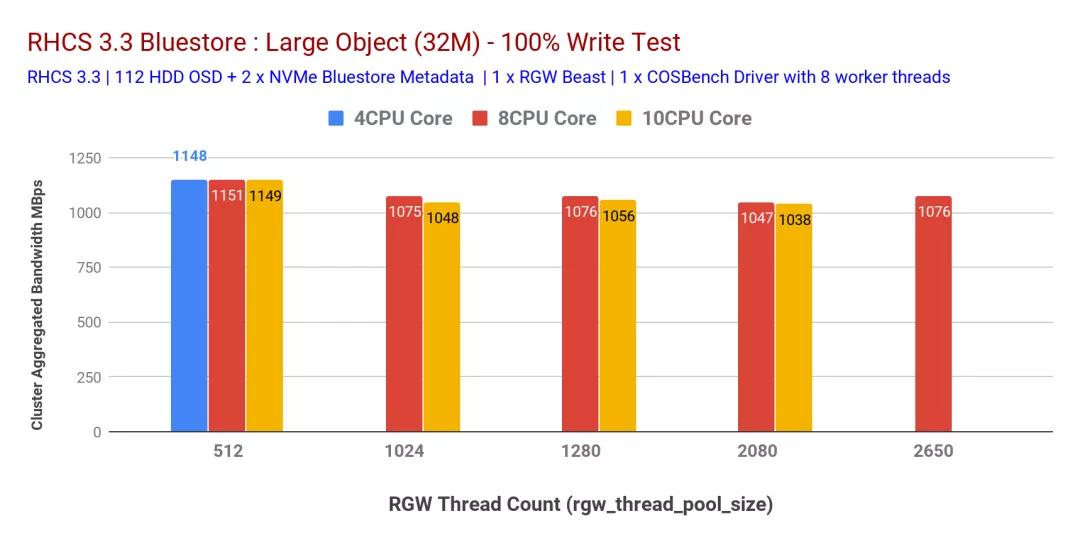
在決定將CPU內(nèi)核分配給RGW實(shí)例時(shí),非常相關(guān)的RGW調(diào)整參數(shù)之一rgw_thread_pool_size是負(fù)責(zé)由Beast生成的與HTTP請(qǐng)求相對(duì)應(yīng)的線程數(shù)。這有效地限制了Beast前端可以服務(wù)的并發(fā)連接數(shù)。
為了確定此可調(diào)參數(shù)最合適的值,我們通過(guò)更改rgw_thread_pool_sizeRGW實(shí)例的CPU核心計(jì)數(shù)和CPU計(jì)數(shù)一起進(jìn)行了測(cè)試。如圖5和6所示,我們發(fā)現(xiàn)設(shè)置rgw_thread_pool_size為512可以在4個(gè)CPU內(nèi)核預(yù)RGW實(shí)例上實(shí)現(xiàn)最高性能。同時(shí)增加CPU核心數(shù)rgw_thread_pool_size并沒(méi)有任何改善。
我們確實(shí)承認(rèn),如果我們進(jìn)行多輪rgw_thread_pool_size低于512 的測(cè)試,則本測(cè)試會(huì)更好。我們的假設(shè)是,由于Beast Web服務(wù)器基于異步c10k Web服務(wù)器,因此不需要每連接一個(gè)線程,因此應(yīng)該在較低的線程上表現(xiàn)良好。不幸的是,我們無(wú)法測(cè)試,但將來(lái)會(huì)嘗試解決這個(gè)問(wèn)題。
因此,這樣的多并置(2x)RGW實(shí)例(每個(gè)RGW實(shí)例具有4個(gè)CPU內(nèi)核)和設(shè)置rgw_thread_pool_size為512個(gè)可以提供最大的性能。
總結(jié)
在這篇文章中,我們了解到,多并置(2x)RGW實(shí)例,每個(gè)RGW實(shí)例具有4個(gè)CPU核心,每個(gè)實(shí)例rgw_thread_pool_size有512個(gè),可在不增加整體硬件成本的情況下提供最佳性能。
3、從ceph集群中獲得最大性能
我們已經(jīng)測(cè)試了各種配置,對(duì)象大小和客戶端數(shù)量,以便針對(duì)小型和大型對(duì)象工作負(fù)載最大化七個(gè)節(jié)點(diǎn)的Ceph集群的吞吐量。如第一篇文章中所述,Ceph集群是使用每個(gè)HDD配置的單個(gè)OSD(對(duì)象存儲(chǔ)設(shè)備)構(gòu)建的,每個(gè)Ceph集群總共有112個(gè)OSD。在本文中,我們將了解不同對(duì)象大小和工作負(fù)載的頂級(jí)性能。
注意:在本文中,術(shù)語(yǔ)“讀取”和HTTP GET可以互換使用,術(shù)語(yǔ)HTTP PUT和“寫入”也可以互換使用。
大對(duì)象工作量
大對(duì)象順序輸入/輸出(I / O)工作負(fù)載是Ceph對(duì)象存儲(chǔ)最常見(jiàn)的用例之一。這些高吞吐量的工作負(fù)載包括大數(shù)據(jù)分析、備份和檔案系統(tǒng)、圖像存儲(chǔ)以及流音頻和視頻。對(duì)于這些類型的工作負(fù)載,吞吐量(MB / s或GB / s)是定義存儲(chǔ)性能的關(guān)鍵指標(biāo)。
如圖1所示,當(dāng)增加RGW主機(jī)的數(shù)量時(shí),大對(duì)象100%HTTP GET和HTTP PUT工作負(fù)載表現(xiàn)出亞線性可伸縮性。因此,我們?yōu)镠TTP GET和HTTP PUT工作負(fù)載測(cè)量了約5.5 GBps的聚合帶寬,有趣的是,我們沒(méi)有注意到Ceph集群節(jié)點(diǎn)中的資源飽和。
如果我們可以將更多負(fù)載分配給該群集,則它可以產(chǎn)生更多的負(fù)載。因此,我們確定了兩種方法。1)添加更多的客戶端節(jié)點(diǎn) 2)添加更多的RGW節(jié)點(diǎn)。我們不能選擇選項(xiàng)1,因?yàn)槲覀兪艽藢?shí)驗(yàn)中可用的物理客戶端節(jié)點(diǎn)的限制。因此,我們選擇了選項(xiàng)2,并進(jìn)行了另一輪測(cè)試,但這次有14個(gè)RGW。
如圖2所示,與7個(gè) RGW測(cè)試相比,14 RGW測(cè)試的寫入性能提高了 14%,最高達(dá)到了6.3GBps,類似地,HTTP GET工作負(fù)載顯示的讀取性能提高了16%,最高達(dá)到6.5GBps。這是在此群集上觀察到的最大聚合吞吐量,此后如圖1所示,注意到了設(shè)備(HDD)飽和。根據(jù)結(jié)果,我們相信,如果我們向該集群添加了更多的Ceph OSD節(jié)點(diǎn),則性能可能會(huì)進(jìn)一步擴(kuò)展,直到受到資源飽和的限制。
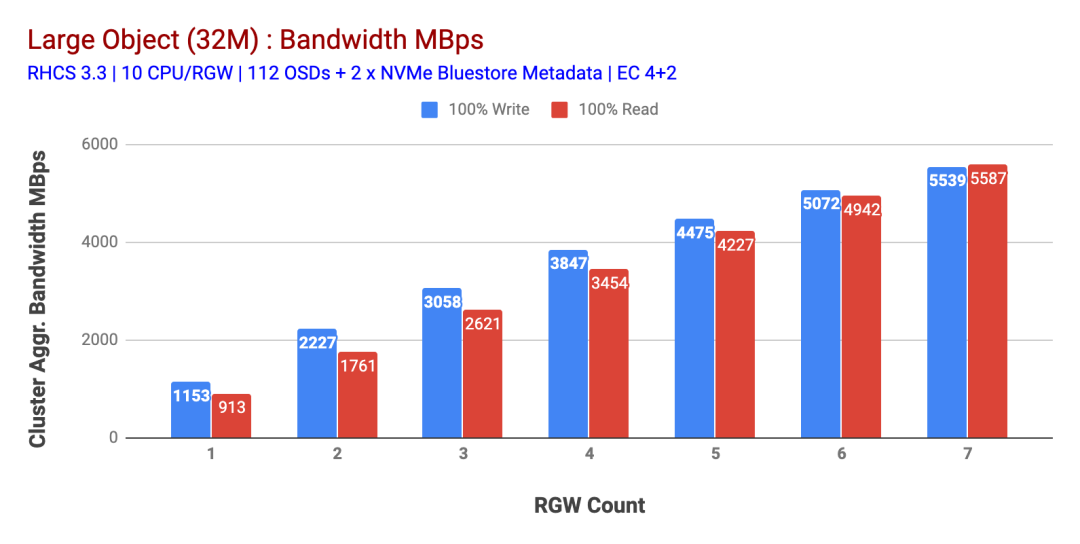
圖1:大對(duì)象測(cè)試
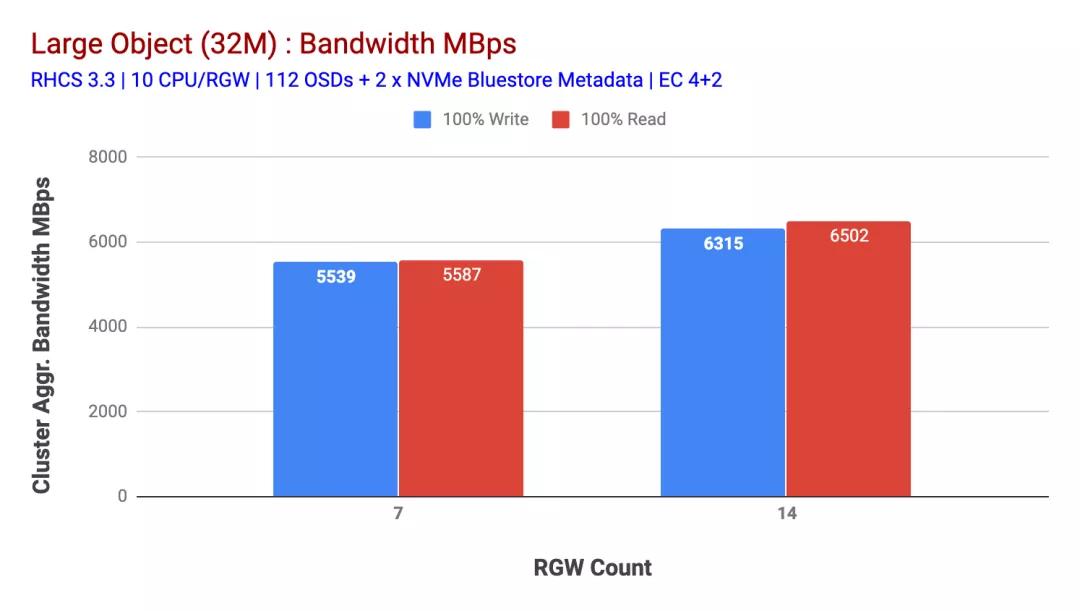
圖2:具有14個(gè)RGW的大型對(duì)象測(cè)試
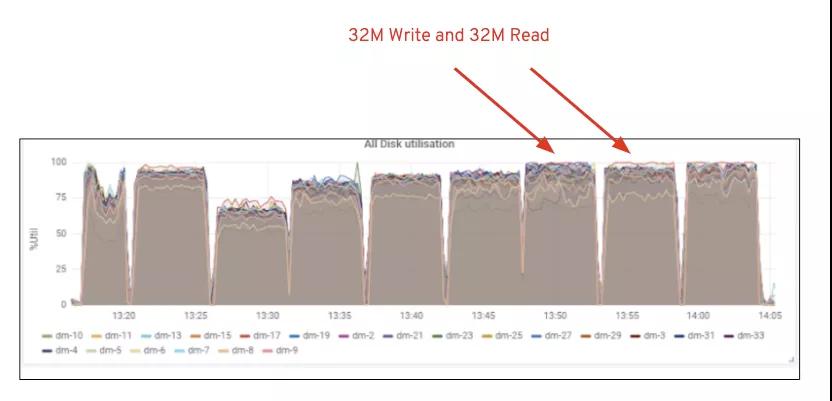
圖1:Ceph OSD(HDD)媒體利用率
小對(duì)象工作量
如圖3所示,當(dāng)增加RGW主機(jī)的數(shù)量時(shí),小型對(duì)象100%HTTP GET和HTTP PUT工作負(fù)載表現(xiàn)出次線性可伸縮性。因此,我們測(cè)量了9ms應(yīng)用程序?qū)懭胙舆t時(shí)HTTP PUT的6.2K Ops吞吐量,以及具有7個(gè)RGW實(shí)例的HTTP GET工作負(fù)載的3.2K Ops吞吐量。
直到7個(gè)RGW實(shí)例,我們才注意到資源飽和,因此我們將RGW實(shí)例擴(kuò)展到14個(gè),從而使RGW實(shí)例增加了一倍,并觀察到HTTP PUT工作負(fù)載的性能下降,這歸因于設(shè)備飽和,而HTTP GET性能則向上擴(kuò)展并達(dá)到4.5萬(wàn)個(gè),如果我們添加更多的Ceph OSD節(jié)點(diǎn),寫性能可能會(huì)更高。就讀取性能而言,我們認(rèn)為添加更多的客戶端節(jié)點(diǎn)應(yīng)該可以改善讀取性能,但是我們?cè)趯?shí)驗(yàn)室中沒(méi)有更多的物理節(jié)點(diǎn)可以驗(yàn)證這一假設(shè)。
從圖3中可以看到的另一個(gè)有趣的觀察結(jié)果是HTTP PUT工作負(fù)載的平均響應(yīng)時(shí)間減少了9ms,而HTTP GET顯示了從應(yīng)用程序生成工作負(fù)載測(cè)得的平均延遲為17ms。我們認(rèn)為,導(dǎo)致寫入工作負(fù)載出現(xiàn)個(gè)位數(shù)的應(yīng)用程序延遲的原因之一是BlueStore OSD后端的性能提高以及用于支持BlueStore元數(shù)據(jù)設(shè)備的高性能Intel Optane NVMe的結(jié)合。值得注意的是,從對(duì)象存儲(chǔ)系統(tǒng)中實(shí)現(xiàn)一位數(shù)的寫入平均延遲并非易事。如圖3所示,將Ceph對(duì)象存儲(chǔ)與BlueStore OSD后端和Intel Optane用于元數(shù)據(jù)一起部署時(shí),可以在較低的響應(yīng)時(shí)間實(shí)現(xiàn)寫入吞吐量。
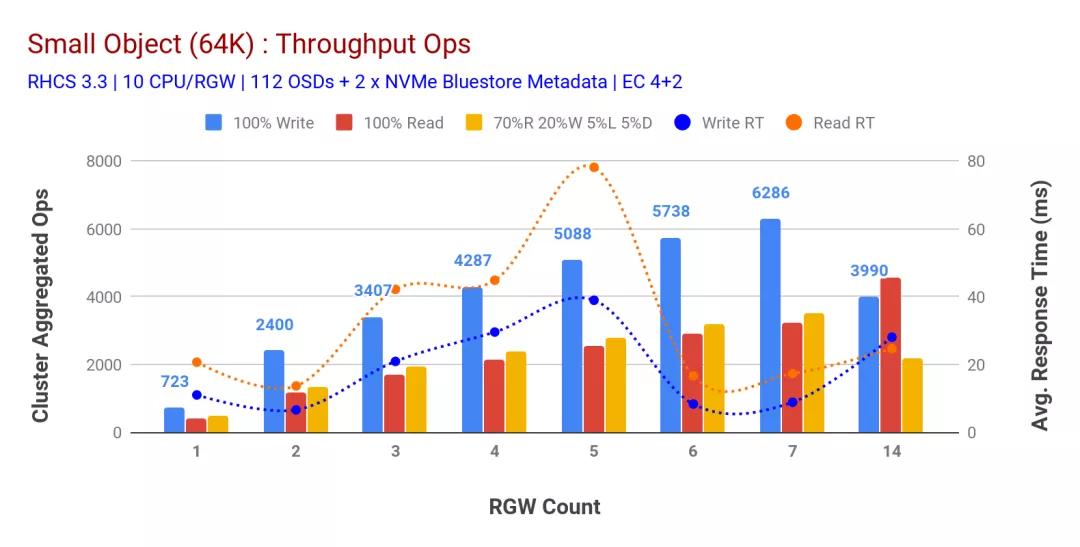
圖3:小對(duì)象測(cè)試
總結(jié)
此測(cè)試中使用的固定大小群集分別為寫入和讀取工作負(fù)載提供了約6.3GBps和約6.5GBps的大對(duì)象帶寬。相同的小對(duì)象集群分別為讀寫工作量提供了約6.5K Ops和約4.5K Ops。
結(jié)果還表明,BlueStore OSD與Intel Optane NVMe的結(jié)合使用實(shí)現(xiàn)了平均應(yīng)用程序延遲個(gè)位數(shù)的好成績(jī),這對(duì)于對(duì)象存儲(chǔ)系統(tǒng)而言是非常重要的。
4、RGW存儲(chǔ)桶分片策略及其性能影響
在有關(guān)Ceph性能的系列文章的第4部分中,我們介紹了RGW存儲(chǔ)桶分片策略及其性能影響。
Ceph RGW為每個(gè)存儲(chǔ)桶維護(hù)一個(gè)索引,該索引保存存儲(chǔ)桶包含的所有對(duì)象的元數(shù)據(jù)。RGW需要索引才能在請(qǐng)求時(shí)提供此元數(shù)據(jù)。例如,列出存儲(chǔ)桶內(nèi)容會(huì)拉出存儲(chǔ)的元數(shù)據(jù),維護(hù)用于對(duì)象版本控制、存儲(chǔ)桶配額、多區(qū)域同步元數(shù)據(jù)等的日志。因此,概括地說(shuō),存儲(chǔ)桶索引存儲(chǔ)了一些有用的信息。存儲(chǔ)區(qū)索引不會(huì)影響對(duì)對(duì)象的讀取操作,但是會(huì)在寫入和修改RGW對(duì)象時(shí)添加額外的操作。
大規(guī)模編寫和修改存儲(chǔ)桶索引具有某些含義。首先,可以存儲(chǔ)在單個(gè)存儲(chǔ)桶索引對(duì)象上的數(shù)據(jù)量有限,這是因?yàn)橛糜诖鎯?chǔ)桶索引對(duì)象的基礎(chǔ)RADOS對(duì)象鍵值接口不是無(wú)限的,并且默認(rèn)情況下每個(gè)存儲(chǔ)桶僅使用一個(gè)RADOS對(duì)象。其次,大索引對(duì)象可能會(huì)導(dǎo)致性能瓶頸,因?yàn)閷?duì)已填充存儲(chǔ)桶的所有寫操作最終都會(huì)修改支持該存儲(chǔ)桶索引的單個(gè)RADOS對(duì)象。
為了解決與非常大的存儲(chǔ)桶索引對(duì)象相關(guān)的問(wèn)題,RHCS 2.0中引入了存儲(chǔ)桶索引分片功能。這樣,每個(gè)存儲(chǔ)桶索引現(xiàn)在都可以分布在多個(gè)RADOS對(duì)象上,通過(guò)允許存儲(chǔ)桶可以容納的對(duì)象數(shù)量與索引對(duì)象(碎片)的數(shù)量成比例,可以擴(kuò)展存儲(chǔ)桶索引元數(shù)據(jù)。
但是,此功能僅限于新創(chuàng)建的存儲(chǔ)桶,并且需要對(duì)未來(lái)的存儲(chǔ)桶對(duì)象進(jìn)行預(yù)先規(guī)劃。為了緩解此存儲(chǔ)桶重新分片可以使用管理員命令,該命令可幫助修改現(xiàn)有存儲(chǔ)桶的存儲(chǔ)桶索引分片數(shù)量。但是,使用這種手動(dòng)方法,通常會(huì)在群集中執(zhí)行存儲(chǔ)區(qū)重新分片看到性能下降的癥狀。同樣,手動(dòng)重新分片要求在重新分片過(guò)程中停止對(duì)存儲(chǔ)區(qū)的寫操作。
動(dòng)態(tài)存儲(chǔ)分區(qū)重新分片的意義
RHCS 3.0引入了動(dòng)態(tài)存儲(chǔ)區(qū)重新分片功能。利用此功能,存儲(chǔ)桶索引現(xiàn)在將隨著存儲(chǔ)桶中對(duì)象數(shù)的增加而自動(dòng)重新分片。重新分片發(fā)生時(shí),您無(wú)需停止在存儲(chǔ)桶中讀取或?qū)懭雽?duì)象。動(dòng)態(tài)重新分片是RGW的本機(jī)功能,如果該存儲(chǔ)桶中的對(duì)象數(shù)量超過(guò)100K,則RGW會(huì)自動(dòng)識(shí)別需要重新分片的存儲(chǔ)桶,RGW通過(guò)產(chǎn)生一個(gè)負(fù)責(zé)處理已調(diào)度的特殊線程來(lái)為該存儲(chǔ)桶調(diào)度重新分片操作。動(dòng)態(tài)重新分片現(xiàn)在是默認(rèn)功能,管理員無(wú)需采取任何措施即可激活它。
在本文中,我們將深入探討與動(dòng)態(tài)重新分片功能相關(guān)的性能,并了解如何使用預(yù)分片的存儲(chǔ)區(qū)將其中的某些內(nèi)容最小化。
測(cè)試方法
為了研究在單個(gè)存儲(chǔ)桶中存儲(chǔ)大量對(duì)象以及動(dòng)態(tài)存儲(chǔ)桶重新分片所帶來(lái)的性能影響,我們特意為每種測(cè)試類型使用單個(gè)存儲(chǔ)桶。同樣,使用默認(rèn)的RHCS 3.3調(diào)整創(chuàng)建了存儲(chǔ)桶。測(cè)試包括兩種類型:
- 動(dòng)態(tài)存儲(chǔ)桶重新分片測(cè)試,單個(gè)存儲(chǔ)桶最多可存儲(chǔ)3000萬(wàn)個(gè)對(duì)象
- 預(yù)先進(jìn)行存儲(chǔ)桶測(cè)試,其中存儲(chǔ)了大約2億個(gè)對(duì)象
對(duì)于每種類型的測(cè)試,COSBench測(cè)試分為50個(gè)回合,其中每個(gè)回合寫入1小時(shí),然后分別進(jìn)行15分鐘的讀取和RWLD(70Read,20Write,5List,5Delete)操作。因此,在整個(gè)測(cè)試周期中,我們?cè)趦蓚€(gè)存儲(chǔ)桶中寫入了約2.45億個(gè)對(duì)象。
動(dòng)態(tài)存儲(chǔ)桶重新分片:性能洞察
如上所述,動(dòng)態(tài)存儲(chǔ)區(qū)重新分片是RHCS中的默認(rèn)功能,當(dāng)存儲(chǔ)區(qū)中存儲(chǔ)的對(duì)象數(shù)量超過(guò)某個(gè)閾值時(shí),該功能會(huì)啟動(dòng)。圖1顯示了性能變化,同時(shí)不斷向桶中填充物體。第一輪測(cè)試交付了約5.4K Ops,同時(shí)在被測(cè)試的存儲(chǔ)桶中存儲(chǔ)了約80萬(wàn)個(gè)對(duì)象。
隨著測(cè)試輪的進(jìn)行,我們不斷在桶中裝滿物品。第44輪測(cè)試交付了約3.9K Ops,而存儲(chǔ)桶中的對(duì)象數(shù)量達(dá)到了約3000萬(wàn)。隨著對(duì)象計(jì)數(shù)的增加,存儲(chǔ)區(qū)分片計(jì)數(shù)也從第1輪的16(默認(rèn))增加到第44輪的512。如圖1所示,吞吐量Ops的突然下降很可能歸因于存儲(chǔ)桶上的RGW動(dòng)態(tài)重新分片活動(dòng)。
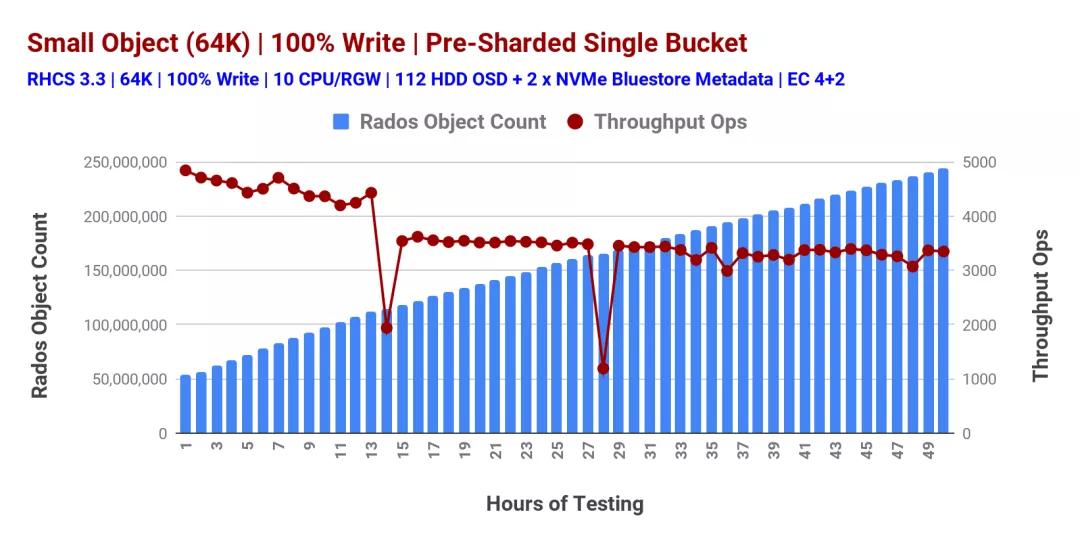
圖1:RGW動(dòng)態(tài)存儲(chǔ)桶重新分片
預(yù)共享存儲(chǔ)桶:性能洞察
帶有一個(gè)過(guò)度填充的bucket的非確定性性能(圖1)引導(dǎo)我們進(jìn)入下一個(gè)測(cè)試類型,在將任何對(duì)象存儲(chǔ)在bucket中之前,我們預(yù)先對(duì)其進(jìn)行了分片。這一次,我們?cè)谶@個(gè)預(yù)切分的bucket中存儲(chǔ)了超過(guò)1.9億個(gè)對(duì)象,我們測(cè)量了性能,如圖2所示。因此,我們觀察到預(yù)切分的桶性能穩(wěn)定,但是,在測(cè)試的第14和28小時(shí),性能突然下降了兩次,這是由于RGW動(dòng)態(tài)桶切分。
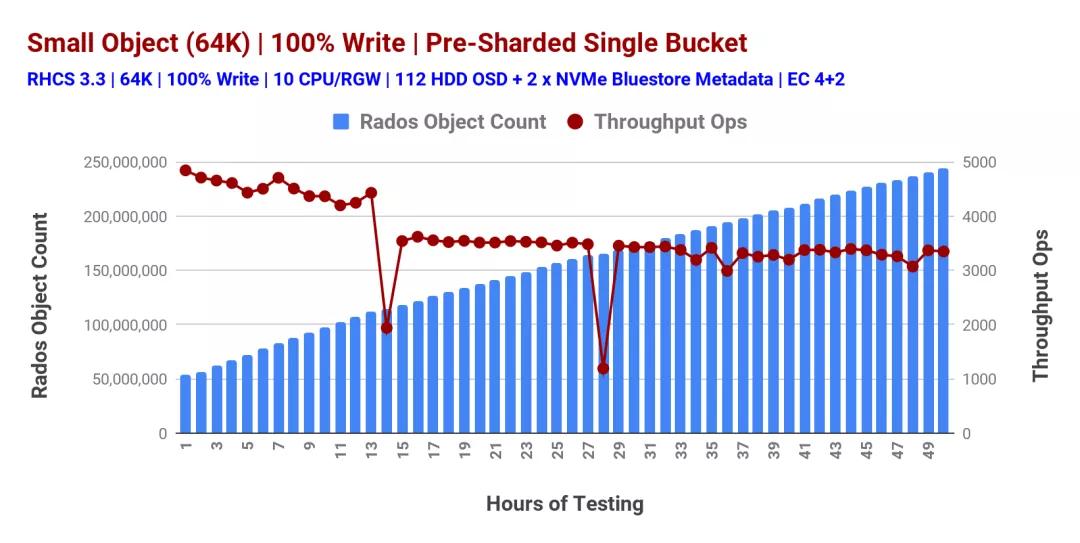
圖2:預(yù)共享桶
圖3顯示了預(yù)分片存儲(chǔ)桶和動(dòng)態(tài)分片存儲(chǔ)桶的性能對(duì)比。根據(jù)測(cè)試后存儲(chǔ)區(qū)統(tǒng)計(jì)數(shù)據(jù),我們認(rèn)為這兩個(gè)類別的性能突然下降是由動(dòng)態(tài)重新分片事件引起的。
因此,預(yù)分片存儲(chǔ)有助于實(shí)現(xiàn)確定性性能,因此從架構(gòu)的角度來(lái)看,以下是一些指導(dǎo):
如果知道應(yīng)用程序的對(duì)象存儲(chǔ)消耗模式,特別是每個(gè)存儲(chǔ)桶的預(yù)期對(duì)象數(shù)(數(shù)量),在這種情況下,對(duì)存儲(chǔ)桶進(jìn)行預(yù)分片通常會(huì)有所幫助。
如果每個(gè)存儲(chǔ)桶中要存儲(chǔ)的對(duì)象數(shù)未知,則動(dòng)態(tài)存儲(chǔ)桶重新分片功能將自動(dòng)完成該工作。但是,在重新分片時(shí)會(huì)消耗少量的性能。
我們的測(cè)試方法夸大了這些事件在集群級(jí)別的影響。在測(cè)試期間,每個(gè)客戶端都向不同的存儲(chǔ)區(qū)寫入數(shù)據(jù),并且每個(gè)客戶端都傾向于以相似的速率寫入對(duì)象。其結(jié)果是,客戶端正在寫入的存儲(chǔ)桶以相似的時(shí)序超過(guò)了動(dòng)態(tài)分片閾值。在現(xiàn)實(shí)環(huán)境中,動(dòng)態(tài)分片事件更有可能在時(shí)間上得到更好的分布。
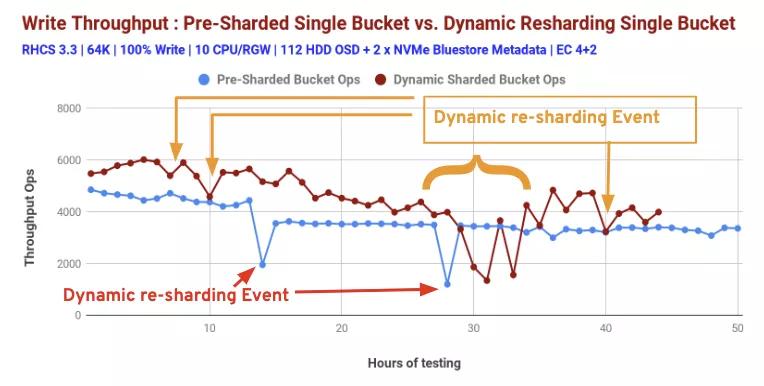
圖表3:動(dòng)態(tài)存儲(chǔ)桶重新分片和預(yù)分片存儲(chǔ)桶性能比較:100%寫入
發(fā)現(xiàn)動(dòng)態(tài)重新分片的存儲(chǔ)桶的讀取性能比預(yù)共享的存儲(chǔ)桶略高,但是預(yù)分片的存儲(chǔ)桶具有確定的性能,如圖4所示。
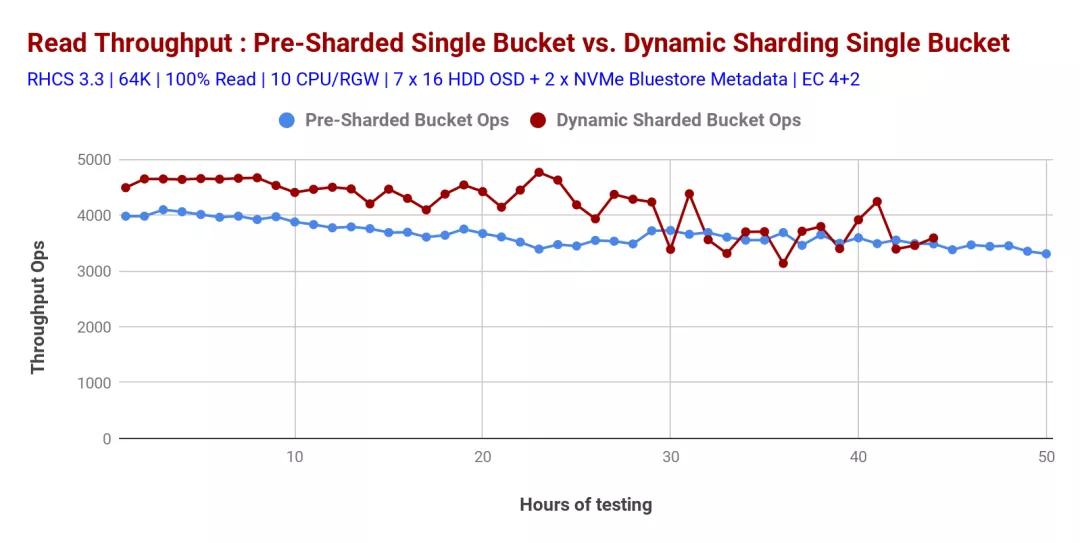
圖表4:動(dòng)態(tài)存儲(chǔ)桶重新分片和預(yù)分片存儲(chǔ)桶性能比較:100%讀取
總結(jié)
如果我們知道應(yīng)用程序?qū)⒃谝粋€(gè)存儲(chǔ)桶中存儲(chǔ)多少個(gè)對(duì)象,則對(duì)存儲(chǔ)桶進(jìn)行預(yù)分片通常有助于提高整體性能。另一方面,如果事先不知道對(duì)象數(shù),則Ceph RGW的動(dòng)態(tài)存儲(chǔ)桶重新分片功能確實(shí)有助于避免與過(guò)載存儲(chǔ)桶相關(guān)的性能下降。
5、Ceph Bluestore的壓縮機(jī)制及性能影響
通過(guò)BlueStore OSD后端,Red Hat Ceph Storage獲得了一項(xiàng)稱為“實(shí)時(shí)數(shù)據(jù)壓縮”的新功能,該功能有助于節(jié)省磁盤空間。可以在BlueStore OSD上創(chuàng)建的每個(gè)Ceph池上啟用或禁用壓縮。除此之外,無(wú)論池中是否包含數(shù)據(jù),均可使用Ceph CLI隨時(shí)更改壓縮算法和模式。在此博客中,我們將深入研究BlueStore的壓縮機(jī)制,并了解其對(duì)性能的影響。
BlueStore中的數(shù)據(jù)是否被壓縮取決于壓縮模式和與寫操作相關(guān)的任何提示的組合。BlueStore提供的不同壓縮模式是:
- none:從不壓縮數(shù)據(jù)。
- passive:除非寫操作具有可壓縮的提示集,否則不要壓縮數(shù)據(jù)。
- aggressive:壓縮數(shù)據(jù),除非寫操作具有不可壓縮的提示集。
- force:無(wú)論如何都嘗試壓縮數(shù)據(jù)。即使客戶端暗示數(shù)據(jù)不可壓縮,在所有情況下都使用壓縮。
可以通過(guò)每個(gè)池屬性或全局配置選項(xiàng)來(lái)設(shè)置compression_mode,compression_algorithm,compression_required_ratio,compression_min-blob_size和compresion_max_blob_size參數(shù)。可以通過(guò)以下方式設(shè)置“pool”屬性:
- ceph osd pool set <pool-name> compression_algorithm <algorithm>
- ceph osd pool set <pool-name> compression_mode <mode>
- ceph osd pool set <pool-name> compression_required_ratio <ratio>
- ceph osd poll set <pool-name> compression_min_blob_size <size>
- ceph osd pool set <pool-name> compression_max_blob_size <size>
Bluestore壓縮內(nèi)部構(gòu)件
Bluestore不會(huì)壓縮任何等于或小于min_alloc_size配置的寫入。在具有默認(rèn)值的部署中,SSD的min_alloc_size為16KiB,而HDD為64 KiB。在我們的案例中,我們使用的是全閃存(SSD)介質(zhì),IO大小小于32KiB的Ceph不會(huì)進(jìn)行任何壓縮嘗試。
為了能夠在較小的塊大小下測(cè)試壓縮性能,我們以4KiB的min_alloc_size重新部署了Ceph集群,通過(guò)對(duì)Ceph配置的修改,我們能夠以8KiB塊大小實(shí)現(xiàn)壓縮。
請(qǐng)注意,從Ceph集群中的默認(rèn)配置修改min_alloc_size會(huì)對(duì)性能產(chǎn)生影響。在我們將大小從16 KiB減小到4KiB的情況下,我們正在修改8KiB和16KiB塊大小IO的數(shù)據(jù)路徑,它們將不再是延遲寫入并首先進(jìn)入WAL設(shè)備,任何大于4KiB的塊將直接寫入OSD配置的塊設(shè)備中。
Bluestore Compression配置和測(cè)試方法
為了了解BlueStore壓縮的性能方面,我們進(jìn)行了如下測(cè)試:
1.在Red Hat Openstack Platform 10上運(yùn)行40個(gè)實(shí)例,每個(gè)實(shí)例附加一個(gè)Cinder卷(40xRBD卷)。然后,我們使用隨附的Cinder卷創(chuàng)建并安裝了XFS文件系統(tǒng)。
2.使用FIO libRBD IOengine進(jìn)行84xRBD卷。
Pbench-Fio用作首選的基準(zhǔn)測(cè)試工具,具有3個(gè)新的FIO參數(shù)(如下所示),以確保FIO在測(cè)試期間將生成可壓縮的數(shù)據(jù)集。
- refill_buffers
- buffer_compress_percentage=80
- buffer_pattern=0xdeadface
我們使用aggressive的壓縮模式運(yùn)行測(cè)試,以便我們壓縮所有對(duì)象,除非客戶端提示它們不可壓縮。測(cè)試期間使用了以下Ceph bluestore壓縮全局選項(xiàng)
- bluestore_compression_algorithm:snappy
- bluestore_compression_mode:aggressive
- bluestore_compression_required_ratio:.875
bluestore_compression_required_ratio是此處的關(guān)鍵可調(diào)參數(shù),其計(jì)算公式為
- bluestore_compression_required_ratio = size_compressed/siz_original
默認(rèn)值為0.875,這意味著如果壓縮未將大小減小至少12.5%,則將不壓縮對(duì)象。由于凈增益低,高于此比率的對(duì)象將不會(huì)壓縮存儲(chǔ)。
要知道我們?cè)贔IO綜合數(shù)據(jù)集測(cè)試期間實(shí)現(xiàn)的壓縮量,我們使用了四個(gè)Ceph性能指標(biāo):
- Bluestore_compressed_original。被壓縮的原始字節(jié)的總和。
- Bluestore_compressed_allocated。分配給壓縮數(shù)據(jù)的字節(jié)總數(shù)。
- Compress_success_count。有益壓縮操作的總和。
- Compress_rejected_count。壓縮操作的總和因空間凈增益低而被拒絕。
要查詢上述性能指標(biāo)的當(dāng)前值,我們可以對(duì)正在運(yùn)行的一個(gè)osd使用Ceph perf dump命令:
- ceph daemon osd.X perf dumo | grep -E'(compress _.* _ count | bluestore_compressed_)'
在壓縮基準(zhǔn)測(cè)試期間從客戶端測(cè)量的關(guān)鍵指標(biāo):
- IOPS。每秒完成的IO操作總數(shù)
- Average lantency。客戶端完成IO操作所需的平均時(shí)間。
- P95%。延遲的95%。
- P99%。延遲的99%。
測(cè)試實(shí)驗(yàn)室配置
該測(cè)試實(shí)驗(yàn)室由5個(gè)RHCS全閃存(NVMe)服務(wù)器和7個(gè)客戶端節(jié)點(diǎn)組成,詳細(xì)的硬件和軟件配置分別如表1和2所示。請(qǐng)參閱此博客文章,以獲取有關(guān)實(shí)驗(yàn)室設(shè)置的更多詳細(xì)信息。
小塊:FIO綜合基準(zhǔn)測(cè)試
重要的是要考慮到,使用Bluestore壓縮可以節(jié)省的空間完全取決于應(yīng)用程序工作負(fù)載的可壓縮性以及所使用的壓縮模式。因此,對(duì)于8KB的塊大小和40個(gè)帶有主動(dòng)壓縮的RBD卷,我們已經(jīng)實(shí)現(xiàn)了以下 compress_success_count和compress_rejected_count。
- “ compress_success_count”:48190908,
- “ compress_rejected_count”:26669868,
在我們的數(shù)據(jù)集執(zhí)行的74860776個(gè)寫請(qǐng)求總數(shù)(8KB)中,我們能夠成功壓縮48190908個(gè)寫請(qǐng)求,因此在我們的綜合數(shù)據(jù)集中成功壓縮的寫請(qǐng)求百分比為64%。
查看 bluestore_compressed_allocated和bluestore_comprperformance計(jì)數(shù)器,我們可以看到通過(guò)Bluestore壓縮,成功壓縮的64%的寫操作已轉(zhuǎn)換為每個(gè)OSD節(jié)省60Gb的空間。
- “ bluestore_compressed_allocated”:60988112896
- “ bluestore_compressed_original”:121976225792
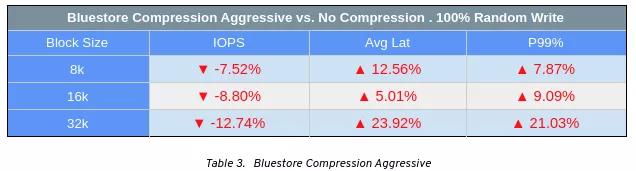
如圖1 /表1所示,在比較“積極壓縮”與“不壓縮”時(shí),我們觀察到IOPS百分比下降,這不是很明顯。同時(shí),發(fā)現(xiàn)平均和尾部潛伏期略高。造成這種性能負(fù)擔(dān)的原因之一是,Ceph BlueStore壓縮每個(gè)對(duì)象blob以匹配compression_required_ratio,然后將確認(rèn)發(fā)送回客戶端。結(jié)果,當(dāng)壓縮設(shè)置為激進(jìn)時(shí),我們看到IOPS略有降低,平均和尾部延遲增加。
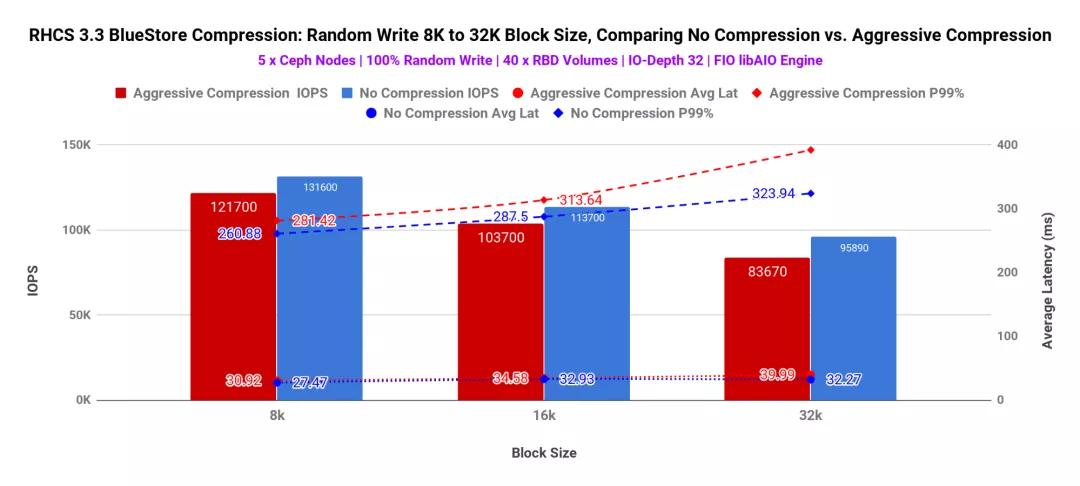
圖表1:FIO 100%寫測(cè)試-40個(gè)RBD卷
如圖2所示,我們嘗試通過(guò)對(duì)主動(dòng)壓縮池和非壓縮池中的84個(gè)RBD卷運(yùn)行FIO來(lái)增加群集上的負(fù)載。我們觀察到了類似的性能差異,如圖1所示。與沒(méi)有壓縮相比,BlueStore壓縮消耗了少許性能。實(shí)際上,任何聲稱提供動(dòng)態(tài)壓縮功能的存儲(chǔ)系統(tǒng)都可以期望這一點(diǎn)。
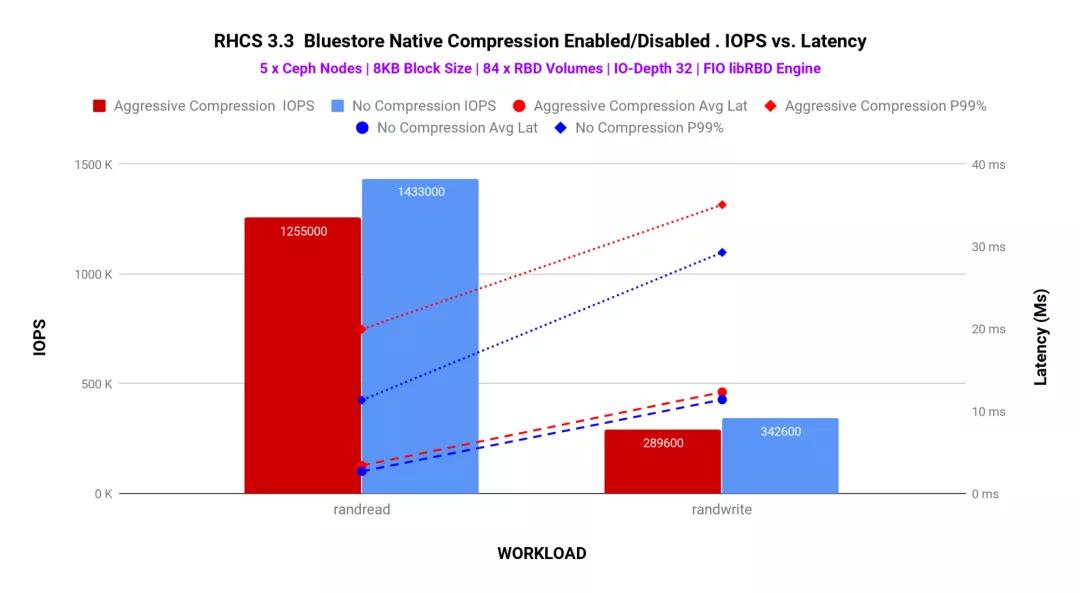
圖表2:FIO 100%隨機(jī)讀取/隨機(jī)寫入測(cè)試-84 RBD卷
壓縮還具有與之相關(guān)的計(jì)算成本。數(shù)據(jù)壓縮是通過(guò)諸如snappy和zstd之類的算法完成的,它們需要CPU周期來(lái)壓縮原始blob并將其存儲(chǔ)。如圖3所示,塊大小較小(8K)時(shí),主動(dòng)壓縮和無(wú)壓縮之間的CPU利用率增量較低。隨著將塊大小增加到16K / 32K / 1M,此增量也會(huì)增加。原因之一可能是,對(duì)于更大的塊大小,壓縮算法需要做更多的工作才能壓縮blob和存儲(chǔ),從而導(dǎo)致更高的CPU消耗。
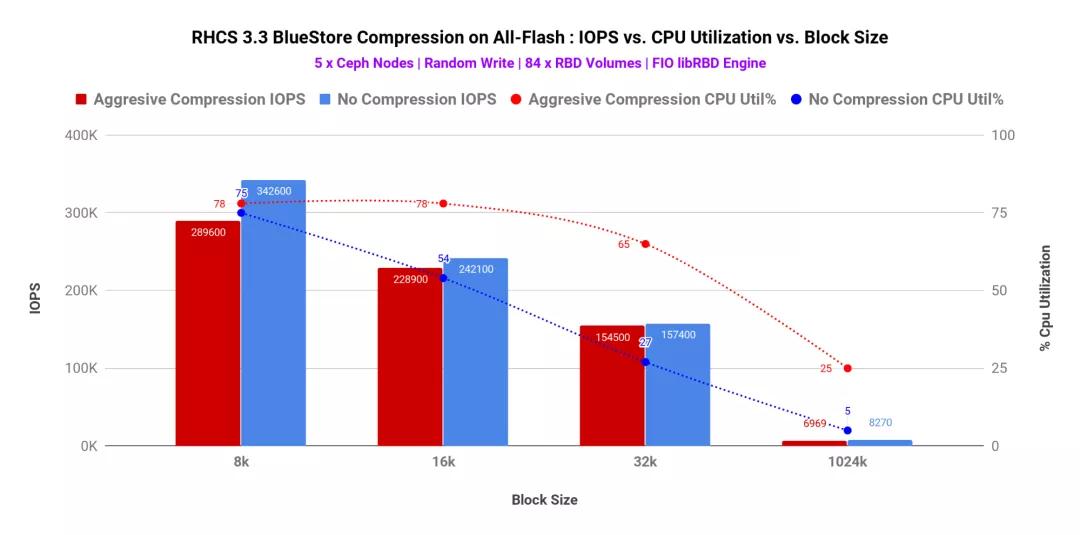
圖表3:FIO 100%隨機(jī)寫入測(cè)試-84個(gè)RBD卷(IOPS與CPU%利用率)
大塊(1MB):FIO綜合基準(zhǔn)測(cè)試
與小塊大小相似,我們還測(cè)試了具有不同壓縮模式的大塊大小工作負(fù)載。因此,我們已經(jīng)測(cè)試了侵略性(aggressive),強(qiáng)制性和非壓縮性模式。如圖4所示,攻擊模式和強(qiáng)制模式的總吞吐量非常相似,我們沒(méi)有觀察到明顯的性能差異。除了隨機(jī)讀取工作負(fù)載以外,在隨機(jī)讀寫和隨機(jī)寫入模式下,壓縮(積極/強(qiáng)制)與非壓縮模式之間的性能差異很大。
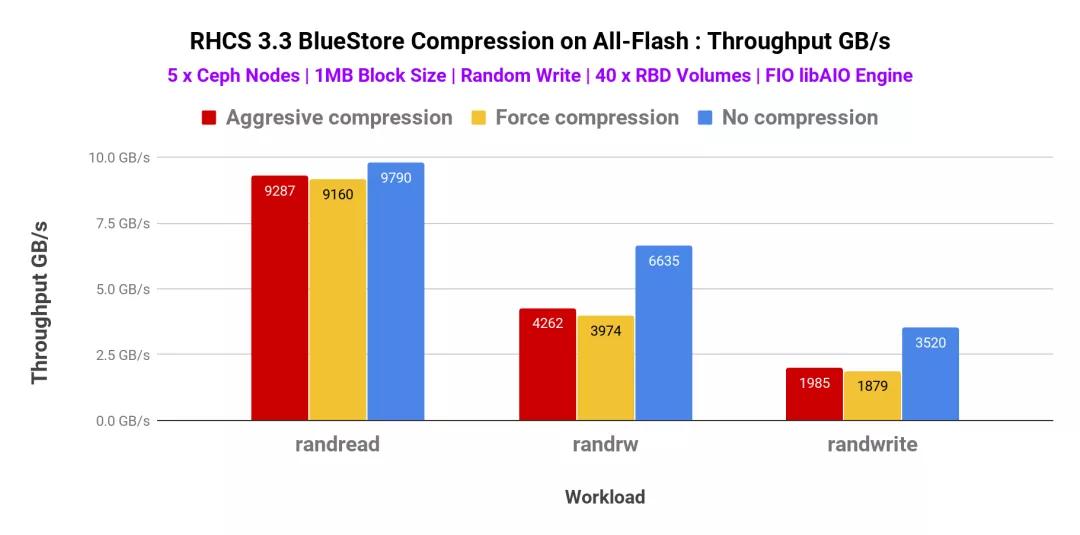
圖表4:FIO 1MB-40 RBD卷
為了確定系統(tǒng)上的更多負(fù)載,我們使用了libRBD FIO IO引擎并生成了84個(gè)RBD卷。該測(cè)試的性能如圖5所示
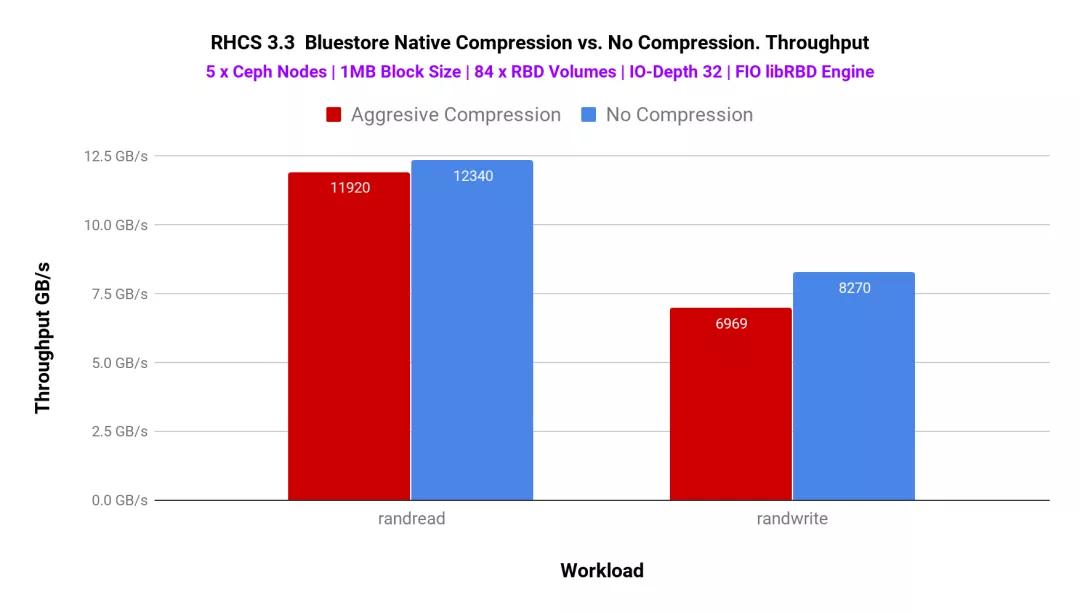
圖表5:FIO 1MB-84 RBD卷
MySQL數(shù)據(jù)庫(kù)池上的Bluestore壓縮
到目前為止,我們已經(jīng)討論了由PBench-Fio自動(dòng)化的基于FIO的綜合性能測(cè)試。為了了解BlueStore壓縮在接近實(shí)際的生產(chǎn)工作負(fù)載中的性能含義,我們?cè)趬嚎s和未壓縮的存儲(chǔ)池上測(cè)試了多個(gè)MySQL數(shù)據(jù)庫(kù)實(shí)例的性能。
MySQL測(cè)試方法
Bluestore的配置與之前的測(cè)試相同,使用的是快速算法和主動(dòng)壓縮模式。我們?cè)贠penStack上部署了20個(gè)VM實(shí)例,這些實(shí)例托管在5個(gè)計(jì)算節(jié)點(diǎn)上。在這20個(gè)VM實(shí)例中,有10個(gè)VM用作MySQL數(shù)據(jù)庫(kù)實(shí)例,而其余10個(gè)實(shí)例是MySQL數(shù)據(jù)庫(kù)客戶端,因此在數(shù)據(jù)庫(kù)實(shí)例和DB客戶端之間創(chuàng)建了1:1關(guān)系。
通過(guò)Cinder為10xMariadb服務(wù)器配置了1x100GB RBD卷,并將其安裝在上/var/lib/mysql。dd在創(chuàng)建文件系統(tǒng)并將其安裝之前,通過(guò)使用該工具寫入完整的塊設(shè)備來(lái)對(duì)該卷進(jìn)行預(yù)處理 。
- /dev/mapper/APLIvg00-lv_mariadb_data 99G 8.6G 91G 9% /var/lib/mysql
測(cè)試過(guò)程中使用的MariaDB配置文件在本要點(diǎn)中可用。數(shù)據(jù)集是使用以下sysbench命令在每個(gè)數(shù)據(jù)庫(kù)上創(chuàng)建的。
- sysbench oltp_write_only --threads=64 --table_size=50000000 --mysql-host=$i --mysql-db=sysbench --mysql-user=sysbench --mysql-password=secret --db-driver=mysql --mysql_storage_engine=innodb prepare
創(chuàng)建數(shù)據(jù)集后,運(yùn)行以下三種類型的測(cè)試:
- 讀
- 寫
- 讀_寫
在每次測(cè)試之前,必須重新啟動(dòng)mariadb實(shí)例以清除innodb緩存,每個(gè)測(cè)試均在900秒內(nèi)運(yùn)行并重復(fù)2次,捕獲的結(jié)果是兩次運(yùn)行的平均值。
MySQL測(cè)試結(jié)果
Bluestore壓縮所能節(jié)省的空間完全取決于應(yīng)用程序工作負(fù)載的可壓縮性以及所使用的壓縮模式。
通過(guò)Mysql壓縮測(cè)試,結(jié)合了Sysbench生成的數(shù)據(jù)集和經(jīng)過(guò)積極壓縮的bluestore默認(rèn)compression_required_ratio(0.875),我們獲得了以下計(jì)數(shù)。
- compress_success_count:594148,
- compress_rejected_count:1991191,
在我們的數(shù)據(jù)集中運(yùn)行的2585339個(gè)寫入請(qǐng)求總數(shù)中,我們能夠成功壓縮594148個(gè)寫入請(qǐng)求,因此在Mysql Sysbench數(shù)據(jù)集中成功壓縮的寫入請(qǐng)求百分比為22%。
查看 bluestore_compressed_allocated和bluestore_compressed_original性能計(jì)數(shù)器,我們可以看到成功壓縮的22%的寫操作通過(guò)壓縮轉(zhuǎn)換為每個(gè)OSD節(jié)省了20Gb的空間。
- bluestore_compressed_allocated:200351744,
- bluestore_compressed_original:400703488,
借助Ceph-metrics,我們?cè)贛ySQL測(cè)試期間監(jiān)視了OSD節(jié)點(diǎn)上的系統(tǒng)資源。發(fā)現(xiàn)OSD節(jié)點(diǎn)的平均cpu使用率低于14%,磁盤利用率低于9%范圍,發(fā)現(xiàn)磁盤延遲平均低于2 ms,且峰值保持在個(gè)位數(shù)。
如圖6所示,BlueStore壓縮未嚴(yán)重影響每秒MySQL事務(wù)(TPS)。與不壓縮TPS和事務(wù)延遲相比,BlueStore主動(dòng)壓縮確實(shí)表現(xiàn)出較小的性能負(fù)擔(dān)。
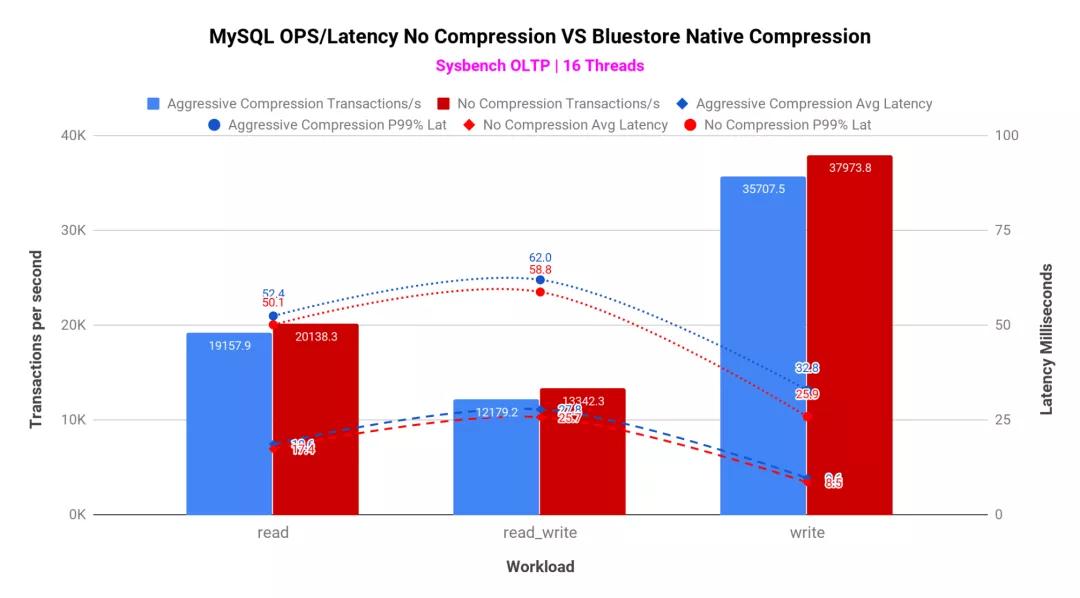
圖6:MySQL數(shù)據(jù)庫(kù)池上的BlueStore壓縮
重要要點(diǎn)
- 與非壓縮池相比,啟用了BlueStore壓縮功能的池與基于FIO的綜合工作負(fù)載相比,性能僅降低10%,而對(duì)MySQL數(shù)據(jù)庫(kù)工作負(fù)載僅降低7%。這種減少歸因于執(zhí)行數(shù)據(jù)壓縮的基礎(chǔ)算法。
- 使用較小的塊大小(8K),發(fā)現(xiàn)主動(dòng)壓縮和無(wú)壓縮模式之間的CPU利用率增量較低。隨著我們?cè)黾訅K大小(16K / 32K / 1M),此增量也會(huì)增加
- 低管理開(kāi)銷,同時(shí)在Ceph池上啟用壓縮。Ceph CLI開(kāi)箱即用,提供了啟用壓縮所需的所有功能。
6、Ceph 3.3與2.2前后端對(duì)比
這篇文章是我們兩年前基于Red Hat Ceph Storage 2.0 FileStore OSD后端和Civetweb RGW前端進(jìn)行的對(duì)象存儲(chǔ)性能測(cè)試的續(xù)篇。在本文中,我們將比較(撰寫本文時(shí))最新可用的 Ceph Storage的性能,即3.3版(BlueStore OSD后端和Beast RGW前端)與Ceph Storage 2.0版(2017年中)(FileStore OSD后端和Civetweb RGW前端)。
我們意識(shí)到,這兩個(gè)性能研究的結(jié)果在科學(xué)上都不具有可比性。但是,我們認(rèn)為,將兩者進(jìn)行比較應(yīng)該可以為您提供重要的性能見(jiàn)解,并使您能夠在架構(gòu)Ceph存儲(chǔ)群集時(shí)做出明智的決定。
正如預(yù)期的那樣,在我們測(cè)試的所有工作負(fù)載中,Ceph Storage 3.3的性能均優(yōu)于Ceph Storage 2.0。我們認(rèn)為Ceph Storage 3.3的性能改進(jìn)歸因于幾件事的結(jié)合。BlueStore OSD后端,RGW的Beast Web前端,BlueStore WAL使用的Intel Optane SSD,block.db和最新一代的Intel Cascade Lake處理器。
讓我們仔細(xì)看一下兩個(gè)Ceph Storage版本的性能比較。
測(cè)試實(shí)驗(yàn)室配置
這是我們實(shí)驗(yàn)室環(huán)境的簡(jiǎn)要介紹。測(cè)試是在Dell EMC實(shí)驗(yàn)室中使用其硬件以及英特爾提供的硬件進(jìn)行的。
Ceph Storage 3.3環(huán)境
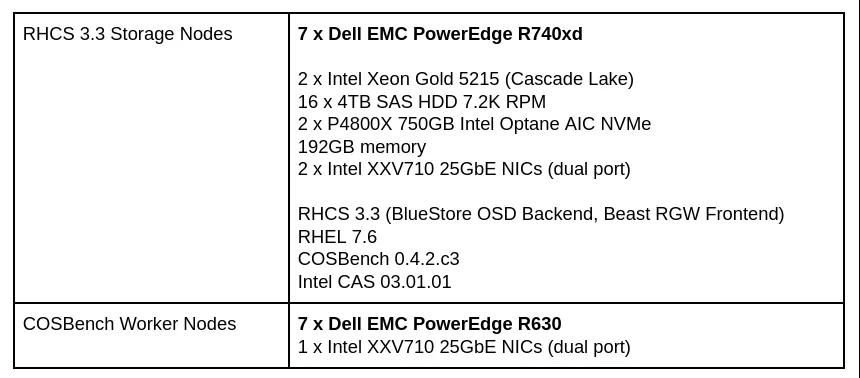
表1:Ceph Storage 3.3測(cè)試實(shí)驗(yàn)室配置
Ceph Storage 2.0環(huán)境

表2:Ceph Storage 2.0測(cè)試實(shí)驗(yàn)室配置
小對(duì)象性能
在本節(jié)中,我們將研究小型對(duì)象的性能。
小對(duì)象100%的寫入工作量
圖表1比較了Ceph Storage 3.3和Ceph Storage 2.0版本的小對(duì)象100%寫入工作負(fù)載的性能。如圖所示,與Ceph Storage 2.0相比,Ceph Storage 3.3始終提供更高的數(shù)量級(jí)每秒操作(Ops)性能。因此,我們發(fā)現(xiàn)Ceph Storage 3.3的操作數(shù)提高了500%以上。
您可能想知道,Ceph Storage 3.3性能線出現(xiàn)2倍性能急劇下降的原因是什么?據(jù)稱是因?yàn)橛蒖GW動(dòng)態(tài)桶重新分片事件導(dǎo)致的(參考上文內(nèi)容)。
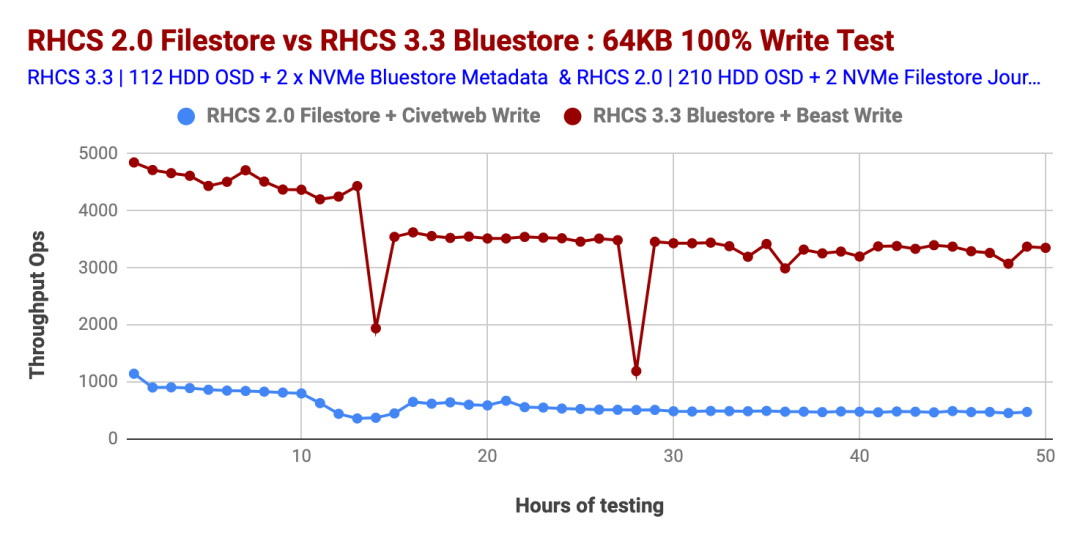
圖表1:小對(duì)象大小100%寫性能
小對(duì)象100%讀取工作負(fù)載
與Ceph Storage 2.0相比,Ceph Storage 3.3的100%讀取工作負(fù)載顯示出近乎完美的性能,而Ceph Storage 2.0的性能在大約第18小時(shí)的測(cè)試中直線下降。對(duì)于Ceph Storage 2.0,讀取OPS的下降是由于隨著群集對(duì)象數(shù)量的增加,文件系統(tǒng)元數(shù)據(jù)查找所花費(fèi)的時(shí)間增加所致。
當(dāng)群集中包含較少的對(duì)象時(shí),內(nèi)核會(huì)在內(nèi)存中緩存更大比例的文件系統(tǒng)元數(shù)據(jù)。但是,當(dāng)群集增長(zhǎng)到數(shù)百萬(wàn)個(gè)對(duì)象時(shí),緩存了較小百分比的元數(shù)據(jù)。然后,磁盤被迫執(zhí)行專門用于元數(shù)據(jù)查找的I / O操作,從而增加了額外的磁盤搜索,并導(dǎo)致讀取的OPS降低。
Ceph Storage 3.3及更高版本的Bluestore OSD后端在讀取操作期間不依賴Linux頁(yè)面緩存。這樣,Bluestore OSD會(huì)執(zhí)行自己的內(nèi)存管理,因此有助于實(shí)現(xiàn)讀取工作負(fù)載的確定性性能,如圖2所示。
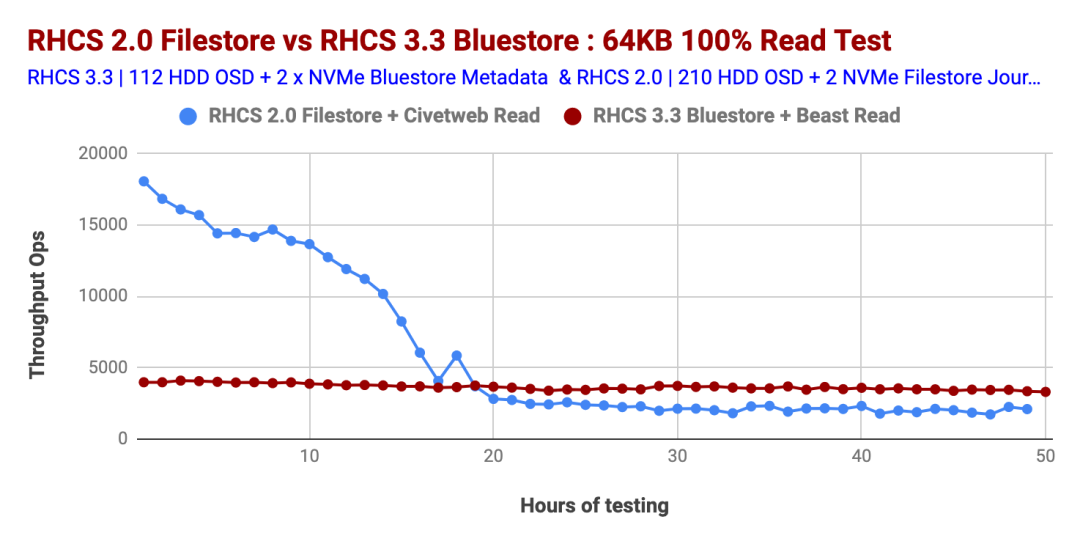
圖表2:小型物件100%的讀取效能
大對(duì)象性能
接下來(lái),我們將注意力轉(zhuǎn)向大型對(duì)象性能基準(zhǔn)測(cè)試。
大對(duì)象100%的寫入工作量
對(duì)于大對(duì)象100%寫入測(cè)試,Ceph Storage 3.3提供了次線性性能改進(jìn),而Ceph Storage 2.0顯示了逆向性能,如圖3所示。在Ceph Storage 2.0測(cè)試期間,我們?nèi)鄙俑郊拥腞GW節(jié)點(diǎn),而Containerized Storage Daemon也沒(méi)有一個(gè)選項(xiàng)。因此,對(duì)于Ceph Storage 2.0測(cè)試,我們無(wú)法測(cè)試超過(guò)4個(gè)RGW。
除非子系統(tǒng)資源飽和,否則Ceph Storage 3.3的寫入帶寬約為5.5 GBps。另一方面,Ceph Storage 2.0的性能卻下降了。
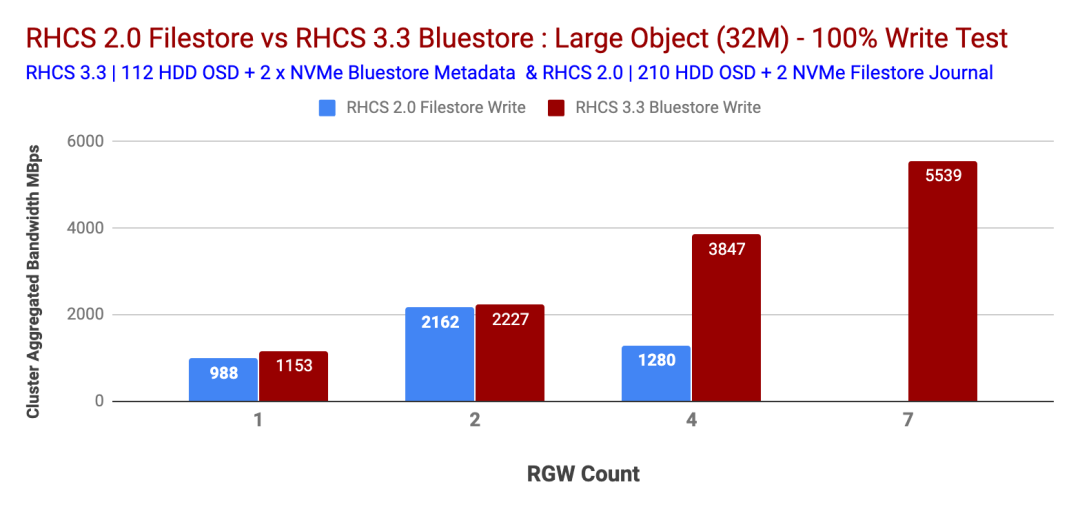
圖表3:大對(duì)象大小100%的寫入性能
大對(duì)象100%讀取工作負(fù)載
大對(duì)象100%的讀取工作負(fù)載顯示了Ceph Storage 2.0和3.3測(cè)試的次線性性能。如上一節(jié)所述,在Ceph Storage 2.0測(cè)試時(shí),我們沒(méi)有用于RGW的其他物理節(jié)點(diǎn),因此我們被限制為4個(gè),無(wú)法進(jìn)一步擴(kuò)展RGW。
Ceph Storage 3.3顯示5.5 GBps 100%的讀取帶寬,在7個(gè)RGW的情況下未發(fā)現(xiàn)瓶頸。我們的假設(shè)是,如果我們添加更多的RGW,Ceph Storage 3.3可能會(huì)提供更多的帶寬。圖表4比較了100%大對(duì)象工作負(fù)載下Ceph Storage 3.3和Ceph Storage 2.2的性能。
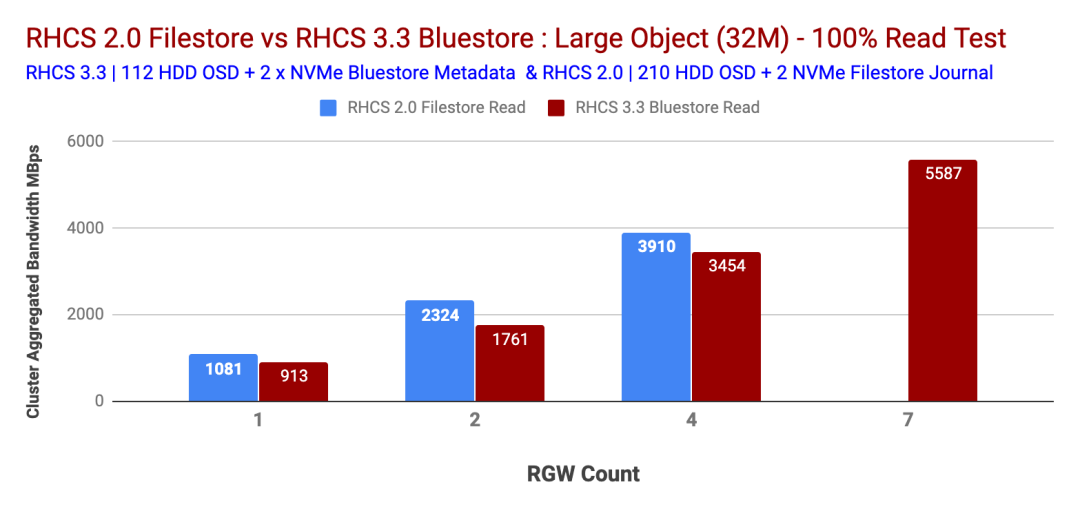
圖4:大對(duì)象大小100%的讀取性能
總結(jié)
我們承認(rèn),上面顯示的性能比較并不完全相似的對(duì)比。我們相信這項(xiàng)研究應(yīng)該為您提供不同Ceph Storage版本的關(guān)鍵性能見(jiàn)解,并幫助您做出明智的決定。
我們盡力在這兩項(xiàng)研究中選擇共同點(diǎn)。有趣的是,只有一半的磁盤軸(110 Ceph Storage 3.3 test vs 210 Ceph Storage 2.0 test)帶有BlueStore OSD后端和Beast RGW前端web服務(wù)器的Ceph Storage 3.3為小對(duì)象提供了5倍高的操作,為大對(duì)象提供了2倍高的帶寬100%的寫入工作負(fù)載。在下一篇文章中,我們將揭示在Ceph集群中存儲(chǔ)10億多個(gè)對(duì)象的性能。
7、Ceph擴(kuò)展到超過(guò)十億個(gè)對(duì)象
這是Red Hat Ceph對(duì)象存儲(chǔ)性能系列中的第六篇。在這篇文章中,我們將進(jìn)行深入研究,學(xué)習(xí)如何將經(jīng)過(guò)測(cè)試的Ceph擴(kuò)展到超過(guò)十億個(gè)對(duì)象,并分享在此過(guò)程中發(fā)現(xiàn)的性能秘密。為了更好地理解本文中顯示的性能結(jié)果,建議閱文章的第一部分內(nèi)容,其中詳細(xì)介紹了實(shí)驗(yàn)室環(huán)境,性能工具包和所用方法。
執(zhí)行摘要
- 讀取:觀察到一致的聚合吞吐量(Ops)和讀取延遲。
- 寫入:觀察到一致的寫入延遲,直到群集達(dá)到大約容量的90%。
- 在整個(gè)測(cè)試周期中,我們沒(méi)有觀察到CPU、內(nèi)存、HDD、NVMe和網(wǎng)絡(luò)上的任何瓶頸。我們也沒(méi)有觀察到Ceph守護(hù)進(jìn)程的任何問(wèn)題,這些問(wèn)題表明集群在存儲(chǔ)對(duì)象的數(shù)量上有困難。
- 此測(cè)試是在相對(duì)較小的集群上執(zhí)行的。元數(shù)據(jù)溢出到較慢的設(shè)備上的組合效應(yīng)以及集群容量的大量使用影響了整體性能。可以通過(guò)正確調(diào)整Bluestore元數(shù)據(jù)設(shè)備的大小并在集群中保持足夠的可用容量來(lái)緩解這種情況。
表現(xiàn)摘要
- 成功攝取了超過(guò)十億個(gè)對(duì)象(準(zhǔn)確地說(shuō)是1,014,912,090個(gè)對(duì)象),這些對(duì)象通過(guò)S3對(duì)象接口跨10K存儲(chǔ)桶分布到Ceph集群中,而操作或數(shù)據(jù)一致性挑戰(zhàn)為零。這證明了Ceph集群的可擴(kuò)展性和健壯性。
- 當(dāng)集群中的對(duì)象總數(shù)接近8.5億時(shí),我們的存儲(chǔ)容量不足。當(dāng)群集填充率達(dá)到約90%時(shí),我們需要為更多的對(duì)象騰出空間,因此我們從以前的測(cè)試中刪除了較大的對(duì)象,并激活了均衡器模塊。他們共同創(chuàng)造了額外的負(fù)載,我們認(rèn)為這會(huì)降低客戶端吞吐量并增加延遲。
- 有害的寫入性能反映了Bluestore元數(shù)據(jù)從閃存溢出到低速設(shè)備的情況。對(duì)于涉及存儲(chǔ)數(shù)十億個(gè)對(duì)象的用例,建議為Bluestore元數(shù)據(jù)(block.db)適當(dāng)調(diào)整SSD的大小,以避免rocksDB級(jí)別溢出到速度較慢的設(shè)備上。
- 使用 bluestore_min_alloc_size = 64KB會(huì)導(dǎo)致小型擦除編碼對(duì)象的空間顯著放大。
- 減少 bluestore_min_alloc_size消除了空間放大問(wèn)題,但是由于18KB未對(duì)齊4KB,導(dǎo)致對(duì)象創(chuàng)建速率降低。
- SSD 的默認(rèn) bluestore_min_alloc_size 在RHCS 4.1中將更改為4KB,并且使4KB也適合HDD的工作。
- 對(duì)于批量刪除操作,發(fā)現(xiàn)S3對(duì)象刪除API與Ceph Rados API相比要慢得多。因此,我們建議您使用“對(duì)象到期存儲(chǔ)桶生命周期”,或使用radosgw-admin工具進(jìn)行批量刪除操作。
測(cè)試方法
要將十億個(gè)對(duì)象存儲(chǔ)到Ceph集群中,我們使用了COSBench并執(zhí)行了數(shù)百次測(cè)試回合,其中每一回合包括
- 創(chuàng)建14個(gè)新的存儲(chǔ)桶。
- 每個(gè)存儲(chǔ)區(qū)可攝取(即寫入)100,000個(gè)64KB有效負(fù)載大小的對(duì)象。
- 在300秒的時(shí)間內(nèi)讀取盡可能多的書面對(duì)象。
績(jī)效結(jié)果
Ceph被設(shè)計(jì)為一個(gè)固有的可擴(kuò)展系統(tǒng)。我們?cè)诖隧?xiàng)目中進(jìn)行的十億個(gè)對(duì)象提取測(cè)試強(qiáng)調(diào)了Ceph可擴(kuò)展性且非常重要的維度。在本節(jié)中,我們將分享在將10億個(gè)對(duì)象存儲(chǔ)到Ceph集群時(shí)捕獲的相關(guān)發(fā)現(xiàn)。
讀取表現(xiàn)
圖1表示以聚合吞吐量(ops)指標(biāo)衡量的讀取性能。圖2顯示了平均讀取延遲,以毫秒為單位(藍(lán)線)。這兩個(gè)圖表均顯示了從Ceph群集獲得的強(qiáng)大且一致的讀取性能,而測(cè)試套件吸收了超過(guò)十億個(gè)對(duì)象。在整個(gè)測(cè)試過(guò)程中,讀取吞吐量保持在15K Ops-10K Ops的范圍內(nèi)。這種性能差異可能與高存儲(chǔ)容量消耗(約90%)以及在后臺(tái)發(fā)生的舊的大對(duì)象刪除和重新平衡操作有關(guān)。
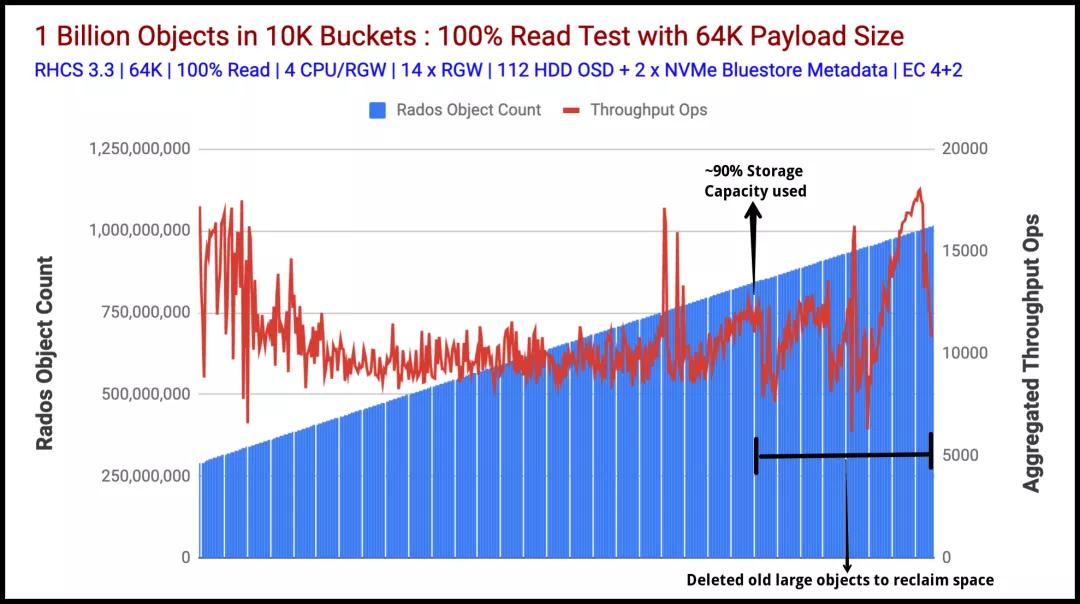
圖表1:對(duì)象計(jì)數(shù)與匯總讀取吞吐量操作
圖2比較了在讀取對(duì)象時(shí)讀寫測(cè)試的平均延遲(以毫秒為單位)(從客戶端測(cè)量)。在此測(cè)試規(guī)模的前提下,讀取和寫入延遲都保持非常一致,直到我們用盡存儲(chǔ)容量并將大量Bluestore元數(shù)據(jù)溢出到速度較慢的設(shè)備上為止。
測(cè)試的前半部分顯示,與讀取相比,寫入延遲保持較低。這可能是Bluestore效應(yīng)。我們過(guò)去所做的性能測(cè)試顯示了類似的行為,其中發(fā)現(xiàn)Bluestore寫延遲比Bluestore讀延遲略低,這可能是因?yàn)锽luestore不依賴Linux頁(yè)面緩存進(jìn)行預(yù)讀和OS級(jí)緩存。
在測(cè)試的后半部分,讀取延遲比寫入延遲低,這可能與Bluestore元數(shù)據(jù)從閃存溢出到慢速HDD有關(guān)(在下一節(jié)中說(shuō)明)。
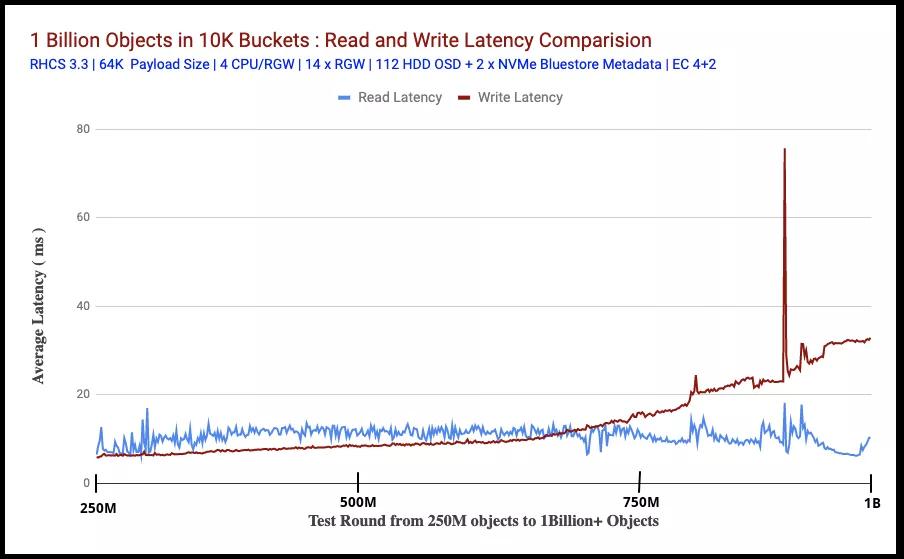
圖表2:讀寫延遲比較
寫性能
圖3表示通過(guò)其S3接口將十億個(gè)64K對(duì)象提取(寫入操作)到我們的Ceph集群。該測(cè)試從已經(jīng)存儲(chǔ)在Ceph集群中的大約2.9億個(gè)對(duì)象開(kāi)始。
該數(shù)據(jù)是由之前的測(cè)試運(yùn)行創(chuàng)建的,我們選擇不刪除該數(shù)據(jù),并從此時(shí)開(kāi)始填充集群,直到達(dá)到10億個(gè)對(duì)象為止。我們執(zhí)行了600多次獨(dú)特的測(cè)試,并在集群中填充了10億個(gè)對(duì)象。在課程中,我們測(cè)量了指標(biāo),例如總對(duì)象數(shù),讀寫吞吐量(Ops),讀寫平均延遲(ms)等。
在大約5億個(gè)對(duì)象的情況下,群集達(dá)到了其可用容量的50%,我們觀察到聚合寫入吞吐量性能下降的趨勢(shì)。經(jīng)過(guò)數(shù)百次測(cè)試后,聚合的寫吞吐量繼續(xù)下降,而群集使用的容量達(dá)到了驚人的90%。
從這一點(diǎn)出發(fā),為了達(dá)到我們的目標(biāo),即存儲(chǔ)十億個(gè)對(duì)象,我們需要更多的可用容量,因此我們刪除/重新平衡了大于64KB的舊對(duì)象。
眾所周知,通常隨著總體消耗的增加,存儲(chǔ)系統(tǒng)的性能會(huì)逐漸下降。我們觀察到與Ceph類似的行為,在大約90%的已用容量下,總吞吐量與我們最初開(kāi)始時(shí)相比有所下降。因此,我們認(rèn)為如果添加更多存儲(chǔ)節(jié)點(diǎn)以保持較低的利用率,則性能可能不會(huì)像我們觀察到的那樣遭受損失。
另一個(gè)有趣的發(fā)現(xiàn),我們發(fā)現(xiàn)Bluestore元數(shù)據(jù)頻繁從NVMe到HDD溢出導(dǎo)致聚合性能下降。我們攝取了大約十億個(gè)新對(duì)象,生成了許多Bluestore元數(shù)據(jù)。根據(jù)設(shè)計(jì),Bluestore元數(shù)據(jù)存儲(chǔ)在rocksDB中,建議將此分區(qū)存儲(chǔ)在Flash介質(zhì)上,在本例中,我們?yōu)槊總€(gè)OSD使用80GB NVMe分區(qū),該分區(qū)共享在Bluestore rocksDB和WAL之間。
rocksDB在內(nèi)部使用級(jí)別樣式壓縮,其中rocksDB中的文件被組織為多個(gè)級(jí)別。例如,Level-0(L0),Level-1(L1)等。級(jí)別0是特殊的,其將內(nèi)存中的寫緩沖區(qū)(內(nèi)存表)刷新到文件,并且其中包含最新數(shù)據(jù)。較高的級(jí)別包含較舊的數(shù)據(jù)。
當(dāng)L0文件達(dá)到特定閾值(可使用 level0_file_num_compaction_trigger進(jìn)行配置)時(shí),它們將合并到L1中。所有非0級(jí)都有目標(biāo)大小。rocksDB的壓縮目標(biāo)是將每個(gè)級(jí)別的數(shù)據(jù)大小限制在目標(biāo)范圍內(nèi)。將目標(biāo)大小計(jì)算為級(jí)別基礎(chǔ)大小x 10作為下一個(gè)級(jí)別乘數(shù)。因此,L0目標(biāo)大小為(250MB),L1(250MB),L2(2,500MB),L3(25,000MB)等。
所有級(jí)別的目標(biāo)大小的總和就是您需要的rocksDB存儲(chǔ)總量。根據(jù)Bluestore配置的建議,rocksDB存儲(chǔ)應(yīng)使用閃存介質(zhì)。如果我們沒(méi)有為rocksDB提供足夠的閃存容量來(lái)存儲(chǔ)其Levels,rocksDB會(huì)將Levels數(shù)據(jù)溢出到速度較慢的設(shè)備(例如HDD)上。畢竟,數(shù)據(jù)必須存儲(chǔ)在某個(gè)地方。
rocksDB元數(shù)據(jù)從閃存設(shè)備到HDD的這種溢出大大降低了性能。如圖4所示,當(dāng)我們將對(duì)象存儲(chǔ)到系統(tǒng)中時(shí),每個(gè)OSD溢出的元數(shù)據(jù)達(dá)到80GB以上。
因此,我們的假設(shè)是,Bluestore元數(shù)據(jù)從閃存介質(zhì)到慢速介質(zhì)的這種頻繁溢出是我們案例中聚合性能下降的原因。
這樣,如果您知道用例將涉及在Ceph集群上存儲(chǔ)數(shù)十億個(gè)對(duì)象,則可以通過(guò)對(duì)每個(gè)Ceph OSD使用適用于BlueStore(rocksDB)元數(shù)據(jù)的Ceph OSD使用較大的閃存分區(qū)來(lái)緩解性能影響,從而可以將其存儲(chǔ)在閃存上訪問(wèn)rocksDB的L4文件。
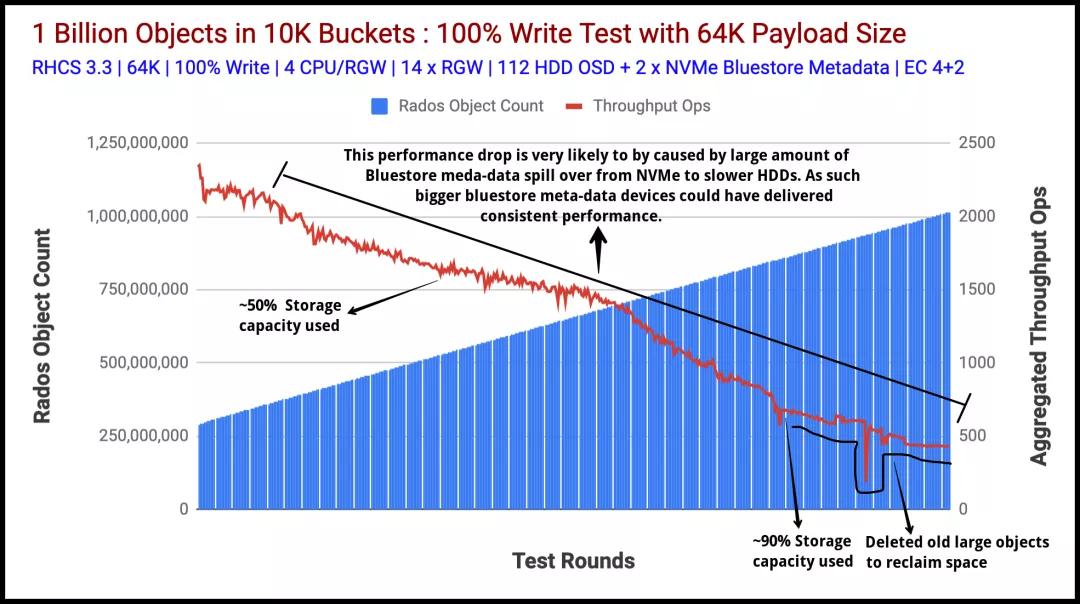
圖表3:對(duì)象計(jì)數(shù)與匯總寫入吞吐量操作
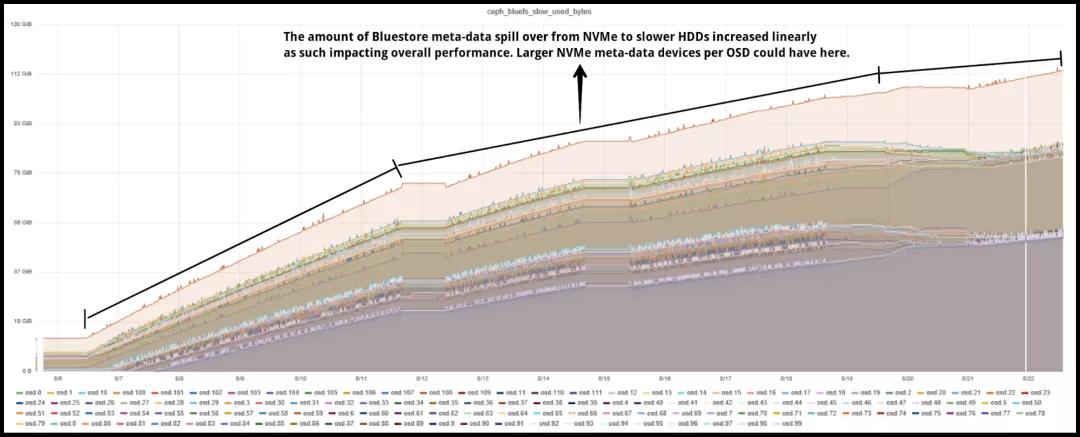
圖表4:Bluestore元數(shù)據(jù)溢出到慢速(HDD)設(shè)備上
其它發(fā)現(xiàn)
在本節(jié)中,我們希望涵蓋我們的一些其他發(fā)現(xiàn)。
大規(guī)模刪除對(duì)象
當(dāng)集群的存儲(chǔ)容量用盡時(shí),除了刪除存儲(chǔ)在存儲(chǔ)桶中的舊的大對(duì)象外,我們別無(wú)選擇,并且有數(shù)百萬(wàn)個(gè)這樣的對(duì)象。我們最初是從S3 API的DELETE方法開(kāi)始的,但很快我們意識(shí)到它不適用于存儲(chǔ)桶刪除,因?yàn)楸仨殑h除存儲(chǔ)桶中的所有對(duì)象,然后才能刪除存儲(chǔ)桶本身。
我們遇到的另一個(gè)S3 API限制是,每個(gè)API請(qǐng)求只能刪除1K個(gè)對(duì)象。我們有數(shù)百個(gè)存儲(chǔ)桶,每個(gè)存儲(chǔ)桶都有100K個(gè)對(duì)象,因此使用S3 API DELETE方法刪除數(shù)百萬(wàn)個(gè)對(duì)象對(duì)我們來(lái)說(shuō)是不切實(shí)際的。
幸運(yùn)的是,使用radosgw-admin CLI工具公開(kāi)的本機(jī)RADOS網(wǎng)關(guān)API支持刪除加載了對(duì)象的存儲(chǔ)桶。通過(guò)使用本機(jī)RADOS網(wǎng)關(guān)API,我們花了幾秒鐘刪除了數(shù)百萬(wàn)個(gè)對(duì)象。因此,對(duì)于任何規(guī)模的刪除對(duì)象,Ceph的本地API都可以挽救。
修改 bluestore_min_alloc_size_hdd參數(shù)
該測(cè)試是在具有4 + 2配置的擦除編碼池上完成的。因此,根據(jù)設(shè)計(jì),每個(gè)64K有效負(fù)載都必須分成4個(gè)16KB的塊。Bluestore使用的 bluestore_min_alloc_size_hdd參數(shù)表示為存儲(chǔ)在Ceph Bluestore對(duì)象存儲(chǔ)中的對(duì)象創(chuàng)建的Blob的最小大小,其默認(rèn)值為64KB。因此在這種情況下,將為每個(gè)16KB EC塊分配64KB空間,這將導(dǎo)致48KB的未使用空間開(kāi)銷,無(wú)法進(jìn)一步利用。
因此,在進(jìn)行10億個(gè)對(duì)象攝取測(cè)試之后,我們決定將 bluestore_min_alloc_size_hdd 降低到18KB并重新測(cè)試。如圖5所示,在將bluestore_min_alloc_size_hdd參數(shù)從64KB(默認(rèn)值)降低到18KB之后,發(fā)現(xiàn)對(duì)象創(chuàng)建速率顯著降低。因此,對(duì)于大于bluestore_min_alloc_size_hdd的對(duì)象,默認(rèn)值似乎是最佳值,如果打算減少bluestore_min_alloc_size_hdd參數(shù),則較小的對(duì)象還需要更多篩選。請(qǐng)注意,不能將bluestore_min_alloc_size_hdd設(shè)置為低于bdev_block_size(默認(rèn)值為4096-4kB)。
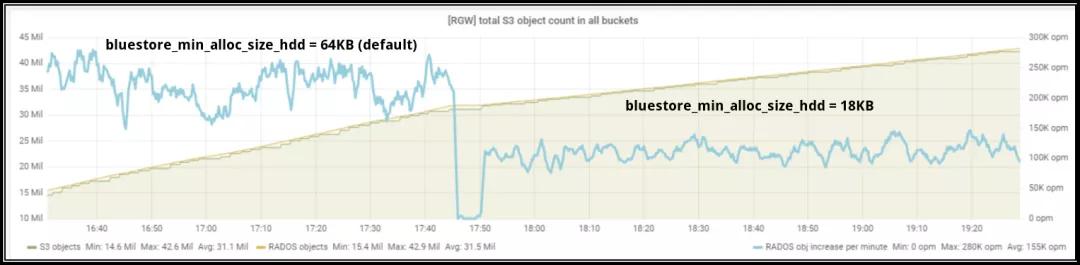
圖5:每分鐘的物體攝取率
總結(jié)
在本文中,我們通過(guò)將十億多個(gè)對(duì)象存儲(chǔ)到Ceph集群中,展示了Ceph集群的健壯性和可伸縮性。我們了解了與群集相關(guān)聯(lián)的各種性能特征,其中包括最大容量的群集,以及將bluestore元數(shù)據(jù)溢出到速度較慢的設(shè)備上如何提高性能,以及在設(shè)計(jì)大規(guī)模規(guī)模的Ceph群集時(shí)可以選擇的緩解措施。
參考鏈接:
https://www.redhat.com/en/blog/red-hat-ceph-object-store-dell-emc-servers-part-1
https://www.redhat.com/en/blog/red-hat-ceph-storage-rgw-deployment-strategies-and-sizing-guidance?source=blogchannel&channel=blog/channel/red-hat-storage&page=1
https://www.redhat.com/en/blog/achieving-maximum-performance-fixed-size-ceph-object-storage-cluster?source=blogchannel&channel=blog/channel/red-hat-storage&page=1
https://www.redhat.com/en/blog/ceph-rgw-dynamic-bucket-sharding-performance-investigation-and-guidance?source=blogchannel&channel=blog/channel/red-hat-storage&page=1
https://www.redhat.com/en/blog/red-hat-ceph-storage-33-bluestore-compression-performance?source=blogchannel&channel=blog/channel/red-hat-storage&page=1
https://www.redhat.com/en/blog/comparing-red-hat-ceph-storage-33-bluestorebeast-performance-red-hat-ceph-storage-20-filestorecivetweb?source=blogchannel&channel=blog/channel/red-hat-storage&page=1
https://www.redhat.com/en/blog/scaling-ceph-billion-objects-and-beyond?source=author&term=43551