明確解釋:機器學習與統計建模有何不同
它們彼此之間非常不同,所有數據科學家都必須了解原因和方式!
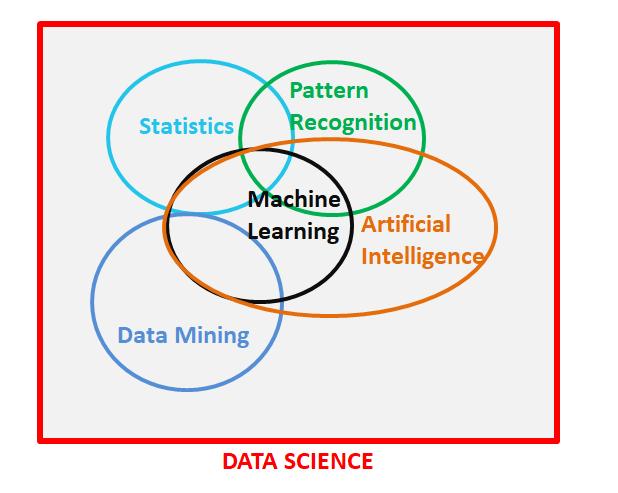
> Source: Inspired by a diagram from SAS Institute
這篇文章提出了一個非常重要的區別,我們應該將其理解為數據科學領域的活躍部分。 上面的維恩圖最初是由SAS Institute發布的,但是它們的圖顯示統計和機器學習之間沒有重疊,據我所知,這是一個疏忽。 我已盡我所能和理解,重新創建了該圖。 該維恩圖非常恰當地提出了數據科學所有分支的區別和重疊。
我想相信數據科學現在是總稱,其他所有術語都可以描述為數據科學的分支,每個分支都是不同的,但與其他分支卻是如此相似!
機器學習與統計建模:這是一個古老的問題,每個數據科學家/機器學習工程師或任何在這些領域開始工作的人都會遇到。 在研究這些領域時,有時機器學習感覺與統計建模息息相關,這使我們想知道如何區分兩者,或者哪種標簽最適合哪種模型。 當然,如今機器學習已成為流行語,但這并不意味著我們開始將統計模型標記為機器學習模型,因為與流行的看法相反,它們是不同的! 讓我們詳細了解差異。
這篇文章的流程將是:
- 機器學習和統計建模的定義
- 機器學習與統計建模之間的差異
- 什么時候使用?

定義
機器學習
在不依賴于基于規則的編程的情況下,對將數據轉換為智能動作的計算機算法開發感興趣的研究領域稱為機器學習。
統計建模
通常將統計模型指定為一個或多個隨機變量與其他非隨機變量之間的數學關系。 因此,統計模型是"理論的形式表示"。
現在,無聊的冗長的定義已不復存在,讓我們更深入地了解這兩個域之間的區別。
機器學習與統計建模之間的差異
1.歷史和學術相關性
在1950年代左右,機器學習開始出現之前,統計建模就已經出現了。1950年代,第一個機器學習程序—塞繆爾(Samuel)的檢查程序引入了。
世界各地的所有大學現在都在啟動其機器學習和AI計劃,但并沒有關閉其統計部門。
機器學習與計算機科學系和獨立的AI系協同教學,它們處理構建預測算法,這些算法能夠通過學習從數據中"學習"而無需任何預先指定的規則,從而能夠自行"智能化"。 上面ML的定義。
鑒于
統計建模與數學系共同教授,其重點是建立模型,該模型可以首先找到不同變量之間的關系,然后可以預測可以描述為其他自變量的函數的事件。
2.不確定度容限
這是兩個域之間重要的區別點。
在統計建模中,我們要注意許多不確定性估計(例如置信區間,假設檢驗),并且必須考慮到所有假設都必須滿足,才能信任特定算法的結果。 因此,它們具有較低的不確定性容限。
例如:如果我們建立了線性回歸模型,則在使用該模型的結果之前,必須檢查是否滿足以下假設:
- 因變量和自變量之間的線性關系
- 錯誤項的獨立性
- 錯誤項(殘差)需要正態分布
- 平均獨立
- 無多重共線性
- 需要方差
相反,如果我們建立了邏輯模型,則必須考慮以下假設:
- 二元邏輯回歸要求因變量為二進制,而序數邏輯回歸要求因變量為序。
- 觀察結果必須彼此獨立。
- 無多重共線性
- 自變量和對數奇數的線性
鑒于
在機器學習算法中,幾乎沒有或不需要假設。 ML算法對統計線性,殘差的正態分布等沒有嚴格要求,因此比統計模型靈活得多。因此,它們具有較高的不確定性容限。
3.數據需求與方法
統計模型無法在非常大的數據集上進行操作,它們需要屬性較少且觀測值數量可觀的可管理數據集。 在統計模型中,屬性的數量絕不會超過10–12,因為它們極易過擬合(在訓練數據集上表現出色,但在看不見的數據上表現差強人意,因為它確實非常接近訓練數據集,這是不希望出現的情況)
此外,大多數統計模型都遵循參數化方法(例如:線性回歸,邏輯回歸)
鑒于
機器學習算法是學習者算法,要學習它們需要大量數據。 因此,他們需要具有大量屬性和觀察結果的數據。 越大越好! ML算法在某種程度上需要大數據。
此外,大多數機器學習模型都遵循非參數方法(K最近鄰,決策樹,隨機森林,梯度提升方法,SVM等)。
什么時候使用?
這主要取決于以下說明的因素。 我們將講解理論上的要點,并舉例說明。
在以下情況下,統計模型應該是您的首選:
- 不確定性很低,因為當您開始構建模型時,大多數假設都已滿足
- 數據大小不是很大
- 如果要隔離少量變量的影響
- 總體預測中的不確定性/邊際誤差是可以的
- 各種自變量之間的相互作用相對較少,可以預先指定
- 需要高解釋性
機器學習可能是更好的選擇
- 當要預測的結果沒有很強的隨機性時; 例如,在視覺模式識別中,對象必須是E或不是E
- 可以對無限數量的精確重復進行訓練(例如,每個字母重復1000次或將某個單詞翻譯成德語)來訓練學習算法
- 當以整體預測為目標時,無法描述任何一個自變量的影響或變量之間的關系
- 人們對估計預測中的不確定性或所選預測器的影響不是很感興趣
- 數據量巨大
- 一個不需要隔離任何特殊變量的影響
- 低可解釋性,模型成為"黑匣子"是可以的
例如:如果您與一家信用卡公司合作,并且他們想建立一個跟蹤客戶流失的模型,那么他們很可能更喜歡一個統計模型,該模型將具有10–12個預測變量,他們可以根據自己的業務領域知識進行解釋和否決 ,在這種情況下,他們將不會喜歡黑盒算法,因為對可解釋性的需求比預測的準確性更高。
另一方面,如果您正在為想要構建強大的推薦引擎的Netflix和Amazon之類的客戶工作,那么在這種情況下,結果準確性的要求高于模型的可解釋性,因此,機器學習模型將 在這里就足夠了。
有了這個,我們到這篇文章的結尾。
您可以在以下文章中了解有關數據挖掘和機器學習之間的區別以及前4個機器學習算法的完整詳細信息:
- 明確解釋:機器學習與數據挖掘有何不同
- 定義,混淆,區別-全部說明
- 明確解釋:4種機器學習算法
- 定義,目的,流行算法和用例-全部說明
觀看此空間,以獲取有關機器學習,數據科學和統計學的更多信息!
學習愉快:)