說一下Zookeeper的ZAB協議?不好意思我肚子疼!
本文轉載自微信公眾號「 三太子敖丙」,轉載本文請聯系 三太子敖丙公眾號。
前言
Zab(Zookeeper Atomic Broadcast)是為ZooKeeper協設計的崩潰恢復原子廣播協議,它保證zookeeper集群數據的一致性和命令的全局有序性。
概念介紹
在介紹zab協議之前首先要知道zookeeper相關的幾個概念,才能更好的了解zab協議。
- 集群角色
- Leader:同一時間集群總只允許有一個Leader,提供對客戶端的讀寫功能,負責將數據同步至各個節點;
- Follower:提供對客戶端讀功能,寫請求則轉發給Leader處理,當Leader崩潰失聯之后參與Leader選舉;
- Observer:與Follower不同的是但不參與Leader選舉。
- 服務狀態
- LOOKING:當節點認為群集中沒有Leader,服務器會進入LOOKING狀態,目的是為了查找或者選舉Leader;
- FOLLOWING:follower角色;
- LEADING:leader角色;
- OBSERVING:observer角色;
可以知道Zookeeper是通過自身的狀態來區分自己所屬的角色,來執行自己應該的任務。
- ZAB狀態Zookeeper還給ZAB定義的4中狀態,反應Zookeeper從選舉到對外提供服務的過程中的四個步驟。狀態枚舉定義:
- public enum ZabState {
- ELECTION,
- DISCOVERY,
- SYNCHRONIZATION,
- BROADCAST
- }
- ELECTION: 集群進入選舉狀態,此過程會選出一個節點作為leader角色;
- DISCOVERY:連接上leader,響應leader心跳,并且檢測leader的角色是否更改,通過此步驟之后選舉出的leader才能執行真正職務;
- SYNCHRONIZATION:整個集群都確認leader之后,將會把leader的數據同步到各個節點,保證整個集群的數據一致性;
- BROADCAST:過渡到廣播狀態,集群開始對外提供服務。
- ZXID
Zxid是極為重要的概念,它是一個long型(64位)整數,分為兩部分:紀元(epoch)部分和計數器(counter)部分,是一個全局有序的數字。
epoch代表當前集群所屬的哪個leader,leader的選舉就類似一個朝代的更替,你前朝的劍不能斬本朝的官,用epoch代表當前命令的有效性,counter是一個遞增的數字。
選舉
基礎概念介紹完了,下面開始介紹zab協議是怎么支持leader選舉的。
進行leader有三個問題,什么時候進行?選舉規則?選擇流程?
下面我會一一解答這三個問題:
1.選舉發生的時機Leader發生選舉有兩個時機,一個是服務啟動的時候當整個集群都沒有leader節點會進入選舉狀態,如果leader已經存在就會告訴該節點leader的信息,自己連接上leader,整個集群不用進入選舉狀態。
還有一個就是在服務運行中,可能會出現各種情況,服務宕機、斷電、網絡延遲很高的時候leader都不能再對外提供服務了,所有當其他幾點通過心跳檢測到leader失聯之后,集群也會進入選舉狀態。
2.選舉規則進入投票選舉流程,怎么才能選舉出leader?或者說按照什么規則來讓其他節點都能選舉你當leader。
3.zab協議是按照幾個比較規則來進行投票的篩選,如果你的票比我更好,就修改自身的投票信息,改投你當leader。
下面代碼是zookeeper投票比較規則:
- /*
- * We return true if one of the following three cases hold:
- * 1- New epoch is higher
- * 2- New epoch is the same as current epoch, but new zxid is higher
- * 3- New epoch is the same as current epoch, new zxid is the same
- * as current zxid, but server id is higher.
- */
- return ((newEpoch > curEpoch)
- || ((newEpoch == curEpoch)
- && ((newZxid > curZxid)
- || ((newZxid == curZxid)
- && (newId > curId)))));
當其他節點的紀元比自身高投它,如果紀元相同比較自身的zxid的大小,選舉zxid大的節點,這里的zxid代表節點所提交事務最大的id,zxid越大代表該節點的數據越完整。
最后如果epoch和zxid都相等,則比較服務的serverId,這個Id是配置zookeeper集群所配置的,所以我們配置zookeeper集群的時候可以把服務性能更高的集群的serverId配置大些,讓性能好的機器擔任leader角色。
選舉流程
時機和規則都有了,下面就是leader的選舉流程:
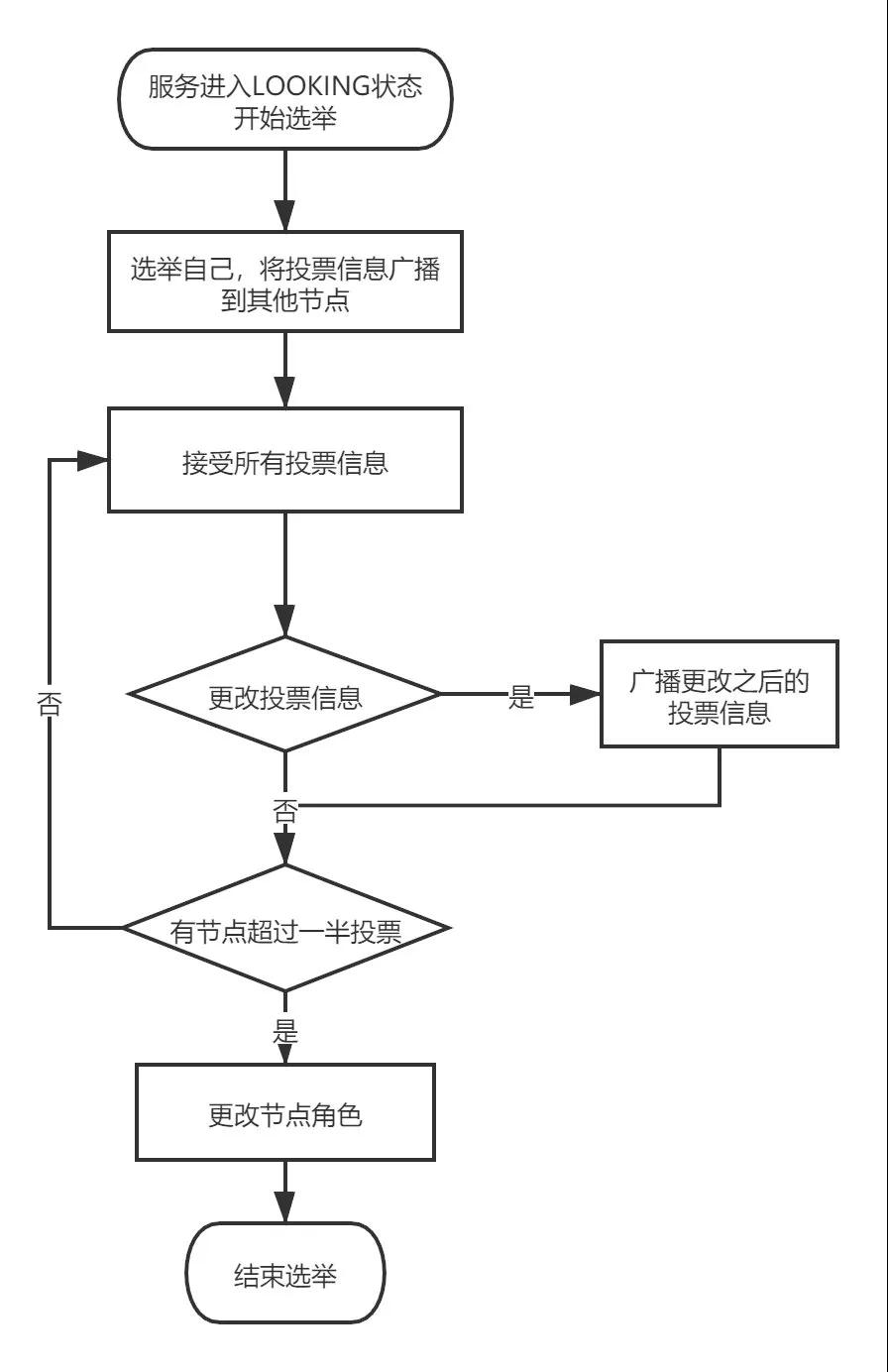
- 所有節點第一票先選舉自己當leader,將投票信息廣播出去;
- 從隊列中接受投票信息;
- 按照規則判斷是否需要更改投票信息,將更改后的投票信息再次廣播出去;
- 判斷是否有超過一半的投票選舉同一個節點,如果是選舉結束根據投票結果設置自己的服務狀態,選舉結束,否則繼續進入投票流程。
舉例
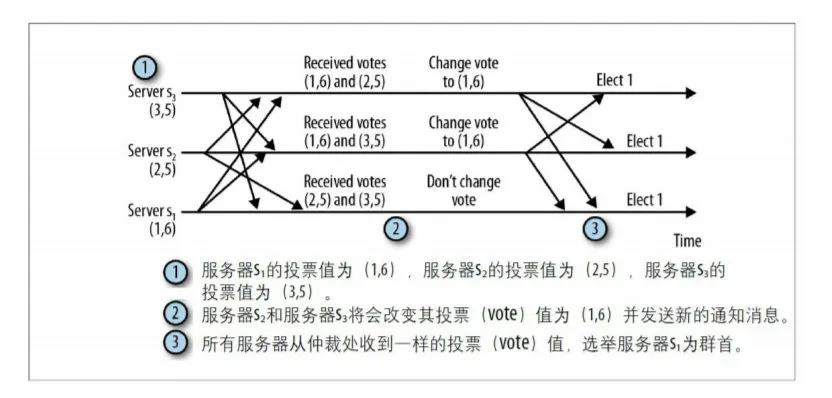
上圖來自《ZooKeeper:分布式過程協同技術詳解》,整體流程還是比較簡單,這里就不具體分析了。
廣播
集群在經過leader選舉之后還會有連接leader和同步兩個步驟,這里就不具體分析這兩個步驟的流程了,主要介紹集群對外提供服務如何保證各個節點數據的一致性。
zab在廣播狀態中保證以下特征
- 可靠傳遞: 如果消息m由一臺服務器傳遞,那么它最終將由所有服務器傳遞。
- 全局有序: 如果一個消息a在消息b之前被一臺服務器交付,那么所有服務器都交付了a和b,并且a先于b。
- 因果有序: 如果消息a在因果上先于消息b并且二者都被交付,那么a必須排在b之前。
有序性是zab協議必須要保證的一個很重要的屬性,因為zookeeper是以類似目錄結構的數據結構存儲數據的,必須要求命名的有序性。
比如一個命名a創建路徑為/test,然后命名b創建路徑為/test/123,如果不能保證有序性b命名在a之前,b命令會因為父節點不存在而創建失敗。
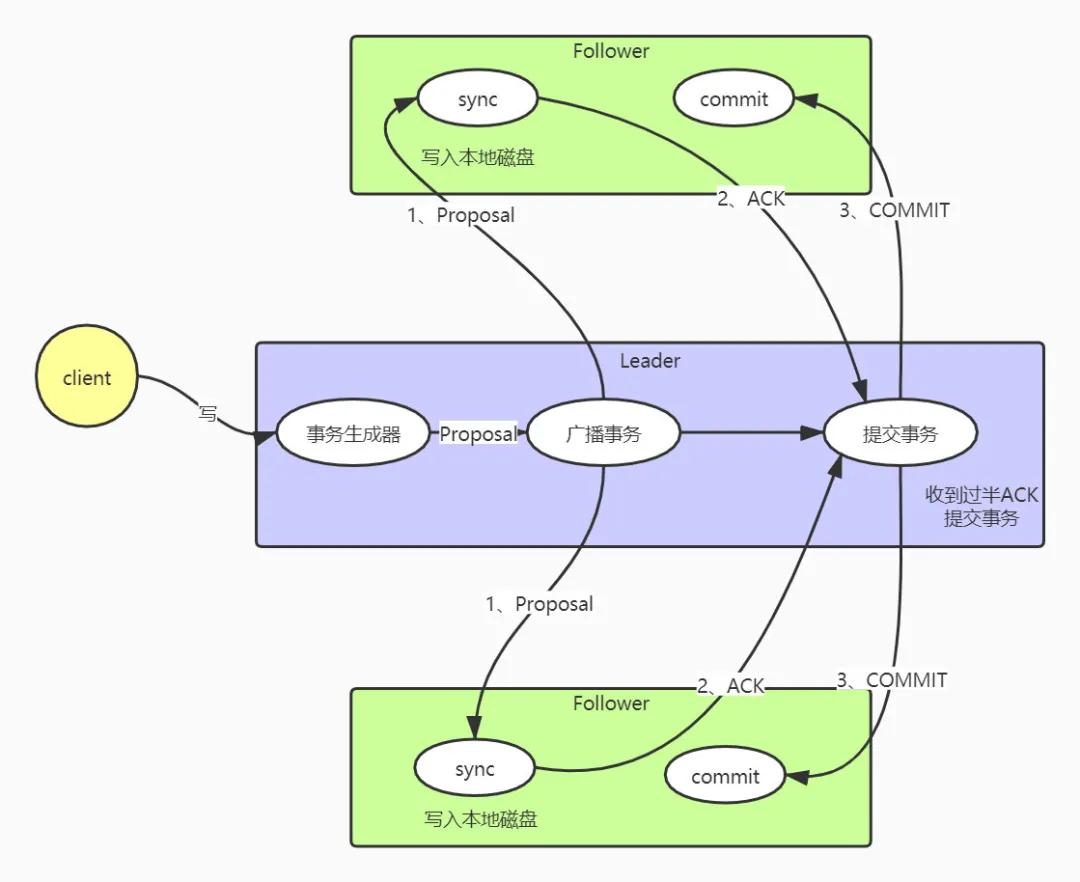
如上圖所示,整個寫請求類似一個二階段的提交。
當收到客戶端的寫請求的時候會經歷以下幾個步驟:
- Leader收到客戶端的寫請求,生成一個事務(Proposal),其中包含了zxid;
- Leader開始廣播該事務,需要注意的是所有節點的通訊都是由一個FIFO的隊列維護的;
- Follower接受到事務之后,將事務寫入本地磁盤,寫入成功之后返回Leader一個ACK;
- Leader收到過半的ACK之后,開始提交本事務,并廣播事務提交信息
- 從節點開始提交本事務。
有以上流程可知,zookeeper通過二階段提交來保證集群中數據的一致性,因為只需要收到過半的ACK就可以提交事務,所以zookeeper的數據并不是強一致性。
zab協議的有序性保證是通過幾個方面來體現的,第一是,服務之前用TCP協議進行通訊,保證在網絡傳輸中的有序性;第二,節點之前都維護了一個FIFO的隊列,保證全局有序性;第三,通過全局遞增的zxid保證因果有序性。
狀態流轉
前面介紹了zookeeper服務狀態有四種,ZAB狀態也有四種。這里就簡單介紹一個他們之間的狀態流轉,更能加深對zab協議在zookeeper工作流程中的作用。
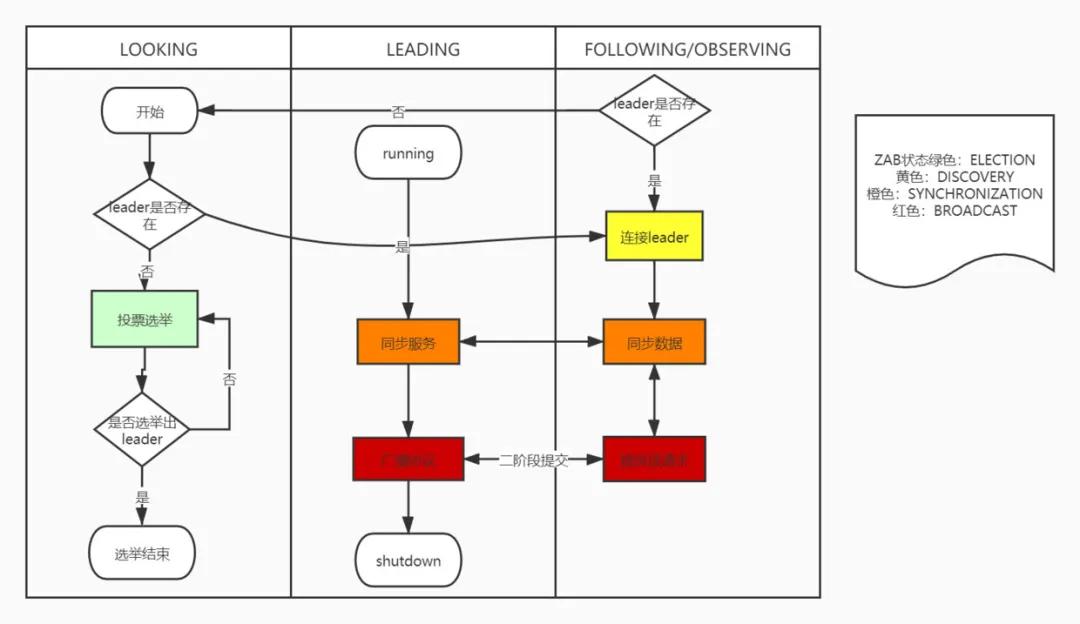
- 服務在啟動或者和leader失聯之后服務狀態轉為LOOKING;
- 如果leader不存在選舉leader,如果存在直接連接leader,此時zab協議狀態為ELECTION;
- 如果有超過半數的投票選擇同一臺server,則leader選舉結束,被選舉為leader的server服務狀態為LEADING,其他server服務狀態為FOLLOWING/OBSERVING;
- 所有server連接上leader,此時zab協議狀態為DISCOVERY;
- leader同步數據給learner,使各個從節點數據和leader保持一致,此時zab協議狀態為SYNCHRONIZATION;
- 同步超過一半的server之后,集群對外提供服務,此時zab狀態為BROADCAST。
可以知道整個zookeeper服務的工作流程類似一個狀態機的轉換,而zab協議就是驅動服務狀態流轉的關鍵,理解了zab就理解了zookeeper工作的關鍵原理
總結
本文對zab協議在zookeeper的工作流程中做了簡單的介紹,希望對大家理解學習zookeeper有所幫助。
我是敖丙,一個在互聯網茍且偷生的工具人。