基于機(jī)器學(xué)習(xí)的用戶實(shí)體行為分析技術(shù)在賬號異常檢測中的應(yīng)用
伴隨企業(yè)業(yè)務(wù)的不斷擴(kuò)增和電子化發(fā)展,企業(yè)自身數(shù)據(jù)和負(fù)載數(shù)據(jù)都開始暴增。然而,作為企業(yè)核心資產(chǎn)之一的內(nèi)部數(shù)據(jù),卻面臨著日益嚴(yán)峻的安全威脅。越來越多以周期長、頻率低、隱蔽強(qiáng)為典型特征的非明顯攻擊繞過傳統(tǒng)安全檢測方法,對大量數(shù)據(jù)造成損毀。
當(dāng)前,用戶實(shí)體行為分析(User and Entity Behavior Analytics,UEBA)系統(tǒng)正作為一種新興的異常用戶檢測體系在逐步顛覆傳統(tǒng)防御手段,開啟網(wǎng)絡(luò)安全保衛(wèi)從“被動防御”到“主動出擊”的新篇章。因此,將主要介紹UEBA在企業(yè)異常用戶檢測中的應(yīng)用情況。
首先,通過用戶、實(shí)體、行為三要素的關(guān)聯(lián),整合可以反映用戶行為基線的各類數(shù)據(jù);其次,定義4類特征提取維度,有效提取幾十種最能反映用戶異常的基礎(chǔ)特征;再次,將3種異常檢測算法通過集成學(xué)習(xí)方法用于異常用戶建模;最后,通過異常打分,定位異常風(fēng)險(xiǎn)最大的一批用戶。
在實(shí)踐中,對排名前10的異常用戶進(jìn)行排查,證明安恒信息的UEBA落地方式在異常用戶檢測中極其高效。隨著互聯(lián)網(wǎng)技術(shù)的日益發(fā)展和國家在大數(shù)據(jù)戰(zhàn)略層面的深化推動,數(shù)據(jù)采集終端越來越多,收錄的種類越來越豐富,數(shù)據(jù)已經(jīng)成為企業(yè)重要乃至最核心的資產(chǎn)之一。
在數(shù)據(jù)價(jià)值受到高度重視的同時(shí),企業(yè)面臨的各種針對數(shù)據(jù)安全威脅的問題也愈發(fā)嚴(yán)重,信息安全保障逐漸聚焦為數(shù)據(jù)的安全保障。通常情況下,外部攻擊種類繁多、持續(xù)高頻,企業(yè)習(xí)慣于將資源布置于構(gòu)筑安全防護(hù)堡壘,以抵御來自外部的進(jìn)攻。然而,除了外部的黑客攻擊,內(nèi)部人員參與信息販賣、共享第三方的違規(guī)泄露事件也層出不窮。
調(diào)查顯示,約有75%的安全威脅是從組織內(nèi)部發(fā)起的。無論是離職員工順走專利數(shù)據(jù),還是心懷怨恨的員工蓄意破壞系統(tǒng),一再發(fā)生的各種安全事件證明,攻破堡壘的最容易的方式往往來自內(nèi)部威脅。面對這種威脅,內(nèi)外雙向的安全需求催生了用戶實(shí)體行為分析(User and Entity Behavior Analytics,UEBA)。對內(nèi),傳統(tǒng)威脅防御手段不足。對于已經(jīng)意識到問題緊迫性的企業(yè)而言,使用傳統(tǒng)的安全技術(shù)并未能幫助他們有效解決來自內(nèi)部的安全問題。
原因在于傳統(tǒng)方法多為分散的、事后的、缺少針對性的。安全最薄弱的環(huán)節(jié)是人,只有建立以用戶為核心對象的分析體系,才能更加及時(shí)發(fā)現(xiàn)和終止內(nèi)部威脅,杜絕信息泄漏于萌芽狀態(tài)。對外,市場需求推動技術(shù)更新。
作為一種高級網(wǎng)絡(luò)威脅檢測手段,UEBA發(fā)展迅速,甚至正在顛覆原有市場格局。UEBA是基于大數(shù)據(jù)驅(qū)動、以用戶為核心、關(guān)聯(lián)實(shí)體資產(chǎn)、采用機(jī)器學(xué)習(xí)算法進(jìn)行異常分析以發(fā)現(xiàn)解決內(nèi)部威脅的一套框架和體系。
相較于傳統(tǒng)手段對安全事件的關(guān)注,UEBA更關(guān)心人,通過用戶畫像和資產(chǎn)畫像,檢測諸如賬號失陷、主機(jī)失陷、數(shù)據(jù)泄漏、權(quán)限濫用等風(fēng)險(xiǎn),以極高的準(zhǔn)確率定位異常用戶。
1 企業(yè)員工賬號的關(guān)聯(lián)
UEBA本質(zhì)上屬于數(shù)據(jù)驅(qū)動的安全分析技術(shù),需要采集大量而廣泛的用戶行為類數(shù)據(jù)。大數(shù)據(jù)時(shí)代,數(shù)據(jù)是一切分析的基礎(chǔ),少量的或者質(zhì)量不高的輸入必然導(dǎo)致價(jià)值不高的輸出。然而,這并不意味著數(shù)據(jù)純粹的越多越好,與場景不相關(guān)的數(shù)據(jù),過多收集只會增加系統(tǒng)負(fù)擔(dān)。
所以,行為分析的基礎(chǔ)是數(shù)據(jù),數(shù)據(jù)采集的前提是場景,采集的數(shù)據(jù)要和分析的特定場景相匹配,高質(zhì)量多種類的數(shù)據(jù)是用戶實(shí)體行為分析的核心。用戶實(shí)體行為分析可以使用的數(shù)據(jù),包括安全日志、網(wǎng)絡(luò)流量、威脅情報(bào)以及身份訪問相關(guān)日志等,盡可能多地接入和用戶場景相關(guān)的數(shù)據(jù),常見如VPN日志、OA日志、員工卡消費(fèi)日志以及門禁刷臉日志等。
可以將這些數(shù)據(jù)大致歸納為用戶身份數(shù)據(jù)、實(shí)體身份數(shù)據(jù)和用戶行為數(shù)據(jù)3種類型。用戶身份數(shù)據(jù)分為兩類:一類是真實(shí)身份數(shù)據(jù),如人事部門提供的員工資料;一類是虛擬身份數(shù)據(jù),如用戶在網(wǎng)絡(luò)上的注冊資料。由于UEBA嚴(yán)重依賴高質(zhì)量數(shù)據(jù),使得企業(yè)需要有數(shù)據(jù)治理的基礎(chǔ)能力,需要有統(tǒng)一的數(shù)據(jù)字典。
通過統(tǒng)一數(shù)據(jù)字典,可以統(tǒng)一不同日志的字段信息,進(jìn)而關(guān)聯(lián)不同日志的用戶信息,通過關(guān)聯(lián)真實(shí)身份與虛擬身份,達(dá)到定位具體的用戶的目標(biāo)。實(shí)體身份數(shù)據(jù)是網(wǎng)絡(luò)中用戶的唯一身份標(biāo)識,如IP地址、MAC地址等。用戶行為數(shù)據(jù)分類則可分為網(wǎng)絡(luò)行為信息和終端行為信息。
2 員工賬號與實(shí)體資產(chǎn)的關(guān)聯(lián)
員工賬號與實(shí)體資產(chǎn)的關(guān)聯(lián),即用戶身份數(shù)據(jù)與實(shí)體身份數(shù)據(jù)的關(guān)聯(lián),它們通過用戶行為數(shù)據(jù)實(shí)現(xiàn)關(guān)聯(lián)。例如,某用戶登錄VPN,通過登錄日志的用戶信息相關(guān)字段,可以定位用戶的身份信息。用戶使用VPN訪問公司內(nèi)網(wǎng),通過訪問日志的目標(biāo)地址信息相關(guān)字段,可以定位實(shí)體資產(chǎn)的身份信息,獲取會話期間終端日志信息,同時(shí)也實(shí)現(xiàn)員工賬號與實(shí)體資產(chǎn)的關(guān)聯(lián)。
訪問日志的獲取有多種形式,可以是VPN設(shè)備自身記錄的日志,也可以是其他安全設(shè)備的記錄日志,如深度包檢測(Deep Packet Inspection,DPI)系統(tǒng)日志。所謂“深度”是和普通的報(bào)文分析層次相比較而言的。
“普通報(bào)文檢測”僅分析IP包4層以下(物理層、數(shù)據(jù)鏈路層、網(wǎng)絡(luò)層、傳輸層)的內(nèi)容,包括源地址、目的地址、源端口、目的端口以及協(xié)議類型。而DPI除了對前面的4層進(jìn)行分析外,還增加了應(yīng)用層等其他層的分析,識別各種應(yīng)用及其內(nèi)容。DPI系統(tǒng)提供的審計(jì)信息、應(yīng)用程序會話識別信息、應(yīng)用程序會話流量統(tǒng)計(jì)信息、網(wǎng)絡(luò)傳輸層流量統(tǒng)計(jì)信息、應(yīng)用層流量統(tǒng)計(jì)信息等,可以極大豐富用戶網(wǎng)絡(luò)行為信息。終端日志可以通過終端檢測與響應(yīng)(Endpoint Detection and Response,EDR)系統(tǒng)獲取。
EDR日志可以幫助采集終端的內(nèi)存操作、磁盤操作、文件操作、系統(tǒng)調(diào)用、端口調(diào)用、網(wǎng)絡(luò)操作、注冊表操作等,通過分析進(jìn)程行為、應(yīng)用行為以及服務(wù)行為等,補(bǔ)全用戶終端行為信息。通過用戶網(wǎng)絡(luò)行為與終端行為等信息整合,可以完成用戶與實(shí)體的關(guān)聯(lián),同時(shí)也完整地還原了用戶的網(wǎng)絡(luò)會話和會話期間的用戶行為,為后期的行為分析提供高質(zhì)量的數(shù)據(jù)素材。
3 基礎(chǔ)特征提取
用戶行為特征提取是整個(gè)用戶行為分析建模的基礎(chǔ),需結(jié)合業(yè)務(wù)實(shí)際需求,找出相關(guān)的數(shù)據(jù)實(shí)體,以數(shù)據(jù)實(shí)體為中心,規(guī)約數(shù)據(jù)維度類型和關(guān)聯(lián)關(guān)系,形成符合業(yè)務(wù)實(shí)際情況的建模體系。一般的特征提取步驟包括用戶數(shù)據(jù)與實(shí)體數(shù)據(jù)的分解和對應(yīng)、實(shí)體間關(guān)聯(lián)關(guān)系分解、用戶特征維度分解以及用戶行為特征的提取。
相比算法層面的精進(jìn),有效提取數(shù)據(jù)特征經(jīng)常會取得更直接的收益,能夠展現(xiàn)數(shù)據(jù)的基本屬性和業(yè)務(wù)邏輯的特性,甚至僅需要使用簡單的模型就能取得很好的結(jié)果,而冗余的無邏輯特征不僅無益于建模,甚至?xí)档头治龅木扰c速度。在特征提取的設(shè)計(jì)中,專家知識至關(guān)重要。經(jīng)驗(yàn)往往是取得成果的捷徑,但是在實(shí)際情況中總會遇到一些陌生的場景,缺少經(jīng)驗(yàn)知識,這時(shí)邏輯和方法論顯得更為普適。
通常采用4類通用的維度來提取用戶行為特征,分別是用戶與用戶之間行為基線的對比、用戶組與用戶組之間行為基線的對比、基于用戶自身行為基線對比的離散數(shù)據(jù)特征提取和基于用戶自身行為基線對比的連續(xù)數(shù)據(jù)特征提取。第1類維度是用戶與用戶之間行為基線的對比。
基于大部分用戶行為是正常的原則,通過用戶與用戶之間的行為基線對比,可以發(fā)現(xiàn)偏離集群基線的少數(shù)用戶。在某一個(gè)特征維度上,這些少數(shù)用戶就是疑似異常的。典型事件為非工作時(shí)間的用戶行為異常。
通常情況下,員工對公司內(nèi)部資源的訪問應(yīng)該在工作時(shí)間,任何非工作時(shí)間的行為都應(yīng)該重點(diǎn)關(guān)注。那么,如何定義非工作時(shí)間呢?不同行業(yè)不同性質(zhì)的企業(yè),工作時(shí)間會有較大差別。國企與民企、傳統(tǒng)產(chǎn)業(yè)與新興產(chǎn)業(yè),工作時(shí)間段上存在比較大的偏差。
此外,同一領(lǐng)域的不同企業(yè)也有各自的加班文化,不能排除很多員工在考勤外時(shí)間通過VPN訪問內(nèi)網(wǎng)是用于正常工作的可能。因此,基于對所有員工的歷史行為記錄,通過核密度估計(jì)(Kernel Density Estimation,KDE)計(jì)算一天24 h每個(gè)時(shí)間點(diǎn)用戶訪問資源的概率密度,將概率低于動態(tài)閾值的時(shí)間點(diǎn)定義為非工作時(shí)間,從而把員工在非工作時(shí)間段產(chǎn)生的行為提取為一個(gè)異常特征。
圖1為某公司的員工賬號24 h在線概率密度分布圖,可得賬號在白天工作時(shí)間在線的概率最大。當(dāng)動態(tài)閾值為0.01時(shí),可以看出該公司的員工在凌晨3點(diǎn)到凌晨6點(diǎn)的在線概率最小。在凌晨0點(diǎn)到凌晨3點(diǎn),該公司還有部分員工在使用VPN加班工作,說明該公司加班嚴(yán)重,加班到凌晨一兩點(diǎn)是常態(tài)。
如果直接定義晚上22點(diǎn)到早上6點(diǎn)為非工作時(shí)間,將導(dǎo)致較多的誤報(bào),而利用該類特征,能夠自適應(yīng)地學(xué)習(xí)該公司真正的非工作時(shí)間。
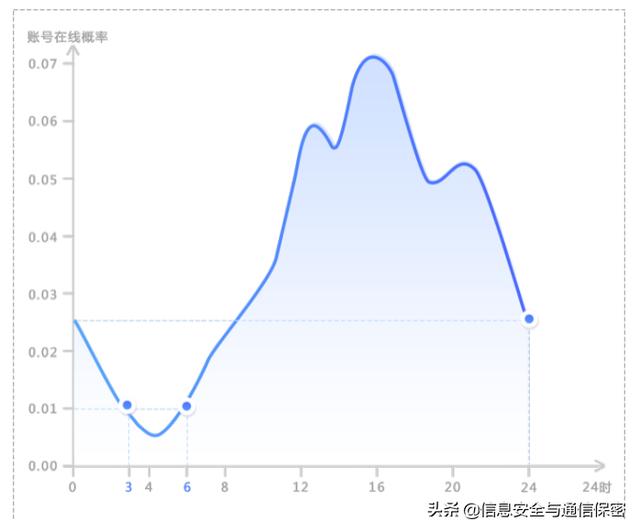
圖1 用戶賬號24小時(shí)在線概率密度分布
第2類維度是用戶組與用戶組之間行為基線的對比。一般而言,在企業(yè)內(nèi)部處于同一個(gè)部門相似崗位的員工應(yīng)該有類似的行為基線,不同部門之間如技術(shù)部門與銷售部門工作上有較大差異,反映在網(wǎng)絡(luò)行為和終端行為上肯定會有較大不同。一個(gè)易于理解的事件是,基于不同角色屬性的員工訪問統(tǒng)一資源定位符(Uniform Resource Locator,URL)記錄的聚類。
顯然,同角色屬性或者同部門的員工應(yīng)該會有更多共同訪問對象和訪問目的。根據(jù)日志信息,建立用戶和一段時(shí)間內(nèi)被訪問較多的或者業(yè)務(wù)相關(guān)的URL的關(guān)聯(lián)矩陣。矩陣元素可以是訪問次數(shù)、訪問時(shí)長或者平均訪問時(shí)長,利用歐式距離計(jì)算客戶之間的距離,并進(jìn)行聚類操作。
對遠(yuǎn)離自身角色所在部門群組的用戶可以標(biāo)記為異常,同時(shí)基于用戶與群組中心的距離給出偏離度,針對異常出現(xiàn)的偏離程度,可提取訪問異常特征。偏離度的計(jì)算公式如下:
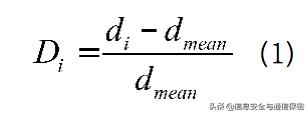
式中,
代表第i個(gè)用戶的偏離度;
代表第i個(gè)用戶與類簇中心距離;
代表同組用戶與類簇中心的平均距離。圖2為技術(shù)部門與銷售部門在訪問次數(shù)、訪問時(shí)長上的聚類圖,圓圈代表技術(shù)部門,三角形代表銷售部門,五角星代表這兩個(gè)組的聚類中心,兩個(gè)類簇中間散落的幾個(gè)用戶可以明顯看出異常。如果不分用戶組,那么圓圈中的三角形將被認(rèn)為是正常用戶;現(xiàn)在區(qū)分用戶組進(jìn)行聚類,則可以明顯看出,這些混雜在圓圈中的三角形離實(shí)際的聚類中心很遠(yuǎn),是異常最大的用戶。
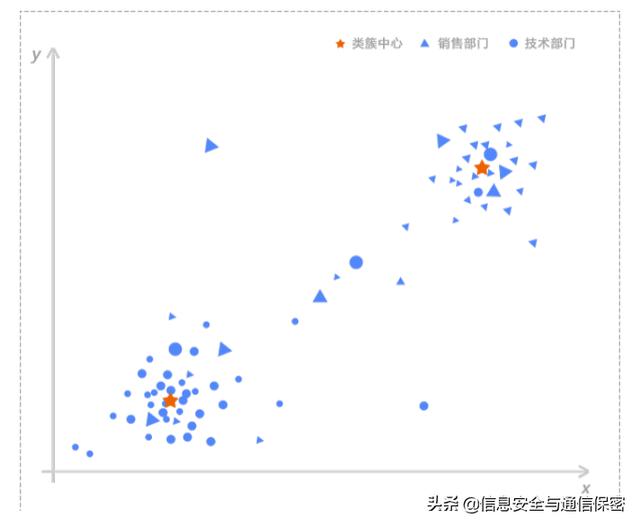
圖2 用戶組聚類結(jié)果
第3類維度是基于用戶自身行為基線對比的離散數(shù)據(jù)特征提取。通過學(xué)習(xí)大量的歷史行為數(shù)據(jù)建立正常的用戶基線后,可以對偏離歷史基線的用戶行為提取異常特征。典型事件是用戶使用新的IP地址。一個(gè)沒有在歷史記錄中出現(xiàn)的IP地址,意味著用戶的活動基線偏離了原有的軌跡,當(dāng)然也可能是諸如用戶出差等客觀原因造成的。
但當(dāng)結(jié)合其他的一些信息如新IP地址伴隨著新的MAC地址,這意味著用戶不僅變更了登錄地址,也變更了登錄設(shè)備,加重了可疑度。如果還有其他的信息輔助,或者用戶的新IP地址不斷出現(xiàn),需要將這類現(xiàn)象歸納為疑似異常。
所以,通過一些場景的設(shè)想,可以基于用戶自身行為基線提取離散數(shù)據(jù)的異常特征。第4類維度是基于用戶自身行為基線對比的連續(xù)數(shù)據(jù)特征提取。通過學(xué)習(xí)用戶的連續(xù)數(shù)據(jù)的行為基線,可以對偏離歷史基線的用戶行為提取異常特征。舉例來說,用戶正常的網(wǎng)絡(luò)行為都應(yīng)該有在一定范圍內(nèi)波動的出入流量,DPI系統(tǒng)可以幫助記錄每次訪問目標(biāo)的流量情況。
用戶的出入流量是連續(xù)變量,應(yīng)該滿足某種分布。假設(shè)用戶的訪問流量持續(xù)大幅遠(yuǎn)離了歷史分布,則有理由懷疑用戶使用習(xí)慣發(fā)生了改變,需要對此加以關(guān)注。通過使用RPCA-SST、ARIMA等算法對這類連續(xù)的時(shí)序數(shù)據(jù)進(jìn)行異常檢測,從而提取出異常特征。
圖3為某用戶在6月份的流量時(shí)序圖,實(shí)線為實(shí)際的流量時(shí)序,陰影為時(shí)序異常檢測算法擬合的正常范圍。超出預(yù)測范圍的點(diǎn)被標(biāo)記為異常,為圖3中的圓點(diǎn)。根據(jù)異常點(diǎn)的個(gè)數(shù)及異常程度,能提取出該用戶的異常特征。
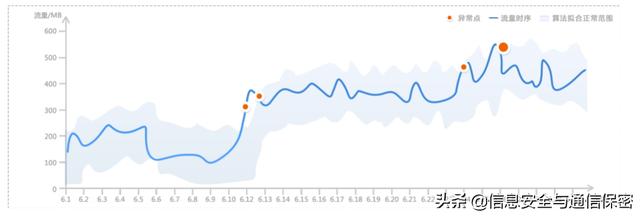
圖3 時(shí)序異常檢測
4 基于Ensemble Learning的異常用戶檢測
用戶異常行為建模的3大要素為用戶、實(shí)體和行為特征。通過訪問關(guān)系的關(guān)聯(lián),將3大要素映射到核心的用戶行為上。經(jīng)過第3章節(jié)介紹的4類維度的分解,提取了幾十種有效的用戶行為特征。獲取特征后,即能使用機(jī)器學(xué)習(xí)算法檢測異常用戶。
由于內(nèi)部攻擊并不經(jīng)常發(fā)生,標(biāo)簽數(shù)據(jù)的稀少性決定了多數(shù)情況下UEBA使用的是無監(jiān)督學(xué)習(xí)算法。從另一個(gè)角度說,不依賴先前的攻擊知識反而允許系統(tǒng)發(fā)現(xiàn)少見的和過往未曾發(fā)現(xiàn)的威脅。異常檢測的主要任務(wù)是在正常的用戶數(shù)據(jù)集中提取出小概率的異常數(shù)據(jù)點(diǎn),這些異常點(diǎn)的產(chǎn)生不是由于隨機(jī)偏差,而是有如故障、威脅、入侵等完全不同的機(jī)制。
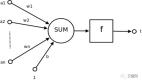
這些異常事件的發(fā)生頻率同大量的正常事件相比僅僅是少數(shù)的一部分。異常檢測算法眾多,它們的期望盡管都是盡可能分離出正常數(shù)據(jù)與異常數(shù)據(jù),但其原理各不相同。針對不同的數(shù)據(jù)源,很難保證哪一類算法能夠取得最優(yōu)的結(jié)果。采用孤立森林、One Class SVM以及局部異常因子3種算法的集成來全面識別和評價(jià)最可能影響系統(tǒng)的各種異常用戶。
利用這3種算法進(jìn)行異常檢測,可以分別得到所有用戶的異常打分。對3種算法結(jié)果進(jìn)行加權(quán)歸一,便可以得到最終的針對所有用戶的異常打分排名。利用這些信息,企業(yè)可以按照一定的邏輯順序,采用適當(dāng)?shù)膶Σ咛幚憩F(xiàn)存的威脅,并按輕重緩急實(shí)施補(bǔ)救措施。
整個(gè)UEBA的核心系統(tǒng)框架如圖4所示。每個(gè)算法都會對用戶i計(jì)算一個(gè)獨(dú)立的異常分值。孤立森林、One Class SVM、局部異常因子3種算法的幾個(gè)分別記為
,其對應(yīng)的權(quán)重分別為
,則最終的異常評分Score為:
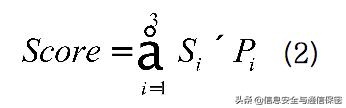
圖4 UEBA核心系統(tǒng)框架
5 實(shí)驗(yàn)結(jié)果分析及案例
表1為排名前20的異常用戶分值及部分特征值,用戶名用Hash做了脫敏處理。對排名靠前的異常用戶一一驗(yàn)證,在排名前10的用戶中,確認(rèn)了包括賬號第三方共享、主機(jī)中毒、惡意掃描、離職員工潛入內(nèi)網(wǎng)以及敏感信息被違規(guī)拉取等問題,賬號風(fēng)險(xiǎn)準(zhǔn)確率達(dá)到90%。表1 排名前20異常用戶分值及部分特征值
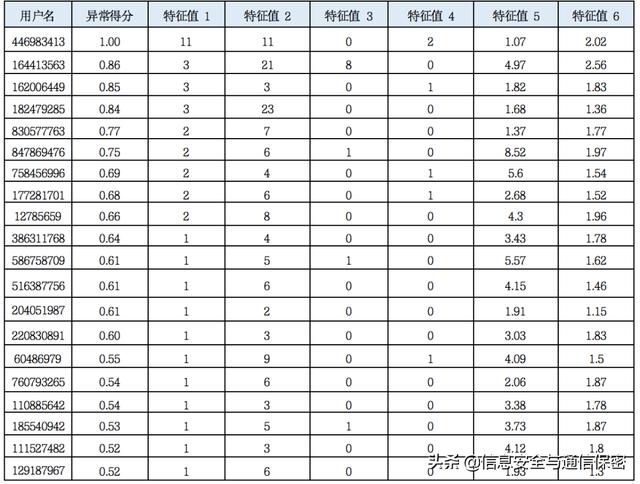
用戶446983413異常排名居首,對其異常特征進(jìn)行排查,發(fā)現(xiàn)存在賬號爆破、異地登錄、端口掃描、從OA系統(tǒng)下載文件以及傳輸流量過大等異常,最終安全運(yùn)維人員確定為因VPN賬號被爆破導(dǎo)致的敏感信息泄露事件。它在時(shí)間軸上的發(fā)生順序如圖5所示。
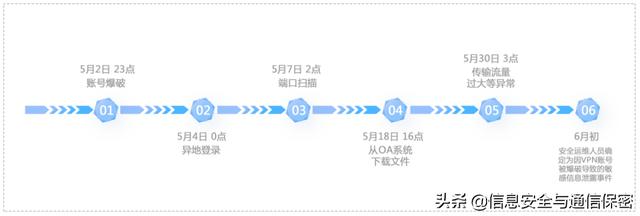
圖5 用戶446983413相關(guān)事件時(shí)間軸
6 結(jié) 語
本文介紹了UEBA即用戶行為實(shí)體分析在企業(yè)異常用戶檢測中的應(yīng)用情況,通過用戶、實(shí)體、行為3要素的關(guān)聯(lián),整合了可以反映用戶行為基線的各類數(shù)據(jù),將用戶的行為特征提取分布到4類維度上展開,有效提取了幾十種最能反映用戶異常的基礎(chǔ)特征。
將3種異常檢測算法通過集成學(xué)習(xí)方法用于異常用戶建模,通過異常打分定位最可能異常的用戶,對排名前10的異常用戶進(jìn)行排查,驗(yàn)證證明存在問題的準(zhǔn)確率達(dá)到90%。企業(yè)最開始部署UEBA系統(tǒng)時(shí),基本不會有用戶賬號的標(biāo)簽。
經(jīng)過一段時(shí)間的使用及排查,會逐步積累用戶賬號的標(biāo)簽,這樣整個(gè)系統(tǒng)的算法漸漸可以從無監(jiān)督過渡到有監(jiān)督,從而可進(jìn)一步提升準(zhǔn)確率。通過這樣的正向循環(huán)反饋強(qiáng)化,最終會筑起堅(jiān)固的安全防線。