













太贊了,大神總結的常見數據分析規范!
在數據分析中,無論數據收集過程有多么科學、數據處理多么先進、分析方法多么高深,如果不能將它們有效地組織和展示出來,并與決策者進行溝通與交流,就無法體現數據和分析的價值。因此,分析報告實質上是一種溝通與交流的形式,主要作用在于展示分析結果、驗證分析質量,為決策者提供參考依據,并可以有針對性、操作性、戰略性的決策。今天,我們來一探究竟常見數據分析及報告規范。
Part1結構規范及寫作
報告常用結構:
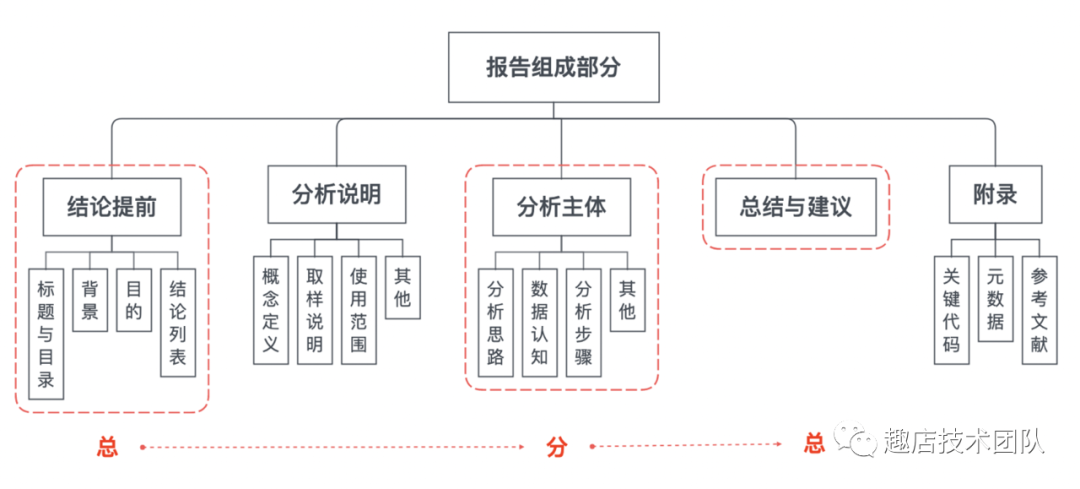
1.1 架構清晰、主次分明
數據分析報告要有一個清晰的架構,層次分明能降低閱讀成本,有助于信息的傳達。雖然不同類型的分析報告有其適用的呈現方式,但總的來說作為議論文的一種,大部分的分析報告還是適用總-分-(總) 的結構。
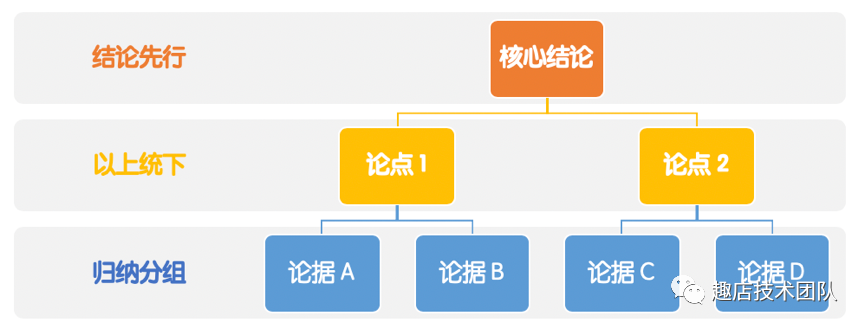
推薦學習金字塔原理,中心思想明確,結論先行,以上統下,歸類分組,邏輯遞進。行文結構先重要后次要,先全局后細節,先結論后原因,先結果后過程。對于不太重要的內容點到即止,舍棄細枝末節與主題不相關的東西。
1.2 核心結論先行、有邏輯有依據
結論求精不求多。大部分情況下,數據分析是為了發現問題,一份分析報告如果能有一個最重要的結論就已經達到目的。精簡的結論能降低閱讀者的閱讀門檻,相反太繁瑣、有問題的結論100個=0。報告要圍繞分析的背景和目的以及要解決的問題,給出明確的答案和清晰的結論;相反,結論或主題太多會讓人不知所云,不知道要表達什么。分析結論一定要基于緊密嚴謹的數據分析推導過程,盡量不要有猜測性的結論,太主觀的結論就會失去說服力,一個連自己都沒有把握的結論千萬不要在報告里誤導別人。但實際中,部分合理的猜測找不到直觀可行的驗證,在給出猜測性結論的時候,一定是基于合理的、有部分驗證依據前提下,謹慎地給出結論,并且說明是猜測。如果在條件允許的前提下可以通過調研/回訪的方式進行論證。不回避 “不良結論” 。在數據準確、推導合理的基礎上,發現產品或業務問題并直擊痛點,這其實是數據分析的一大價值所在。
1.3 結合實際業務、建議合理
基于分析結論,要有針對性的建議或者提出詳細解決方案,那么如何寫建議呢?首先,要搞清給誰提建議。不同的目標對象所處的位置不同,看問題的角度就不一樣,比如高層更關注方向,分析報告需要提供業務的深度洞察和指出潛在機會點,中層及員工關注具體策略,基于分析結論能通過哪些具體措施去改善現狀。 其次,要結合業務實際情況提建議。 雖然建議是以數據分析為基礎提出的,但僅從數據的角度去考慮就容易受到局限、甚至走入脫離業務忽略行業環境的誤區,造成建議提了不如不提的結果。因此提出建議,一定要基于對業務的深刻了解和對實際情況的充分考慮。再進一步,如果可以給出這個建議實施后的收益,下單轉化提升多少、交易提升多少、能節省多少成本等,把價值點直接傳遞給閱讀對象。
上面講了報告的寫作原則,舉個例子,參考艾瑞網,《留存與未來-疫情背后的互聯網發展趨勢報告》
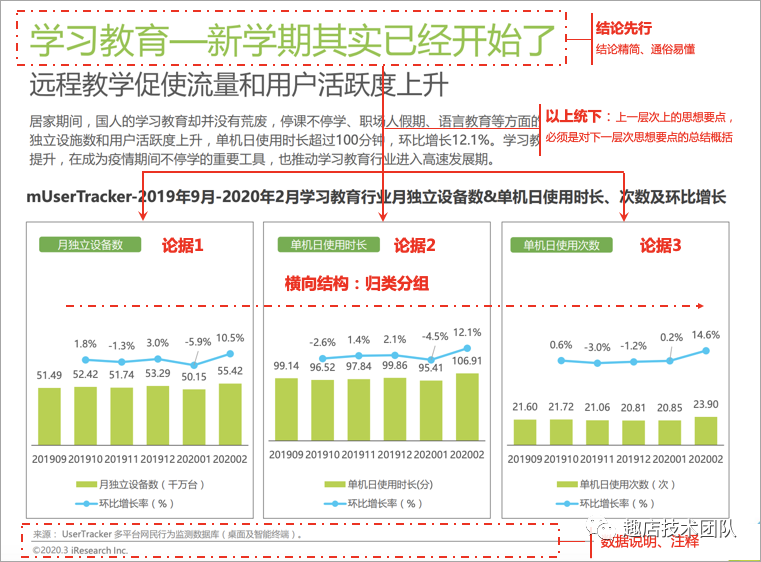
Tips:嘗試站在讀者的角度去寫分析報告,內容通俗易懂,用語規范謹慎。如果匯報對象不是該領域的專家,就要避免使用太多晦澀難懂的詞句,同時報告中使用的名詞術語一定要規范,要與既定的標準(如公司指標規范)以及業內公認的術語一致。
Part2數據使用及圖表
數據分析往往是80%的數據處理,20%的分析。大部分時候,收集和處理數據確實會占據很多時間,最后才在正確數據的基礎上做分析,既然一切都是為了找到正確的結論,那么保證數據準確就顯得格外重要,否則一切努力都是誤導別人。
2.1 分析需要基于可靠的數據源
用于鑒別信息/數據的可靠性,主要有四種方法:同類對比、狹義/廣義比對、相關對比和演繹歸謬。2.1.1 同類對比與口徑相同或相近,但來源不同的信息進行對比。示例:最常見就是把跑出來的數據和報表數據核對校驗。2.1.2 狹義/廣義對比通過與更廣義(被包含)或更狹義(包含)的信息進行對比。示例:3C品類銷售額與商城總銷售額比較,3C的銷售額更高顯然是錯誤的,因為商城總銷售額包含3C銷售額;某些頁面/頻道的UV與APP總UV比較也類似。 2.1.3 相關對比通過與具有相關性、關聯性的信息進行對比。示例:某平臺的Dn留存率,對于同一個基準日期來說,D60留存率一定低于D30留存率的,如果出現大于的情況,那就是錯誤數據了。2.1.4 演繹歸謬通過對現有證據的深入演繹,推導出結果,判斷結果是否合理。示例:比如某平臺的銷售客單價2000左右,總銷售額1億左右;計算得出當日交易用戶數10萬,通過乘以客單價,得到當天銷售額2億,顯然與業務體量不符,為錯誤的數據。
Tips:以上都是常用的方法論,最核心是足夠了解業務,對關鍵指標數據情況了然于心,那么對數據準確性的判斷水到渠成。對此,建議是每日觀測核心業務的數據情況,并分析波動原因,培養業務理解力和數據敏感度。
2.2 盡量圖標化,提高可讀性
用圖表代替大量堆砌的數字,有助于閱讀者更形象直觀地看清楚問題和結論,當然,圖表也不要太多,過多的圖表一樣會讓人無所適從。讓圖表五臟俱全,一張圖必須包含完整的元素,才能讓閱讀者一目了然。標題、圖例、單位、腳注、資料來源這些圖表元素就好比圖表的五臟六腑。 要注意的條條框框。首先,避免生出無意義的圖表。決定做不做圖的唯一標準就是能否幫助你有效地表達信息。第二點、不要把圖表撐破。最好一張圖表反映一個觀點,突出重點,讓讀者迅速捕捉到核心思想。第三點、只選對的,不選復雜的。第四點、一句話標題。
常見的圖表類型選擇:
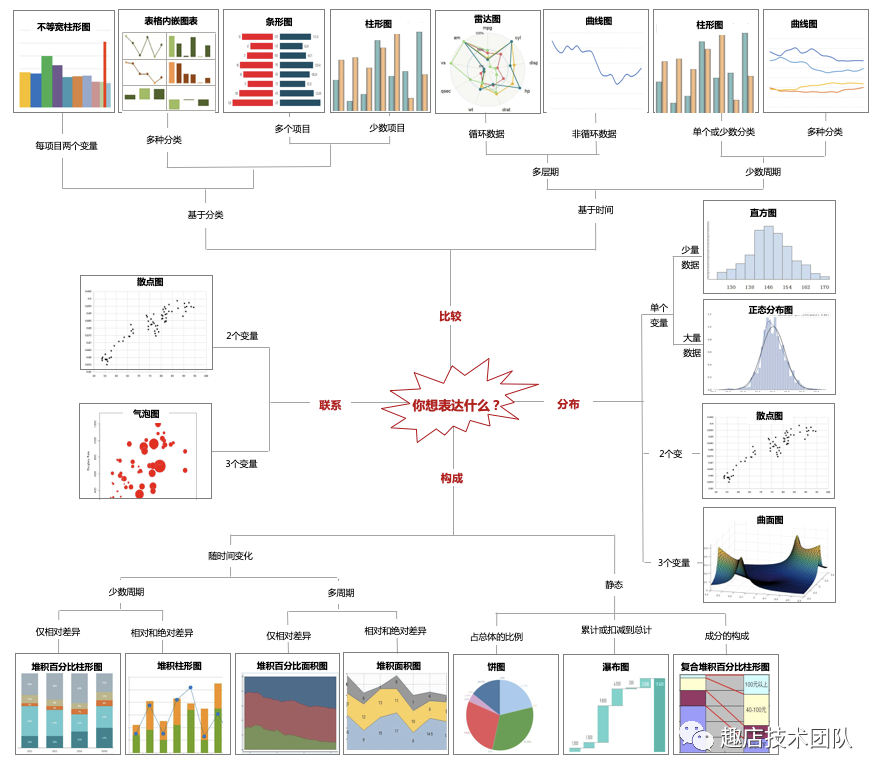
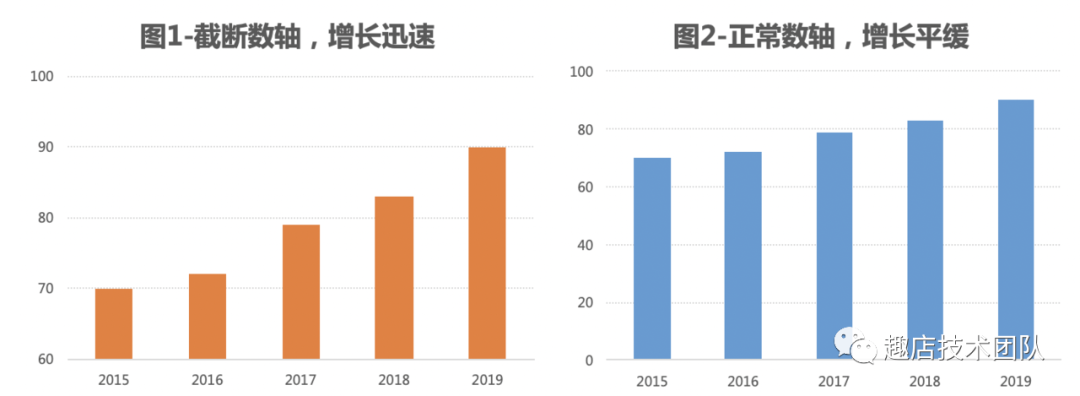
圖表使用Tips:2.2.1 折線圖選用的線型要相對粗些,線條一般不超過5條,不使用傾斜的標簽,縱坐標軸一般刻度從0開始。預測值的線條線型改為虛線。2.2.2 柱形圖同一數據序列使用相同的顏色。不使用傾斜的標簽,縱坐標軸一般刻度從0開始。一般來說,柱形圖最好添加數據標簽,如果添加了數據標簽,可以刪除縱坐標刻度線和網格線。2.2.3 條形圖同一數據序列使用相同的顏色。不使用傾斜的標簽,最好添加數據標簽,盡量讓數據由大到小排列,方便閱讀。2.2.4 餅圖餅圖使用場景相對少,如需使用,注意以下事項:把數據從12點鐘的位置開始排列,最重要的成分緊靠12點鐘的位置。數據項不要太多,保持在6項以內,不使用爆炸式的餅圖分離。不過可以將某一片的扇區分離出來,前提是你希望強調這片扇區。餅圖不使用圖例。不使用3D效果。當扇區使用顏色填充時,推薦使用白色的邊框線,具有較好的切割感。2.2.5 警惕圖表說謊虛張聲勢的增長人們喜歡研究一條線的發展趨勢,例如股市、房價、銷售額的增長趨勢,有時候為了吸引讀者故意夸大變化趨勢,如圖1通過截斷數軸夸大增長速度,從正常數軸的圖2看到增長是緩慢的。
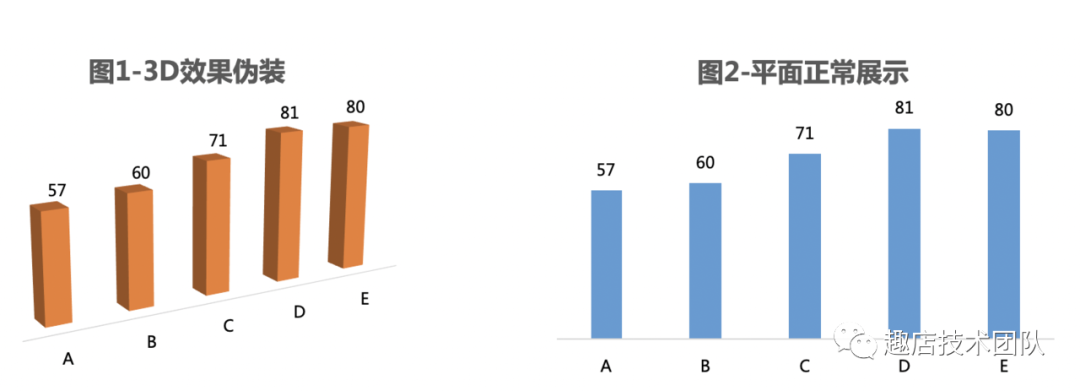
3D效果的偽裝3D圖形容易造成視覺偏差,如圖1有3D效果,看上去 A->B->C->D->E依次遞增,實際是D>E,要格外小心圖表的偽裝。
Part3常見數據分析誤區
“用數據說話”,已經成為一種流行語。在很多人的心里,數據就代表著科學,科學就意味著真相。“數據不會騙人”,也成了說服別人時常用的口頭禪,事實果真如此嗎?讓我們來談談那些常見的誤區。
3.1 控制變量謬誤
在做A/B測試時沒有控制好變量,導致測試結果不能反映實驗結果。或者在進行數據對比時,兩個指標沒有可比性。舉個例子,為測試不同營銷時間點對下的轉化的影響,但A實驗使用短信營銷、B實驗使用電話營銷,未控制變量(營銷方式),導致實驗無法得出結論。
3.2 樣本謬誤
3.2.1 樣本量不夠統計學的基礎理論基石之一就是大數定律,只有當數據量達到一定程度后,才能反映出特定的規律。如果出現樣本量極少的情況,建議把時間線拉長,獲得足量的樣本。或者將不重要的限定條件去掉,增加樣本數。3.2.2 存在選擇性偏見或者幸存者偏見統計學的另一大理論基石是中心極限定理。簡單描述就是,總體樣本中,任意一個群體樣本的平均值,都會圍繞在這個群體的整體平均值周圍。舉個例子,在應用升級期間,衡量登錄用戶數、交易用戶數等指標,來判斷用戶對新版本的喜歡是否優于老版本。聽上去非常合理,但這里實際就隱藏了選擇性偏見,因為新版本發布時,第一批升級上來的用戶往往就是最活躍的用戶,往往這批用戶的指標較好,但不代表新版本更好。3.2.2 混入臟數據這種數據的破壞性比較大,可能得出錯誤的結論。通常我們會采用數據校驗的手段,屏蔽掉校驗失敗的數據。同時,在分析具體業務時,也要針對特定業務,對所使用的數據進行合理性限定,過濾掉異常離群值,來確保擁有比較好的數據質量。
3.3 因果相關謬誤
會誤把相關當因果,忽略中介變量。比如,有人發現雪糕的銷量和河溪溺死的兒童數量呈明顯相關,就下令削減雪糕銷量。其實可能只是因為這兩者都是發生在天氣炎熱的夏天。天氣炎熱,購買雪糕的人就越多,而去河里游泳的人也顯著增多。
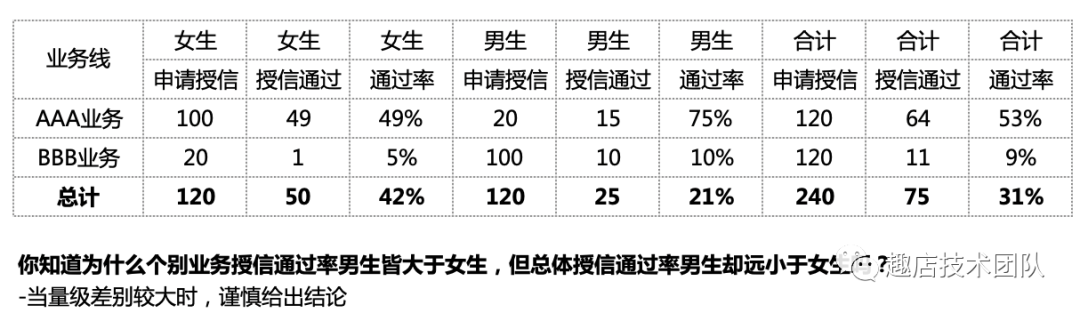
3.4 辛普森悖論
簡單來說,就是在兩個相差較多的分組數據相加時,在分組比較中都占優勢的一方,會在總評中反而是失勢的一方。
3.5 個人認知謬誤
主觀臆斷、經驗當事實、個體當整體、特征當全貌、眼見當事實。舉個主觀臆斷的例子:某個產品A頁面到B頁面的轉化率30%,直接判斷為很低,推導出可以提高到75%。但實際類似產品或者用戶行為決定頁面的轉化率就只有這么高,得出一個錯誤的結論。標準至關重要,數據+標準=判斷。有了判斷才能深入分析。通過分組對比找標準(象限法、多維法、二八法、對比法),有標準通過分析對比,找到“好/壞”的點
統計學規律和理論不會錯,犯錯的是使用它的人。因此,我們在進行數據分析時,一定要格外小心,錯誤的數據,披上科學的外衣,就很難分辨了。



















