













我會手動創建線程,為什么讓我使用線程池?
好看請贊,養成習慣
- 你有一個思想,我有一個思想,我們交換后,一個人就有兩個思想
- If you can NOT explain it simply, you do NOT understand it well enough
上一篇文章 面試問我,創建多少個線程合適?我該怎么說 從定性到定量的分析了如何創建正確個數的線程來最大化利用系統資源(其實就是幾道小學數學題)。通常來講,有了個這個知識點傍身,按需手動創建相應個數的線程就好
但是現實中,你也許聽過或者被要求:
盡量避免手動創建線程,應使用線程池統一管理線程
為什么會有這樣的要求?背后的道理又是怎樣的呢?順著這個經驗理論來推斷,那肯定是手動創建線程有缺點
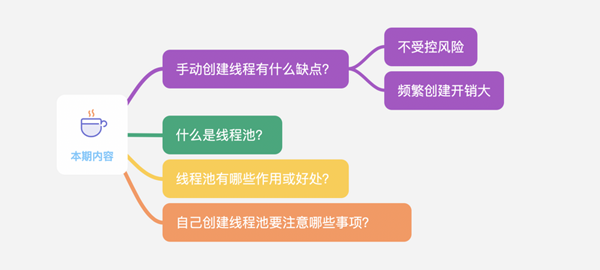
手動創建線程有什么缺點?
- 不受控風險
- 頻繁創建開銷大
不受控風險
這個缺點,相信你也可以說出一二
系統資源有限,每個人針對不同業務都可以手動創建線程,并且創建標準不一樣(比如線程沒有名字)。當系統運行起來,所有線程都在瘋狂搶占資源,無組織無紀律,混亂場面可想而知(出現問題,自然也就不可能輕易的發現和解決)
如果有位神奇的小伙伴,為每個請求都創建一個線程,當大量請求鋪面而來的時候,這好比一個正規木馬程序,內存被無情榨干耗盡(你無情,你冷酷,你無理取鬧)
另外,過多的線程自然也會引起上下文切換的開銷
總的來說,不受控風險很大
頻繁創建開銷大
面試問: 頻繁手動創建線程有什么問題?
答: 開銷大
這貌似是一個不假思索就可以回答出來的正確答案。那我要繼續問了
面試官: 創建一個線程干了什么就開銷大了?和我們創建一個普通 Java 對象有什么差別?
答: ... 嗯...啊
按照常規理解 new Thread() 創建一個線程和 new Object() 沒有什么差別。Java中萬物接對象,因為 Thread 的老祖宗也是 Object
如果你真是這么理解的,說明你對線程的生命周期還不是很理解,請回看之前的 Java線程生命周期這樣理解挺簡單的
在這篇文章中我們明確說明,new Thread() 在操作系統層面并沒有創建新的線程,這是編程語言特有的。真正轉換為操作系統層面創建一個線程,還要調用操作系統內核的API,然后操作系統要為該線程分配一系列的資源
廢話不多說,我們將二者做個對比:

new Object() 過程
- Object obj = new Object();
當我需要【對象】時,我就會給自己 new 一個(不知你是否和我一樣),這個過程你應該很熟悉了:
- 分配一塊內存 M
- 在內存 M 上初始化該對象
- 將內存 M 的地址賦值給引用變量 obj
就是這么簡單
創建一個線程的過程
上面已經提到了,創建一個線程還要調用操作系統內核API。為了更好的理解創建并啟動一個線程的開銷,我們需要看看 JVM 在背后幫我們做了哪些事情:
- 它為一個線程棧分配內存,該棧為每個線程方法調用保存一個棧幀
- 每一棧幀由一個局部變量數組、返回值、操作數堆棧和常量池組成
- 一些支持本機方法的 jvm 也會分配一個本機堆棧
- 每個線程獲得一個程序計數器,告訴它當前處理器執行的指令是什么
- 系統創建一個與Java線程對應的本機線程
- 將與線程相關的描述符添加到JVM內部數據結構中
- 線程共享堆和方法區域
這段描述稍稍有點抽象,用數據來說明創建一個線程(即便不干什么)需要多大空間呢?答案是大約 1M 左右
- java -XX:+UnlockDiagnosticVMOptions -XX:NativeMemoryTracking=summary -XX:+PrintNMTStatistics -version
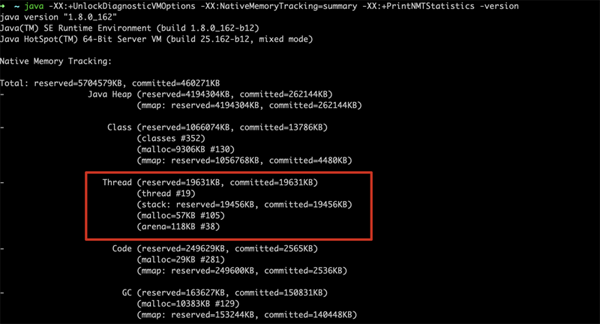
上圖是我用 Java8 的測試結果,19個線程,預留和提交的大概都是19000+KB,平均每個線程大概需要 1M 左右的大小(Java11的結果完全不同,這個大家自行測試吧)
相信到這里你已經明白了,對于性能要求嚴苛的現在,頻繁手動創建/銷毀線程的代價是非常巨大的,解決方案自然也是你知道的線程池了
什么是線程池?
你常見的數據庫連接池,實例池,還有XX池,OO池,各種池,都是一種池化(pooling)思想,簡而言之就是為了最大化收益,并最小化風險,將資源統一在一起管理的思想
Java 也提供了它自己實現的線程池模型—— ThreadPoolExecutor。套用上面池化的想象來說,Java線程池就是為了最大化高并發帶來的性能提升,并最小化手動創建線程的風險,將多個線程統一在一起管理的思想
為了了解這個管理思想,我們當前只需要關注 ThreadPoolExecutor 構造方法就可以了
- public ThreadPoolExecutor(int corePoolSize,
- int maximumPoolSize,
- long keepAliveTime,
- TimeUnit unit,
- BlockingQueue<Runnable> workQueue,
- ThreadFactory threadFactory,
- RejectedExecutionHandler handler) {
- if (corePoolSize < 0 ||
- maximumPoolSize <= 0 ||
- maximumPoolSize < corePoolSize ||
- keepAliveTime < 0)
- throw new IllegalArgumentException();
- if (workQueue == null || threadFactory == null || handler == null)
- throw new NullPointerException();
- this.acc = System.getSecurityManager() == null ?
- null :
- AccessController.getContext();
- this.corePoolSize = corePoolSize;
- this.maximumPoolSize = maximumPoolSize;
- this.workQueue = workQueue;
- this.keepAliveTime = unit.toNanos(keepAliveTime);
- this.threadFactory = threadFactory;
- this.handler = handler;
- }
這么復雜的構造方法在JDK中還真是不多見,為了個更形象化的讓大家理解這幾個核心參數,我們以多數人都經歷過的春運(北京——上海)來說明
| 序號 | 參數名稱 | 參數解釋 | 春運形象說明 |
|---|---|---|---|
| 1 | corePoolSize | 表示常駐核心線程數,如果大于0,即使本地任務執行完也不會被銷毀 | 日常固定的列車數輛(不管是不是春運,都要有固定這些車次運行) |
| 2 | maximumPoolSize | 表示線程池能夠容納可同時執行的最大線程數 | 春運客流量大,臨時加車,加車后,總列車次數不能超過這個最大值,否則就會出現調度不開等問題 (結合workqueue) |
| 3 | keepAliveTime | 表示線程池中線程空閑的時間,當空閑時間達到該值時,線程會被銷毀,只剩下 corePoolSize 個線程位置 |
春運壓力過后,臨時的加車(如果空閑時間超過keepAliveTime)就會被撤掉,只保留日常固定的列車車次數量用于日常運營 |
| 4 | unit | keepAliveTime 的時間單位,最終都會轉換成【納秒】,因為CPU的執行速度杠杠滴 |
keepAliveTime 的單位,春運以【天】為計算單位 |
| 5 | workQueue | 當請求的線程數大于 corePoolSize 時,線程進入該阻塞隊列 |
春運壓力異常大,(達到corePoolSize)也不能滿足要求,所有乘坐請求都會進入該阻塞隊列中排隊, 隊列滿,還有額外請求,就需要加車了 |
| 6 | threadFactory | 顧名思義,線程工廠,用來生產一組相同任務的線程,同時也可以通過它增加前綴名,虛擬機棧分析時更清晰 | 比如(北京——上海)就屬于該段列車所有前綴,表明列車運輸職責 |
| 7 | handler | 執行拒絕策略,當 workQueue 達到上限,同時也達到 maximumPoolSize 就要通過這個來處理,比如拒絕,丟棄等,這是一種限流的保護措施 |
當workQueue排隊也達到隊列最大上線,maximumPoolSize 就要提示無票等拒絕策略了,因為我們不能加車了,當前所有車次已經滿負載 |
整體來看就是這樣:
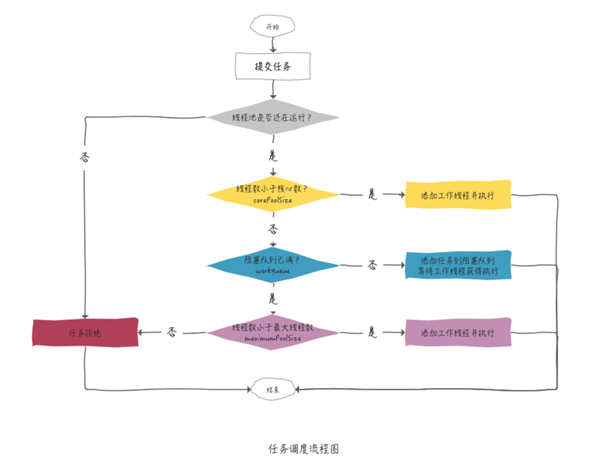
試想,如果有請求就新建一趟列車,請求結束就“銷毀”這趟列車,頻繁往復這樣操作,這樣的代價肯定是不能接受的。
可以看到,使用線程池不但能完成手動創建線程可以做到的工作,同時也填補了手動線程不能做到的空白。歸納起來說,線程池的作用包括:
- 利用線程池管理并服用線程,控制最大并發數(手動創建線程很難得到保證)
- 實現任務線程隊列緩存策略和拒絕機制
- 實現某些與實踐相關的功能,如定時執行,周期執行等(比如列車指定時間運行)
- 隔離線程環境,比如,交易服務和搜索服務在同一臺服務器上,分別開啟兩個線程池,交易線程的資源消耗明顯要大。因此,通過配置獨立的線程池,將較慢的交易服務與搜索服務個離開,避免個服務線程互相影響
相信到這里,你已經了解線程池的基本思想了,在使用過程中還是有幾個注意事項要說明一下的
線程池使用思想/注意事項
不能忽略的線程池拒絕策略
我們很難準確的預測未來的最大并發量,所以定制合理的拒絕策略是必不可少的步驟。默認情況, ThreadPoolExecutor 提供了四種拒絕策略:

- AbortPolicy:默認的拒絕策略,會 throw RejectedExecutionException 拒絕
- CallerRunsPolicy:提交任務的線程自己去執行該任務
- DiscardOldestPolicy:丟棄最老的任務,其實就是把最早進入工作隊列的任務丟棄,然后把新任務加入到工作隊列
- DiscardPolicy:相當大膽的策略,直接丟棄任務,沒有任何異常拋出
不同的框架(Netty,Dubbo)都有不同的拒絕策略,我們也可以通過實現 RejectedExecutionHandler 自定義的拒絕策略
對于采用何種策略,具體要看執行的任務重要程度。如果是一些不重要任務,可以選擇直接丟棄;如果是重要任務,可以采用降級(所謂降級就是在服務無法正常提供功能的情況下,采取的補救措施。具體采用何種降級手段,這也是要看具體場景)處理,例如將任務信息插入數據庫或者消息隊列,啟用一個專門用作補償的線程池去進行補償
沒有絕對的拒絕策略,只有適合那一個,但在設計過程中千萬不要忽略掉拒絕策略就可以
禁止使用Executors創建線程池
相信很多人都看到過這個問題(阿里巴巴Java開發手冊說明禁止使用 Executors 創建線程池),我把出處(P247)截圖在此:

Executors 大大的簡化了我們創建各種類型線程池的方式,為什么還不讓使用呢?
其實,只要你打開看看它的靜態方法參數就會明白了
- public static ExecutorService newFixedThreadPool(int nThreads) {
- return new ThreadPoolExecutor(nThreads, nThreads,
- 0L, TimeUnit.MILLISECONDS,
- new LinkedBlockingQueue<Runnable>());
- }
傳入的workQueue 是一個邊界為 Integer.MAX_VALUE 隊列,我們也可以變相的稱之為無界隊列了,因為邊界太大了,這么大的等待隊列也是非常消耗內存的
- /**
- * Creates a {@code LinkedBlockingQueue} with a capacity of
- * {@link Integer#MAX_VALUE}.
- */
- public LinkedBlockingQueue() {
- this(Integer.MAX_VALUE);
- }
另外該 ThreadPoolExecutor方法使用的是默認拒絕策略(直接拒絕),但并不是所有業務場景都適合使用這個策略,當很重要的請求過來直接選擇拒絕顯然是不合適的
- public ThreadPoolExecutor(int corePoolSize,
- int maximumPoolSize,
- long keepAliveTime,
- TimeUnit unit,
- BlockingQueue<Runnable> workQueue) {
- this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
- Executors.defaultThreadFactory(), defaultHandler);
- }
總的來說,使用 Executors 創建的線程池太過于理想化,并不能滿足很多現實中的業務場景,所以要求我們通過 ThreadPoolExecutor來創建,并傳入合適的參數
總結
當我們需要頻繁的創建線程時,我們要考慮到通過線程池統一管理線程資源,避免不可控風險以及額外的開銷
了解了線程池的幾個核心參數概念后,我們也需要經過調優的過程來設置最佳線程參數值(這個過程時必不可少的)
線程池雖然彌補了手動創建線程的缺陷和空白,同時,合理的降級策略能大大增加系統的穩定性
阿里巴巴手冊都是前輩們無數填坑后總結的精華,你也應該遵守相應的指示,結合自己的實際業務場景,設定合適的參數來創建線程池
























