一篇值得收藏的正則表達式文章
目前越來越多的網站、編輯器、編程語言都已支持一種叫“正則表達式”的字符串查找“公式”,有過編程經驗的同學都應該了解正則表達式(Regular Expression 簡寫regex)是什么東西,它是一種字符串匹配的模式(pattern),更像是一種邏輯公式。
- 使用正則表達式去匹配字符串Hello World 中的 Hello
- 偽代碼:/Hello/, "Hello World"
- 輸出:Hello
如何寫好一篇關于 正則表達式 的文章,我思考了一周的時間,從未有一篇文章能讓豬哥如此費神。
因為我覺得正則表達式 :難記憶、難描述、廣而深且不受重視,有人說正則表達式既好寫也難寫!
- 好寫:無非寫一些常用、實用的案例,說實話你們每個人都能寫出這種:在網上百度一下然后結合一點自己的實際經驗,一篇文章就出來了。
- 難寫:很多人都認為正則簡單,不用記,要用就百度一下。但是絕大多數人了解的只是正則的一個小面,真正的精髓卻很少關注!
豬哥希望大家能知道正則的知識點其實非常非常多,尤其是正則引擎執行原理以及正則優化,這算是正則表達式的進階知識點,面試中也可能會被問到。
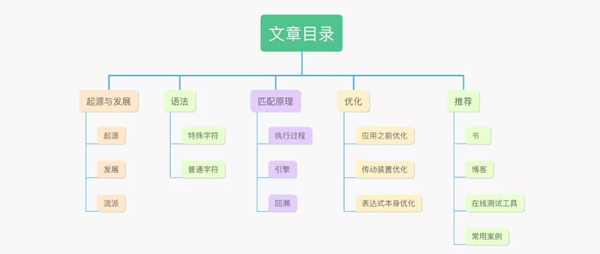
一、起源與發展
我們在學習一門技術的時候有必要了解其起源與發展過程,這對我們去理解技術本身有一定的幫助!
20世紀40年代:正則表達式最初的想法來自兩位神經學家:沃爾特·皮茨與麥卡洛克,他們研究出了一種用數學方式來描述神經網絡的模型。
1956年:一位名叫Stephen Kleene的數學科學家發表了一篇題目是《神經網事件的表示法》的論文,利用稱之為正則集合的數學符號來描述此模型,引入了正則表達式的概念。正則表達式被作為用來描述其稱之為“正則集的代數”的一種表達式,因而采用了“正則表達式”這個術語。
1968年:C語言之父、UNIX之父肯·湯普森把這個“正則表達式”的理論成果用于做一些搜索算法的研究,他描述了一種正則表達式的編譯器,于是出現了應該算是最早的正則表達式的編譯器qed(這也就成為后來的grep編輯器)。
Unix使用正則之后,正則表達式不斷的發展壯大,然后大規模應用于各種領域,根據這些領域各自的條件需要,又發展出了許多版本的正則表達式,出現了許多的分支。我們把這些分支叫做“流派”。
1987年:Perl語言誕生了,它綜合了其他的語言,用正則表達式作為基礎,開創了一個新的流派,Perl流派。之后很多編程語言如:Python、Java、Ruby、.Net、PHP等等在設計正則式支持的時候都參考Perl正則表達式。

到這里我們也就知道為什么眾多編程語言的正則表達式基本一樣,因為他們都師從Perl。
注:Perl語言是一種擅長處理文本的語言,但因晦澀語法和古怪符號不利于理解和記憶導致很多開發者并不喜歡。
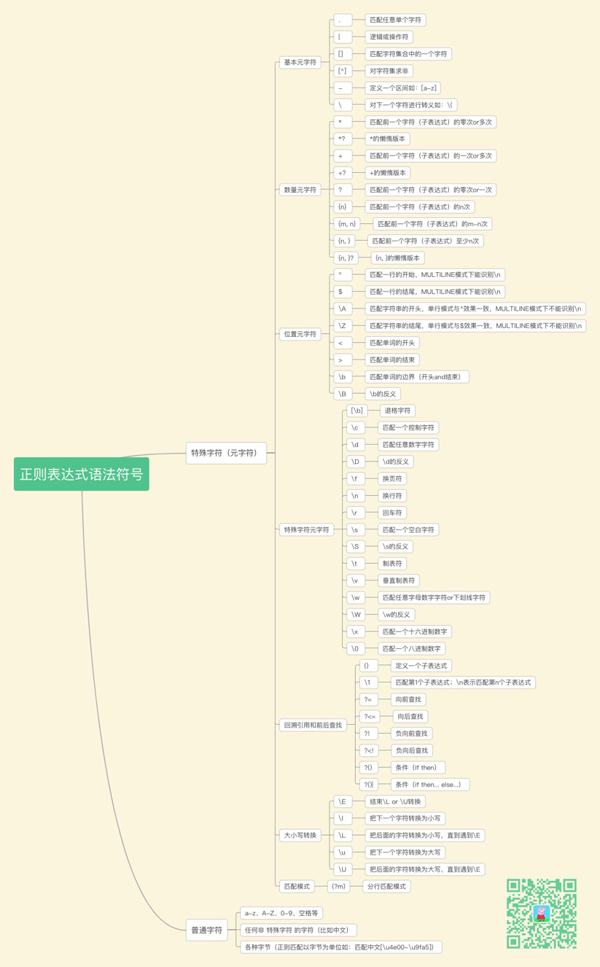
二、語法
完整的正則表達式由兩種字符構成:特殊字符(元字符)和普通字符。
ps:元字符表示正則表達式功能的最小單位,如 * ^ $ \d 等等
關于語法部分豬哥并不想過多的講解,給大家做一個詳細的歸納整理,供大家日后快速查找吧!
如果想系統學習正則表達式的語法部分,豬哥推薦 菜鳥教程: https://www.runoob.com/regexp/regexp-tutorial.html
三、匹配原理
匹配原理是豬哥想要重點講解的部分,也希望同學們可以認真了解這部分的內容。
很多人覺得開車沒必要了解車的構造原理,但是我們學編程的還真的需要了解原理。
因為了解原理,你才能調優,這往往也是初級工程師與中高級工程師之間的差別點之一!
1.執行過程
正則表達式的執行,是由正則表達引擎編譯執行的,大致的執行流程豬哥也畫了個流程圖給大家看看。
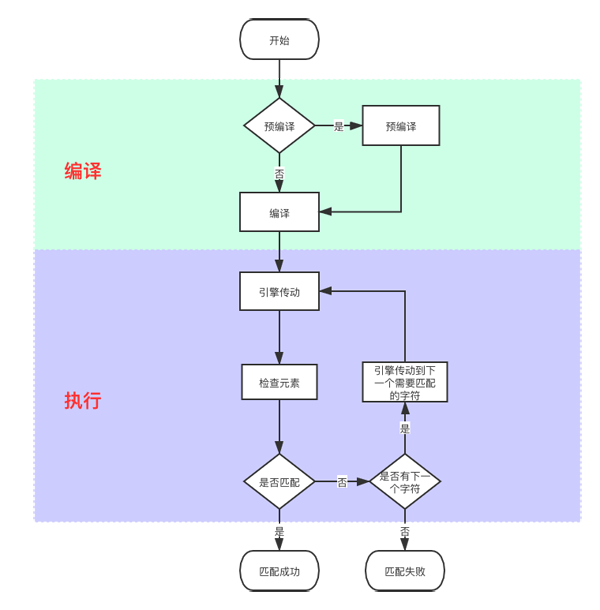
這里給大家提一點就是:預編譯(pre-use compile)
豬哥建議大家在生產環境中使用預編譯功能,為什么呢?
以Python語言內置re模塊舉例:
- 通過re.compile(pattern)預編譯返回Pattern對象,在后面代碼中可以直接引用。
- 通過re.match(pattern, text)即用編譯,雖然也會有緩存Pattern對象,但是每次使用都需要去緩存中取出,比預編譯多一步取操作。
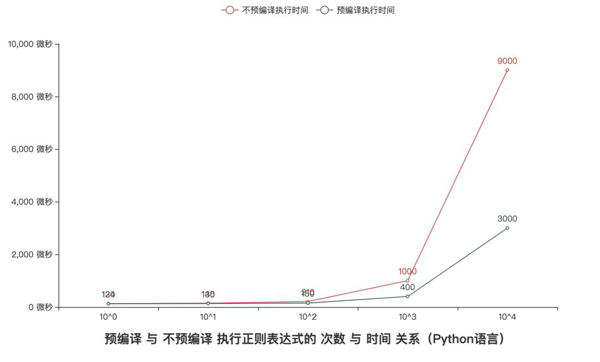
豬哥也通過實際測試來 驗證預編譯 確實比 即用編譯 要快!
- pattern = r'http:\/\/(?:.?\w+)+'
- text = '<a href="http://www.xxx.com">xxx.com</a>'
2.引擎(重點)
既然正則表達式由執行引擎執行,那我們就來講講正則表達式的引擎吧,這一塊是重點,希望大家仔細看看,弄懂了理解了才行!
正則引擎主要可以分為基本不同的兩大類:
- DFA (Deterministic finite automaton) 確定型有窮自動機
- NFA (Non-deterministic finite automaton) 非確定型有窮自動機
ps:當然還有一種引擎為:POSIX NFA,這是根據NFA引擎出的規范版本,但因為使用較少所以我們這里也就不重點講解。
這里需要和大家解釋下何為確定型、有窮、自動機這幾個名詞:
- 確定型與非確定型:假設有一個字符串(text=abc)需要匹配,在沒有編寫正則表達式的前提下,就直接可以確定字符匹配順序的就是確定型,不能確定字符匹配順序的則為非確定型。
- 有窮:有窮即表示有限的意思,這里表示有限次數內能得到結果。
- 自動機:自動機便是自動完成,在我們設置好匹配規則后由引擎自動完成,不需要人為干預!
根據上面的解釋我們可得知DFA引擎 和 NFA引擎 的一個很大區別就是:在沒有編寫正則表達式的前提下,是否能確定字符執行順序!
DFA引擎執行原理:
為了大家能很清楚的理解DFA引擎執行原理,豬哥制作了一個簡易的動態執行過程圖給大家看看

根據上面的動圖我們可以得出DFA引擎的一些特點:
- 文本主導:按照文本的順序執行,這也就能說明為什么DFA引擎是確定型(deterministic)了,穩定!
- 記錄當前有效的所有可能:我們看到當執行到(d|b)時,同時比較表達式中的d和b,所以會需要更多的內存。
- 每個字符只檢查一次:這提高了執行效率,而且速度與正則表達式無關。
- 不能使用反向引用等功能:因為每個字符只檢查一次,文本零寬度(位置)只記錄當前比較值,所以不能使用反向引用、環視等一些功能!
NFA引擎執行原理:
豬哥同樣畫了一個簡易的NFA引擎執行過程圖方便大家理解

根據上面的動圖我們可以得出NFA引擎的一些特點:
- 文表達式主導:按照表達式的一部分執行,如果不匹配換其他部分繼續匹配,直到表達式匹配完成。
- 會記錄某個位置:我們看到當執行到(d|b)時,NFA引擎會記錄字符的位置(零寬度),然后選擇其中一個先匹配。
- 單個字符可能檢查多次:我們看到當執行到(d|b)時,比較d后發現不匹配,于是NFA引擎換表達式的另一個分支b,同時文本位置回退,重新匹配字符'b'。這也是NFA引擎是非確定型的原因,同時帶來另一個問題效率可能沒有DFA引擎高。
4. 可實現反向引用等功能:因為具有回退這一步,所以可以很容易的實現反向引用、環視等一些功能!
兩種引擎比較
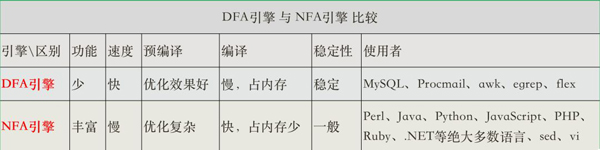
關于這兩種引擎的總結,豬哥引用《精通正則表達式》書本中的一句話來概括:
DFA(電動機) 和NFA(汽油機) 都有很長的歷史,不過,正如汽油機一樣,NFA 的歷史更長一些。也有些系統采用了混合引擎,它們會根據任務的不同選擇合適的引擎(甚至對同一表達式中的不同部分采用不同的引擎,以求得功能與速度之間的最佳平衡)。 ——《精通正則表達式》
3.回溯(重點)
作為絕大多數編程語言都選擇的引擎——NFA (非確定型有窮自動機) 引擎,我們當然要再詳細了解一下它的精髓——回溯。

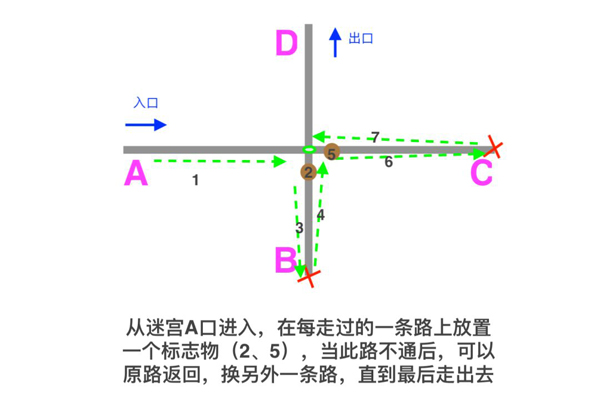
動圖中,我們可以看到當某個正則分支匹配不成功之后,文本的位置需要回退,然后換另一個分支匹配,而回退這步專業術語就叫:回溯。
回溯的原理類似我們走迷宮時走過的路設置一個標志物,如果不對則原路返回,換另一條路。
回溯機制不但需要重新計算正則表達式和文本的對應位置,也需要維護括號內的子表達式所匹配文本的狀態(b匹配成功),保存到內存中以數字編號的組中,這就叫捕獲組。
保存括號內的匹配結果之后,我們在后面的正則表達式中就可以使用,這就是我們所說的反向引用,在上面的案例中只有一個捕獲,所以$1=b。
回溯陷阱:講到回溯必須提到回溯陷阱,它導致的結果就是機器CPU使用率爆滿(超100%),機器就卡死了。
舉個例子:text=aaaaa,pattern=/^(a*)b$/,匹配過程大致是
- (a*):匹配到了文本中的aaaaa
- 匹配正則中的b,但是失敗,因為(a*)已經把text都吃了
- 這時候引擎會要求(a*)吐出最后一個字符(a),但是無法匹配b
- 第二次是吐出倒數第二個字符(還是a),依然無法匹配
- 就這樣引擎會要求(a*)逐個將吃進去的字符都吐出來
- 但是到最后都無法匹配b
這里的重點就在于 引擎會要求*匹配的東西一點一點吐回,我們假設如果文本長度為幾萬,那引擎就要回溯幾萬次,這對機器的CPU來說簡直是災難。
有些復雜的正則表達式可能有多個部分都要回溯,那回溯次數就是指數型。如果文本長度為500,一個表達式有兩部分都要回溯,那次數可能是500^2=25萬次,這誰受得了!
關于更多更詳細的回溯介紹,推薦大家可以閱讀《精通正則表達式》這本書!
四、優化
編寫巧妙的正則表達式不僅僅是一種技能,而且還是一種藝術。
上面我們了解到,絕大多數的編程語言都采用的是NFA引擎,而NFA引擎的特點是:功能強大、但有回溯機制所以效率慢。所以我們需要學習一些NFA引擎的一些優化技巧,以減少引擎回溯次數以及更直接的匹配到結果!
針對NFA引擎的可優化的點其實挺多的,為了方便大家記憶,豬哥也畫幅結構圖歸納一下,方便大家收藏細看。
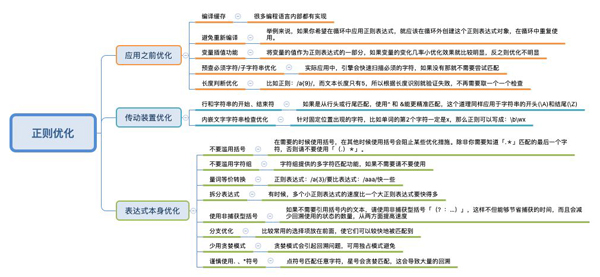
在面試過程中也許會被問到關于正則的優化,大家記住幾點就可以。
五、推薦
上面我們講解了關于正則表達式的誕生和發展、引擎、優化等知識,但是關于正則表達式的知識點遠遠不止這些,所以最后豬哥推薦一些好的學習資料,大家有空可以了解學習下。
1.書
推薦正則表達式的書,那必然是《精通正則表達式》 ,目前這本書已經出了第三版,豆瓣評分8.9。
內容雖然稍有啰嗦,但是對于正則新手很友好,唯一不足是Python案例少。

2.博客
入門:菜鳥教程:https://www.runoob.com/regexp/regexp-tutorial.html
深入:某不知名大佬:https://blog.csdn.net/lxcnn
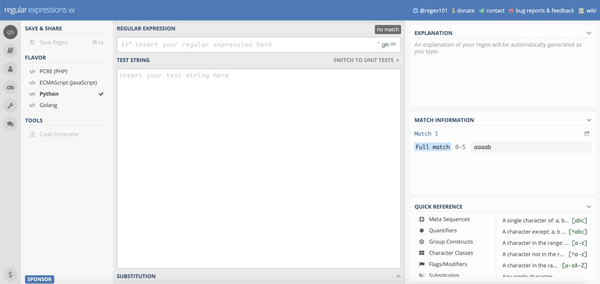
3.在線測試工具
https://regex101.com/,這個網站可以選擇不同編程語言的正則支持,有語義分析、匹配測試、參考列表等,非常實用。
4.常用案例
一些簡單常用的小案例匯總,菜鳥教程:http://c.runoob.com/front-end/854

最后祝愿大家都能搞定正則表達式,處理文本可以得心應手!