













一場HBase2.x的寫入性能優(yōu)化之旅
HBase2.x的寫入性能到底怎么樣?來,不服跑個分!
首先,簡單介紹一下我們的測試環(huán)境:集群由5個節(jié)點組成,每個節(jié)點有12塊800GB的SSD盤、24核CPU、128GB內(nèi)存;集群采用HBase和HDFS混布方式,也就是同一個節(jié)點既部署RegionServer進程,又部署DataNode進程,這樣其實可以保證更好的寫入性能,畢竟至少寫一副本在本地。關(guān)于軟件版本,我們使用的HBase2.1.2版本以及HDFS 2.6.0版本,Java使用OpenJDK1.8.0_202。
對每一個RegionServer進程,我們正常的線上配置是50GB堆內(nèi)內(nèi)存和50GB堆外內(nèi)存(RS合計占用100GB內(nèi)存),其中堆內(nèi)內(nèi)存主要用于Memstore(~36GB),堆外內(nèi)存主要用于BucketCache(~36GB)。這里,我們?yōu)榱吮WC盡量跟線上配置一樣,雖然現(xiàn)在是100%寫入的測試場景,我們還是保留了50GB的堆外內(nèi)存給BucketCache。
在搭建好集群后,我們提前用YCSB壓入了100億行數(shù)據(jù),每行數(shù)據(jù)占用100字節(jié)。注意,壓入數(shù)據(jù)時,采用BufferMutator的方式批量寫入,單機吞吐可以達到令人恐怖的20萬QPS,所以這個過程是非常快的。
正常寫入性能結(jié)果
接著我們開始測試正常的單行Put(設置autoflush=true)延遲了。我們在100億行數(shù)據(jù)集規(guī)模的基礎(chǔ)上,用YCSB持續(xù)寫入數(shù)據(jù)到HBase集群,將YCSB的性能數(shù)據(jù)制作成如下監(jiān)控圖:
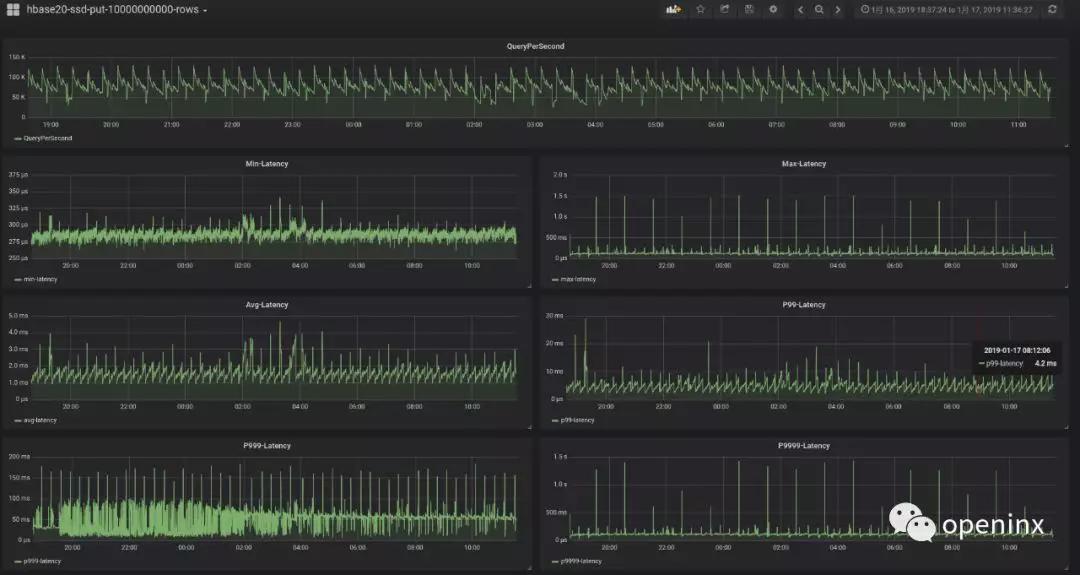
首先,我們可以看到5個節(jié)點的總QPS在10w/s左右,單機QPS在2w+/s左右,avgLatency<4ms,P99-Latency<20ms。從基本面上看,這個數(shù)據(jù)還是很不錯的。 但是,圖中我們也能發(fā)現(xiàn)一些非常明顯的問題:
1.QPS曲線呈現(xiàn)出明顯的高峰和低谷,而且高峰和低谷是周期性出現(xiàn)的,大概15min出現(xiàn)一次高峰,對應的平均延遲(avg-Latency)也出現(xiàn)相應的周期性。這種不穩(wěn)定的吞吐和延遲表現(xiàn),對業(yè)務是非常不友好的,因為在低谷時期業(yè)務的QPS將受到極大的限制。
2.有時會出現(xiàn)大量P999為150ms的請求,P999曲線毛刺非常突出,而且毛刺點比平均的P999延遲要高100ms,這是一個非常令人困惑的數(shù)據(jù)。
3.P9999延遲出現(xiàn)部分超過1s的毛刺點。
優(yōu)化毛刺
我們來分析上述幾個問題的原因。首先,我們找了幾個QPS低谷的時間點,去RegionServer的日志中看了下,確認低谷時間點基本上是 Memstore做Flush的時間點 。另外,確認P999毛刺時間點也是Flush的時間點。由此,推斷出可能的幾個原因有:
1.在測試集群中,每個節(jié)點的Region數(shù)以及各Region數(shù)據(jù)寫入量都非常均衡。這樣可能造成的一個問題就是,某一個時間點所有的Region幾乎同時進入Flush狀態(tài),造成短期內(nèi)磁盤有巨大的寫入壓力,最終吞吐下降,延遲上升。
2.MemStore Flush的過程,分成兩步:第一步加寫鎖,將Memstore切換成snapshot狀態(tài),釋放寫鎖;第二步,將snapshot數(shù)據(jù)異步的刷新成HFile文件。其中第一步持有寫鎖的過程中,是會阻塞當前寫入的,第二步已經(jīng)釋放了寫鎖,所以刷新相當于是異步的,不會阻塞當前的寫入請求。如果在第一步持有寫鎖過程中,有任何耗時操作,都會造成延遲飆升。
第一個問題在真實的線上集群其實不太可能發(fā)生,因為線上不可能做到絕對均衡,F(xiàn)lush必然是錯峰出現(xiàn)。另外,即使絕對均衡,也可以采用限流的方式來控制Flush的寫入速率,進而控制延遲。這個問題我們暫時可以放一放。
第二個問題,我們嘗試加了點日志,打印出每次Flush時RegionServer持有寫鎖的時長。發(fā)現(xiàn)一些如下日志: “–> Memstore snapshotting cost: 146ms”
這說明在Memstore snapshot過程中,確實有一些長耗時的操作。在進一步核對代碼之后,我們發(fā)現(xiàn)一個如下存在問題的棧:

換句話說,在Memstore Snapshot中調(diào)用了一次ConcurrentSkipListMap#size()接口,而這個接口的時間復雜度是O(N)的。也就是說,如果有256MB的Memstore,那么這個size()接口會逐個掃描Memstore中的KV,最終統(tǒng)計得出Map中元素個數(shù)。ConcurrentSkipListMap為什么要這么實現(xiàn)呢?因為ConcurrentSkipListMap為了保證更好的寫入并發(fā)性,不會在更新刪除Map時維護一個線程安全的size變量,所以只能實時的統(tǒng)計Map元素個數(shù)。
這是一個潛藏在HBase代碼倉庫中很長時間的一個bug,從0.98一直到現(xiàn)在的2.0,甚至3.0,都沒有用戶發(fā)現(xiàn)這個bug。更多詳情可以參考HBASE-21738。
其實,找到了問題之后,修改起來也就很簡單,只需要把這個耗時的size()操作去掉,或者用其他的方式來替換即可。 我們已經(jīng)在各分支最新版本中修復了這個bug,建議對性能有更高追求的用戶升級。當然,對此我們也做了進一步的性能測試:
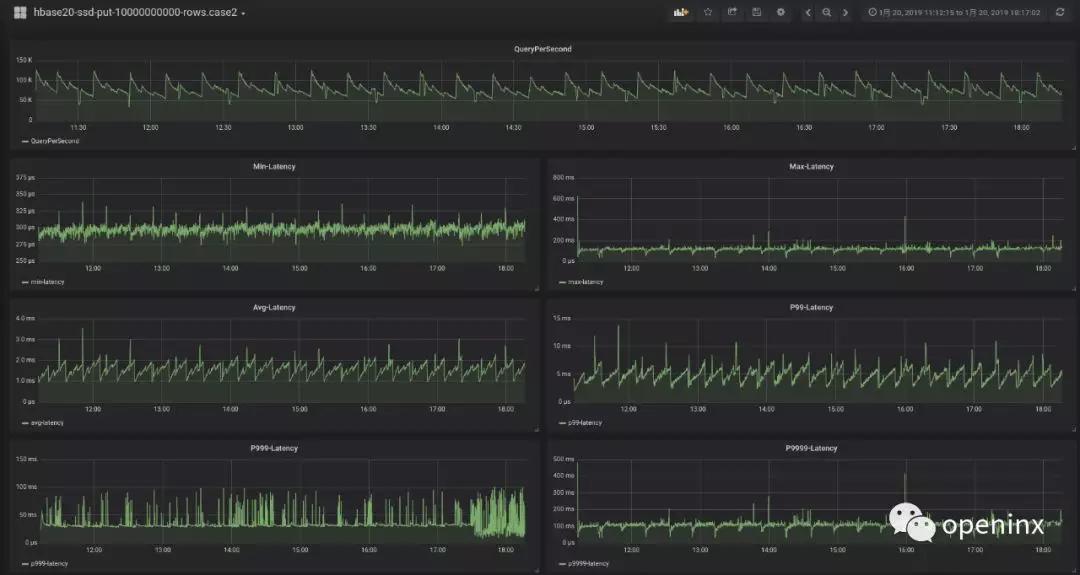
從圖中看出,至少我們把P999的延遲控制在了100ms以內(nèi),另外,我們也可以很容易發(fā)現(xiàn)P9999的毛刺也從之前的1000ms下降到200ms~500ms左右。這說明,上述fix對解決毛刺問題還是很有效果的。
采用In-Memory Compaction進一步優(yōu)化毛刺
但事實上,就目前的情況來說,我們?nèi)匀挥X得P999~100ms不夠好,其實大部分的P999是小于40ms的,但由于毛刺的問題,還是把P999拉到了100ms。進一步分析日志之后,我們發(fā)現(xiàn)此時G1 GC的STW是影響P999最大的因素,因為毛刺點都是GC STW的時間點,而且STW的耗時正好是100ms左右。
于是,我們考慮采用社區(qū)HBase 2.0引入的In-memory compaction功能來優(yōu)化集群的寫性能。這個功能的本質(zhì)優(yōu)勢在于,把256MB的Memstore劃分成多個2MB大小的小有序集合,這些集合中有一個是Mutable的集合,其他的都是Immutable的集合。每次寫入都先寫Mutable的集合,等Mutable集合占用字節(jié)超過2MB之后,就把它切換成Immutable的集合,再新開一個Mutable集合供寫入。Immutable的集合由于其不可變性,可以直接用有序數(shù)組替換掉ConcurrentSkipListMap,節(jié)省大量heap消耗,進一步控制GC延遲。甚至更進一步,我們可以把MSLAB的內(nèi)存池分配到offheap內(nèi)。從此,整個Memstore幾乎沒有堆內(nèi)的內(nèi)存占用。理論上,這個feature的性能表現(xiàn)將非常強勁,我們做個測試來驗證一下。
測試環(huán)境跟之前一樣,不同的是我們會將Memstore配置為CompactingMemstore。注意,目前我們的MSLAB仍然是放在heap上的(若想把MSLAB為offheap,需要設置hbase.regionserver.offheap.global.memstore.size=36864,相當于把36GB的堆外內(nèi)存給MSLAB)。
RegionServer的核心配置如下:
- hbase.hregion.memstore.block.multiplier=5
- hbase.hregion.memstore.flush.size=268435456
- hbase.regionserver.global.memstore.size=0.4
- hbase.regionserver.global.memstore.size.lower.limit=0.625
- hbase.hregion.compacting.memstore.type=BASIC
最終,我們得到的In-memory compaction測試結(jié)果如下:
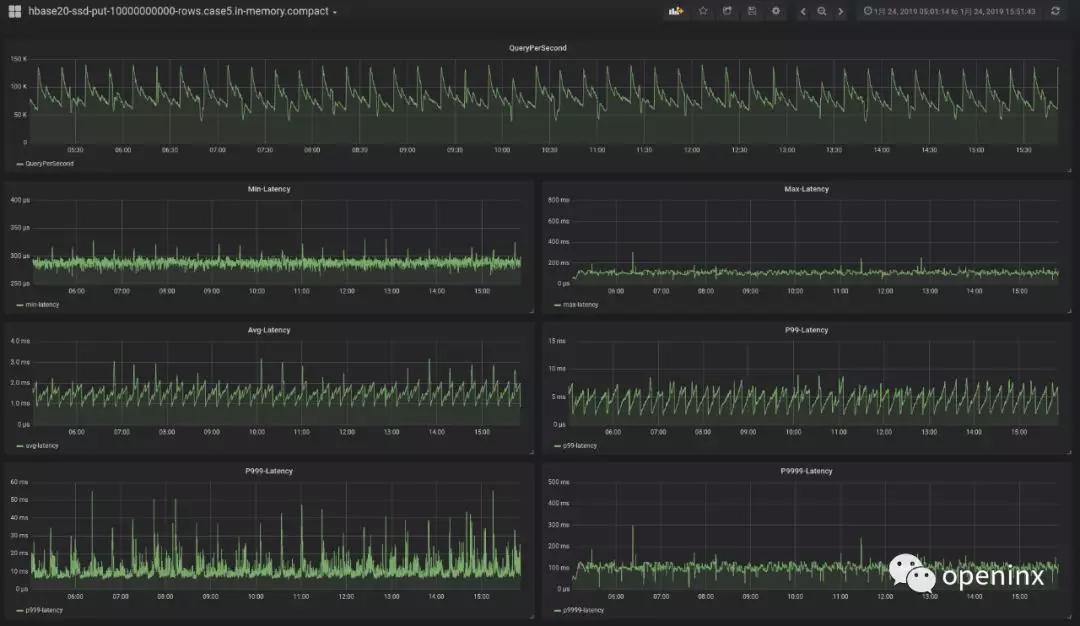
從圖中可以非常明顯的看出,P999延遲控制在令人驚訝的50ms以內(nèi),同時P9999控制在100ms左右,遠低于之前的200ms~500ms。與此同時,吞吐跟平均延遲幾乎沒有任何損耗。如果使用堆外的CompactingMemstore,理論上毛刺會控制的更加嚴格,但有可能稍微拉升平均延遲。這里我沒有再提供進一步的詳細測試結(jié)果,感興趣的朋友可以嘗試一下。
總結(jié)
社區(qū)HBase2.1.2版本的寫入延遲和吞吐表現(xiàn)都非常出色,但是某些場景下容易出現(xiàn)較高的毛刺。經(jīng)過HBASE-21738優(yōu)化之后,我們已經(jīng)能很好地把P999延遲控制在100ms左右。這中間大部分時間點的P999<40ms,少數(shù)時間點因為GC STW拉高了P999的表現(xiàn)。接著,我們采用堆內(nèi)的In-Memory Compaction優(yōu)化之后,P999已經(jīng)能控制在滿意的50ms以內(nèi),甚至P9999可以控制在100ms以內(nèi)。從這些點上來說,HBase2.1.3和HBase2.2.0版本已經(jīng)是性能非常強悍的版本。

















