2020年深度學習優秀GPU一覽,看看哪一款最適合你!
作者:大數據文摘
如果你準備進入深度學習,什么樣的GPU才是最合適的呢?下面列出了一些適合進行深度學習模型訓練的GPU,并將它們進行了橫向比較,一起來看看吧!

大數據文摘出品
來源:lambdalabs
編譯:張秋玥
深度學習模型越來越強大的同時,也占用了更多的內存空間,但是許多GPU卻并沒有足夠的VRAM來訓練它們。
那么如果你準備進入深度學習,什么樣的GPU才是最合適的呢?下面列出了一些適合進行深度學習模型訓練的GPU,并將它們進行了橫向比較,一起來看看吧!
太長不看版
截至2020年2月,以下GPU可以訓練所有當今語言和圖像模型:
- RTX 8000:48GB VRAM,約5500美元
- RTX 6000:24GB VRAM,約4000美元
- Titan RTX:24GB VRAM,約2500美元
以下GPU可以訓練大多數(但不是全部)模型:
- RTX 2080 Ti:11GB VRAM,約1150美元
- GTX 1080 Ti:11GB VRAM,返廠翻新機約800美元
- RTX 2080:8GB VRAM,約720美元
- RTX 2070:8GB VRAM,約500美元
以下GPU不適合用于訓練現在模型:
- RTX 2060:6GB VRAM,約359美元。
在這個GPU上進行訓練需要相對較小的batch size,模型的分布近似會受到影響,從而模型精度可能會較低。
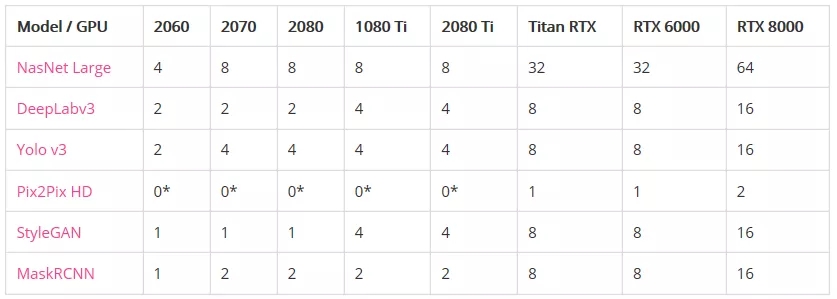
圖像模型
內存不足之前的最大批處理大小:
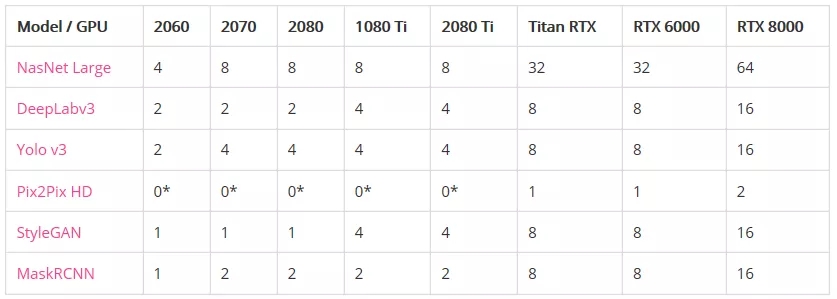
*表示GPU沒有足夠的內存來運行模型。
性能(以每秒處理的圖像為單位):
*表示GPU沒有足夠的內存來運行模型。
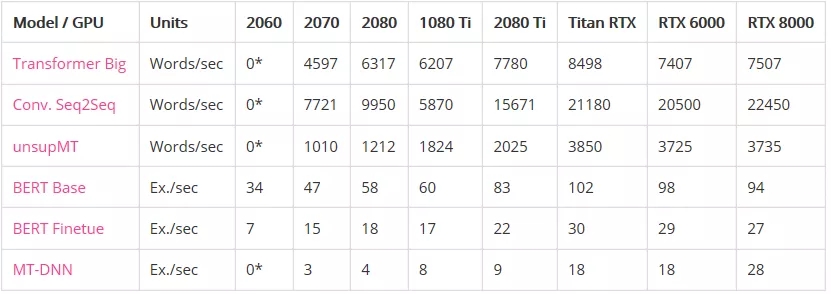
語言模型
內存不足之前的最大批處理大小:

*表示GPU沒有足夠的內存來運行模型。
性能:
* GPU沒有足夠的內存來運行模型。
使用Quadro RTX 8000結果進行標準化后的表現
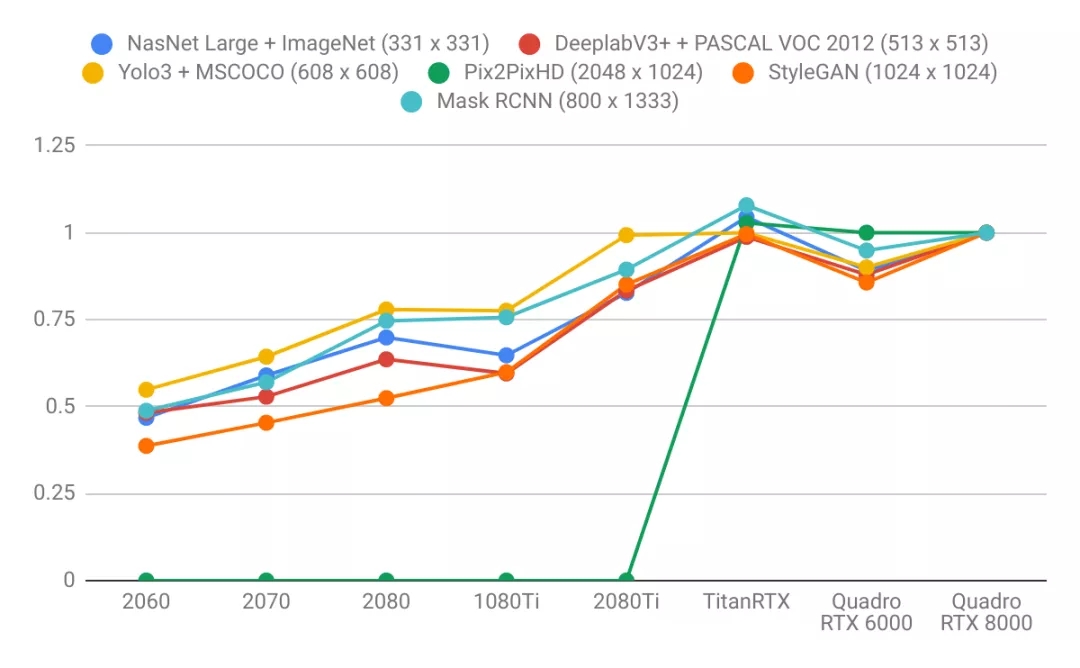
圖像模型:
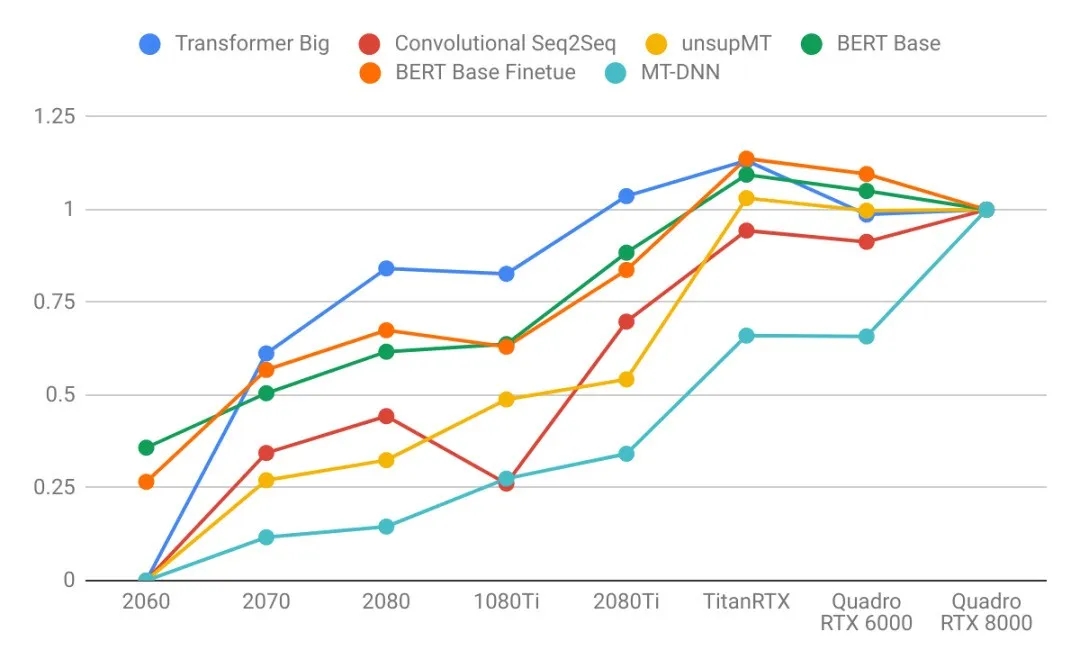
語言模型
結論
- 語言模型比圖像模型受益于更大的GPU內存。注意右圖的曲線比左圖更陡。這表明語言模型受內存大小限制更大,而圖像模型受計算力限制更大。
- 具有較大VRAM的GPU具有更好的性能,因為使用較大的批處理大小有助于使CUDA內核飽和。
- 具有更高VRAM的GPU可按比例實現更大的批處理大小。只懂小學數學的人都知道這很合理:擁有24 GB VRAM的GPU可以比具有8 GB VRAM的GPU容納3倍大的批次。
- 比起其他模型來說,長序列語言模型不成比例地占用大量的內存,因為注意力(attention)是序列長度的二次項。
GPU購買建議
- RTX 2060(6 GB):你想在業余時間探索深度學習。
- RTX 2070或2080(8 GB):你在認真研究深度學習,但GPU預算只有600-800美元。8 GB的VRAM適用于大多數模型。
- RTX 2080 Ti(11 GB):你在認真研究深度學習并且您的GPU預算約為1,200美元。RTX 2080 Ti比RTX 2080快大約40%。
- Titan RTX和Quadro RTX 6000(24 GB):你正在廣泛使用現代模型,但卻沒有足夠買下RTX 8000的預算。
- Quadro RTX 8000(48 GB):你要么是想投資未來,要么是在研究2020年最新最酷炫的模型。
附注
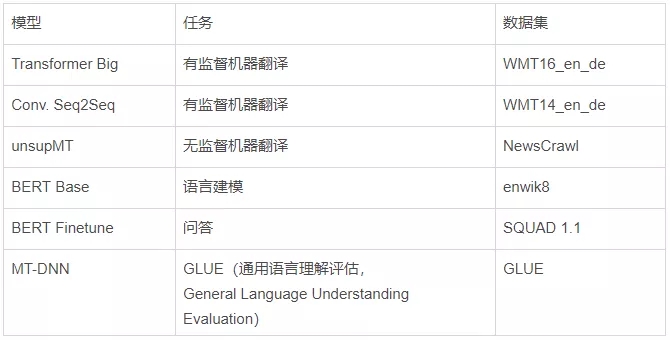
圖像模型:

語言模型:
相關報道:https://lambdalabs.com/blog/choosing-a-gpu-for-deep-learning/
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】

責任編輯:趙寧寧
來源:
51CTO專欄