扛住100億次紅包請求的架構是這樣設計的!
偶然看到了《扛住 100 億次請求——如何做一個“有把握”的春晚紅包系統(tǒng)》一文,看完以后,感慨良多,收益很多。
圖片來自 Pexels
正所謂他山之石,可以攻玉,雖然此文發(fā)表于 2015 年,我看到時已經(jīng)過去良久,但是其中的思想仍然可以為很多后端設計借鑒。
同時作為一名微信后端工程師,看完以后又會思考,學習了這樣的文章以后,是否能給自己的工作帶來一些實際的經(jīng)驗呢?所謂紙上得來終覺淺,絕知此事要躬行,能否自己實踐一下 100 億次紅包請求呢?
否則讀完以后腦子里能剩下的東西不過就是 100 億,1400 萬 QPS 整流這樣的字眼,剩下的文章將展示作者是如何以此過程為目標,在本地環(huán)境的模擬了此過程。
實現(xiàn)的目標:單機支持 100 萬連接,模擬了搖紅包和發(fā)紅包過程,單機峰值 QPS 6 萬,平穩(wěn)支持了業(yè)務。
注:本文以及作者所有內(nèi)容,僅代表個人理解和實踐,過程和微信團隊沒有任何關系,真正的線上系統(tǒng)也不同,只是從一些技術點進行了實踐,請讀者進行區(qū)分。
背景知識
QPS:Queries per second(每秒的請求數(shù)目)。
PPS:Packets per second(每秒數(shù)據(jù)包數(shù)目)。
搖紅包:客戶端發(fā)出一個搖紅包的請求,如果系統(tǒng)有紅包就會返回,用戶獲得紅包。
發(fā)紅包:產(chǎn)生一個紅包里面含有一定金額,紅包指定數(shù)個用戶,每個用戶會收到紅包信息,用戶可以發(fā)送拆紅包的請求,獲取其中的部分金額。
確定目標
在一切系統(tǒng)開始以前,我們應該搞清楚我們的系統(tǒng)在完成以后,應該有一個什么樣的負載能力。
用戶總數(shù)
通過文章我們可以了解到接入服務器 638 臺,服務上限大概是 14.3 億用戶, 所以單機負載的用戶上限大概是 14.3 億/638 臺=228 萬用戶/臺。
但是目前中國肯定不會有 14 億用戶同時在線,參考的說法:
- http://qiye.qianzhan.com/show/detail/160818-b8d1c700.html
2016 年 Q2 微信用戶大概是 8 億,月活在 5.4 億左右。所以在 2015 年春節(jié)期間,雖然使用的用戶會很多,但是同時在線肯定不到 5.4 億。
服務器數(shù)量
一共有 638 臺服務器,按照正常運維設計,我相信所有服務器不會完全上線,會有一定的硬件冗余,來防止突發(fā)硬件故障。假設一共有 600 臺接入服務器。
單機需要支持的負載數(shù)
每臺服務器支持的用戶數(shù):5.4 億/ 600=90 萬。也就是平均單機支持 90 萬用戶。
如果真實情況比 90 萬更多,則模擬的情況可能會有偏差,但是我認為 QPS 在這個實驗中更重要。
單機峰值 QPS
文章中明確表示為 1400 萬 QPS。這個數(shù)值是非常高的,但是因為有 600 臺服務器存在,所以單機的 QPS 為 1400 萬/600=約為 2.3 萬 QPS。
文章曾經(jīng)提及系統(tǒng)可以支持 4000 萬 QPS,那么系統(tǒng)的 QPS 至少要到 4000 萬/ 600=約為 6.6 萬,這個數(shù)值大約是目前的 3 倍,短期來看并不會被觸及。但是我相信應該做過相應的壓力測試。
發(fā)放紅包
文中提到系統(tǒng)以 5 萬個每秒的下發(fā)速度,那么單機每秒下發(fā)速度 50000/600=83 個/秒,也就是單機系統(tǒng)應該保證每秒以 83 個的速度下發(fā)即可。
最后考慮到系統(tǒng)的真實性,還至少有用戶登錄的動作,真實的系統(tǒng)還會包括聊天這樣的服務業(yè)務。
最后整體看一下 100 億次搖紅包這個需求,假設它是均勻地發(fā)生在春節(jié)聯(lián)歡晚會的 4 個小時里。
那么服務器的 QPS 應該是 10000000000/600/3600/4.0=1157。也就是單機每秒 1000 多次,這個數(shù)值其實并不高。
如果完全由峰值速度 1400 萬消化 10000000000/(1400*10000)=714 秒,也就是說只需要峰值堅持 11 分鐘,就可以完成所有的請求。
可見互聯(lián)網(wǎng)產(chǎn)品的一個特點就是峰值非常高,持續(xù)時間并不會很長。
總結:從單臺服務器看,它需要滿足下面一些條件。
①支持至少 100 萬連接用戶。
②每秒至少能處理 2.3 萬的 QPS,這里我們把目標定得更高一些 ,分別設定到了 3 萬和 6 萬。
③搖紅包:支持每秒 83 個的速度下發(fā)放紅包,也就是說每秒有 2.3 萬次搖紅包的請求,其中 83 個請求能搖到紅包,其余的 2.29 萬次請求會知道自己沒搖到。
當然客戶端在收到紅包以后,也需要確保客戶端和服務器兩邊的紅包數(shù)目和紅包內(nèi)的金額要一致。
因為沒有支付模塊,所以我們也把要求提高一倍,達到 200 個紅包每秒的分發(fā)速度。
④支持用戶之間發(fā)紅包業(yè)務,確保收發(fā)兩邊的紅包數(shù)目和紅包內(nèi)金額要一致。同樣也設定 200 個紅包每秒的分發(fā)速度為我們的目標。
想要完整地模擬整個系統(tǒng)實在是太難了,首先需要海量的服務器,其次需要上億的模擬客戶端。
這對我來說是辦不到,但是有一點可以確定,整個系統(tǒng)是可以水平擴展的,所以我們可以模擬 100 萬客戶端,再模擬一臺服務器,那么就完成了 1/600 的模擬。
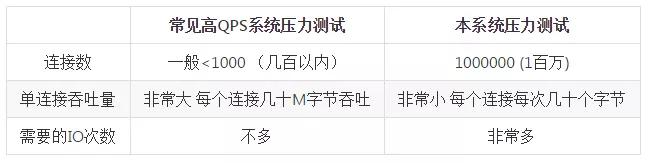
和現(xiàn)有系統(tǒng)區(qū)別:和大部分高 QPS 測試的不同,本系統(tǒng)的側重點有所不同。
我對兩者做了一些對比:
基礎軟件和硬件
軟件
Golang 1.8r3,Shell,Python(開發(fā)沒有使用 C++ 而是使用了 Golang,是因為使用 Golang 的最初原型達到了系統(tǒng)要求。雖然 Golang 還存在一定的問題,但是和開發(fā)效率比,這點損失可以接受)。
服務器操作系統(tǒng):Ubuntu 12.04。
客戶端操作系統(tǒng):debian 5.0。
硬件環(huán)境
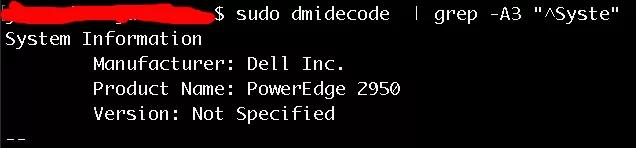
服務端:dell R2950。8 核物理機,非獨占有其他業(yè)務在工作,16G 內(nèi)存。這臺硬件大概是 7 年前的產(chǎn)品,性能要求應該不是很高。
服務器硬件版本:
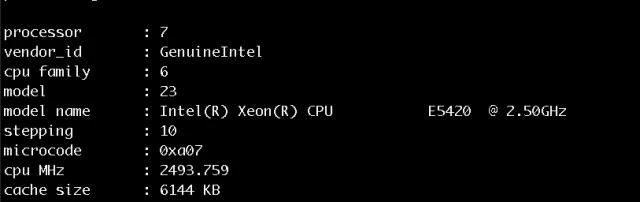
服務器 CPU 信息:
客戶端:esxi 5.0 虛擬機,配置為 4 核 5G 內(nèi)存。一共 17 臺,每臺和服務器建立 6 萬個連接,完成 100 萬客戶端模擬。
技術分析和實現(xiàn)
單機實現(xiàn) 100 萬用戶連接
這一點來說相對簡單,筆者在幾年前就早完成了單機百萬用戶的開發(fā)以及操作。現(xiàn)代的服務器都可以支持百萬用戶。相關內(nèi)容可以查看 Github 代碼以及相關文檔、系統(tǒng)配置以及優(yōu)化文檔。
參考鏈接:
- https://github.com/xiaojiaqi/C1000kPracticeGuide
- https://github.com/xiaojiaqi/C1000kPracticeGuide/tree/master/docs/cn
3 萬 QPS
這個問題需要分 2 個部分來看客戶端方面和服務器方面。
①客戶端 QPS
因為有 100 萬連接連在服務器上,QPS 為 3 萬。這就意味著每個連接每 33 秒,就需要向服務器發(fā)一個搖紅包的請求。
因為單 IP 可以建立的連接數(shù)為 6 萬左右,有 17 臺服務器同時模擬客戶端行為。我們要做的就是保證在每一秒都有這么多的請求發(fā)往服務器即可。
其中技術要點就是客戶端協(xié)同。但是各個客戶端的啟動時間,建立連接的時間都不一致,還存在網(wǎng)絡斷開重連這樣的情況,各個客戶端如何判斷何時自己需要發(fā)送請求,各自該發(fā)送多少請求呢?
我是這樣解決的:利用 NTP 服務,同步所有的服務器時間,客戶端利用時間戳來判斷自己的此時需要發(fā)送多少請求。
算法很容易實現(xiàn):假設有 100 萬用戶,則用戶 id 為 0-999999。要求的 QPS 為 5 萬,客戶端得知 QPS 為 5 萬,總用戶數(shù)為 100 萬,它計算 100 萬/5 萬=20,所有的用戶應該分為 20 組。
如果 time()%20==用戶id%20,那么這個 id 的用戶就該在這一秒發(fā)出請求,如此實現(xiàn)了多客戶端協(xié)同工作。每個客戶端只需要知道總用戶數(shù)和 QPS 就能自行準確發(fā)出請求了。
擴展思考:如果 QPS 是 3 萬這樣不能被整除的數(shù)目,該如何做?如何保證每臺客戶端發(fā)出的請求數(shù)目盡量的均衡呢?
②服務器 QPS
服務器端的 QPS 相對簡單,它只需要處理客戶端的請求即可。但是為了客觀了解處理情況,我們還需要做 2 件事情。
第一:需要記錄每秒處理的請求數(shù)目,這需要在代碼里埋入計數(shù)器。
第二:需要監(jiān)控網(wǎng)絡,因為網(wǎng)絡的吞吐情況,可以客觀的反映出 QPS 的真實數(shù)據(jù)。
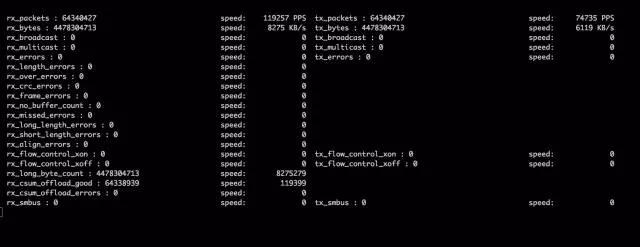
為此,我利用 Python 腳本結合 ethtool 工具編寫了一個簡單的工具,通過它我們可以直觀地監(jiān)視到網(wǎng)絡的數(shù)據(jù)包通過情況如何。它可以客觀地顯示出我們的網(wǎng)絡有如此多的數(shù)據(jù)傳輸在發(fā)生。
工具截圖:
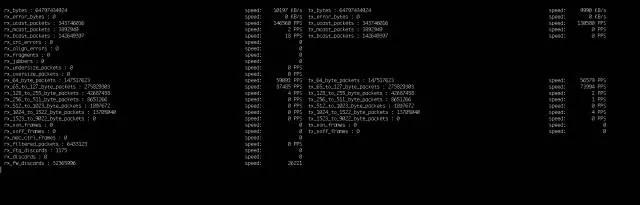
搖紅包業(yè)務
搖紅包的業(yè)務非常簡單,首先服務器按照一定的速度生產(chǎn)紅包。紅包沒有被取走的話,就堆積在里面。
服務器接收一個客戶端的請求,如果服務器里現(xiàn)在有紅包就會告訴客戶端有,否則就提示沒有紅包。
因為單機每秒有 3 萬的請求,所以大部分的請求會失敗。只需要處理好鎖的問題即可。
我為了減少競爭,將所有的用戶分在了不同的桶里。這樣可以減少對鎖的競爭。
如果以后還有更高的性能要求,還可以使用高性能隊列——Disruptor 來進一步提高性能。
注意,在我的測試環(huán)境里是缺少支付這個核心服務的,所以實現(xiàn)的難度是大大地減輕了。
另外提供一組數(shù)字:2016 年淘寶的雙 11 的交易峰值僅僅為 12 萬/秒,微信紅包分發(fā)速度是 5 萬/秒,要做到這點是非常困難的。
參考鏈接:
- http://mt.sohu.com/20161111/n472951708.shtml
發(fā)紅包業(yè)務
發(fā)紅包的業(yè)務很簡單,系統(tǒng)隨機產(chǎn)生一些紅包,并且隨機選擇一些用戶,系統(tǒng)向這些用戶提示有紅包。
這些用戶只需要發(fā)出拆紅包的請求,系統(tǒng)就可以隨機從紅包中拆分出部分金額,分給用戶,完成這個業(yè)務。同樣這里也沒有支付這個核心服務。
監(jiān)控
最后,我們需要一套監(jiān)控系統(tǒng)來了解系統(tǒng)的狀況,我借用了我另一個項目里的部分代碼完成了這個監(jiān)控模塊,利用這個監(jiān)控,服務器和客戶端會把當前的計數(shù)器內(nèi)容發(fā)往監(jiān)控,監(jiān)控需要把各個客戶端的數(shù)據(jù)做一個整合和展示。
同時還會把日志記錄下來,給以后的分析提供原始數(shù)據(jù)。線上系統(tǒng)更多使用 opentsdb 這樣的時序數(shù)據(jù)庫,這里資源有限,所以用了一個原始的方案。
參考鏈接:
- https://github.com/xiaojiaqi/fakewechat
監(jiān)控顯示日志大概這樣:

代碼實現(xiàn)及分析
在代碼方面,使用到的技巧實在不多,主要是設計思想和 Golang 本身的一些問題需要考慮。
首先 Golang 的 goroutine 的數(shù)目控制,因為至少有 100 萬以上的連接,所以按照普通的設計方案,至少需要 200 萬或者 300 萬的 goroutine 在工作,這會造成系統(tǒng)本身的負擔很重。
其次就是 100 萬個連接的管理,無論是連接還是業(yè)務都會造成一些心智的負擔。
我的設計是這樣的:
①首先將 100 萬連接分成多個不同的 SET,每個 SET 是一個獨立、平行的對象。
每個 SET 只管理幾千個連接,如果單個 SET 工作正常,我只需要添加 SET 就能提高系統(tǒng)處理能力。
②其次謹慎地設計了每個 SET 里數(shù)據(jù)結構的大小,保證每個 SET 的壓力不會太大,不會出現(xiàn)消息的堆積。
③再次減少了 gcroutine 的數(shù)目,每個連接只使用一個 goroutine,發(fā)送消息在一個 SET 里只有一個 gcroutine 負責,這樣節(jié)省了 100 萬個 goroutine。
這樣整個系統(tǒng)只需要保留 100 萬零幾百個 gcroutine 就能完成業(yè)務。大量的節(jié)省了 CPU 和內(nèi)存。
系統(tǒng)的工作流程大概是:每個客戶端連接成功后,系統(tǒng)會分配一個 goroutine 讀取客戶端的消息,當消息讀取完成,將它轉化為消息對象放至在 SET 的接收消息隊列,然后返回獲取下一個消息。
在 SET 內(nèi)部,有一個工作 goroutine,它只做非常簡單而高效的事情,它做的事情如下。
檢查 SET 的接受消息,它會收到 3 類消息:
- 客戶端的搖紅包請求消息。
- 客戶端的其他消息,比如聊天好友這一類。
- 服務器端對客戶端消息的回應。
對于第 1 種消息是這樣處理的,從客戶端拿到搖紅包請求消息,試圖從 SET 的紅包隊列里獲取一個紅包,如果拿到了就把紅包信息返回給客戶端,否則構造一個沒有搖到的消息,返回給對應的客戶端。
對于第 2 種消息,只需簡單地從隊列里拿走消息,轉發(fā)給后端的聊天服務隊列即可,其他服務會把消息轉發(fā)出去。
對于第 3 種消息,SET 只需要根據(jù)消息里的用戶 id,找到 SET 里保留的用戶連接對象,發(fā)回去就可以了。
對于紅包產(chǎn)生服務,它的工作很簡單,只需要按照順序輪流在每個 SET 的紅包產(chǎn)生隊列里放置紅包對象就可以了。
這樣可以保證每個 SET 里都是公平的,其次它的工作強度很低,可以保證業(yè)務穩(wěn)定。
參考鏈接:
- https://github.com/xiaojiaqi/10billionhongbaos
實踐
實踐的過程分為三個階段:
階段 1
分別啟動服務器端和監(jiān)控端,然后逐一啟動 17 臺客戶端,讓它們建立起 100 萬的鏈接。在服務器端,利用 ss 命令統(tǒng)計出每個客戶端和服務器建立了多少連接。
命令如下:
- Alias ss2=Ss –ant | grep 1025 | grep EST | awk –F: “{print \$8}” | sort | uniq –c’
結果如下:
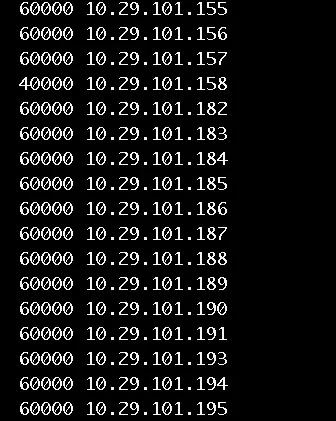
階段 2
利用客戶端的 HTTP 接口,將所有的客戶端 QPS 調(diào)整到 3 萬,讓客戶端發(fā)出 3W QPS 強度的請求。
運行如下命令:
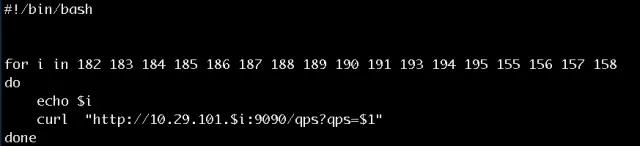
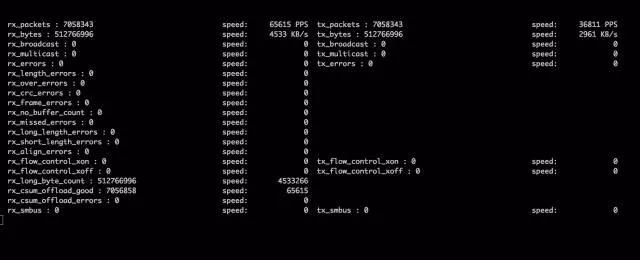
觀察網(wǎng)絡監(jiān)控和監(jiān)控端反饋,發(fā)現(xiàn) QPS 達到預期數(shù)據(jù),網(wǎng)絡監(jiān)控截圖:
在服務器端啟動一個產(chǎn)生紅包的服務,這個服務會以 200 個每秒的速度下發(fā)紅包,總共 4 萬個。
此時觀察客戶端在監(jiān)控上的日志,會發(fā)現(xiàn)基本上以 200 個每秒的速度獲取到紅包。

等到所有紅包下發(fā)完成后,再啟動一個發(fā)紅包的服務,這個服務系統(tǒng)會生成 2 萬個紅包,每秒也是 200 個,每個紅包隨機指定 3 位用戶,并向這 3 個用戶發(fā)出消息,客戶端會自動來拿紅包,最后所有的紅包都被拿走。

階段 3
利用客戶端的 HTTP 接口,將所有的客戶端 QPS 調(diào)整到 6 萬,讓客戶端發(fā)出 6W QPS 強度的請求。
如法炮制,在服務器端,啟動一個產(chǎn)生紅包的服務,這個服務會以 200 個每秒的速度下發(fā)紅包,總共 4 萬個。
此時觀察客戶端在監(jiān)控上的日志,會發(fā)現(xiàn)基本上以 200 個每秒的速度獲取到紅包。
等到所有紅包下發(fā)完成后,再啟動一個發(fā)紅包的服務,這個服務系統(tǒng)會生成 2 萬個紅包,每秒也是 200 個,每個紅包隨機指定 3 位用戶,并向這 3 個用戶發(fā)出消息,客戶端會自動來拿紅包,最后所有的紅包都被拿走。
最后,實踐完成。
分析數(shù)據(jù)
在實踐過程中,服務器和客戶端都將自己內(nèi)部的計數(shù)器記錄發(fā)往監(jiān)控端,成為了日志。
我們利用簡單 Python 腳本和 gnuplt 繪圖工具,將實踐的過程可視化,由此來驗證運行過程。
第一張是客戶端的 QPS 發(fā)送數(shù)據(jù):
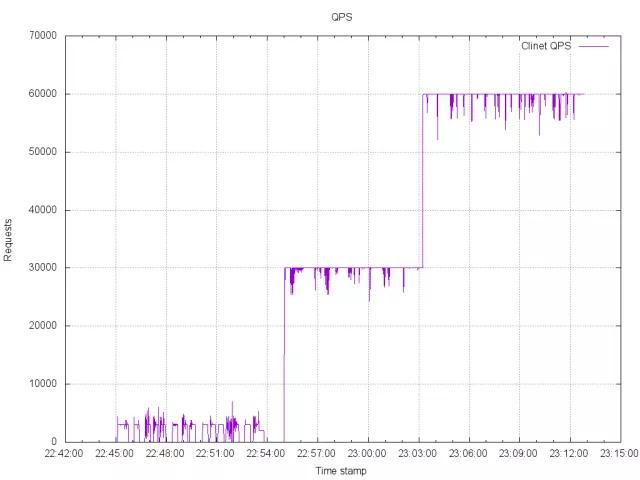
這張圖的橫坐標是時間,單位是秒,縱坐標是 QPS,表示這時刻所有客戶端發(fā)送的請求的 QPS。
圖的第一區(qū)間,幾個小的峰值,是 100 萬客戶端建立連接的, 圖的第二區(qū)間是 3 萬 QPS 區(qū)間,我們可以看到數(shù)據(jù)比較穩(wěn)定地保持在 3 萬這個區(qū)間。最后是 6 萬 QPS 區(qū)間。
但是從整張圖可以看到 QPS 不是完美地保持在我們希望的直線上。
這主要是以下幾個原因造成的:
①當非常多 goroutine 同時運行的時候,依靠 sleep 定時并不準確,發(fā)生了偏移。
我覺得這是 Golang 本身調(diào)度導致的。當然如果 CPU 比較強勁,這個現(xiàn)象會消失。
②因為網(wǎng)絡的影響,客戶端在發(fā)起連接時,可能發(fā)生延遲,導致在前 1 秒沒有完成連接。
③服務器負載較大時,1000M 網(wǎng)絡已經(jīng)出現(xiàn)了丟包現(xiàn)象,可以通過 ifconfig 命令觀察到這個現(xiàn)象,所以會有 QPS 的波動。
第二張是服務器處理的 QPS 圖:

和客戶端相對應,服務器也存在 3 個區(qū)間,和客戶端的情況很接近。但是我們看到了在大概 22:57 分,系統(tǒng)的處理能力就有一個明顯的下降,隨后又提高的尖狀,這說明代碼還需要優(yōu)化。
整體觀察可以發(fā)現(xiàn),在 3 萬 QPS 區(qū)間,服務器的 QPS 比較穩(wěn)定,在 6 萬 QSP 時候,服務器的處理就不穩(wěn)定了。我相信這和我的代碼有關,如果繼續(xù)優(yōu)化的話,還應該能有更好的效果。
將兩張圖合并起來:

基本是吻合的,這也證明系統(tǒng)是符合預期設計的。
這是紅包生成數(shù)量的狀態(tài)變化圖:
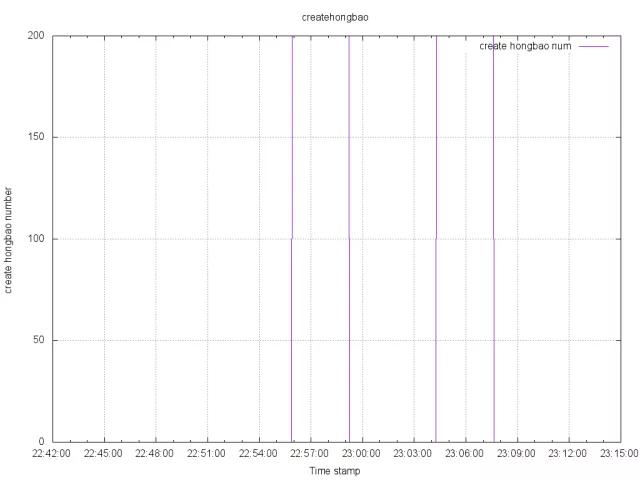
非常穩(wěn)定。
這是客戶端每秒獲取的搖紅包狀態(tài):

可以發(fā)現(xiàn) 3 萬 QPS 區(qū)間,客戶端每秒獲取的紅包數(shù)基本在 200 左右,在 6 萬 QPS 的時候,以及出現(xiàn)劇烈的抖動,不能保證在 200 這個數(shù)值了。
我覺得主要是 6 萬 QPS 時候,網(wǎng)絡的抖動加劇了,造成了紅包數(shù)目也在抖動。
最后是 Golang 自帶的 pprof 信息,其中有 GC 時間超過了 10ms, 考慮到這是一個 7 年前的硬件,而且非獨占模式,所以還是可以接受。

總結
按照設計目標,我們模擬和設計了一個支持 100 萬用戶,并且每秒至少可以支持 3 萬 QPS,最多 6 萬 QPS 的系統(tǒng),簡單模擬了微信的搖紅包和發(fā)紅包的過程,可以說達到了預期的目的。
如果 600 臺主機每臺主機可以支持 6 萬 QPS,只需要 7 分鐘就可以完成 100 億次搖紅包請求。
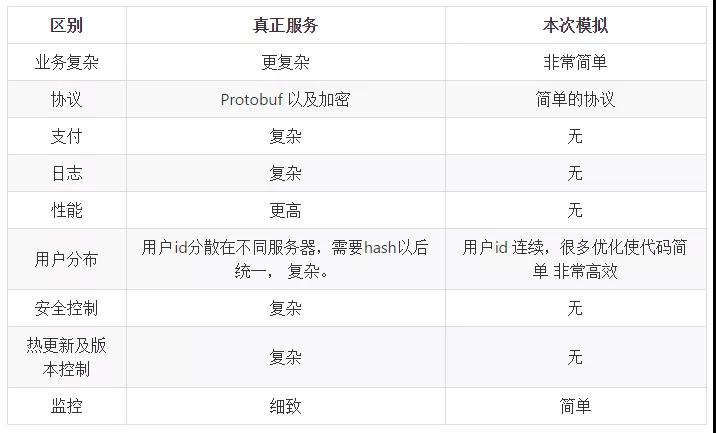
雖然這個原型簡單地完成了預設的業(yè)務,但是它和真正的服務會有哪些差別呢?
我羅列了一下:
參考資料:
- 單機百萬的實踐
https://github.com/xiaojiaqi/C1000kPracticeGuide
- 如何在 AWS 上進行 100 萬用戶壓力
https://github.com/xiaojiaqi/fakewechat/wiki/Stress-Testing-in-the-Cloud
- 構建一個你自己的類微信系統(tǒng)
https://github.com/xiaojiaqi/fakewechat/wiki/Design
http://techblog.cloudperf.net/2016/05/2-million-packets-per-second-on-public.html
- @火丁筆記
http://huoding.com/2013/10/30/296
https://gobyexample.com/non-blocking-channel-operations