如何利用Python實現SQL自動化?
筆者在工作中經常要使用SQL,其不乏存在惱人的細微差異和種種限制,但說到底,它是數據行業的基石。因此,對于每一位數據領域的工作者,SQL都是不可或缺的。精通SQL意義非凡。
SQL是很不錯,但怎么能僅滿足于“不錯”呢?為什么不進一步操作SQL呢?
陳述性語句會誘發SQL限制的發生,就是說,向SQL尋求數據,SQL會在特定數據庫找尋并反饋。對于許多數據提取或簡單的數據操作任務來說,這已經足夠了。
但如果有更多需求怎么辦?
本文將為你展示如何操作。
從基礎開始
- import pyodbc
- from datetime import datetime
- classSql:
- def__init__(self, database, server="XXVIR00012,55000"):
- # here we are telling python what to connect to (our SQL Server)
- self.cnxn = pyodbc.connect("Driver={SQL Server Native Client 11.0};"
- "Server="+server+";"
- "Database="+database+";"
- "Trusted_Connection=yes;")
- # initialise query attribute
- self.query ="-- {}\n\n-- Made in Python".format(datetime.now()
- .strftime("%d/%m/%Y"))
這個代碼就是操作MS SQL服務器的基礎。只要編寫好這個代碼,通過Python 連接到SQL 僅需:
- sql = Sql('database123')
很簡單對么?同時發生了幾件事,下面將對此代碼進行剖析。class Sql:
首先要注意,這個代碼包含在一個類中。筆者發現這是合乎邏輯的,因為在此格式中,已經對此特定數據庫進行了增添或移除進程。若見其工作過程,思路便能更加清晰。
初始化類:
- def __init__(self, database,server="XXVIR00012,55000"):
因為筆者和同事幾乎總是連接到相同的服務器,所以筆者將這個通用瀏覽器的名稱設為默認參數server。
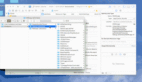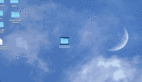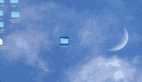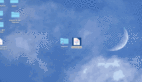
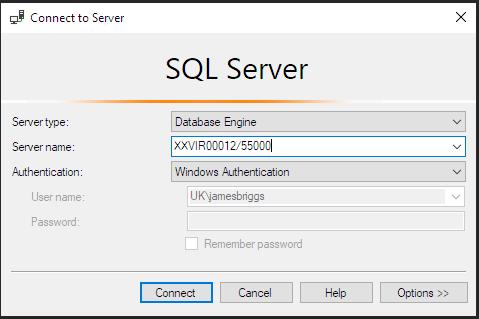
在“Connect to Server”對話框或者MS SQL Server Management Studio的視窗頂端可以找到服務器的名稱:
下一步,連接SQL:
- self.cnxn =pyodbc.connect("Driver={SQL Server Native Client 11.0};"
- "Server="+self.server+";"
- "Database="+self.database+";"
- "Trusted_Connection=yes;")
pyodbc 模塊,使得這一步驟異常簡單。只需將連接字符串過渡到 pyodbc.connect(...) 函數即可,點擊以了解詳情here。
最后,筆者通常會在 Sql 類中編寫一個查詢字符串,sql類會隨每個傳遞給類的查詢而更新:
- self.query = "-- {}\n\n--Made in Python".format(datetime.now()
- .strftime("%d/%m/%Y"))
這樣便于記錄代碼,同時也使輸出更為可讀,讓他人讀起來更舒服。
請注意在下列的代碼片段中,筆者將不再更新代碼中的self.query 部分。
組塊
一些重要函數非常有用,筆者幾乎每天都會使用。這些函數都側重于將數據從數據庫中傳入或傳出。
以下圖文件目錄為始:
對于當前此項目,需要:
- 將文件導入SQL
- 將其合并到單一表格內
- 根據列中類別靈活創建多個表格
SQL類不斷被充實后,后續會容易很多:
- import sys
- sys.path.insert(0, r'C:\\User\medium\pysqlplus\lib')
- import os
- from data importSql
- sql =Sql('database123') # initialise the Sql object
- directory =r'C:\\User\medium\data\\' # this is where our generic data is stored
- file_list = os.listdir(directory) # get a list of all files
- for file in file_list: # loop to import files to sql
- df = pd.read_csv(directory+file) # read file to dataframe
- sql.push_dataframe(df, file[:-4])
- # now we convert our file_list names into the table names we have imported to SQL
- table_names = [x[:-4] for x in file_list]
- sql.union(table_names, 'generic_jan') # union our files into one new table called 'generic_jan'
- sql.drop(table_names) # drop our original tables as we now have full table
- # get list of categories in colX, eg ['hr', 'finance', 'tech', 'c_suite']
- sets =list(sql.manual("SELECT colX AS 'category' FROM generic_jan GROUP BY colX", response=True)['category'])
- for category in sets:
- sql.manual("SELECT * INTO generic_jan_"+category+" FROM generic_jan WHERE colX = '"+category+"'")
從頭開始。
入棧數據結構
- defpush_dataframe(self, data, table="raw_data", batchsize=500):
- # create execution cursor
- cursor = self.cnxn.cursor()
- # activate fast execute
- cursor.fast_executemany =True
- # create create table statement
- query ="CREATE TABLE ["+ table +"] (\n"
- # iterate through each column to be included in create table statement
- for i inrange(len(list(data))):
- query +="\t[{}] varchar(255)".format(list(data)[i]) # add column (everything is varchar for now)
- # append correct connection/end statement code
- if i !=len(list(data))-1:
- query +=",\n"
- else:
- query +="\n);"
- cursor.execute(query) # execute the create table statement
- self.cnxn.commit() # commit changes
- # append query to our SQL code logger
- self.query += ("\n\n-- create table\n"+ query)
- # insert the data in batches
- query = ("INSERT INTO [{}] ({})\n".format(table,
- '['+'], [' # get columns
- .join(list(data)) +']') +
- "VALUES\n(?{})".format(", ?"*(len(list(data))-1)))
- # insert data into target table in batches of 'batchsize'
- for i inrange(0, len(data), batchsize):
- if i+batchsize >len(data):
- batch = data[i: len(data)].values.tolist()
- else:
- batch = data[i: i+batchsize].values.tolist()
- # execute batch insert
- cursor.executemany(query, batch)
- # commit insert to SQL Server
- self.cnxn.commit()
此函數包含在SQL類中,能輕松將Pandas dataframe插入SQL數據庫。
其在需要上傳大量文件時非常有用。然而,Python能將數據插入到SQL的真正原因在于其靈活性。
要橫跨一打Excel工作簿才能在SQL中插入特定標簽真的很糟心。但有Python在,小菜一碟。如今已經構建起了一個可以使用Python讀取標簽的函數,還能將標簽插入到SQL中。
Manual(函數)
- defmanual(self, query, response=False):
- cursor = self.cnxn.cursor() # create execution cursor
- if response:
- returnread_sql(query, self.cnxn) # get sql query output to dataframe
- try:
- cursor.execute(query) # execute
- except pyodbc.ProgrammingErroras error:
- print("Warning:\n{}".format(error)) # print error as a warning
- self.cnxn.commit() # commit query to SQL Server
- return"Query complete."
此函數實際上應用在union 和 drop 函數中。僅能使處理SQL代碼變得盡可能簡單。
response參數能將查詢輸出解壓到DataFrame。generic_jan 表中的colX ,可供摘錄所有獨特值,操作如下:
- sets =list(sql.manual("SELECT colX AS 'category' FROM generic_jan GROUP BYcolX", response=True)['category'])
Union(函數)
構建 了manual 函數,創建 union 函數就簡單了:
- defunion(self, table_list, name="union", join="UNION"):
- # initialise the query
- query ="SELECT * INTO ["+name+"] FROM (\n"
- # build the SQL query
- query +=f'\n{join}\n'.join(
- [f'SELECT [{x}].* FROM [{x}]'for x in table_list]
- )
- query +=") x" # add end of query
- self.manual(query, fast=True) # fast execute
創建 union 函數只不過是在循環參考 table_list提出的表名,從而為給定的表名構建 UNION函數查詢。然后用self.manual(query)處理。
Drop(函數)
上傳大量表到SQL服務器是可行的。雖然可行,但會使數據庫迅速過載。 為解決這一問題,需要創建一個drop函數:
- defdrop(self, tables):
- # check if single or list
- ifisinstance(tables, str):
- # if single string, convert to single item in list for for-loop
- tables = [tables]
- for table in tables:
- # check for pre-existing table and delete if present
- query = ("IF OBJECT_ID ('["+table+"]', 'U') IS NOT NULL "
- "DROP TABLE ["+table+"]")
- self.manual(query) # execute
view rawpysqlplus_drop_short.py hosted with ❤ by GitHub
點擊
https://gist.github.com/jamescalam/b316c1714c30986fff58c22b00395cc0
得全圖
同樣,此函數也由于 manual 函數極為簡單。操作者可選擇輸入字符到tables ,刪除單個表,或者向tables提供一列表名,刪除多個表。
當這些非常簡單的函數結合在一起時,便可以利用Python的優勢極大豐富SQL的功能。
筆者本人幾乎天天使用此法,其簡單且十分有效。
希望能夠幫助其他用戶找到將Python并入其SQL路徑的方法,感謝閱讀!