騰訊高性能圖計算框架Plato及其算法應用
Plato 簡介
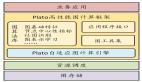
騰訊高性能圖計算框架 Plato
圖作為一種表示和分析大數據的有效方法,已成為社交網絡、推薦系統、網絡安全、文本檢索和生物醫療等領域至關重要的數據分析和挖掘工具。例如,定期對網頁進行影響力排序以提升用戶的搜索體驗;分析龐大的社交網絡結構以便精準地為用戶推薦服務;通過子圖匹配等方式了解蛋白質間的相互作用從而研制更有效的臨床醫藥。
Plato 是騰訊圖計算 TGraph 整合騰訊內部圖計算資源,打造的業界領先的超大規模圖計算平臺。Plato 針對十億級節點的超大規模圖計算,將算法計算時間從天級縮短到分鐘級,性能提升數十倍,達到業界領先水平,并且打破了動輒需要數百臺服務器的資源瓶頸,最少只需十臺服務器即可完成計算。Plato 賦能騰訊內部包括微信在內的眾多核心業務,極大的創造了業務價值。
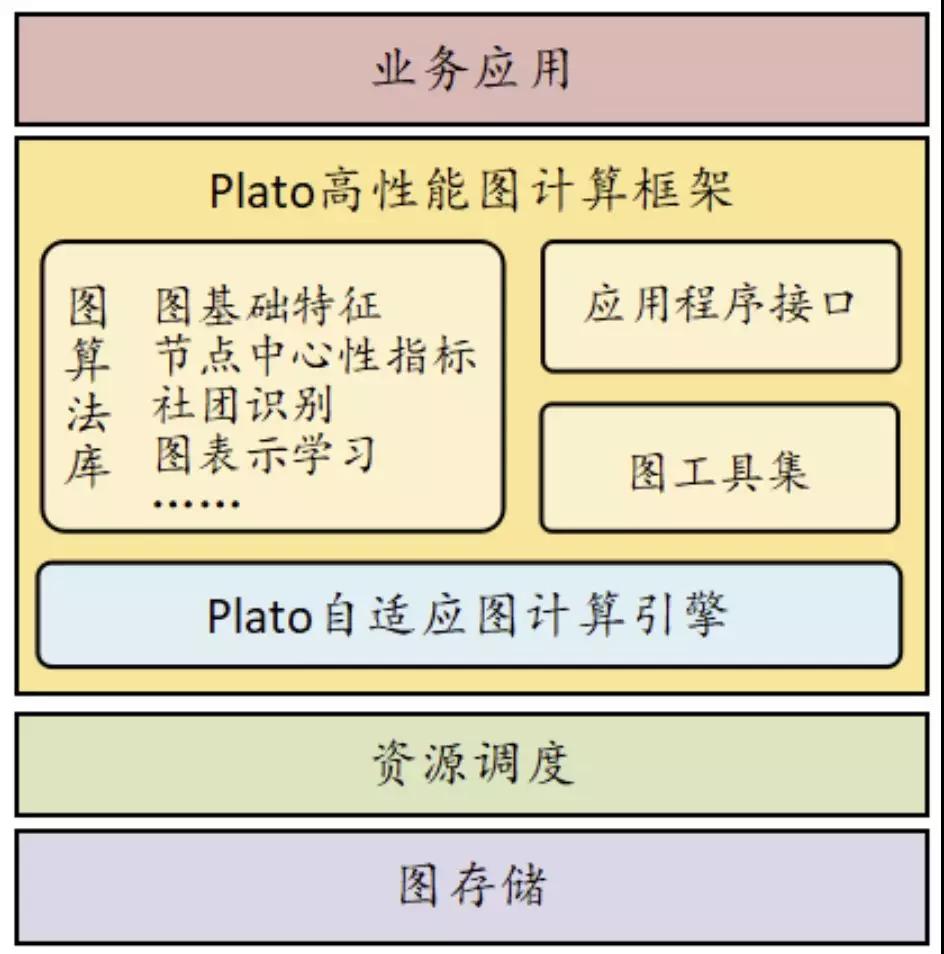
圖1:Plato架構
Plato 開源地址:https://github.com/tencent/plato
Plato 高性能圖計算框架主要有以下貢獻:
- Plato 能高效地支撐騰訊超大規模社交網絡圖數據的各類計算,且性能達到了學術界和工業界的頂尖水平,比 Spark GraphX 高出 1-2 個數量級,使得許多按天計算的算法可在小時甚至分鐘級別完成,也意味著騰訊圖計算全面進入了分鐘級時代。
- Plato 的內存消耗比 Spark GraphX 減少了 1-2 個數量級,意味著只需中小規模的集群(10 臺服務器左右)即可完成騰訊數據量級的超大規模圖計算,打破了動輒需要上百臺服務器的資源瓶頸,同時也極大地節約了計算成本。
- Plato 隸屬騰訊圖計算 TGraph,起源于超大規模社交網絡圖數據,但可以完美適配其他類型的圖數據,同時,Plato 作為高性能、可擴展、易插拔的工業級圖計算框架,推動了業界超大規模圖計算框架的技術進步。
Plato 算法應用
Plato 目前已支持節點中心性指標、連通圖、社團發現、圖表示學習等多種圖算法,本次將重點介紹基于 Plato 的社團發現算法。
社交網絡往往具有聚類效應,具有相似背景或相同愛好的人,更傾向于聚集在一起,形成一個圈子(社團)。如何從一個給定的社交網絡還原現實生活中的圈子,在社交推薦、社交營銷等領域有著非常廣泛的應用。
社團發現算法簡介
復雜網絡中的聚類效應
復雜網絡研究用圖(Graph)表示網絡:將網絡的參與者抽象成節點(Vertex),而將參與者之間的交互或聯系抽象成節點之間的連邊(Edge),這些節點的集合 V = {v1,v2,··· ,vn} 與連邊的集合 E = {vivj | vi,vj ∈ V } 就構成一幅圖 G(V,E)。
如圖 2 所示,網絡中有 4 簇內部連邊稠密、與外部連邊稀疏的節點,這就是聚類效應的直觀體現。通常把這些聚簇稱為社團(Community),社團發現算法的目標就是將節點準確地劃分至不同的社團中。我們對該網絡使用經典的社團發現算法,計算結果如圖 3 所示,用節點顏色標記社團歸屬。
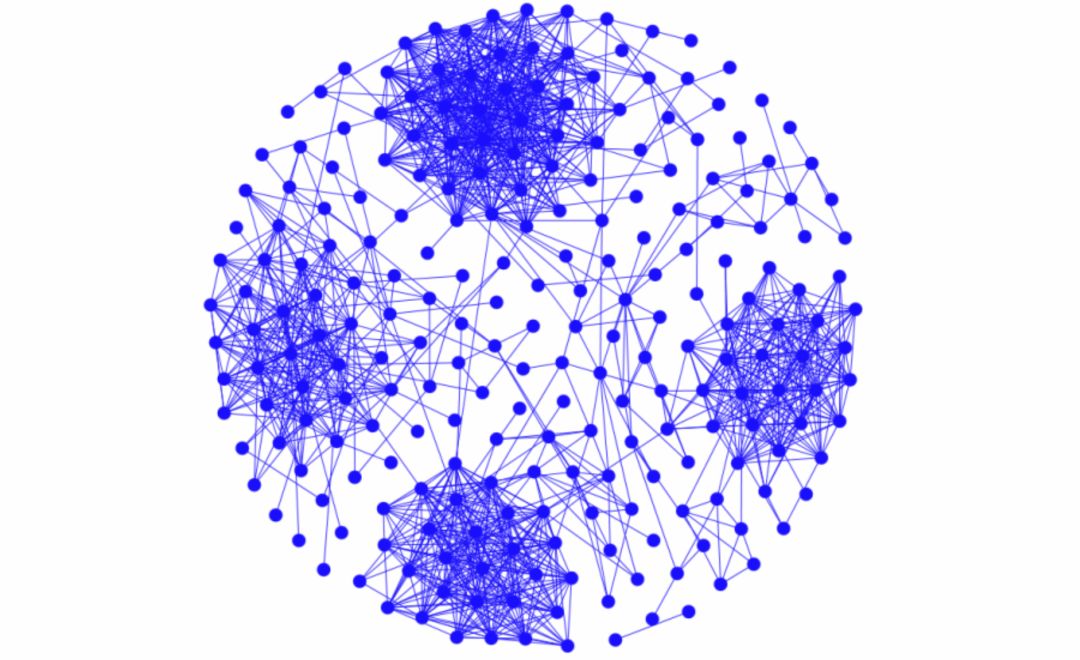
圖2:社交網絡
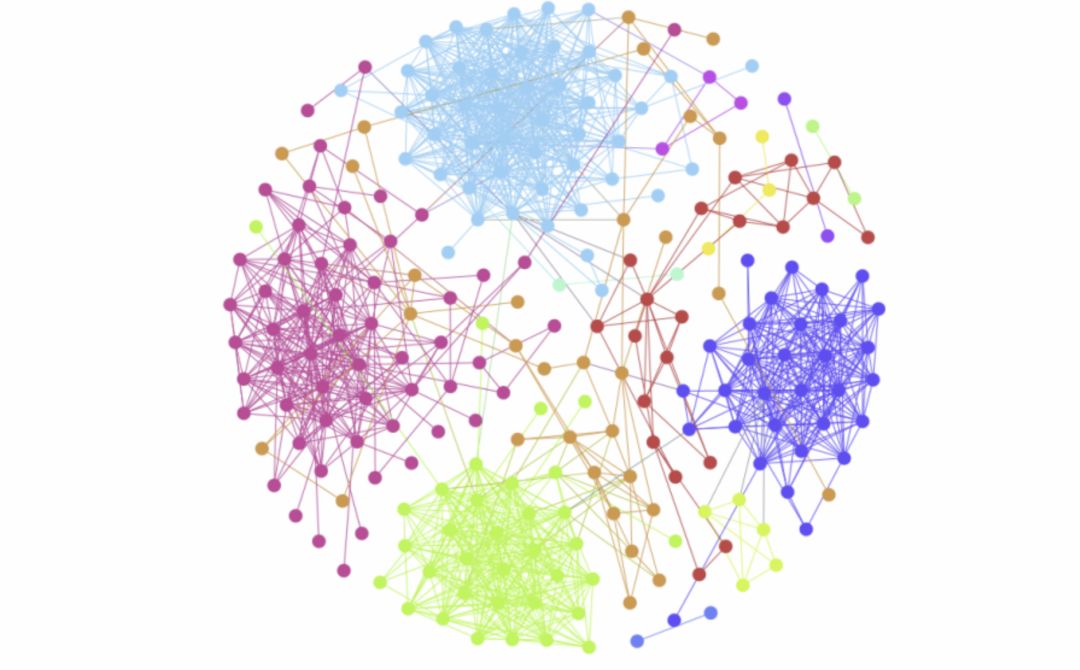
圖3:社團發現計算結果
模塊度指標
模塊度指標能較好地刻畫社團劃分質量[1]:
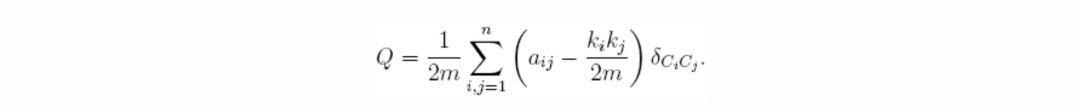
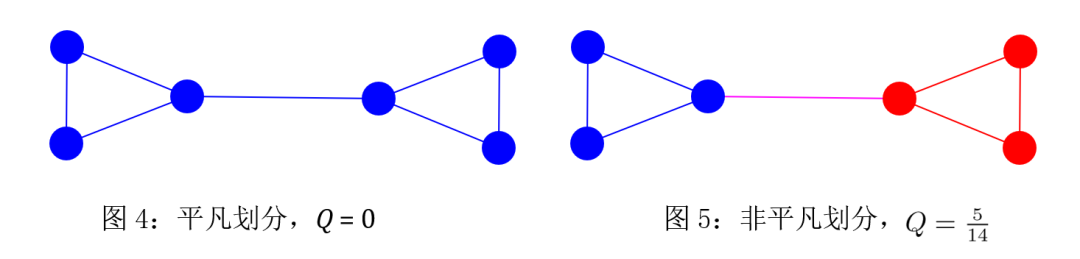
對于同一個網絡,不同的社團劃分通常對應不同的模塊度,以圖 4 和圖 5 為例,若以不同的顏色區分不同的社團,那么圖 4 中的平凡劃分的模塊度為零,圖 5 中的非平凡劃分的模塊度為 5/14。顯然,后者的劃分更為合理。這說明模塊度的大小能在一定程度上反映社團劃分的質量,其值越大,劃分質量越好。
基于邊介數的分裂算法
我們已經找到社團劃分質量的衡量指標——模塊度,接下來就要找出使模塊度達到最大的社團劃分。模塊度的最大化問題已被證明是一個“NP 難題”[5]。因此,為了在可接受的時間內求得社團劃分,我們往往使用貪心策略尋求次優解,這與數據聚類的思想是如出一轍的。
在接下來介紹的聚類算法中,又可以分為分裂算法和凝聚算法,首先介紹一個以去除連邊達到聚類目的的分裂算法:首先把整個網絡看作一個社團,然后不斷地去除介數最大的邊,使其分裂成多個社團,然后通過模塊度指標來控制分裂的深度。由于分裂算法涉及到全網邊介數的計算,計算復雜度過高,工程實現困難,接下來介紹更易工程實現的算法。
基于模塊度增益的凝聚算法
針對分裂算法無法應用于大規模網絡以及無法識別小規模社團的缺點,提出了一種能夠偵測到層次化社團結構的凝聚算法[2](Fast Unfolding 算法):首先把每個節點分別看作一個社團,然后把使模塊度增益最大的鄰近社團吸納成更大的社團,當模塊度增益為零時停止。
算法最終可能輸出多個社團劃分:每一次凝聚都對應一個層次的社團劃分。層次越低,社團規模越小,從而避免了小規模社團的偵測遺漏現象。
標簽傳播算法
標簽傳播算法[3](簡稱 LPA)不以目標函數為導向,大體流程是:將節點所屬社團的名稱作為節點標簽,標簽通過某種方式在網絡中傳播開來,當標簽的傳播穩定后,每個節點都有一個標識其所屬社團的標簽,也就完成了社團劃分。
然而,LPA 也有一個不容忽視的弱點:計算結果的高隨機性,重復運行兩次 LPA 的社團劃分結果往往并不一致。LPA 用鄰居標簽來在更新節點標簽時,每個鄰居的重要性是等同的、每個標簽的重要性也是等同的,結合到 LPA 在傳播過程中的隨機性,某一次隨機傳播帶來的誤差,可能被多次傳播,從而被不斷擴散、放大。
因此提出了 HANP 算法[4],在采集鄰居的標簽時,綜合考慮各個鄰居對節點的重要性,以及各標簽經過多輪傳播后的衰減,從而降低誤差產生的概率以及控制誤差放大。
社團發現算法基于 Plato 的高性能實現
業界實現方案
在圖計算發展的近些年來,涌現出許多優秀的圖計算框架。
使用 C/C++語言編寫的 GraphLab 和 PowerGraph 系統提供了基于消息傳遞的編程接口以及一套圖算法的高性能分布式實現,但系統實現層面的 COST(the Configuration that Outperforms a Single Thread)[6]較高。
Spark GraphX 系統結合了 Spark 的大數據生態環境,在編程接口上相對 GraphLab 和 PowerGraph 提高了易用性,同時很好的處理了計算容錯問題,但由于 Java/Scala 語言本身的開銷,無法達到理想的性能。
Gemini[7]系統提供了一種低 COST 且可擴展的分布式圖計算設計方案。
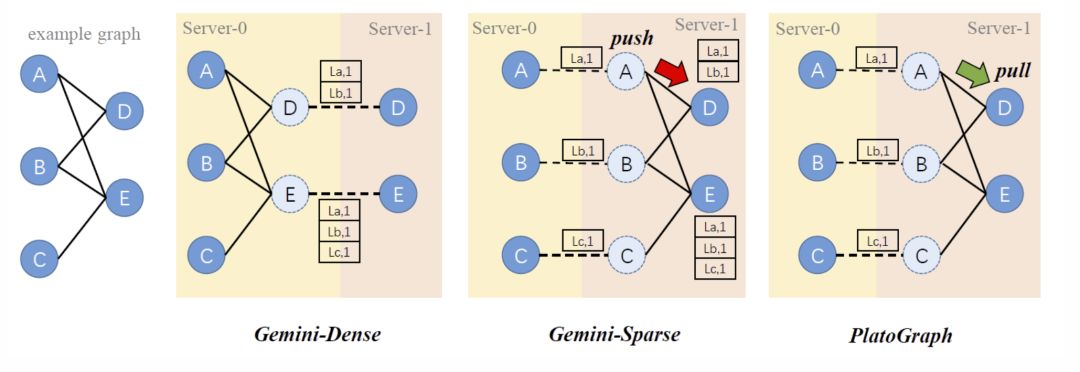
圖6:不同計算模式下LPA算法執行示意圖
社團識別算法的計算模式多種多樣,對于 LPA 和 HANP 等算法,已有計算模式存在很大的性能問題,圖 6 以 Gemini 系統為例來詳細介紹:
Dense 模式下,節點 D 從鄰居節點獲取標簽,并嘗試合并為一個消息(包含兩個元素(La,1),(Lb,1)分別表示 A 和 B 的標簽值)。由于無法合并為定長消息,因此 D 和 E 的消息總長度為 5。
Sparse 模式下,A 將自己的標簽發送到 A 的鏡像節點中,因此 ABC 三個節點發送消息總長度為 3,相比 dense 模式減少了不錯的通信量。但 Sparse 模式下 ABC 三個節點通過 push 的方式將消息傳遞到 DE 兩個節點,需要加鎖避免寫沖突,同時 D 和 E 需要維護長度為 5 的變長 buffer 來保存標簽。
從上述例子我們發現:發送的消息不可以被合并為定長消息,內存占用過多,無法在有限資源內高效的完成計算。
Plato 高性能實現方案
Plato 借鑒并簡化了 Cyclops[8]論文中的方法,使用 MPI 的高性能通訊原語來實現。如圖 6 所示,ABC 三點首先將自己的狀態(標簽值)同步至 server-1 中,在這個過程中產生 3 個單位的通信量,相比 Dense 模式通信更少。之后,節點 D 和 E 使用 Pull 的方式訪問周圍所有節點的標簽來確定自己的標簽值。
通過以上方式,可以極大的減少計算過程中的內存消耗以及通信開銷,能夠做到在有限資源內迅速完成 LPA 和 HANP 等消息不可合并為定長數據類型的圖算法計算。
Plato 算法示例
上述 FastUnfolding、LPA 和 HANP 等社團發現算法已在 github 開源,感興趣的讀者可通過如下地址獲取算法介紹和源代碼:
開源地址:https://github.com/Tencent/plato
算法介紹:https://github.com/Tencent/plato/wiki
代碼示例:https://github.com/Tencent/plato/tree/master/example
總結
騰訊高性能分布式圖計算框架 Plato,已集成了最常用的 Fast Unfolding、LPA 和 HANP 等社團發現算法的高性能實現,可以在分鐘級完成超大規模網絡的社團發現,期待能為業界圖計算的技術進步貢獻一份力量。
參考文獻
M. E. J. Newman, M. Girvan. Finding and Evaluating Community Structure in Networks [ J ].Physical Review E, 2004, 69(2): 026113.
V. D. Blondel, J. L. Guillaume, R. Lambiotter, et al. Fast Unfolding of Community Hierarchies in Large Networks [J]. Journal of Statistical Machanics: Theory and Experiment, 2008, 10: 10008.
U. N. Raghavan, R. Albert, S. Kumara. Near Linear Time Algorithm to DetectCommunity Structures in Large-Scale Networks [J/OL]. Eprint arXiv,2007, 0709:2938. [2012-6-18]. http://www.arXiv.org.
Ian X.Y. Leung, Pan Hui, Pietro Li`o, et al. Towards real-time community detection in large networks [J/OL]. Eprint arXiv, 2009, 0808:2633.[2019-12-18]. http://www.arXiv.org.
S. Fortunato. Community Detection in Graphs [J/OL]. Eprint arXiv. 2009,0906:0612. [2012-12-24]. http://www.arXiv.org.
McSherry, Frank, Michael Isard, and Derek G. Murray. "Scalability! But at what {COST}?." 15th Workshop on Hot Topics in Operating Systems (HotOS {XV}). 2015.
Zhu, Xiaowei, et al. "Gemini: A computation-centric distributed graph processing system." 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16). 2016.
Chen, Rong, et al. "Computation and communication efficient graph processing with distributed immutable view." Proceedings of the 23rd international symposium on High-performance parallel and distributed computing. ACM, 2014.