教你如何將Pandas迭代速度加快150倍?
面對現實吧,Python的速度在與C語言或Go語言相比時,的確引發了不少口水戰。
這讓筆者一段時間以來,一直對Python快速處理任務的能力有所懷疑。
目前,筆者嘗試在Go語言中進行數據科學研究——這是有可能的——但操作起來根本不像在Python中那樣令人愉快,多半是由于語言的靜態特性和數據科學大多是探索性領域。
并不是說用Go語言重寫完成的解決方案不能提高性能,但這是另一篇文章的主題。
迄今為止,筆者至少忽略了Python可以更快地處理任務這一能力。筆者一直飽受目光短淺之苦——這是一種表現為當你只看到一種解決方案時,完全忽視其他方案的存在的綜合征。相信出現這種情況的不只筆者自己。
這就是筆者今天想簡要介紹如何令Pandas每日工作速度更快且更為愉悅的原因。更準確地說,該示例將關注行之間的迭代,并在過程中執行一些數據操作。因此,事不宜遲,一起進入正題。
做一個數據集
把觀點論述清楚最簡單的方法是聲明一個單列數據框對象,其整數值范圍為1到100000:
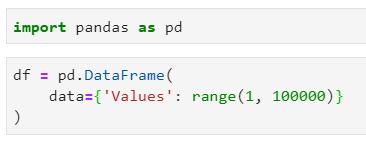
真的不需要任何更為復雜的東西來解決Pandas的速度問題。為驗證一切進展順利,以下是數據集的前幾行和整體形狀:

好了,準備工作已做足,現在一起看看如何遍歷以及如何不遍歷數據框的行。首先介紹如何不進行選擇。
以下是你不應該做的事
啊,筆者一直在使用(和過度使用)如此多的iterrows()方法。它在默認情況下速度很慢,但你知道筆者費心去尋找替代方案的原因(目光短淺)。
為證明你不該使用iterrows()方法在數據框中進行遍歷,筆者會做個快速演示——聲明一個變量并將其初始設置為0——然后在每次迭代時按Values屬性的當前值進行遞增。
如果你想知道%%time魔法函數返回單元格完成所有操作所需的秒數/毫秒數。
一起看看該函數是如何運行的:
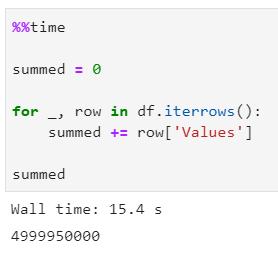
你現在可能會想,用15秒遍歷100000行并遞增一些外部變量的值并不算多。但事實上是——請看下一部分的闡述原因。
以下是你應該做的事
現在有一個神奇的方法能進行挽救——itertuples()。顧名思義,itertuples()循環遍歷數據框的行,然后返回一個命名元組。這就是不能用括號[]訪問這些值,而是需要使用.符號的原因。
現在將演示與幾分鐘前相同的示例,但使用的是itertuples()方法:
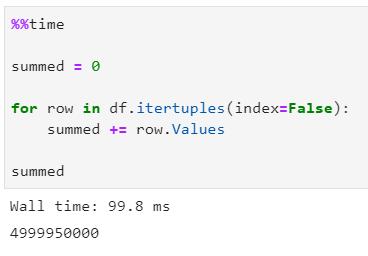
瞧瞧!使用itertuples()進行同樣的運算,速度快了約154倍!現在想象一下你的日常工作場景,你正在處理上百萬條行——itertuples()可以幫你節省大量時間。
在這個簡單的例子中,我們已經見識到對代碼進行的小小改動就能對整體結果產生的巨大影響。
這不意味itertuples()在每個場景下都會比iterrows()快150倍,但在某種程度上這確實意味著每次都會快一些。
感謝閱讀,希望大家有所收獲!