Redis哨兵的配置和原理
哨兵
在一個典型的一主多從的Redis系統中,當主數據庫遇到異常中斷服務后,需要手動選擇一個從數據庫升級為主數據庫,整個過程需要人工介入,難以自動化。
Redis2.8提供了哨兵2.0(2.6提供了1.0,但是問題較多),哨兵顧名思義就是監控Redis系統的運行狀況。它的功能包括一下兩個:
- 監控主數據庫和從數據庫是否正常運行;
- 主數據庫出現故障時自動將從數據庫升級為主數據庫;
哨兵是一個獨立的進行,在一個一主多從的Redis系統中,可以使用多個哨兵監控整個Redis系統,哨兵之間也會互相監控。
配置
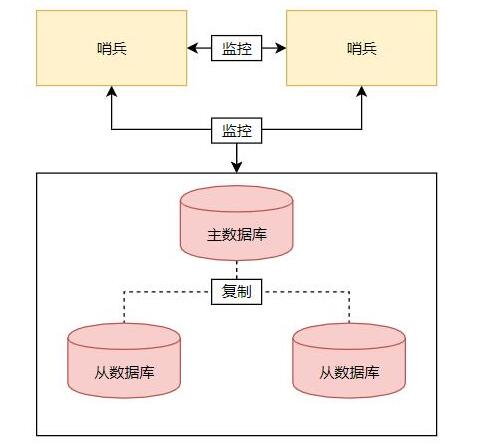
基于前面的一主兩從架構,為他們加入哨兵。
可以在三個redis節點的redis目錄下找到sentinel.conf文件,這個文件就是哨兵的配置文件,修改配置如下:
- sentinel monitor mymaster 192.168.2.101 6379 3
其中:
- mymaster是要監控的主數據庫名字,可以自定義;
- 接下來是主數據庫的ip和端口;
- 最后一個3是指哨兵最低通過票數;
如果你需要后臺啟動,則修改daemonize參數:
- daemonize yes
配置后如果有防火墻,不要忘記打開哨兵的端口,默認是26379。
最后,開啟哨兵:
- redis-sentinel /yourpath/sentinel.conf
做個測試,關閉主數據庫(192.168.2.101)后,等待30秒(默認30秒):
- 哨兵將從數據庫中的一個節點升級成主數據庫(192.168.2.102);
- 將另一個從數據庫(192.168.2.103)的主數據庫(192.168.2.101)切換到新的主數據庫(192.168.2.102);
隨后啟動剛才關閉的主數據庫(192.168.2.101),哨兵自動將其轉為從數據庫;
原理
1. 監控過程
哨兵啟動后,會與要監控的主數據庫建立兩條連接:
- 一條用來用來訂閱__sentinel__:hello頻道以獲取其他哨兵節點的信息;
- 另一條用來定期向主數據庫發送INFO等命令來獲取主數據庫本身的信息;
在和主數據庫建立連接后,哨兵會定時執行下面3個操作:
- 每10秒哨兵會向主數據庫和從數據庫發送INFO命令;
- 每2秒哨兵會向主數據庫和從數據庫的__sentinel__:hello頻道發送自己的信息;
- 每1秒哨兵會向主數據庫和從數據庫和其他哨兵發送PING命令;
第一個操作是發送INFO命令,目的是獲取主數據庫的信息,以及主數據庫的從數據庫的信息,從而實現新節點的自動發現,并對從數據庫也建立兩條連接。
第二個操作是訂閱__sentinel__:hello頻道,并發送哨兵本身的信息,與同樣監控該數據庫的其他哨兵分享自己的信息,同時也能識別哨兵是否是新哨兵。哨兵與哨兵之間也會建立一個鏈接,用來發送PING命令;
第三個操作是發送PING命令,在發現了從數據庫和其他哨兵后,要做的就是定時監控Redis服務是否停止,時間間隔與配置文件中的down-after-milliseconds有關,當這個值小于1秒時,哨兵會每隔該值的時間發送PING命令,當這個值大于1秒時,哨兵會每隔1秒發送一次PING命令。
配置方式是在sentinel.conf文件中加入:
- sentinel down-after-milliseconds mymaster 600 # 600毫秒發送一個PING
當超過down-after-milliseconds時,如果PING的數據庫未回復,則哨兵認為其主觀下線。主觀下線可以理解為當前的哨兵認為該節點下線了。
如果該節點是主數據庫,則哨兵們會進一步判斷是否需要對其進行故障修復:
哨兵會發送SENTINEL is-master-down-by-addr命令詢問其他哨兵,判斷他們是否也認為該主數據庫下線,如果達到quorum參數,也就是我們在配置哨兵時的命令:
- sentinel monitor mymaster 192.168.2.101 6379 3
的最后一個參數3,哨兵們會認為這個主數據庫客觀下線,并選舉一個領頭哨兵對主從系統發起故障恢復。
2. 領頭哨兵選舉
要進行故障恢復,則需要選舉出一個領頭哨兵,領頭哨兵的選擇算法是Raft算法,具體過程如下:
- 發現主數據庫客觀下線的哨兵節點(A節點)想每個哨兵節點發送命令,要求對方選擇自己成為領頭哨兵;
- 如果目標哨兵節點沒有選擇過其他人,則會同意將A設置成領頭哨兵;
- 如果A發現超過半數且超過quorum參數個哨兵節點同意選擇自己,則A成功成為領頭哨兵;
- 當有多個哨兵同時參選,則會出現沒有任何節點當選的可能,此時每個參選節點將等待一個隨即時間重新發起競選,直到選舉成功。
3. 故障恢復
選擇出領頭哨兵后,會把從數據庫中的一個挑選出來升級為主數據庫:
- 所有先線的從數據庫中,選擇優先級最高的,優先級可以通過slave-priority來設置;
- 如果有多個一樣優先級的從數據庫,則復制的命令偏移量越大,越優先(與down掉的主數據庫最接近);
- 如果還有多個備選,則選擇運行ID較小的(運行ID不會重復);
選擇好節點后,領頭哨兵將想這個節點發送slaveof no one,升級他為主數據庫。
然后想其他從數據庫發送slaveof命令切換主數據庫。
最后更新內部的記錄,將已經停止服務的舊的主數據庫更新為新的主數據庫的從數據庫,當其回復后自動以從數據庫的身份加入到主從架構中。
哨兵部署
哨兵的推薦部署方案:
- 為每個節點(無論是主數據庫還是從數據庫)都部署一個哨兵;
- 使每個哨兵與其對應的節點的網絡環境相同或相近;
設置quorum的值為N/2+1,這樣使得只有當大部分哨兵統一后才會選擇領頭哨兵進行故障恢復。