













HDFS的讀寫流程和一些重要策略
前情回顧
在闡述HDFS最基礎的理論知識那一篇讀完后,這一篇是HDFS的主要工作流程,和一些較為有用的策略
補充一個問題,就是當我們 NameNode 掛掉,SecondaryNameNode作為新的NameNode上位時,它確實可以根據fsimage.ckpt把一部分元數據加載到內存,可是如果這時還有一部分操作日志在edits new中沒有執行怎么辦?
這時候有一個解決方案就是利用一個network fileSystem來解決,比如說集群中有一個服務器安裝了一個nfs server,而在NameNode上再安裝一個nfs client,此時客戶端向HDFS寫數據時,同時把向edits new中寫的數據寫一份到nfs server中,SecondaryNamenode就可以通過這個nfs server來獲取此時斷層的數據了
其他似乎也沒啥可多說的,讓我們直奔主題吧
以往鏈接
從零開始的大數據(一) --- HDFS的知識概述(上)
一、HDFS的讀流程
之后的內容會圍繞下圖開始
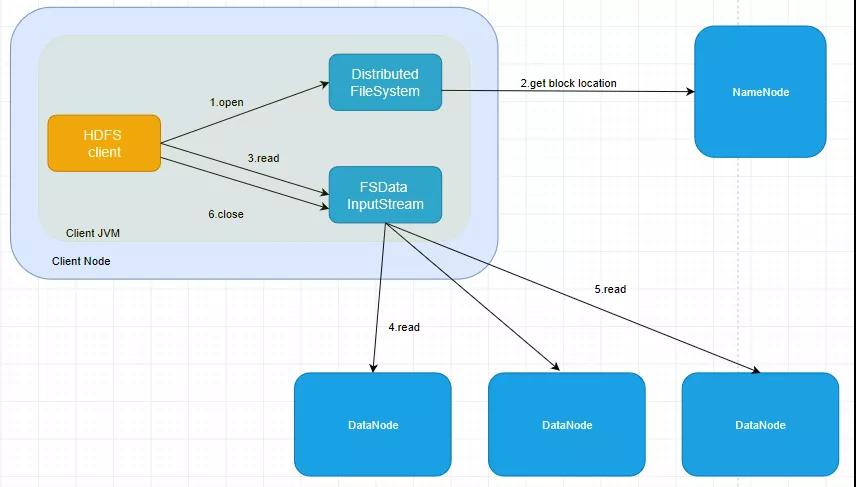
1.認識角色
簡單過一下圖里面的角色,最大塊的是一個client node,也就是說,這個節點上運行著客戶端,如果實在是沒搞清楚哪個是客戶端,那也很簡單,平時沒事就執行
hadoop fs -ls /
這個命令的機器,那就是客戶端了,其他就是NameNode和DataNode,在client node上運行著一個JVM虛擬機,讓HDFS client跑起來
2.步驟分析
① HDFS client調用文件系統的open方法
Distributed FileSystem顧名思義是一個分布式文件系統,它會通過RPC的方式遠程過程調用NameNode里的open方法,這個open方法有什么作用呢,就是獲取要讀的文件的file block locations,也就是文件的block的位置,在上一講我們也已經提到了,一個文件是會分割成128M一塊的大小分別存儲在各個數據節點的。
同時在執行open方法時,客戶端會產生一個FSData InputStream的一個輸入流對象(客戶端讀數據是從外部讀回來的)
② FSData InputStream讀數據
HDFS client調用FSData InputStream的read方法,同上也是遠程過程調用DataNode的read方法,此時的讀取順序是由近到遠,就是DataNode和client node的距離,這里所指的距離是一種物理距離,判定可以參考上一篇文章中機架的概念。
在聯系上DataNode并成功讀取后,關閉流就走完了一個正常的流程。
而且補充一下就是,上面Distributed FileSystem所調用的get block locations的方法只會返回部分數據塊,get block locations會分批次地返回block塊的位置信息。讀block塊理論上來說是依次讀,當然也可以通過多線程的方式實現同步讀。
③ 容錯機制
1.如果client從DataNode上讀取block時網絡中斷了如何解決?
此時我們會找到block另外的副本(一個block塊有3個副本,上一篇已經說過了),并且通過FSData InputStream進行記錄,以后就不再從中斷的副本上讀了。
2.如果一個DataNode掛掉了怎么辦?
在上一篇中我們提到了一個HDFS的心跳機制,DataNode會隔一小時向NameNode匯報blockReport,比如現在的情況是,block1的三個副本分別存儲在DataNode1,2,3上,此時DataNode1掛掉了。NameNode得知某個block還剩2個副本,此時攜帶這block的其余兩個副本的DataNode2,3在向NameNode報告時,NameNode就會對它們中的某一個返回一個指令,把block1復制一份給其他正常的節點。讓block1恢復成原本的3個副本。
3.client如何保證讀取數據的完整性
因為從DataNode上讀數據是通過網絡來讀取的,這說明會存在讀取過來的數據是不完整的或者是錯誤的情況。
DataNode上存儲的不僅僅是數據,數據還附帶著一個叫做checkSum檢驗和(CRC32算法)的概念,針對于任何大小的數據塊計算CRC32的值都是32位4個字節大小。此時我們的FSData InputStream向DataNode讀數據時,會將與這份數據對應的checkSum也一并讀取過來,此時FSData InputStream再對它讀過來的數據做一個checkSum,把它與讀過來的checkSum做一個對比,如果不一致,就重新從另外的DataNode上再次讀取。
4.上一個問題完成后工作
FSData InputStream會告訴NameNode,這個DataNode上的這個block有問題了,NameNode收到消息后就會再通過心跳機制通知這個DataNode刪除它的block塊,然后再用類似2的做法,讓正常的DataNode去copy一份正常的block數據給其它節點,保證副本數為3
代碼簡單示例(可跳過)
- try {
- //
- String srcFile = "hdfs://node-01:9000/data/hdfs01.mp4";
- Configuration conf = new Configuration();
- FileSystem fs = FileSystem.get(URI.create(srcFile),conf);
- FSDataInputStream hdfsInStream = fs.open(new Path(srcFile));
- BufferedOutputStream outputStream = new BufferedOutputStream(new FileOutputStream("/home/node1/hdfs02.mp4"));
- IOUtils.copyBytes(hdfsInStream, outputStream, 4096, true);
- } catch (IOException e) {
- e.printStackTrace();
- }
二、HDFS寫流程
寫流程我們會按照下圖來進行講解,比讀數據更加復雜一丟丟,角色基本沒有改變所以就不詳細介紹了
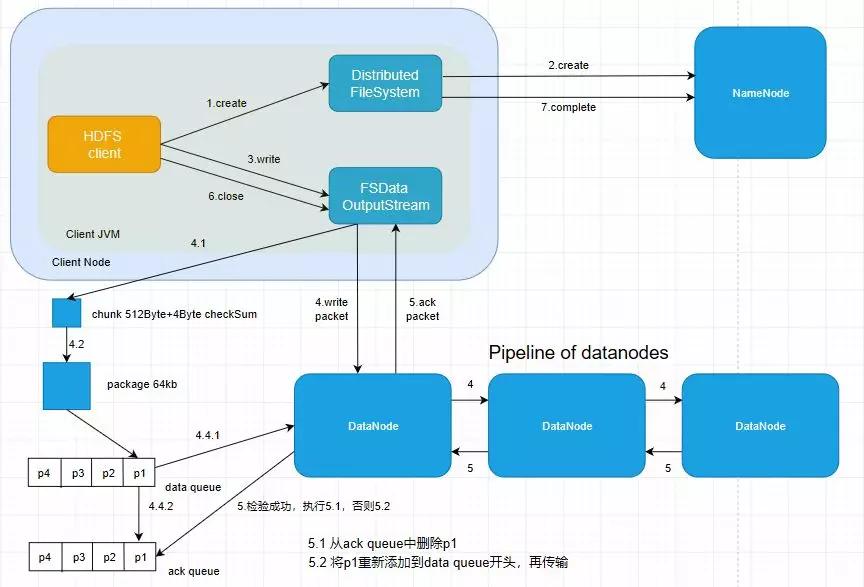
客戶端向HDFS寫數據的時候是把文件分塊存儲在HDFS的各個節點上,而規定了存儲位置的是NameNode,所以Client node在存儲文件時需要先和NameNode進行聯系讓它進行分配。
步驟分析
① 客戶端調用分布式文件系統的create方法
和上面讀的方法類似,不過這次調用的是Distributed FileSystem的create方法,此時也是通過遠程調用NameNode的create方法
此時NameNode會進行的舉措
1.檢測自己是否正常運行
2.判斷要創建的文件是否存在
3.client是否有創建文件的權限
4.對HDFS做狀態的更改需要在edits log寫日志記錄
② 客戶端調用輸出流的write方法
create方法的返回值是一個OutputStream對象,為什么是output,因為是由HDFS去往DataNode去寫數據,此時HDFS會調用這個OutputStream的write方法
但是有個問題,此時我們還不知道我們的這些block塊要分別存放于哪些節點上,所以此時FSData OutputStream就要再和NameNode交互一下,遠程過程調用NameNode的addBlock方法,這個方法返回的是各個block塊分別需要寫在哪3個DataNode上面。
此時OutputStream就完整得知了數據和數據該往哪里去寫了
③ 具體的寫流程分析
請看流程4.1,chunk是一個512字節大小的數據塊,寫數據的過程中數據是一字節一字節往chunk那里寫的,當寫滿一個chunk后,會計算一個checkSum,這個checkSum是4個字節大小,計算完成后一并放入chunk,所以整一個chunk大小其實是512字節+4字節=516字節。
上述步驟結束后,一個chunk就會往package里面放,package是一個64kb大小的數據包,我們知道64kb = 64 * 1024字節,所以這個package可以放非常多的chunk。
此時一個package滿了之后,會把這個packjage放到一個data queue隊列里面,之后會陸續有源源不斷的package傳輸過來,圖中用p1,p2···等表示
這時候開始真正的寫數據過程
data queue中的package往數據節點DataNode上傳輸,傳輸的順序按照NameNode的addBlock()方法返回的列表依次傳輸
(ps:傳輸的類為一個叫做dataStreamer的類,而且其實addBlock方法返回的列表基本是按照離客戶端物理距離由近到遠的順序的)
往DataNode上傳輸的同時也往確認隊列ack queue上傳輸
針對DataNode中傳輸完成的數據做一個checkSum,并與原本打包前的checkSum做一個比較
校驗成功,就從確認隊列ack queue中刪除該package,否則該package重新置入data queue重傳
補充:1.以上邏輯歸屬于FSData OutputStream的邏輯
2.雖然本身一個block為128M,而package為64Kb,128M對于網絡傳輸過程來說算是比較大,拆分為小包是為了可靠傳輸
3.網絡中斷時的舉措:HDFS會先把整個pineline關閉,然后獲取一個已存在的完整的文件的version,發送給NameNode后,由NameNode通過心跳機制對未正確傳輸的數據下達刪除命令
4.如果是某個DataNode不可用,在1中我們也提到過了,通過心跳機制會通知其余的可用DataNode的其中一個進行copy到一個可用節點上
④ 寫入結束后的行動
完成后通過心跳機制NameNode就可以得知副本已經創建完成,再調用addBlock()方法寫之后的文件。
⑤ 流程總結
1.client端調用Distributed FileSystem的create,此時是遠程調用了NameNode的create,此時NameNode進行4個操作,檢測自己是否正常,文件是否存在,客戶端的權限和寫日志
2.create的返回值為一個FSData OutputStream對象,此時client調用流的write方法,和NameNode進行連接,NameNode的addBlock方法返回塊分配的DataNode列表
3.開始寫數據,先寫在chunk,后package,置入data queue,此時兩個操作,向DataNode傳輸,和放入ack queue,DataNode傳輸結束會檢測checkSum,成功就刪除ack queue的package,否則放回data queue重傳
4.結束后關閉流,告訴NameNode,調用complete方法結束
簡單代碼示例(可跳過)
- String source="/home/node1/hdfs01.mp4"; //linux中的文件路徑,demo存在一定數據
- //先確保/data目錄存在
- String destination="hdfs://node-01:9000/data/hdfs01.mp4";//HDFS的路徑
- InputStream in = null;
- try {
- in = new BufferedInputStream(new FileInputStream(source));
- //HDFS讀寫的配置文件
- Configuration conf = new Configuration();
- FileSystem fs = FileSystem.get(URI.create(destination),conf);
- //調用Filesystem的create方法返回的是FSDataOutputStream對象
- //該對象不允許在文件中定位,因為HDFS只允許一個已打開的文件順序寫入或追加
- OutputStream out = fs.create(new Path(destination));
- IOUtils.copyBytes(in, out, 4096, true);
- } catch (FileNotFoundException e) {
- System.out.println("exception");
- e.printStackTrace();
- } catch (IOException e) {
- System.out.println("exception1");
- e.printStackTrace();
- }
3.Hadoop HA高可用
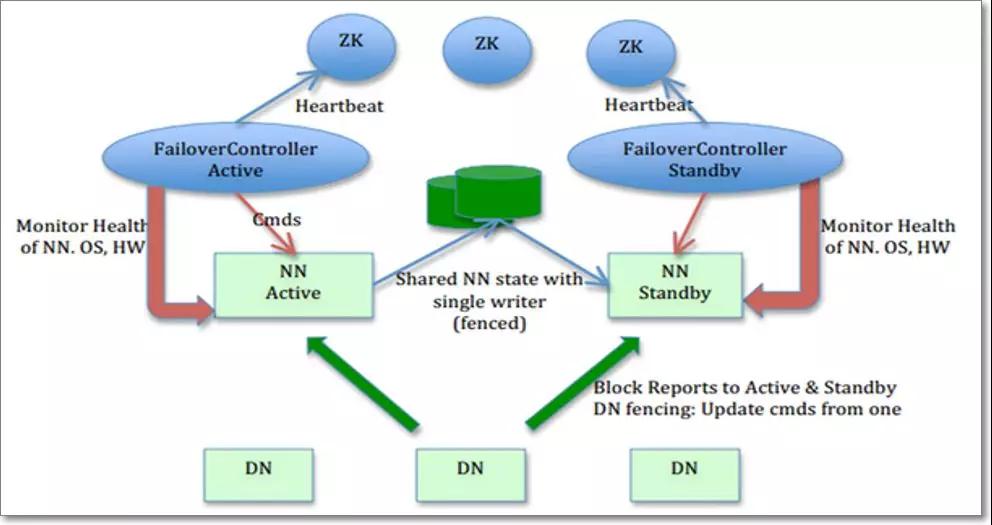
之前已經提到過,元數據是放在NameNode的內存中的,當元數據丟失,造成服務不可用,這時候就需要時間來恢復。HA就可以讓用戶感知不到這種問題。這需要yarn,MapReduce,zookeeper的支持
僅有一個NameNode時,當NameNode掛掉就需要把fsimage讀到內存,然后把edits log所記錄的日志重新執行一遍,元數據才能恢復,而這種做法需要大量的時間
所以解決方案就在于我們要花大量時間來恢復元數據metaData,所以解決的方案就是讓集群瞬間變回可用狀態即可。
通過設置一個stand by的NameNode,并和主NameNode的元數據保持一致,圖中綠色的區域表示一個共享存儲,主NameNode的元數據會傳輸至共享存儲里面,讓stand by的NameNode進行同步。
下面的DataNode會同時往兩個NameNode發送blockReport,因為讀取DataNode的塊信息并不會很快,所以為了保證在active掛掉的時候,standby能立刻頂上位置,所以要事先讀取塊信息,同時這也是方便standby來構建它的元數據信息的途徑。
active掛掉后讓stand by立刻生效的機制是上面的FailoverControllerActive實現的,簡稱zkfc,它會定時ping主NameNode,如果發現NameNode掛掉,就會通知我們的zookeeper集群,然后集群的另一個FailoverControllerActive就會通知stand by。
4.Hadoop聯邦
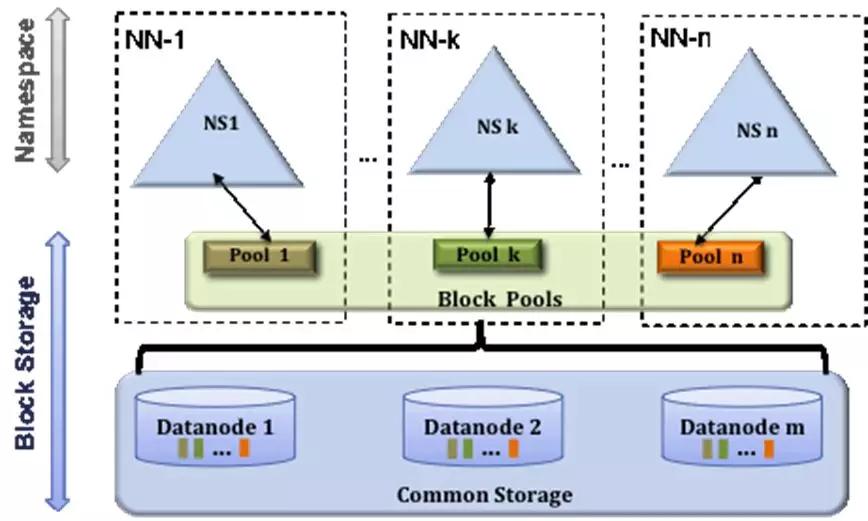
集群中的元數據會保存在NameNode的內存中,而這些元數據每份占用約150字節,對于一個擁有大量文件的集群來說,因為NameNode的metaData被占滿,DataNode就無法寫入了,聯邦就可以幫助系統突破文件數上限
其實就是布置了多個NameNode來共同維護集群,來增加namespace,而且分散了NameNode的訪問壓力,而且客戶端的讀寫互不影響。就是擴展性,高吞吐和隔離性。
5.HDFS存儲大量小文件
和剛剛的聯邦的介紹時的情況一樣,文件數量(每個文件元數據150byte)會影響到NameNode的內存
方案1:HAR文件
方案其實就是通過一個MR程序把許多小文件合并成一個大文件,需要啟動Yarn
- # 創建archive文件
- hadoop archive -archiveName test.har -p /testhar -r 3 th1 th2 /outhar # 原文件還存在,需手動刪除
- # 查看archive文件
- hdfs dfs -ls -R har:///outhar/test.har
- # 解壓archive文件
- hdfs dfs -cp har:///outhar/test.har/th1 hdfs:/unarchivef
- hadoop fs -ls /unarchivef # 順序
- hadoop distcp har:///outhar/test.har/th1 hdfs:/unarchivef2 # 并行,啟動MR
方案2:Sequence File方案
其核心是以文件名為key,文件內容為value組織小文件。10000個100KB的小文件,可以編寫程序將這些文件放到一個SequenceFile文件,然后就以數據流的方式處理這些文件,也可以使用MapReduce進行處理。一個SequenceFile是可分割的,所以MapReduce可將文件切分成塊,每一塊獨立操作。不像HAR,SequenceFile支持壓縮。在大多數情況下,以block為單位進行壓縮是最好的選擇,因為一個block包含多條記錄,壓縮作用在block之上,比reduce壓縮方式(一條一條記錄進行壓縮)的壓縮比高.把已有的數據轉存為SequenceFile比較慢。比起先寫小文件,再將小文件寫入SequenceFile,一個更好的選擇是直接將數據寫入一個SequenceFile文件,省去小文件作為中間媒介.
此方案的代碼不是很重要,所以就直接省略了,實在是想看看長啥樣的可以艾特我
finally
到此HDFS的內容就差不多了,希望對你會有所幫助。之后會繼續往下分享MapReduce,帶你走完整個大數據的流程,感興趣的朋友可以持續關注下,謝謝。











