













為什么 MongoDB 使用 B 樹?
為什么這么設計(Why's THE Design)是一系列關于計算機領域中程序設計決策的文章,我們在這個系列的每一篇文章中都會提出一個具體的問題并從不同的角度討論這種設計的優缺點、對具體實現造成的影響。
概述
MongoDB 是一個通用的、面向文檔的分布式數據庫[^1],這是官方對 MongoDB 介紹。區別于傳統的關系型數據庫 MySQL、Oracle 和 SQL Server,MongoDB 最重要的一個特點就是『面向文檔』,由于數據存儲方式的不同,對外提供的接口不再是被大家熟知的 SQL,所以被劃分成了 NoSQL,NoSQL 是相對 SQL 而言的,很多我們耳熟能詳的存儲系統都被劃分成了 NoSQL,例如:Redis、DynamoDB[^2] 和 Elasticsearch 等。
sql-and-nosq
NoSQL 經常被理解成沒有 SQL(Non-SQL)或者非關系型(Non-Relational)[^3],不過也有人將其理解成不只是 SQL(Not Only SQL)[^4],深挖這個詞的含義和起源可能沒有太多意義,這種二次解讀很多時候都是為營銷服務的,我們只需要知道 MongoDB 對數據的存儲方式與傳統的關系型數據庫完全不同。
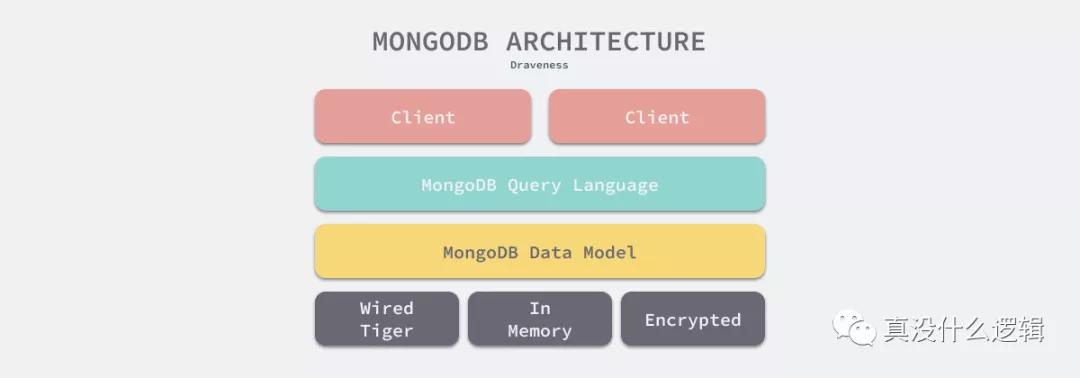
MongoDB 的架構與 MySQL 非常類似,它們底層都使用了可插拔的存儲引擎以滿足用戶的不同需求,用戶可以根據數據特征選擇不同的存儲引擎,最新版本的 MongoDB 使用了 WiredTiger 作為默認的存儲引擎[^5]。
mongodb-architecture
作為 MongoDB 默認的存儲引擎,WiredTiger 使用 B 樹作為索引底層的數據結構,但是除了 B 樹之外,它還支持 LSM 樹作為可選的底層存儲結構,LSM 樹的全稱是 Log-structured merge-tree,你可以在 MongoDB 中使用如下所示的命令創建一個基于 LSM 樹的集合(Collection)[^6]:
- db.createCollection(
- "posts",
- { storageEngine: { wiredTiger: {configString: "type=lsm"}}}
- )
我們在這篇文章中不僅會介紹 MongoDB 的默認存儲引擎 WiredTiger 為什么選擇使用 B 樹而不是 B+ 樹,還會對 B 樹和 LSM 樹之間的性能和應用場景進行比較,幫助各位讀者更全面地理解今天的問題。
設計
既然要比較兩個不同數據結構與 B 樹的差別,那么在這里我們將分兩個小節分別介紹 B+ 樹和 LSM 樹為什么沒有成為 WiredTiger 默認的數據結構:
- 作為非關系型的數據庫,MongoDB 對于遍歷數據的需求沒有關系型數據庫那么強,它追求的是讀寫單個記錄的性能;
- 大多數 OLTP 的數據庫面對的都是讀多寫少的場景,B 樹與 LSM 樹在該場景下有更大的優勢;
上述的兩個場景都是 MongoDB 需要面對和解決的,所以我們會在這兩個常見場景下對不同的數據結構進行比較。
非關系型
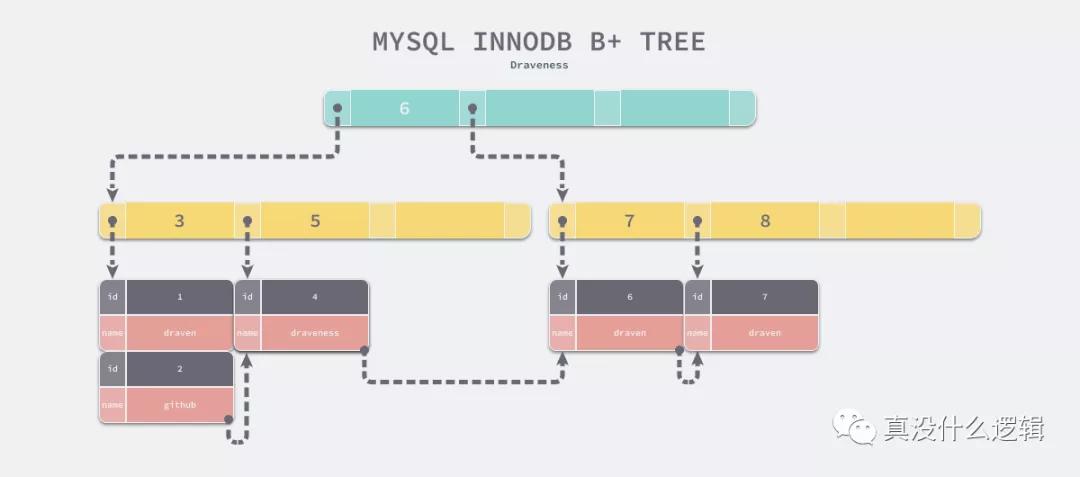
我們在上面其實已經多次提到了 MongoDB 是非關系型的文檔數據庫,它完全拋棄了關系型數據庫那一套體系之后,在設計和實現上就非常自由,它不再需要遵循 SQL 和關系型數據庫的體系,可以更自由對特定場景進行優化,而在 MongoDB 假設的場景中遍歷數據并不是常見的需求。
mysql-innodb-b-plus-tree
MySQL 中使用 B+ 樹是因為 B+ 樹只有葉節點會存儲數據,將樹中的每一個葉節點通過指針連接起來就能實現順序遍歷,而遍歷數據在關系型數據庫中非常常見,所以這么選擇是完全沒有問題的[^7]。
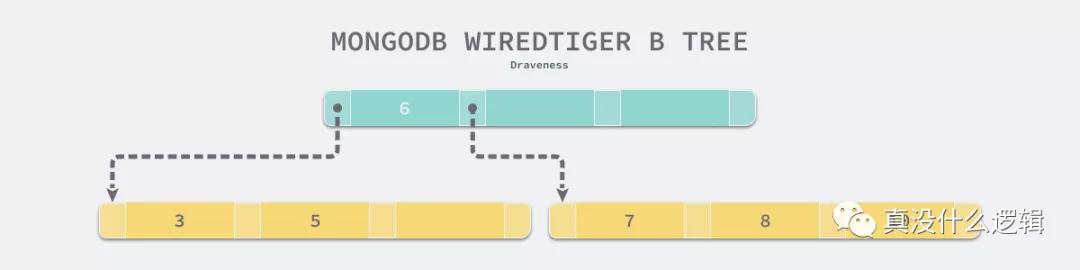
MongoDB 和 MySQL 在多個不同數據結構之間選擇的最終目的就是減少查詢需要的隨機 IO 次數,MySQL 認為遍歷數據的查詢是常見的,所以它選擇 B+ 樹作為底層數據結構,而舍棄了通過非葉節點存儲數據這一特性,但是 MongoDB 面對的問題就不太一樣了:
mongodb-wiredtiger-b-tree
雖然遍歷數據的查詢是相對常見的,但是 MongoDB 認為查詢單個數據記錄遠比遍歷數據更加常見,由于 B 樹的非葉結點也可以存儲數據,所以查詢一條數據所需要的平均隨機 IO 次數會比 B+ 樹少,使用 B 樹的 MongoDB 在類似場景中的查詢速度就會比 MySQL 快。這里并不是說 MongoDB 并不能對數據進行遍歷,我們在 MongoDB 中也可以使用范圍來查詢一批滿足對應條件的記錄,只是需要的時間會比 MySQL 長一些。
- SELECT * FROM comments WHERE created_at > '2019-01-01'
很多人看到遍歷數據的查詢想到的可能都是如上所示的范圍查詢,然而在關系型數據庫中更常見的其實是如下所示的 SQL —— 查詢外鍵或者某字段等于某一個值的全部記錄:
- SELECT * FROM comments WHERE post_id = 1
上述查詢其實并不是范圍查詢,它沒有使用 >、< 等表達式,但是它卻會在 comments 表中查詢一系列的記錄,如果 comments 表上有索引 post_id,那么這個查詢可能就會在索引中遍歷相應索引,找到滿足條件的 comment,這種查詢也會受益于 MySQL B+ 樹相互連接的葉節點,因為它能減少磁盤的隨機 IO 次數。
MongoDB 作為非關系型的數據庫,它從集合的設計上就使用了完全不同的方法,如果我們仍然使用傳統的關系型數據庫的表設計思路來思考 MongoDB 中集合的設計,寫出類似如上所示的查詢會帶來相對比較差的性能:
- db.comments.find( { post_id: 1 } )
因為 B 樹的所有節點都能存儲數據,各個連續的節點之間沒有很好的辦法通過指針相連,所以上述查詢在 B 樹中性能會比 B+ 樹差很多,但是這并不是一個 MongoDB 中推薦的設計方法,更合適的做法其實是使用嵌入文檔,將 post 和屬于它的所有 comments 都存儲到一起:
- {
- "_id": "...",
- "title": "為什么 MongoDB 使用 B 樹",
- "author": "draven",
- "comments": [
- {
- "_id": "...",
- "content": "你這寫的不行"
- },
- {
- "_id": "...",
- "content": "一樓說的對"
- }
- ]
- }
使用上述方式對數據進行存儲時就不會遇到 db.comments.find( { post_id: 1 } ) 這樣的查詢了,我們只需要將 post 取出來就會獲得相關的全部評論,這種區別于傳統關系型數據庫的設計方式是需要所有使用 MongoDB 的開發者重新思考的,這也是很多人使用 MongoDB 后卻發現性能不如 MySQL 的最大原因 —— 使用的姿勢不對。
有些讀者到這里可能會有疑問了,既然 MongoDB 認為查詢單個數據記錄遠比遍歷數據的查詢更加常見,那為什么不使用哈希作為底層的數據結構呢?
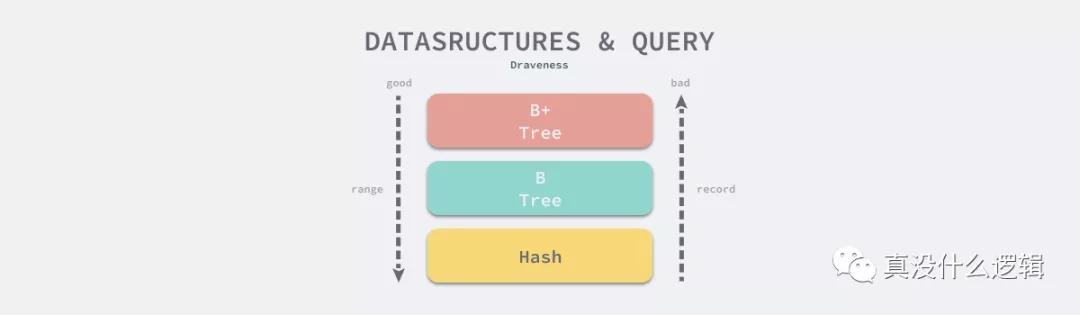
datastructures-and-query
如果我們使用哈希,那么對于所有單條記錄查詢的復雜度都會是 O(1),但是遍歷數據的復雜度就是 O(n);如果使用 B+ 樹,那么單條記錄查詢的復雜度是 O(log n),遍歷數據的復雜度就是 O(log n) + X,這兩種不同的數據結構一種提供了最好的單記錄查詢性能,一種提供了最好的遍歷數據的性能,但是這都不能滿足 MongoDB 面對的場景 —— 單記錄查詢非常常見,但是對于遍歷數據也需要有相對較好的性能支持,哈希這種性能表現較為極端的數據結構往往只能在簡單、極端的場景下使用。
讀多寫少
LSM 樹是一個基于磁盤的數據結構,它設計的主要目的是為長期需要高頻率寫入操作的文件提供低成本的索引機制[^8]。無論是 B 樹還是 B+ 樹,向這些數據結構組成的索引文件中寫入記錄都需要執行的磁盤隨機寫,LSM 樹的優化邏輯就是犧牲部分的讀性能,將隨機寫轉換成順序寫以優化數據的寫入。
我們在這篇文章不會詳細介紹為什么 LSM 樹有著較好的寫入性能,我們只是來分析為什么 WiredTiger 使用 B 樹作為默認的數據結構。WiredTiger 對 LSM 樹和 B 樹的性能進行了讀寫吞吐量的基準測試[^9],通過基準測試得到了如下圖所示的結果,從圖中的結果我們能發現:
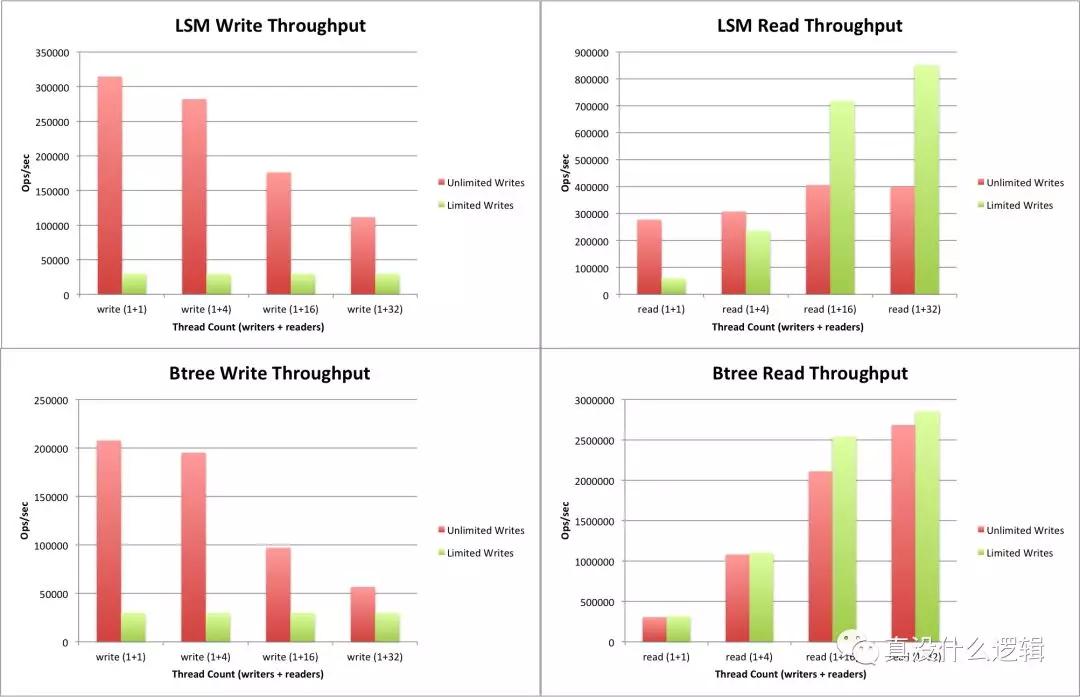
LSM_btree_Throughput
在不限制寫入的情況下;
- LSM 樹的寫入性能是 B 樹的 1.5 ~ 2 倍;
- LSM 樹的讀取性能是 B 樹的 1/6 ~ 1/3;
在限制寫入的情況下;
- LSM 樹的寫入性能與 B 樹的性能基本持平;
- LSM 樹的讀取性能是 B 樹的 1/4 ~ 1/2;
在限制寫入的情況下,每秒會寫入 30,000 條數據,從這里的分析結果來看,無論那種情況下 B 樹的讀取性能是遠好于 LSM 樹的。對于大多數的 OLTP 系統來說,系統的查詢會是寫的很多倍,所以 LSM 樹在寫入方面的優異表現也沒有辦法讓它成為 MongoDB 默認的數據格式。
總結
應用場景永遠都是系統設計時首先需要考慮的問題,作為 NoSQL 的 MongoDB,其目標場景就與更早的數據庫就有著比較大的差異,我們來簡單總結一下 MongoDB 最終選擇使用 B 樹的兩個原因:
MySQL 使用 B+ 樹是因為數據的遍歷在關系型數據庫中非常常見,它經常需要處理各個表之間的關系并通過范圍查詢一些數據;但是 MongoDB 作為面向文檔的數據庫,與數據之間的關系相比,它更看重以文檔為中心的組織方式,所以選擇了查詢單個文檔性能較好的 B 樹,這個選擇對遍歷數據的查詢也可以保證可以接受的時延;
LSM 樹是一種專門用來優化寫入的數據結構,它將隨機寫變成了順序寫顯著地提高了寫入性能,但是卻犧牲了讀的效率,這與大多數場景需要的特點是不匹配的,所以 MongoDB 最終還是選擇讀取性能更好的 B 樹作為默認的數據結構;
到最后,我們還是來看一些比較開放的相關問題,有興趣的讀者可以仔細思考一下下面的問題:
BigTable、LevelDB 和 HBase 的應用場景都是什么?它們的讀寫比例有多少?為什么使用 LSM 樹作為底層的數據結構?
在設計表結構時,MongoDB 與傳統的關系型數據庫有哪些區別?
如果對文章中的內容有疑問或者想要了解更多軟件工程上一些設計決策背后的原因,可以在博客下面留言,作者會及時回復本文相關的疑問并選擇其中合適的主題作為后續的內容。
[^1]: MongoDB 官方網站 The database for modern applications https://www.mongodb.com/
[^2]: 分布式鍵值存儲 Dynamo 的實現原理 https://draveness.me/dynamo
[^3]: NoSQL 維基百科 https://en.wikipedia.org/wiki/NoSQL
[^4]: NoSQL (Not Only SQL database) https://searchdatamanagement.techtarget.com/definition/NoSQL-Not-Only-SQL
[^5]: 『淺入淺出』MongoDB 和 WiredTiger https://draveness.me/mongodb-wiredtiger
[^6]: MongoDB 中的集合(Collection)與 MySQL 中的表(Table)是差不多的概念
[^7]: 為什么 MySQL 使用 B+ 樹 · Why's THE Design? https://draveness.me/whys-the-design-mysql-b-plus-tree
[^8]: The Log-Structured Merge-Tree (LSM-Tree), Patrick O'Neil, Edward Cheng, Dieter Gawlick, Elizabeth O'Neil https://www.cs.umb.edu/~poneil/lsmtree.pdf
[^9]: Btree vs LSM https://github.com/wiredtiger/wiredtiger/wiki/Btree-vs-LSM

















