Kubernetes用了,延遲高了10倍,問題在哪?

當我們團隊將業務遷移至 Kubernetes 之后,一旦出現問題,總有人覺得“這是遷移之后的陣痛”,并把矛頭指向 Kubernetes,但最終事實證明犯錯的并不是 Kubernetes。雖然文章并不涉及關于 Kubernetes 的突破性啟示,但我認為內容仍值得各位管理復雜系統的朋友借鑒。
近期,我所在的團隊將一項微服務遷移到中央平臺。這套中央平臺捆綁有 CI/CD,基于 Kubernetes 的運行時以及其他功能。這項演習也將作為先頭試點,用于指導未來幾個月內另外 150 多項微服務的進一步遷移。而這一切,都是為了給西班牙的多個主要在線平臺(包括 Infojobs、Fotocasa 等)提供支持。
在將應用程序部署到 Kubernetes 并路由一部分生產流量過去后,情況開始發生變化。Kubernetes 部署中的請求延遲要比 EC2 上的高出 10 倍。如果不找到解決辦法,不光是后續微服務遷移無法正常進行,整個項目都有遭到廢棄的風險。
為什么 Kubernetes 中的延遲要遠高于 EC2?
為了查明瓶頸,我們收集了整個請求路徑中的指標。這套架構非常簡單,首先是一個 API 網關(Zuul),負責將請求代理至運行在 EC2 或者 Kubernetes 中的微服務實例。在 Kubernetes 中,我們僅代表和 NGINX Ingress 控制器,后端則為運行有基于 Spring 的 JVM 應用程序的 Deployment 對象。
- EC2
- +---------------+
- | +---------+ |
- | | | |
- +-------> BACKEND | |
- | | | | |
- | | +---------+ |
- | +---------------+
- +------+ |
- ublic | | |
- -------> ZUUL +--+
- raffic | | | Kubernetes
- +------+ | +-----------------------------+
- | | +-------+ +---------+ |
- | | | | xx | | |
- +-------> NGINX +------> BACKEND | |
- | | | xx | | |
- | +-------+ +---------+ |
- +-----------------------------+
問題似乎來自后端的上游延遲(我在圖中以「xx」進行標記)。將應用程序部署至 EC2 中之后,系統大約需要 20 毫秒就能做出響應。但在 Kubernetes 中,整個過程卻需要 100 到 200 毫秒。
我們很快排除了隨運行時間變化而可能出現的可疑對象。JVM 版本完全相同,而且由于應用程序已經運行在 EC2 容器當中,所以問題也不會源自容器化機制。另外,負載強度也是無辜的,因為即使每秒只發出 1 項請求,延遲同樣居高不下。另外,GC 暫停時長幾乎可以忽略不計。
我們的一位 Kubernetes 管理員詢問這款應用程序是否具有外部依賴項,因為 DNS 解析之前就曾引起過類似的問題,這也是我們目前找到的可能性最高的假設。
假設一:DNS 解析
在每一次請求時,我們的應用程序都像域中的某個 AWS ElasticSearch 實例(例如 elastic.spain.adevinta.com)發出 1 到 3 條查詢。我們在容器中添加了一個 shell,用于驗證該域名的 DNS 解析時間是否過長。
來自容器的 DNS 查詢結果:
- [root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
- ;; Query time: 22 msec
- ;; Query time: 22 msec
- ;; Query time: 29 msec
- ;; Query time: 21 msec
- ;; Query time: 28 msec
- ;; Query time: 43 msec
- ;; Query time: 39 msec
來自運行這款應用程序的 EC2 實例的相同查詢結果:
- bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
- ;; Query time: 77 msec
- ;; Query time: 0 msec
- ;; Query time: 0 msec
- ;; Query time: 0 msec
- ;; Query time: 0 msec
前者的平均解析時間約為 30 毫秒,很明顯,我們的應用程序在其 ElasticSearch 上造成了額外的 DNS 解析延遲。
但這種情況非常奇怪,原因有二:
- Kubernetes 當中已經包含大量與 AWS 資源進行通信的應用程序,而且都沒有出現延遲過高的情況。因此,我們必須弄清引發當前問題的具體原因。
- 我們知道 JVM 采用了內存內的 DNS 緩存。從配置中可以看到,TTL 在 $JAVA_HOME/jre/lib/security/java.security 位置進行配置,并被設置為 networkaddress.cache.ttl = 10。JVM 應該能夠以 10 秒為周期緩存所有 DNS 查詢。
為了確認 DNS 假設,我們決定剝離 DNS 解析步驟,并查看問題是否可以消失。我們的第一項嘗試是讓應用程序直接與 ELasticSearch IP 通信,從而繞過域名機制。這需要變更代碼并進行新的部署,即需要在 /etc.hosts 中添加一行代碼以將域名映射至其實際 IP:
- 34.55.5.111 elastic.spain.adevinta.com
通過這種方式,容器能夠以近即時方式進行 IP 解析。我們發現延遲確實有所改進,但距離目標等待時間仍然相去甚遠。盡管 DNS 解析時長有問題,但真正的原因還沒有被找到。
網絡管道
我們決定在容器中進行 tcpdump,以便準確觀察網絡的運行狀況。
- [root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap
我們隨后發送了多項請求并下載了捕捉結果(kubectl cp my-service:/capture.pcap capture.pcap),而后利用 Wireshark 進行檢查。
DNS 查詢部分一切正常(少部分值得討論的細節,我將在后文提到)。但是,我們的服務處理各項請求的方式有些奇怪。以下是捕捉結果的截圖,顯示出在響應開始之前的請求接收情況。
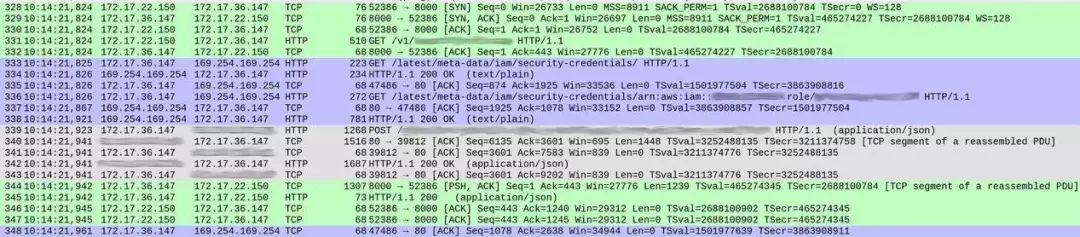
數據包編號顯示在第一列當中。為了清楚起見,我對不同的 TCP 流填充了不同的顏色。
從數據包 328 開始的綠色部分顯示,客戶端(172.17.22.150)打開了容器(172.17.36.147)間的 TCP 連接。在最初的握手(328 至 330)之后,數據包 331 將 HTTP GET /v1/..(傳入請求)引向我們的服務,整個過程耗時約 1 毫秒。
來自數據包 339 的灰色部分表明,我們的服務向 ElasticSearch 實例發送了 HTTP 請求(這里沒有顯示 TCP 握手,是因為其使用原有 TCP 連接),整個過程耗費了 18 毫秒。
到這里,一切看起來還算正常,而且時間也基本符合整體響應延遲預期(在客戶端一側測量為 20 到 30 毫秒)。
但在兩次交換之間,藍色部分占用了 86 毫秒。這到底是怎么回事?在數據包 333,我們的服務向 /latest/meta-data/iam/security-credentials 發送了一項 HTTP GET 請求,而后在同一 TCP 連接上,又向 /latest/meta-data/iam/security-credentials/arn:.. 發送了另一項 GET 請求。
我們進行了驗證,發現整個流程中的每項單一請求都發生了這種情況。在容器內,DNS 解析確實有點慢(理由同樣非常有趣,有機會的話我會另起一文詳加討論)。但是,導致高延遲的真正原因,在于針對每項單獨請求的 AWS Instance Metadata Service 查詢。
假設二:指向 AWS 的流氓調用
兩個端點都是 AWS Instance Metadata API 的組成部分。我們的微服務會在從 ElasticSearch 中讀取信息時使用該服務。這兩條調用屬于授權工作的基本流程,端點通過第一項請求產生與實例相關的 IAM 角色。
- / # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
- arn:aws:iam::<account_id>:role/some_role
第二條請求則向第二個端點查詢實例的臨時憑證:
- / # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
- {
- "Code" : "Success",
- "LastUpdated" : "2012-04-26T16:39:16Z",
- "Type" : "AWS-HMAC",
- "AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
- "SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
- "Token" : "token",
- "Expiration" : "2017-05-17T15:09:54Z"
- }
客戶可以在短時間內使用這些憑證,且端點會定期(在 Expiration 過期之前)檢索新憑證。這套模型非常簡單:出于安全原因,AWS 經常輪換臨時密鑰,但客戶端可以將密鑰緩存幾分鐘,從而抵消檢索新憑證所帶來的性能損失。
照理來說,整個過程應該由 AWS Java SDK 為我們處理。但不知道為什么,實際情況并非如此。搜索了一遍 GitHub 問題,我們從 #1921 當中找到了需要的線索。
AWS SDK 會在滿足以下兩項條件之一時刷新憑證:
- Expiration 已經達到 EXPIRATION_THRESHOLD 之內,硬編碼為 15 分鐘。
- 最后一次刷新憑證的嘗試大于 REFRESH_THRESHOLD,硬編碼為 60 分鐘。
我們希望查看所獲取憑證的實際到期時間,因此我們針對容器 API 運行了 cURL 命令——分別指向 EC2 實例與容器。但容器給出的響應要短得多:正好 15 分鐘。現在的問題很明顯了:我們的服務將為第一項請求獲取臨時憑證。由于有效時間僅為 15 分鐘,因此在下一條請求中,AWS SDK 會首先進行憑證刷新,每一項請求中都會發生同樣的情況。
為什么憑證的過期時間這么短?
AWS Instance Metadata Service 在設計上主要適合 EC2 實例使用,而不太適合 Kubernetes。但是,其為應用程序保留相同接口的機制確實很方便,所以我們轉而使用 KIAM,一款能夠運行在各個 Kubernetes 節點上的工具,允許用戶(即負責將應用程序部署至集群內的工程師)將 IAM 角色關聯至 Pod 容器,或者說將后者視為 EC2 實例的同等對象。其工作原理是攔截指向 AWS Instance Metadata Service 的調用,并利用自己的緩存(預提取自 AWS)及時接上。從應用程序的角度來看,整個流程與 EC2 運行環境沒有區別。
KIAM 恰好為 Pod 提供了周期更短的臨時憑證,因此可以合理做出假設,Pod 的平均存在周期應該短于 EC2 實例——默認值為 15 分鐘。如果將兩種默認值放在一起,就會引發問題。提供給應用程序的每一份證書都會在 15 分鐘之后到期,但 AWS Java SDK 會對一切剩余時間不足 15 分鐘的憑證做出強制性刷新。
結果就是,每項請求都將被迫進行憑證刷新,這使每項請求的延遲提升。接下來,我們又在 AWS Java SDK 中發現了一項功能請求,其中也提到了相同的問題。
相比之下,修復工作非常簡單。我們對 KIAM 重新配置以延長憑證的有效期。在應用了此項變更之后,我們就能夠在不涉及 AWS Instance Metadata Service 的情況下開始處理請求,同時返回比 EC2 更低的延遲水平。
總結
根據我們的實際遷移經驗,最常見的問題并非源自 Kubernetes 或者該平臺其他組件,與我們正在遷移的微服務本身也基本無關。事實上,大多數問題源自我們急于把某些組件粗暴地整合在一起。
我們之前從來沒有復雜系統的整合經驗,所以這一次我們的處理方式比較粗糙,未能充分考慮到更多活動部件、更大的故障面以及更高熵值帶來的實際影響。
在這種情況下,導致延遲升高的并不是 Kubernetes、KIAM、AWS Java SDK 或者微服務層面的錯誤決策。相反,問題源自 KIAM 與 AWS Java SDK 當中兩項看似完全正常的默認值。單獨來看,這兩個默認值都很合理:AWS Java SDK 希望更頻繁地刷新憑證,而 KIAM 設定了較低的默認過期時間。但在二者結合之后,卻產生了病態的結果。是的,各個組件能夠正常獨立運行,并不代表它們就能順利協作并構成更龐大的系統。