獨家分享!5個鮮為人知的Pandas技巧
Pandas為Python營造了一個高水平的操作環(huán)境,還提供了便于操作的數(shù)據結構和分析工具
無需更多介紹,Pandas已經是Python中數(shù)據分析的常用工具了。作為一個數(shù)據科學家,Pandas是我日常使用的工具,我總會驚嘆于它強大的功能。本篇文章將會講解5個我最近學到的,并且極大提升了工作效率的Pandas技巧。
對于pandas新手而言,Pandas為Python編程語言營造了一個高水平的操作環(huán)境,還提供了便于操作的數(shù)據結構和分析工具。Pandas這個名字是由“面板數(shù)據”(panel data)衍生而來,這是一個計量經濟學中的術語,它是一個數(shù)據集,由同一個個體在多個時間段內所觀察的結果組成。
1. 數(shù)據范圍
從外部應用程序接口(API)或者數(shù)據庫中抓取數(shù)據的時候,通常需要確定一個數(shù)據范圍。Pandas可以很好地解決這一問題,它的data_range函數(shù)能夠產出按日、月、年等方式遞增的日期。
假設現(xiàn)在需要一組按天數(shù)遞增的數(shù)據范圍。
- date_from ="2019-01-01"
- date_to = "2019-01-12"
- date_range = pd.date_range(date_from, date_to, freq="D")
- date_range

把產出的date_range轉化為開始和結束日期,這一步可以用后續(xù)函數(shù)(subsequentfunction)完成。
- for i, (date_from, date_to) inenumerate(zip(date_range[:-1], date_range[1:]), 1):
- date_from = date_from.date().isoformat()
- date_to = date_to.date().isoformat()
- print("%d. date_from: %s,date_to: %s" % (i, date_from, date_to))1. date_from: 2019-01-01,date_to: 2019-01-02
2. date_from: 2019-01-02, date_to: 2019-01-03
3. date_from: 2019-01-03, date_to: 2019-01-04
4. date_from: 2019-01-04, date_to: 2019-01-05
5. date_from: 2019-01-05, date_to: 2019-01-06
6. date_from: 2019-01-06, date_to: 2019-01-07
7. date_from: 2019-01-07, date_to: 2019-01-08
8. date_from: 2019-01-08, date_to: 2019-01-09
9. date_from: 2019-01-09, date_to: 2019-01-10
10. date_from: 2019-01-10, date_to: 2019-01-11
11. date_from: 2019-01-11, date_to: 2019-01-12
2. 使用指示符合并
合并兩個數(shù)據集就是將它們變成一個數(shù)據集的過程,這需要根據它們的公共屬性或欄來對齊其中的每一行。
合并函數(shù)中有許多arguments(對應于傳遞給函數(shù)的參數(shù)的類數(shù)組對象),其中指示符(indicator)argument可主要應用到合并過程中,它在左、右或者兩邊的數(shù)據幀(DataFrame)函數(shù)添加_merge欄,這一欄就顯示了“數(shù)據行是哪里來的”。用_merge欄來處理更大的數(shù)據集會非常有用,尤其是需要檢查合并操作的正確率時。
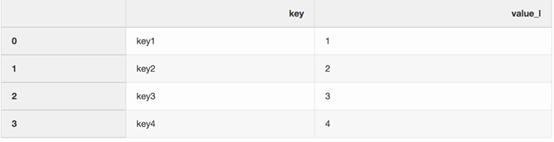
- left = pd.DataFrame({"key":["key1", "key2", "key3", "key4"],"value_l": [1, 2, 3, 4]})
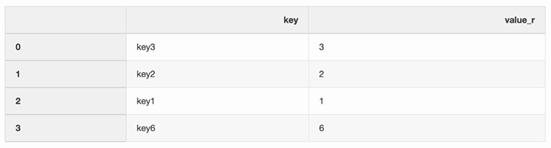
- right = pd.DataFrame({"key":["key3", "key2", "key1", "key6"],"value_r": [3, 2, 1, 6]})
- df_merge = left.merge(right,on='key', how='left',indicator=True)
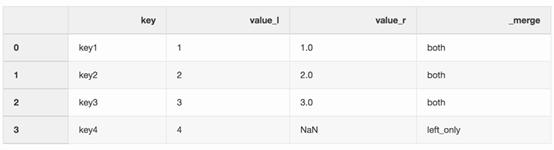
_merge欄可以用來檢查是否得到了我們預期的行數(shù),而且它反映的是來自兩個數(shù)據框架的預期值。
- df_merge._merge.value_counts()both 3
- left_only 1
- right_only 0
- Name: _merge, dtype: int64
3. 最近合并(Nearest merge)
在處理像股票或者加密貨幣一類的金融數(shù)據時,還需要把報價(價格變化)與實際交易結合。現(xiàn)在,假設目的是希望將每筆交易與之前幾毫秒產生的報價合并起來。Pandas有一個merge_asof函數(shù),它能夠通過最近的key(本文中指時間戳)來合并數(shù)據框架。有關報價和交易的數(shù)據集可以從pandas實例中獲得。
報價數(shù)據框架包含了不同股票的價格變化。通常情況下,報價要比交易多得多。
- quotes = pd.DataFrame(
- [
- ["2016-05-2513:30:00.023", "GOOG", 720.50, 720.93],
- ["2016-05-2513:30:00.023", "MSFT", 51.95, 51.96],
- ["2016-05-2513:30:00.030", "MSFT", 51.97, 51.98],
- ["2016-05-2513:30:00.041", "MSFT", 51.99, 52.00],
- ["2016-05-2513:30:00.048", "GOOG", 720.50, 720.93],
- ["2016-05-2513:30:00.049", "AAPL", 97.99, 98.01],
- ["2016-05-2513:30:00.072", "GOOG", 720.50, 720.88],
- ["2016-05-2513:30:00.075", "MSFT", 52.01, 52.03],
- ],
- columns=["timestamp","ticker", "bid", "ask"],
- )
- quotes['timestamp'] = pd.to_datetime(quotes['timestamp'])
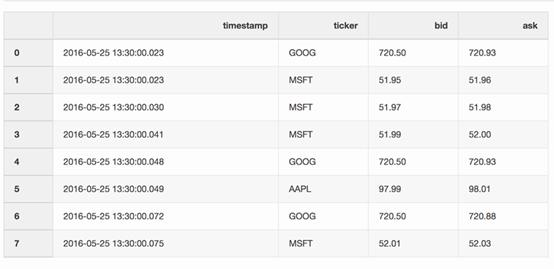
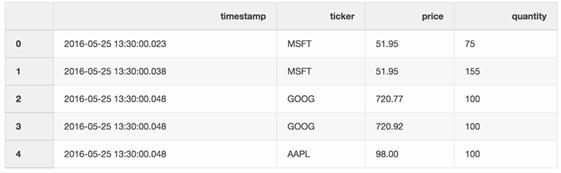
交易數(shù)據框架包含了不同股票的交易信息。
- trades = pd.DataFrame(
- [
- ["2016-05-2513:30:00.023", "MSFT", 51.95, 75],
- ["2016-05-2513:30:00.038", "MSFT", 51.95, 155],
- ["2016-05-2513:30:00.048", "GOOG", 720.77, 100],
- ["2016-05-2513:30:00.048", "GOOG", 720.92, 100],
- ["2016-05-2513:30:00.048", "AAPL", 98.00, 100],
- ],
- columns=["timestamp","ticker", "price", "quantity"],
- )
- trades['timestamp'] = pd.to_datetime(trades['timestamp'])
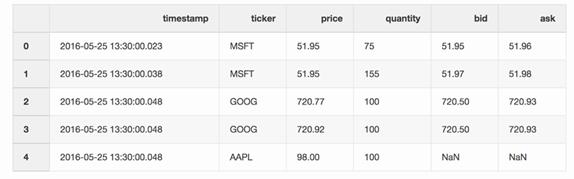
通過股價報告(tickers)可以合并交易和報價信息,報告中報價可能只比交易遲了10毫秒。如果報價的時間差長于10毫秒,或者沒有報價,任何出價和詢問報價都是無效的(以蘋果股價報告*為例)。
*蘋果股價報告:AAPL ticker。
- pd.merge_asof(trades,quotes, on="timestamp", by='ticker', tolerance=pd.Timedelta('10ms'),direction='backward')
4. 創(chuàng)建Excel報告
Pandas和XlsxWriter庫同時使用能夠幫助我們創(chuàng)建基于數(shù)據框架的Excel 報告。這能節(jié)省很多時間,不用再花時間先把數(shù)據框架存為csv格式,然后再導入Excel排版。還可以直接加入各種圖表等多種便捷操作。
- df = pd.DataFrame(pd.np.array([[1,2, 3], [4, 5, 6], [7, 8, 9]]), columns=["a", "b","c"])
以下的一小段代碼就創(chuàng)建了一個Excel報告。要想將一個數(shù)據框架存儲到Excel文件,需要反注釋writer.save()行。
- report_name ='example_report.xlsx'
- sheet_name = 'Sheet1'writer = pd.ExcelWriter(report_name,engine='xlsxwriter')
- df.to_excel(writer, sheet_name=sheet_name, index=False)
- # writer.save()
正如前文中提到的那樣,這個數(shù)據庫也支持添加圖表到Excel報告中。這需要確定圖表的類型(本文中是線形圖表)以及圖表所反映的數(shù)據序列,注意,這些數(shù)據序列應位于Excel的電子表格程序里(spreadsheet)。
- # define the workbook
- workbook= writer.book
- worksheet = writer.sheets[sheet_name]# create a chart lineobject
- chart = workbook.add_chart({'type': 'line'})# configurethe series of the chart from the spreadsheet
- # using a list of values instead of category/value formulas:
- # [sheetname, first_row, first_col,last_row, last_col]
- chart.add_series({
- 'categories': [sheet_name, 1, 0, 3,0],
- 'values': [sheet_name, 1, 1, 3, 1],
- })# configure the chart axes
- chart.set_x_axis({'name': 'Index', 'position_axis': 'on_tick'})
- chart.set_y_axis({'name': 'Value', 'major_gridlines': {'visible':False}})# place the chart on the worksheet
- worksheet.insert_chart('E2', chart)# output the excel file
- writer.save()
5. 節(jié)省磁盤空間
同時處理幾個數(shù)據科學項目,結束后通常會有很多從不同實驗中得到的預處理數(shù)據集。這樣筆記本電腦的固態(tài)硬盤很快就會被這些數(shù)據塞滿。Pandas在保存數(shù)據集時發(fā)揮作用,壓縮數(shù)據,讀取這些數(shù)據時又是解壓形式。
不妨創(chuàng)建一個隨機數(shù)字的大Pandas數(shù)據框架。
- df = pd.DataFrame(pd.np.random.randn(50000,300))
如果把這個文件存為csv格式,它會占掉硬盤驅動器上300MB的空間。
- df.to_csv('random_data.csv',index=False)
通過一個compression=‘gzip’argument,就可以將文件大小縮至136MB。
- df.to_csv('random_data.gz',compression='gzip', index=False)
同時,在數(shù)據框架上讀取gzipped數(shù)據也很容易,所以功能上并不會有任何損失。
- df = pd.read_csv('random_data.gz')
結語
這些pandas技巧極大的提高了工作效率。希望這篇文章能幫助到你,通過展示pandas新功能,提高你的工作效率。
你最喜歡哪一個pandas技巧呢?