NLP極簡入門指南,助你通過面試,踏入NLP的大門
弱人工智能的時代已經到來,人們每天的生活都離不開算法所提供的服務。比如:資訊類APP是根據用戶偏好做的個性化推薦;出行類APP背后是算法在做最優化調度;購物類APP是根據歷史購買行為和商品間相似度進行推薦。這樣的例子還有很多很多,就不一一列舉了。
可見算法對于一家互聯網公司有多么的重要,而市場上優秀的算法工程師卻非常稀少,因此各大互聯網公司不惜開出高薪來吸引人才,同時算法工程師的職業生命周期還很長,對絕大多數的開發者來說是一個非常理想的職業。
NLP的全稱是Natuarl Language Processing,中文意思是自然語言處理,是人工智能領域的一個重要方向。隨著機器學習不斷的發展,在圖像識別、語音識別等方向都取得了巨大的進步。相比較而言NLP卻落后了一些,這與NLP所要解決問題的復雜度有關。
人類語言是抽象的信息符號,其中蘊含著豐富的語義信息,人類可以很輕松地理解其中的含義。而計算機只能處理數值化的信息,無法直接理解人類語言,所以需要將人類語言進行數值化轉換。不僅如此,人類間的溝通交流是有上下文信息的,這對于計算機也是巨大的挑戰。
NLP就是解決上述問題的技術集合,不是某個單一的技術點,而是一整套技術體系,其復雜度可見一斑。因此,NLP算法工程師的薪資待遇要遠高于行業的平均水平。
本文希望通過言簡意賅的方式,幫助大家建立一個關于NLP的整體知識體系,方便大家快速入門NLP,爭取早日成為大牛,走上人生巔峰,:-P。
我們首先來看看NLP的任務類型,如下圖所示:
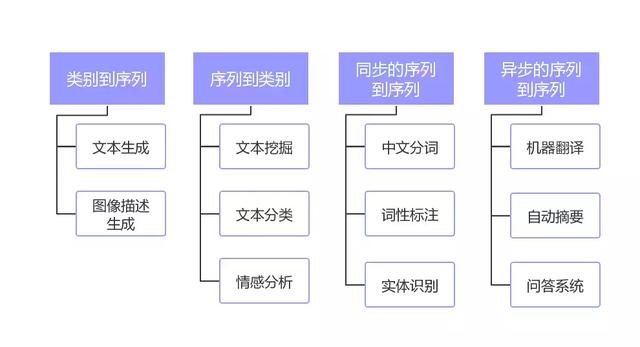
主要劃分為了四大類:
- 類別到序列
- 序列到類別
- 同步的序列到序列
- 異步的序列到序列
其中“類別”可以理解為是標簽或者分類,而“序列”可以理解為是一段文本或者一個數組。簡單概況NLP的任務就是從一種數據類型轉換成另一種數據類型的過程,這與絕大多數的機器學習模型相同或者類似,所以掌握了NLP的技術棧就等于掌握了機器學習的技術棧。
NLP的預處理
為了能夠完成上述的NLP任務,我們需要一些預處理,是NLP任務的基本流程。預處理包括:收集語料庫、文本清洗、分詞、去掉停用詞(可選)、標準化和特征提取等。
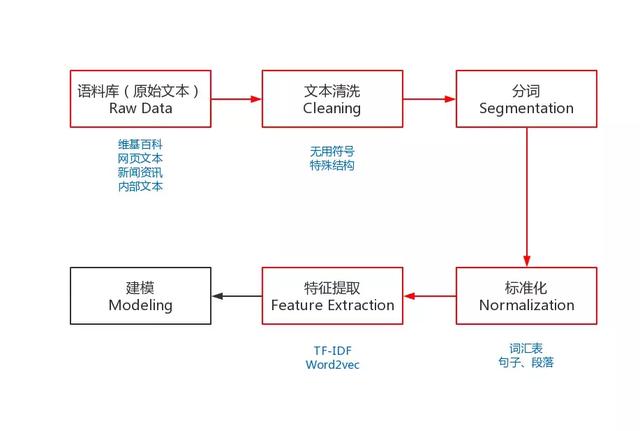
圖中紅色的部分就是NLP任務的預處理流程,有別于其它機器學習任務的流程,下面我就來分布介紹一下:
語料庫
對于NLP任務來說,沒有大量高質量的語料,就是巧婦難為無米之炊,是無法工作的。
而獲取語料的途徑有很多種,最常見的方式就是直接下載開源的語料庫,如:維基百科的語料庫。
但這樣開源的語料庫一般都無法滿足業務的個性化需要,所以就需要自己動手開發爬蟲去抓取特定的內容,這也是一種獲取語料庫的途徑。
當然,每家互聯網公司根據自身的業務,也都會有大量的語料數據,如:用戶評論、電子書、商品描述等等,都是很好的語料庫。
現在,數據對于互聯網公司來說就是石油,其中蘊含著巨大的商業價值。所以,小伙伴們在日常工作中一定要養成收集數據的習慣,遇到好的語料庫一定要記得備份(當然是在合理合法的條件下),它將會對你解決問題提供巨大的幫助。
文本清洗
我們通過不同的途徑獲取到了想要的語料庫之后,接下來就需要對其進行清洗。因為很多的語料數據是無法直接使用的,其中包含了大量的無用符號、特殊的文本結構。
數據類型分為:
結構化數據:關系型數據、json等 半結構化數據:XML、HTML等 非結構化數據:Word、PDF、文本、日志等
需要將原始的語料數據轉化成易于處理的格式,一般在處理HTML、XML時,會使用Python的lxml庫,功能非常豐富且易于使用。對一些日志或者純文本的數據,我們可以使用正則表達式進行處理。
正則表達式是使用單個字符串來描述、匹配一系列符合某個句法規則的字符串。Python的示例代碼如下:
- import re
- # 定義中文字符的正則表達式
- re_han_default = re.compile("([\\u4E00-\\u9FD5]+)", re.U)
- sentence = "我/愛/自/然/語/言/處/理"
- # 根據正則表達式進行切分
- blocks= re_han_default.split(sentence)
- for blk in blocks:
- # 校驗單個字符是否符合正則表達式
- if blk and re_han_default.match(blk):
- print(blk)
輸出:
我愛自然語言處理復制代碼
除了上述的內容之外,我們還需要注意中文的編碼問題,在windows平臺下中文的默認編碼是GBK(gb2312),而在linux平臺下中文的默認編碼是UTF-8。在執行NLP任務之前,我們需要統一不同來源語料的編碼,避免各種莫名其妙的問題。
如果大家事前無法判斷語料的編碼,那么我推薦大家可以使用Python的chardet庫來檢測編碼,簡單易用。既支持命令行:chardetect somefile,也支持代碼開發。
分詞
中文分詞和英文分詞有很大的不同,英文是使用空格作為分隔符,所以英文分詞基本沒有什么難度。而中文是字與字直接連接,中間沒有任何的分隔符,但中文是以“詞”作為基本的語義單位,很多NLP任務的輸入和輸出都是“詞”,所以中文分詞的難度要遠大于英文分詞。
中文分詞是一個比較大的課題,相關的知識點和技術棧非常豐富,可以說搞懂了中文分詞就等于搞懂了大半個NLP。中文分詞經歷了20多年的發展,克服了重重困難,取得了巨大的進步,大體可以劃分成兩個階段,如下圖所示:
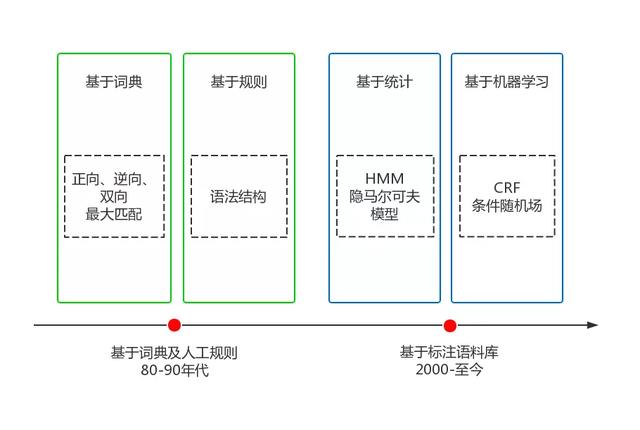
目前,主流的中文分詞技術采用的都是基于詞典最大概率路徑+未登錄詞識別(HMM)的方案,其中典型的代表就是jieba分詞,一個熱門的多語言中文分詞包。
如果對中文分詞感興趣的朋友,想進一步詳細了解,我推薦你看一看我寫的一本掘金小冊《深入理解NLP的中文分詞:從原理到實踐》,里面詳細地講解了中文分詞的各種實現方法,并深度分析了jiebe的Python源碼,讓你可以從零開始徹底掌握中文分詞的技術,同時也講解了多種NLP的實際案例,相信你一定會收獲很多。
標準化
標準化是為了給后續的處理提供一些必要的基礎數據,包括:去掉停用詞、詞匯表、訓練數據等等。
當我們完成了分詞之后,可以去掉停用詞,如:“其中”、“況且”、“什么”等等,但這一步不是必須的,要根據實際業務進行選擇,像關鍵詞挖掘就需要去掉停用詞,而像訓練詞向量就不需要。
詞匯表是為語料庫建立一個所有不重復詞的列表,每個詞對應一個索引值,并索引值不可以改變。詞匯表的最大作用就是可以將詞轉化成一個向量,即One-Hot編碼。
假設我們有這樣一個詞匯表:
我愛自然語言處理復制代碼
那么,我們就可以得到如下的One-Hot編碼:
- 我: [1, 0, 0, 0, 0]
- 愛: [0, 1, 0, 0, 0]
- 自然:[0, 0, 1, 0, 0]
- 語言:[0, 0, 0, 1, 0]
- 處理:[0, 0, 0, 0, 1]
這樣我們就可以簡單的將詞轉化成了計算機可以直接處理的數值化數據了。雖然One-Hot編碼可以較好的完成部分NLP任務,但它的問題還是不少的。
當詞匯表的維度特別大的時候,就會導致經過One-Hot編碼后的詞向量非常稀疏,同時One-Hot編碼也缺少詞的語義信息。由于這些問題,才有了后面大名鼎鼎的Word2vec,以及Word2vec的升級版BERT。
除了詞匯表之外,我們在訓練模型時,還需要提供訓練數據。模型的學習可以大體分為兩類:
- 監督學習,在已知答案的標注數據集上,模型給出的預測結果盡可能接近真實答案,適合預測任務
- 非監督學習,學習沒有標注的數據,是要揭示關于數據隱藏結構的一些規律,適合描述任務
根據不同的學習任務,我們需要提供不同的標準化數據。一般情況下,標注數據的獲取成本非常昂貴,非監督學習雖然不需要花費這樣的成本,但在實際問題的解決上,主流的方式還選擇監督學習,因為效果更好。
帶標注的訓練數據大概如下所示(情感分析的訓練數據):
- 距離 川沙 公路 較近 公交 指示 蔡陸線 麻煩 建議 路線 房間 較為簡單 __label__1
- 商務 大床 房 房間 很大 床有 2M 寬 整體 感覺 經濟 實惠 不錯 ! __label__1
- 半夜 沒 暖氣 住 ! __label__0
其中每一行就是一條訓練樣本,__label__0和__label__1是分類信息,其余的部分就是分詞后的文本數據。
特征提取
為了能夠更好的訓練模型,我們需要將文本的原始特征轉化成具體特征,轉化的方式主要有兩種:統計和Embedding。
原始特征:需要人類或者機器進行轉化,如:文本、圖像。
具體特征:已經被人類進行整理和分析,可以直接使用,如:物體的重要、大小。
統計
統計的方式主要是計算詞的詞頻(TF)和逆向文件頻率(IDF):
- 詞頻,是指某一個給定的詞在該文件中出現的頻率,需要進行歸一化,避免偏向長文本
- 逆向文件頻率,是一個詞普遍重要性的度量,由總文件數目除以包含該詞的文件那么,每個詞都會得到一個TF-IDF值,用來衡量它的重要程度,計算公式如下:
- Embedding
Embedding是將詞嵌入到一個由神經網絡的隱藏層權重構成的空間中,讓語義相近的詞在這個空間中距離也是相近的。Word2vec就是這個領域具有表達性的方法,大體的網絡結構如下:
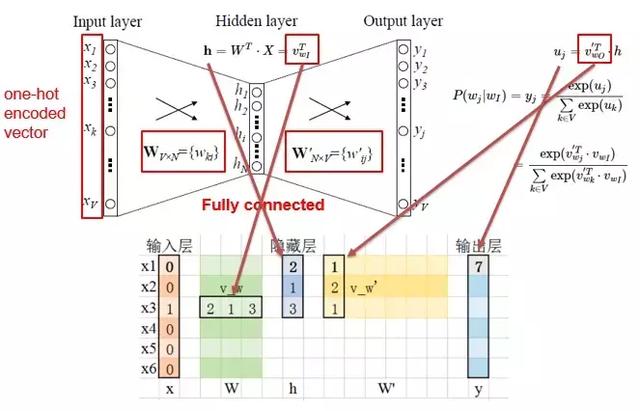
輸入層是經過One-Hot編碼的詞,隱藏層是我們想要得到的Embedding維度,而輸出層是我們基于語料的預測結果。不斷迭代這個網絡,使得預測結果與真實結果越來越接近,直到收斂,我們就得到了詞的Embedding編碼,一個稠密的且包含語義信息的詞向量,可以作為后續模型的輸入。
綜上所述,我們就將NLP預處理的部分講解清楚了,已經涵蓋了大部分的NLP內容,接下來我們來聊聊NLP的一些具體業務場景。
- NLP的業務場景
NLP的業務場景非常豐富,我簡單的梳理了一下:
- 文本糾錯:識別文本中的錯別字,給出提示以及正確的建議
- 情感傾向分析:對包含主觀信息的文本進行情感傾向性判斷
- 評論觀點抽取:分析評論關注點和觀點,輸出標簽
- 對話情緒識別:識別會話者所表現出的情緒類別及置信度
- 文本標簽:輸出能夠反映文章關鍵信息的多維度標簽
- 文章分類:輸出文章的主題分類及對應的置信度
- 新聞摘要:抽取關鍵信息并生成指定長度的新聞摘要
大家不要被這些眼花繚亂的業務場景給搞暈了,其實上面的這些業務都是基于我們之前講的NLP預處理的輸出,只是應用了不同的機器學習模型,比如:SVM、LSTM、LDA等等。
這些機器學習模型大部分是分類模型(序列標注也是一種分類模型),只有少部分是聚類模型。這些模型就是泛化的了,并不只是針對于NLP任務的。要想講清楚這部分內容,就需要另開一個關于“機器學習入門”的主題,這里就不過多的展開了。
小結:只要大家掌握了NLP的預處理,就算入門NLP了,因為后續的處理都是一些常見的機器學習模型和方法。