想擺脫無效報警?十年運維監控報警優化經驗總結
Google SRE每周十條故障報警
運維工程師面試者第一個問題是:需要值班嗎?
筆者自己也曾經歷過月入十萬的時期,在那個時候,數個系統同時發布下一代版本,而老系統還需要過渡很長時間,工作量直接翻倍。
大家只能勉強應付一線運維工作,團隊成員開始陸續離職,而新人又無法在短時間內上手,整體情況不斷惡化,持續半年左右才緩過勁來。
下面兩張截圖是我挑選的兩個團隊一周報警數的對比圖,前者的單日報警量最高是55348條,后者單日的報警量最高為34條,兩者相差1600倍,而前者才是國內很多互聯網運維團隊的真實寫照。


在管理大規模集群的情況下,究竟有多少報警量才是合理的呢?
Google SRE每周只有十條報警,如果超過十條,說明沒有把無效報警過濾掉(Google SRE僅負責SLA要求為99.99%的服務)。
筆者所在的團隊要求則是,每周至多兩晚有報警,單日報警量不能超過50條(比Google SRE放水好多啊)。
通過控制單日報警數量,嚴格約束夜間報警天數,確保最少不低于四人參與值班,筆者所在的團隊,近幾年來,不僅少有因為值班壓力而離職的同學,而且我們每年都能持續招聘到985前20名學校的多個研究生。
那么,怎么做到呢,以下是筆者的一些經驗分享。
運維工程角度看報警優化
1)報警值班和報警升級
基于值班表,每天安排兩人進行值班處理報警,將值班壓力從全團隊壓縮在兩人范圍內,從而讓團隊能夠有足夠的時間和人力進行優化工作。
同時,為了避免兩個值班人員都沒有響應報警,可以使用報警升級功能,如果一個報警在5min內值班人員均未響應,或者15min內未處理完畢,或者有嚴重故障發生,都可以將報警進行升級,通告團隊其他成員協助處理。
如果公司的監控系統暫不支持值班表功能,則通過人工定期修改報警接收人的方式進行。
而對于監控系統不支持報警升級的問題,通過自行開發腳本的方式,也能在一定程度上得到解決。
也可以將報警短信發送至商業平臺來實現。總之一句話,辦法總比問題多。
對于報警值班人員,需要隨時攜帶筆記本以方便處理服務故障,這個要求,和報警數量多少以及報警的自動化處理程度并無關系,僅和服務重要性有關。
對于節假日依然需要值班的同學,公司或者部門也應該盡量以各種方式進行補償。
2)基于重要性不同,分級應對
一個問題請大家思考一下,如果線上的服務器全部掉電后以短信方式通知值班人員,那么線上一臺機器的根分區打滿,也通過短信來通知是否有必要。
上述的問題在日常工作也屢屢發生,對于問題、異常和故障,我們采取了同樣的處理方式,因此產生了如此多的無效報警。
Google SRE的實踐則是將監控系統的輸出分為三類,報警、工單和記錄。
SRE的要求是所有的故障級別的報警,都必須是接到報警,有明確的非機械重復的事情要做,且必須馬上就得做,才能叫做故障級別的報警。其他要么是工單,要么是記錄。
在波音公司裝配多個發動機的飛機上,一個發動機熄火的情況只會產生一個”提醒“級別的警示(最高級別是警報,接下來依次是警告、提醒、建議),對于各種警示,會有個檢查清單自動彈出在中央屏幕上,以引導飛行員找到解決方案。
如果是最高級別的警報,則會以紅色信息,語音警報,以及飛機操縱桿的劇烈震動來提示。如果這時你什么都不做,飛機將會墜毀。
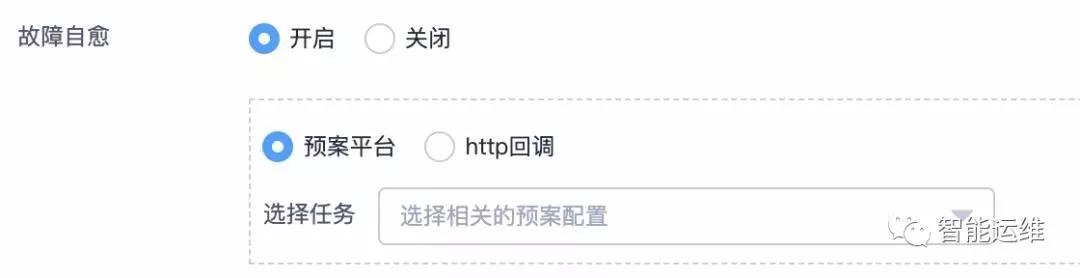
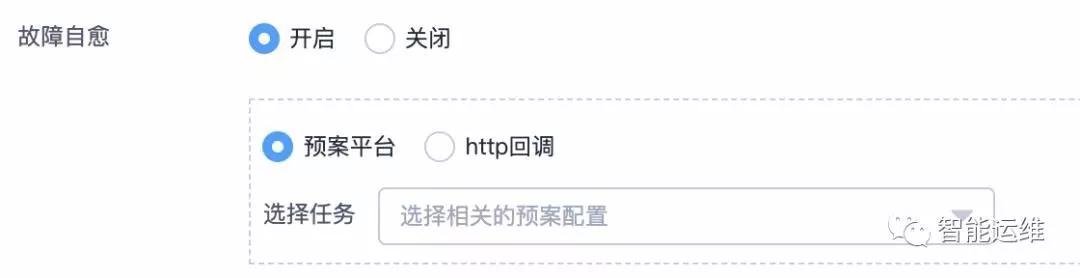
3)故障自愈
重啟作為單機預案,在很多業務線,可以解決至少50%的報警。沒有響應,重啟試試,請求異常,重啟試試,資源占用異常,重啟試試,各種問題,重啟都屢試不爽。
換言之,針對簡單場景具有明確處置方案的報警,自動化是一個比較好的解決方案,能夠將人力從大量重復的工作中解放出來。
- 自動化處理報警的過程中,需要注意以下問題:
- 自動化處理比例不能超過服務的冗余度(默認串行處理最為穩妥);
- 不能對同一個問題在短時間內重復多次地自動化處理(不斷重啟某個機器上的特定進程);
- 在特定情況下可以在全局范圍內快速終止自動化處理機制;
- 盡量避免高危操作(如刪除操作、重啟服務器等操作);
- 每次執行操作都需要確保上一個操作的結果和效果收集分析完畢(如果一個服務重啟需要10min)。
4)報警儀表盤,持續優化TOP-3的報警
如下圖示,全年TOP-3的報警量占比達到30%,通過對TOP-3的報警安排專人進行跟進優化,可以在短時間大幅降低報警量。
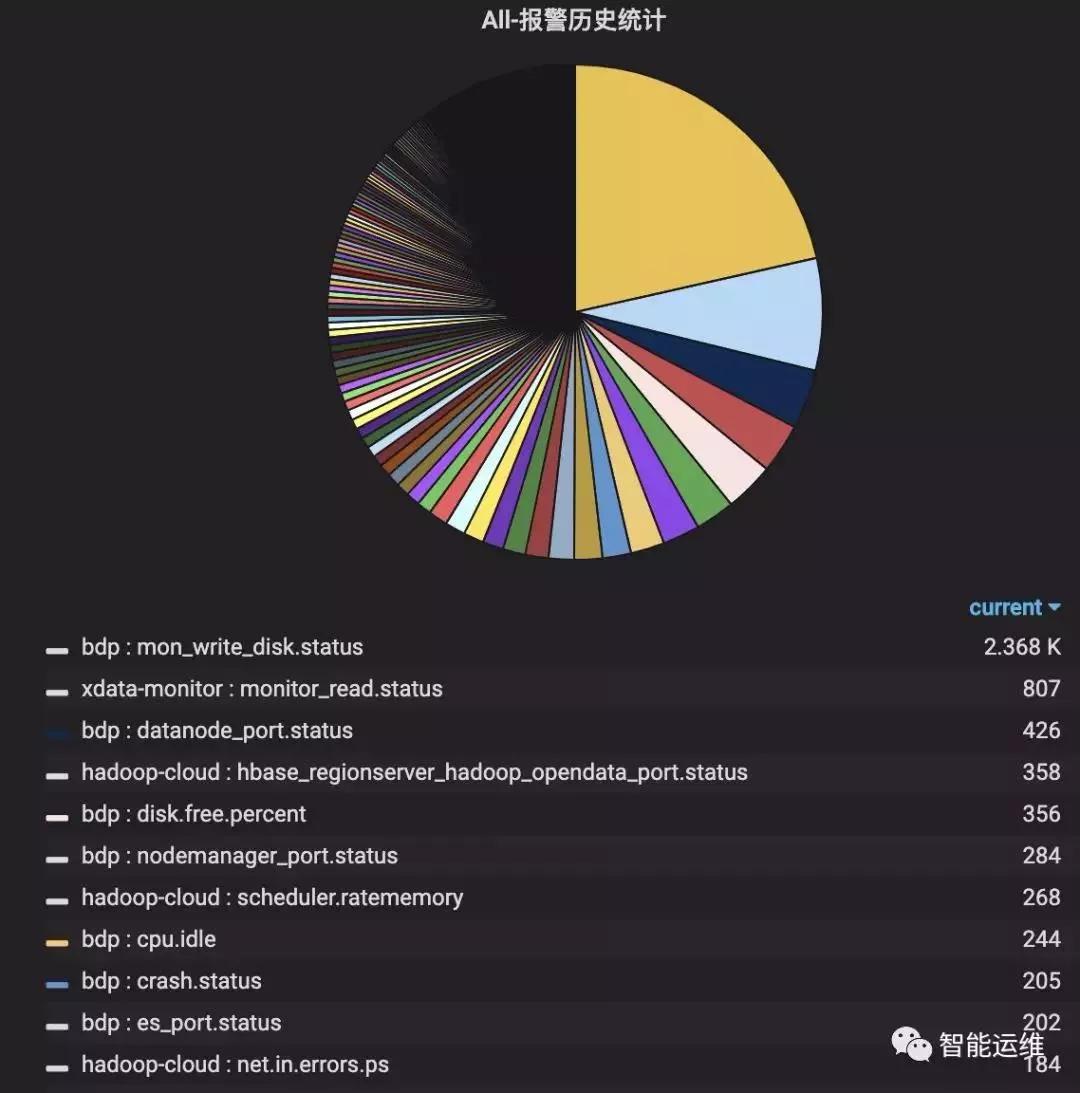
TOP-3只是報警儀表盤數據分析的典型場景之一,在TOP-3之后,還可以對報警特征進行分析,如哪些模塊的報警最多,哪些機器的報警最多,哪個時間段的報警最多,哪種類型的報警最多,進而進行細粒度的優化。
同時,報警儀表盤還需要提供報警視圖的功能,能夠基于各種維度展示當前有哪些報警正在發生,從而便于當短時間內收到大量報警,或者是報警處理中的狀態總覽,以及報警恢復后的確認等。
5)基于時間段分而治之
下圖是國內非常典型的一類流量圖,流量峰值在每天晚上,流量低谷在每天凌晨。
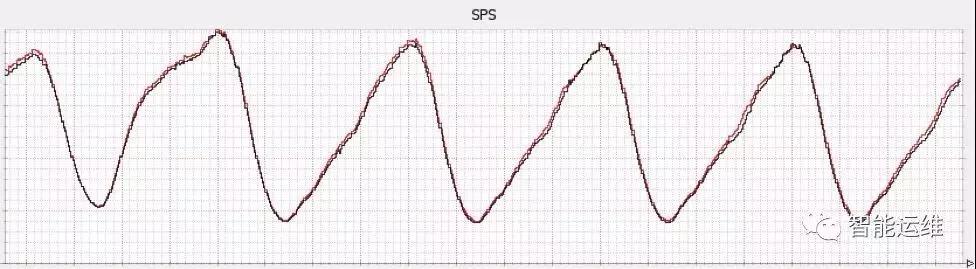
從冗余度角度來分析,如果在流量峰值有20%的冗余度,那么在流量低谷,冗余度至少為50%。
基于冗余度的變換,相應的監控策略的閾值,隨機也應該發生一系列的變化。
舉例來說,在高峰期,可能一個服務故障20%的實例,就必須介入處理的話,那么在低谷期,可能故障50%的實例,也不需要立即處理,依賴于報警自動化處理功能,逐步修復即可。
在具體的實踐中,一種比較簡單的方式就是,在流量低谷期,僅接收故障級別的報警,其余報警轉為靜默方式或者是自動化處理方式,在流量高峰期來臨前幾個小時,重新恢復,這樣即使流量低谷期出現一些嚴重隱患,依然有數小時進行修復。
這種方式之所以大量流行,是因為該策略能夠大幅減少凌晨的報警數量,讓值班人員能夠正常休息。
6)報警周期優化,避免瞬報
在監控趨勢圖中,會看到偶發的一些毛刺或者抖動,這些毛刺和抖動,就是造成瞬報的主要原因。
這些毛刺和抖動,至多定義為異常,而非服務故障,因此應該以非緊急的通知方式進行。
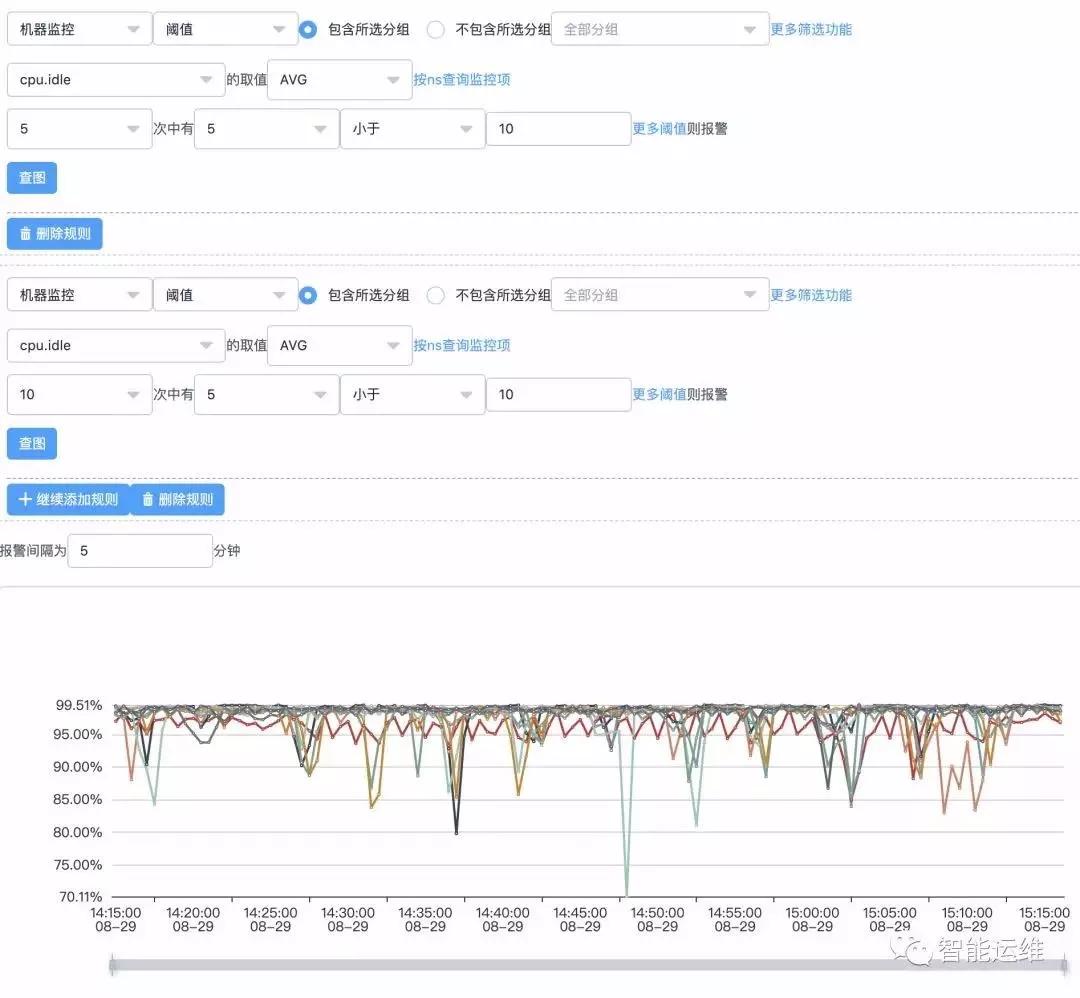
以CPU瞬報為例,如果設置采集周期為10s,監控條件為CPU使用率大于90%報警,如果設置每次滿足條件就報警,那么就會產生大量的報警。
如果設置為連續5次滿足條件報警,或者連續的10次中有5次滿足條件就報警,則會大幅減少無效報警。對于重要服務,一般建議為在3min內,至少出現5次以上異常,再發送報警較為合理。
7)提前預警,防患于未然
對于很多有趨勢規律的場景,可以通過提前預警的方式,降低問題的緊迫程度和嚴重性。
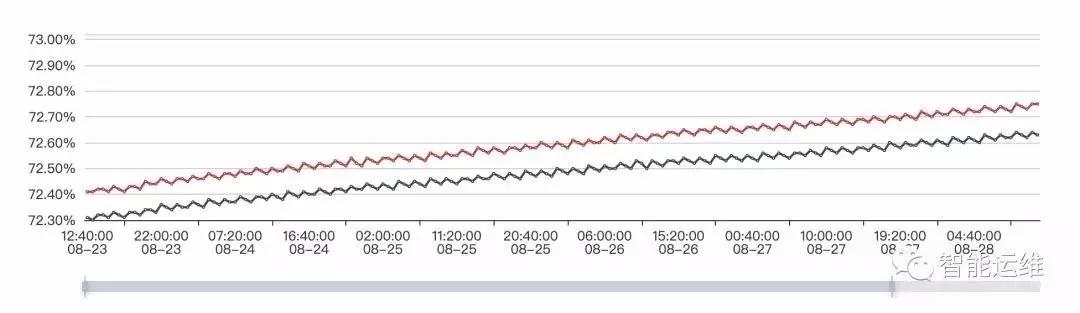
下圖是兩臺機器一周內的磁盤使用率監控圖,可以預見,按照目前的增長趨勢,必然會在某一個時間點觸發磁盤剩余空間5%的報警,可以在剩余空間小于10%的時候,通過工單或者其他非緊急方式提醒,在工作時間段內,相對從容的處理完畢即可,畢竟10%到5%還是需要一個時間過程的。
8)日常巡檢
提前預警面向的是有規律的場景,而日常巡檢,還可以發現那些沒有規律的隱患。
以CPU使用率為例進行說明,近期的一個業務上線后,CPU使用率偶發突增的情況,但是無法觸發報警條件(例如3分鐘內有5次使用率超過70%報警),因此無法通過報警感知。
放任不管的話,只能是問題足夠嚴重了,才能通過報警發現。
這個時候,如果每天有例行的巡檢工作,那么這類問題就能夠提前發現,盡快解決,從而避免更加嚴重的問題發生。
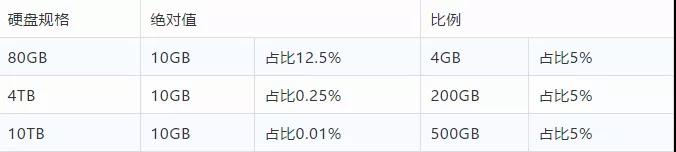
9)比例為主,絕對值為輔
線上機器的規格不同,如果從絕對值角度進行監控,則無法適配所有的機器規格,勢必會產生大量無意義的報警。
以磁盤剩余空間監控為例,線上規格從80GB到10TB存在多種規格,從下圖表格看,比例比絕對值模式能更好的適配各種規格的場景(EXT4文件系統的默認預留空間為5%,也是基于比例設置的并可通過tune2fs進行調整)。
對于一些特殊場景,同樣以磁盤剩余空間為例進行說明,例如計算任務要求磁盤至少有100GB以上空間,以供存放臨時文件,那這個時候,監控策略就可以調整為:磁盤剩余空間小于5%報警且磁盤剩余空間絕對值小于100GB報警。
10)Code Review
前人埋坑,后人挖坑。在解決存量問題的情況下,不對增量問題進行控制,那報警優化,勢必會進入螺旋式緩慢上升的過程,這對于報警優化這類項目來說,無疑是致命的。
通過對新增監控的Code Review,可以讓團隊成員快速達成一致認知,從而避免監控配置出現千人千面的情況出現。
11)沉淀標準和最佳實踐
僅僅做Code Review還遠遠不夠,一堆人開會,面對一行監控配置,大眼瞪小眼,對不對,為什么不對,怎么做更好?大家沒有一個標準,進而會浪費很多時間來進行不斷的討論。
這時候,如果有一個標準,告訴大家什么是好,那么就有了評價標準,很多事情就比較容易做了。
標準本身也是需要迭代和進步的,因此大家并不需要擔心說我的標準不夠完美。
基于標準,再給出一些最佳的監控時間,那執行起來,就更加容易了。
以機器監控為例進行說明,機器監控必須覆蓋如下的監控指標,且閾值設定也給出了最佳實踐,具體如下:
- CPU_IDLE < 10 ;
- MEM_USED_PERCENT > 90;
- NET_MAX_NIC_INOUT_PERCENT > 80 (網卡入口/出口流量最大使用率);
- CPU_SERVER_LOADAVG_5 > 15 ;
- DISK_MAX_PARTITION_USED_PERCENT > 95 (磁盤各個分區最大使用率);
- DISK_TOTAL_WRITE_KB(可選項);
- DISK_TOTAL_READ_KB(可選項);
- CPU_WAIT_IO(可選項);
- DISK_TOTAL_IO_UTIL(可選項);
- NET_TCP_CURR_ESTAB(可選項);
- NET_TCP_RETRANS(可選項)。
12)徹底解決問題不等于自動處理問題
舉兩個例子,大家來分析一下這個問題是否得到徹底解決:
如果一個模塊經常崩掉,那么我們可以通過添加一個定時拉起腳本來解決該問題。
那這個模塊崩掉的問題解決了嗎?其實并沒有,你增加一個拉起腳本,只是說自己不用上機器去處理了而已,但是模塊為什么經常崩掉這個問題,卻并沒有人去關注,更別提徹底解決了。
如果一個機器經常出現CPU_IDLE報警,那么我們可以將現在的監控策略進行調整。
比如說,以前5min內出現5次就報警,現在可以調整為10min內出現20次再報警,或者直接刪除這個報警策略,或者將報警短信調整為報警郵件,或者各種類似的手段。
但這個機器為什么出現CPU_IDLE報警,卻并沒有人去關注,更別提解決了。
通過上面兩個例子,大家就理解,自動化處理問題不等于解決問題,掩耳盜鈴也不等于解決問題,什么叫做解決問題,只有是找到問題的根本原因,并消滅之,才能確保徹底解決問題,輕易不會再次發生。
還是上面自動拉起的例子,如果仔細分析后,發現是內存泄露導致的進程頻繁崩掉,或者是程序bug導致的coredump,那么解決掉這些問題,就能夠徹底避免了。
如何解決團隊內部的值班排斥情緒
每個運維團隊早晚都會面對團隊高工對值班工作的排斥,這也是人之常情。
辛辛苦苦干了幾年了,還需要值班,老婆孩子各種抱怨,有時候身體狀況也不允許了,都不容易。
不同的團隊,解決方式不同,但有些解決方案,會讓人覺得,你自己都不想值班,還天天給我們打雞血說值班重要。
更嚴重一些的,會讓團隊成員感受到不公平,憑什么他可以不值班,下次是不是我們大家也可以找同樣的理由呢。
筆者的團隊是這樣明確說明的:
保證值班人員數量不低于四人,如果短時間內低于四人,那么就需要將二線工程師短暫加入一線值班工作中,為期不超過三個月。
對于希望退出值班列表的中級工程師,給三個月不值班時間,如果能將目前的報警短信數量優化20%-50%,則可以退出值班序列,但如果情況反彈,則需要重回值班工作。
團隊達到一定級別的工程師,就可以轉二線,不參與日常值班工作,僅接收核心報警,且對核心報警的有效性負責,若服務故障核心報警未發出,則每次罰款兩百。
團隊負責人不參與值班工作,但需要對單日報警數量負責,如果當周的日報警數量大于要求值,則每次罰款兩百元。如果團隊成員數量低于四人時,則需要加入值班列表。
寫在最后
在團隊的報警量有了明顯減少后,就需要對報警的準確性和召回率進行要求了,從而才能持續的進行報警優化工作。
所謂的準確性,也就是有報警必有損,而召回率呢,則是有損必有報警。
最后,祝愿大家都不在因為值班工作而苦惱!