技術干貨分享:HBase數據遷移到Kafka實戰
1.概述
在實際的應用場景中,數據存儲在HBase集群中,但是由于一些特殊的原因,需要將數據從HBase遷移到Kafka。正常情況下,一般都是源數據到Kafka,再有消費者處理數據,將數據寫入HBase。但是,如果逆向處理,如何將HBase的數據遷移到Kafka呢?今天筆者就給大家來分享一下具體的實現流程。

2.內容
一般業務場景如下,數據源頭產生數據,進入Kafka,然后由消費者(如Flink、Spark、Kafka API)處理數據后進入到HBase。這是一個很典型的實時處理流程。流程圖如下:

上述這類實時處理流程,處理數據都比較容易,畢竟數據流向是順序處理的。但是,如果將這個流程逆向,那么就會遇到一些問題。
2.1 海量數據
HBase的分布式特性,集群的橫向拓展,HBase中的數據往往都是百億、千億級別,或者數量級更大。這類級別的數據,對于這類逆向數據流的場景,會有個很麻煩的問題,那就是取數問題。如何將這海量數據從HBase中取出來?
2.2 沒有數據分區
我們知道HBase做數據Get或者List很快,也比較容易。而它又沒有類似Hive這類數據倉庫分區的概念,不能提供某段時間內的數據。如果要提取最近一周的數據,可能全表掃描,通過過濾時間戳來獲取一周的數據。數量小的時候,可能問題不大,而數據量很大的時候,全表去掃描HBase很困難。
3.解決思路
對于這類逆向數據流程,如何處理。其實,我們可以利用HBase Get和List的特性來實現。因為HBase通過RowKey來構建了一級索引,對于RowKey級別的取數,速度是很快的。實現流程細節如下:
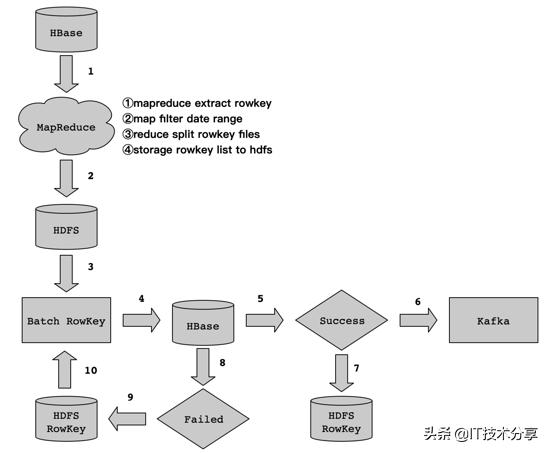
數據流程如上圖所示,下面筆者為大家來剖析每個流程的實現細節,以及注意事項。
3.1 Rowkey抽取
我們知道HBase針對Rowkey取數做了一級索引,所以我們可以利用這個特性來展開。我們可以將海量數據中的Rowkey從HBase表中抽取,然后按照我們制定的抽取規則和存儲規則將抽取的Rowkey存儲到HDFS上。
這里需要注意一個問題,那就是關于HBase Rowkey的抽取,海量數據級別的Rowkey抽取,建議采用MapReduce來實現。這個得益于HBase提供了TableMapReduceUtil類來實現,通過MapReduce任務,將HBase中的Rowkey在map階段按照指定的時間范圍進行過濾,在reduce階段將rowkey拆分為多個文件,最后存儲到HDFS上。
這里可能會有同學有疑問,都用MapReduce抽取Rowkey了,為啥不直接在掃描處理列簇下的列數據呢?這里,我們在啟動MapReduce任務的時候,Scan HBase的數據時只過濾Rowkey(利用FirstKeyOnlyFilter來實現),不對列簇數據做處理,這樣會快很多。對HBase RegionServer的壓力也會小很多。
- RowColumnrow001info:namerow001info:agerow001info:sexrow001info:sn
這里舉個例子,比如上表中的數據,其實我們只需要取出Rowkey(row001)。但是,實際業務數據中,HBase表描述一條數據可能有很多特征屬性(例如姓名、性別、年齡、身份證等等),可能有些業務數據一個列簇下有十幾個特征,但是他們卻只有一個Rowkey,我們也只需要這一個Rowkey。那么,我們使用FirstKeyOnlyFilter來實現就很合適了。
- /**
- * A filter that will only return the first KV from each row.
- * <p>
- * This filter can be used to more efficiently perform row count operations.
- */
這個是FirstKeyOnlyFilter的一段功能描述,它用于返回第一條KV數據,官方其實用它來做計數使用,這里我們稍加改進,把FirstKeyOnlyFilter用來做抽取Rowkey。
3.2 Rowkey生成
抽取的Rowkey如何生成,這里可能根據實際的數量級來確認Reduce個數。建議生成Rowkey文件時,切合實際的數據量來算Reduce的個數。盡量不用為了使用方便就一個HDFS文件,這樣后面不好維護。舉個例子,比如HBase表有100GB,我們可以拆分為100個文件。
3.3 數據處理
在步驟1中,按照抽取規則和存儲規則,將數據從HBase中通過MapReduce抽取Rowkey并存儲到HDFS上。然后,我們在通過MapReduce任務讀取HDFS上的Rowkey文件,通過List的方式去HBase中獲取數據。拆解細節如下:

Map階段,我們從HDFS讀取Rowkey的數據文件,然后通過批量Get的方式從HBase取數,然后組裝數據發送到Reduce階段。在Reduce階段,獲取來自Map階段的數據,寫數據到Kafka,通過Kafka生產者回調函數,獲取寫入Kafka狀態信息,根據狀態信息判斷數據是否寫入成功。如果成功,記錄成功的Rowkey到HDFS,便于統計成功的進度;如果失敗,記錄失敗的Rowkey到HDFS,便于統計失敗的進度。
3.4 失敗重跑
通過MapReduce任務寫數據到Kafka中,可能會有失敗的情況,對于失敗的情況,我們只需要記錄Rowkey到HDFS上,當任務執行完成后,再去程序檢查HDFS上是否存在失敗的Rowkey文件,如果存在,那么再次啟動步驟3,即讀取HDFS上失敗的Rowkey文件,然后再List HBase中的數據,進行數據處理后,最后再寫Kafka,以此類推,直到HDFS上失敗的Rowkey處理完成為止。
4.實現代碼
這里實現的代碼量也并不復雜,下面提供一個偽代碼,可以在此基礎上進行改造(例如Rowkey的抽取、MapReduce讀取Rowkey并批量Get HBase表,然后在寫入Kafka等)。示例代碼如下:
- public class MRROW2HDFS {
- public static void main(String[] args) throws Exception {
- Configuration config = HBaseConfiguration.create(); // HBase Config info
- Job job = Job.getInstance(config, "MRROW2HDFS");
- job.setJarByClass(MRROW2HDFS.class);
- job.setReducerClass(ROWReducer.class);
- String hbaseTableName = "hbase_tbl_name";
- Scan scan = new Scan();
- scan.setCaching(1000);
- scan.setCacheBlocks(false);
- scan.setFilter(new FirstKeyOnlyFilter());
- TableMapReduceUtil.initTableMapperJob(hbaseTableName, scan, ROWMapper.class, Text.class, Text.class, job);
- FileOutputFormat.setOutputPath(job, new Path("/tmp/rowkey.list")); // input you storage rowkey hdfs path
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- public static class ROWMapper extends TableMapper<Text, Text> {
- @Override
- protected void map(ImmutableBytesWritable key, Result value,
- Mapper<ImmutableBytesWritable, Result, Text, Text>.Context context)
- throws IOException, InterruptedException {
- for (Cell cell : value.rawCells()) {
- // Filter date range
- // context.write(...);
- }
- }
- }
- public static class ROWReducer extends Reducer<Text,Text,Text,Text>{
- private Text result = new Text();
- @Override
- protected void reduce(Text key, Iterable<Text> values,Context context) throws IOException, InterruptedException {
- for(Text val:values){
- result.set(val);
- context.write(key, result);
- }
- }
- }
- }
5.總結
整個逆向數據處理流程,并不算復雜,實現也是很基本的MapReduce邏輯,沒有太復雜的邏輯處理。在處理的過程中,需要幾個細節問題,Rowkey生成到HDFS上時,可能存在行位空格的情況,在讀取HDFS上Rowkey文件去List時,最好對每條數據做個過濾空格處理。另外,就是對于成功處理Rowkey和失敗處理Rowkey的記錄,這樣便于任務失敗重跑和數據對賬。可以知曉數據遷移進度和完成情況。同時,我們可以使用 Kafka Eagle 監控工具來查看Kafka寫入進度。