為什么會產(chǎn)生微服務架構(gòu),原來是這些原因
Web應用架構(gòu)受系統(tǒng)用戶量、開發(fā)人員組織方式影響嚴重。過去二十年互聯(lián)網(wǎng)迅速發(fā)展,Web架構(gòu)也從單體式演進出微服務,背后還有比如 Martin Fowler 提出的理論支撐。雖然每個人都聽說過微服務,但是很多人并不太清楚為什么要這么做,應該怎么做,怎么拆。要回答這個問題我認為需要從Web架構(gòu)的演化歷史的高度去理解這些架構(gòu)設(shè)計中的取舍。
首先我們改進系統(tǒng)架構(gòu)的目的是為了滿足系統(tǒng)可靠性、并發(fā)量以及快速開發(fā)的需求。所有的改進方案都是為了解決這其中一個或多個問題而產(chǎn)生的。
單體結(jié)構(gòu)
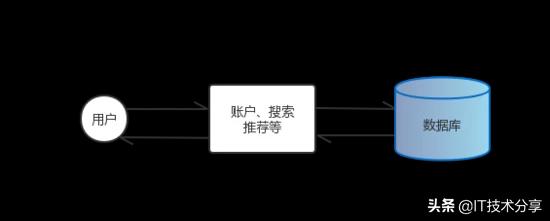
單體結(jié)構(gòu)
最開始Web服務器、數(shù)據(jù)庫全部部署在同一臺服務器上,這也是最簡單的應用架構(gòu),通常公司早期項目都采用這種方式。在很長一段時間里單體結(jié)構(gòu)可以滿足系統(tǒng)快速開發(fā)與并發(fā)量的需求。當用戶量越來越大,通常會數(shù)據(jù)庫性能會成為系統(tǒng)瓶頸,此時可以將Web業(yè)務與數(shù)據(jù)庫部署在不同服務器上,增強數(shù)據(jù)庫服務器的配置并做讀寫分離等提高系統(tǒng)的吞吐量與可用性。
與此同時也可以將業(yè)務系統(tǒng)等價部署在多臺服務器上來提高系統(tǒng)吞吐量,但整體上這仍然是一個單體應用。
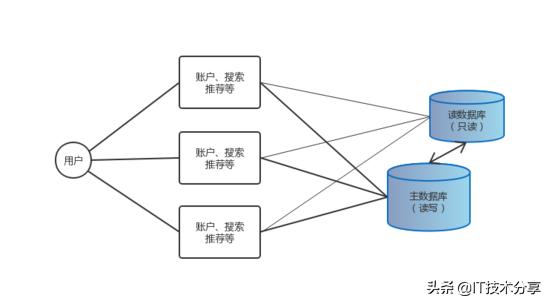
單體等價部署
隨著用戶、數(shù)據(jù)量進一步增大,單體應用的缺點會進一步顯露出來,比如:
- 耦合嚴重、復雜度高、可靠性差 :單體應用越來越來很多業(yè)務會耦合在一起,一但某些模塊出現(xiàn)Bug會影響整個系統(tǒng)正常運行,業(yè)務代碼的耦合也會形成開發(fā)人員的依賴造成新業(yè)務難以推進
- 增加技術(shù)債、部署困難效率差 :技術(shù)債越來越多容易會造成“不壞不修“的囧境,已完成的代碼難以被修改以防止系統(tǒng)某個地方意料之外的調(diào)用。同于由于代碼量大導致應用全量部署困難
- 系統(tǒng)吞吐量受限、阻礙技術(shù)進步 :單體應用難以進一步擴展使系統(tǒng)吞吐量受限,同時單體應用要求使用統(tǒng)一技術(shù)平臺或解決方案,要想引入新語言或框架會非常困難
拆分
應用規(guī)模越來越大,首先遇到瓶頸的可能就是數(shù)據(jù)庫系統(tǒng),面對數(shù)據(jù)庫壓力通常我們可以對數(shù)據(jù)庫做拆分把負載分擔到不同的服務器上來解決,通常數(shù)據(jù)庫拆分有兩種方案:
- 垂直拆分:對不同的業(yè)務系統(tǒng)如賬戶、搜索、推薦系統(tǒng)使用不同的數(shù)據(jù)庫
- 水平拆分:對于大表,比如十億百億級別的,進行多表拆分
數(shù)據(jù)庫水平拆分與業(yè)務邏輯耦合緊密,需要具體問題具體分析,通常這是一個非常復雜的問題。后來人們引入 NoSQL、NewSQL 用分布式概念在數(shù)據(jù)庫層屏蔽掉數(shù)據(jù)庫的水平拆分,比如 NoSQL 的 MongoDB Sharding,NewSQL 的 TiDB。
同樣的在業(yè)務層上我們也可以通過垂直拆分和水平拆分將單體業(yè)務拆成不同的服務,服務之間通過約定好的協(xié)議通信,以提高人員開發(fā)效率,實現(xiàn)多機部署冗余部署來提高系統(tǒng)可用性與吞吐量。
微服務
我們都知道微服務是一種提倡將單一服務拆分成一組小服務、服務之間相互協(xié)調(diào)、配合,提高開發(fā)效率,最終為用戶提供價值的思路。說到微服務那么這里面最重要的一個問題就是服務應該怎么拆。微服務作為 SOA(Service Oriented Architecture)思想的一種具體實踐我們首先想到的就是按照不同的業(yè)務系統(tǒng)做垂直拆分,如下圖所示:
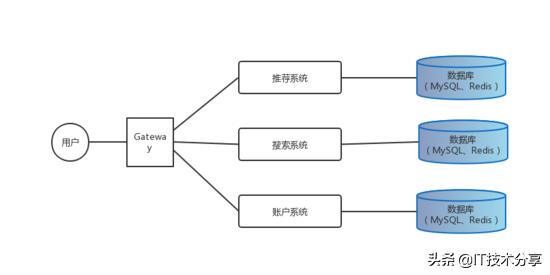
SOA垂直拆分
按業(yè)務系統(tǒng)對單體應用做垂直拆分,不同的業(yè)務線完全可以獨立配備產(chǎn)品經(jīng)歷與工程師同步開發(fā)維護,將不同業(yè)務線解耦出來有不同團隊維護。但上圖是一種理想情況,各系統(tǒng)拆分力度比較大,系統(tǒng)之間不需要更詳細的通信。如果是被拆除出了的子系統(tǒng)之間有大量的數(shù)據(jù)交互與調(diào)用,網(wǎng)關(guān)模式便不是一種很好的實踐,通常會將各業(yè)務子系統(tǒng)接入一個數(shù)據(jù)總線用 ESB(Enterprise Service Bus)模式來進行數(shù)據(jù)交互,各子系統(tǒng)與數(shù)據(jù)總線進行數(shù)據(jù)交換便需要對子系統(tǒng)做統(tǒng)一管理,這遍有了 服務治理 的概念,用一套統(tǒng)一的保準來處理各子系統(tǒng)的注冊、權(quán)限、監(jiān)控等,目前有很多 ESB 開源或閉源的解決方案,這里不再贅述。
垂直拆分將各業(yè)務子系統(tǒng)解耦出來,但是每次請求在不同階段遇到的瓶頸與負載是不一樣的,因此我們對可以使用水平拆分的思路對服務進行拆分:
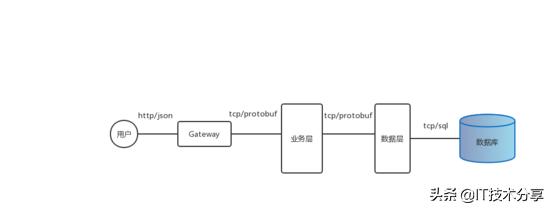
水平拆分
首先用戶請求通過http協(xié)議到達網(wǎng)關(guān),網(wǎng)關(guān)將json數(shù)據(jù)格式轉(zhuǎn)為protobuf,通過tcp長鏈接與服務層、數(shù)據(jù)層通信獲取目標數(shù)據(jù)然后返回給用戶。這樣拆分加長了用戶請求鏈路時延,但是如果服務全部部署在同一內(nèi)網(wǎng),而且使用protobuf格式通信那么這個時延在幾十毫秒內(nèi)是完全可以接受的。業(yè)務層與數(shù)據(jù)層完全解耦便可以輕松將不同類型的服務進入冗余部署,同時在不動業(yè)務層的同時修改它的數(shù)據(jù)存儲方式。
如果我們對系統(tǒng)即做垂直拆分也做水分拆分,那么就有了微服務的樣子,
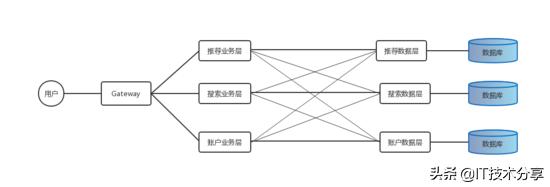
水平拆分
每級服務只能調(diào)用比他低級別的服務,如果搜索服務層只能掉賬戶接口層服務而不能調(diào)賬戶服務層接口,這樣可以用來避免服務A調(diào)用服務B,而服務B同時又調(diào)用了服務A的循環(huán)調(diào)用問題。但是這樣的拆分粒度仍然不夠的,比如搜索系統(tǒng)和推薦系統(tǒng)都要調(diào)用賬戶系統(tǒng)的一些基礎(chǔ)查詢、修改邏輯,那么需要在搜索與推薦的服務層兩次實現(xiàn)同樣的代碼嗎,這樣顯然是不合理了,任何不能復用的設(shè)計顯然都是有問題的。如果通過編寫SDK庫提供Jar包的模式去實現(xiàn)這個功能呢?,顯然也存在問題比如推薦系統(tǒng)是Python實現(xiàn),而搜索系統(tǒng)是Java實現(xiàn)的呢?所以這里我們將每個子系統(tǒng)可共用代碼部分也單獨抽取出來作為一個服務。
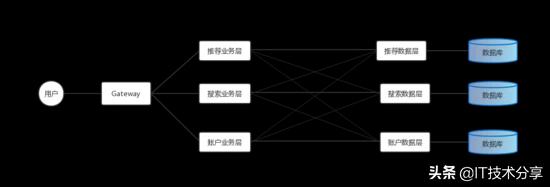
水平拆分2
這樣拆分后的系統(tǒng)可以靈活部署,獨立開發(fā),并且各模塊服務使用的技術(shù)棧相對獨立不受限制。但是同時拆分也將系統(tǒng)的網(wǎng)絡(luò)拓撲便的復雜,運維負擔加重,服務間的依賴使得服務接口的調(diào)整成本非常高。服務增多的同時對服務治理的要求也更高,需要專門做服務的發(fā)現(xiàn)、注冊、鑒權(quán)、監(jiān)控等系統(tǒng)功能。