













盤口數(shù)據(jù)頻繁變化,100W用戶如何實時通知?

繼續(xù)答星球水友提問:盤口數(shù)據(jù)頻繁變化,如何做緩存與推送,如何降低數(shù)據(jù)庫壓力?
并沒有做過相關(guān)的業(yè)務(wù),結(jié)合自己的架構(gòu)經(jīng)驗,說說自己的思路和想法,希望對大家有啟示。
一、業(yè)務(wù)抽象
- 有很多客戶端關(guān)注盤口,假設(shè)百萬級別;
- 數(shù)據(jù)量不一定很大,上市交易的股票個數(shù),假設(shè)萬級別;
- 寫的量比較大,每秒鐘有很多交易發(fā)生,假設(shè)每秒百級別;
- 計算比較復(fù)雜,有求和/分組/排序等操作;
二、潛在技術(shù)折衷
1. 客戶端與服務(wù)端連接如何選型?
首先,盤口客戶端與服務(wù)器建立TCP長連接,而不是每次請求都建立與銷毀短連接,能極大提升性能,降低服務(wù)器壓力。
2. 業(yè)務(wù)的實時性如何滿足?
盤口業(yè)務(wù),對數(shù)據(jù)實時性的要求較高,服務(wù)端可以通過TCP長連接推送,保證消息的實時性。
由于推送量級巨大,可以獨立推送集群,專門實施推送。推送集群獨立化之后,增加推送服務(wù)器數(shù)量,就可以線性提升推送能力。
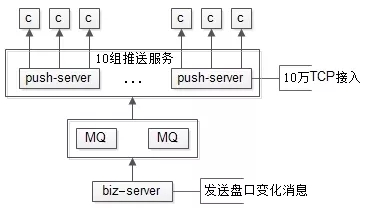
如上圖所示,假設(shè)有100W用戶接收實時推送:
- 搭建專門的推送集群,維護(hù)與客戶端的tcp長連接,實時推送
- 每臺推送服務(wù)維護(hù)10W長連接,10臺推送服務(wù)即可服務(wù)100W用戶
- 推送集群與業(yè)務(wù)集群之間,通過MQ解耦,推送集群只單純的推送消息,無任何業(yè)務(wù)邏輯計算,推送消息的內(nèi)容,都是業(yè)務(wù)集群計算好的
3. 推送服務(wù)最大的瓶頸是,如何將一條消息,最快的推送給與之連接的10W個客戶端?
- 如果消息量不大,例如幾秒鐘一個消息,可以開多線程,例如100個線程,并發(fā)推送
畫外音:對應(yīng)水友提到的,如果量不大,可以成交一筆推送一筆。
- 如果消息量過大,例如一秒鐘幾百個消息,可以將消息暫存一秒,批量推送
畫外音:對應(yīng)水友提到的,如果消息量巨大,批量推送是很好的方法。
4. 數(shù)據(jù)量,寫入量,擴(kuò)展性如何滿足?
股票個數(shù)較少,數(shù)據(jù)量不是瓶頸。
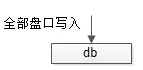
流水?dāng)?shù)據(jù)寫入量,每秒百級別,甚至千級別,數(shù)據(jù)庫寫性能也不是瓶頸,理論上一個庫可以抗住。
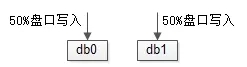
假如每秒寫入量達(dá)到萬級別,可以在數(shù)據(jù)庫層面實施水平切分,將不同股票的流水拆到不同水平切分的庫里去,就能線性增加數(shù)據(jù)庫的寫入量。
畫外音:水平拆分后,同一個股票,數(shù)據(jù)在同一個庫里,不同股票,可能在不同的庫里,理論上不會有跨庫查詢的需求。
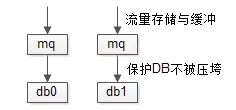
如果每秒寫入量達(dá)到十萬,百萬級別,還可以加入MQ緩沖請求,削峰填谷,保護(hù)數(shù)據(jù)庫。
如論如何,根據(jù)本業(yè)務(wù)的數(shù)據(jù)量與寫入量,單庫應(yīng)該是沒有問題的。
5. 復(fù)雜的業(yè)務(wù)邏輯操作,如何滿足?
本業(yè)務(wù)的寫入量不大,但讀取量很大,肯定不能每個讀取請求都sum/group by/order by,這樣數(shù)據(jù)庫肯定扛不住。
水友已經(jīng)想到了,可以用緩存來降低數(shù)據(jù)庫的壓力,但擔(dān)心“隨著時間的推移,這個偏差勢必會慢慢放大”。
關(guān)于緩存的一致性的放大,可以這么搞:
- 做一個異步的線程,每秒鐘訪問一次數(shù)據(jù)庫,將復(fù)雜的業(yè)務(wù)邏輯計算出來,放入高可用緩存
- 所有的讀請求不再耦合業(yè)務(wù)邏輯計算,都直接從高可用緩存讀結(jié)果
如此一來,復(fù)雜業(yè)務(wù)邏輯的計算,每秒鐘只會有一次。
帶來的問題是,一秒內(nèi)可能有很多流水寫入數(shù)據(jù)庫,但不會實時的反應(yīng)到緩存里,用戶最差情況下,會讀到一秒前的盤口數(shù)據(jù)。
無論如何,這是一個性能與一致性的設(shè)計折衷。
上面的所有方案,都是基于在線客戶量級巨大,推送消息巨大的前提下,采用推送方案。很多時候,工程師都會妄加猜測,把問題想得很復(fù)雜,把方案搞得很復(fù)雜。
如果在線用戶量很小,用戶能夠接受的盤口時延較長(例如5s),完全可以采用輪詢拉取方案:
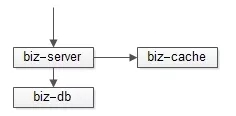
- 取消整個推送集群與MQ集群;
- 盤口數(shù)據(jù),異步線程每1s寫入高可用緩存一次;
- 客戶端每5s輪詢拉取最新的盤口數(shù)據(jù),都只從緩存中拉取;
搞定!
反正,肯定不能每個讀請求都sum/group by/order by掃庫計算,這個是最需要優(yōu)化的。
三、總結(jié)
- 長連接比短連接性能好很多倍
- 推送量巨大時,推送集群需要與業(yè)務(wù)集群解耦
- 推送量巨大時,并發(fā)推送與批量推送是一個常見的優(yōu)化手段
- 寫入量巨大時,水平切分能夠擴(kuò)容,MQ緩沖可以保護(hù)數(shù)據(jù)庫
- 業(yè)務(wù)復(fù)雜,讀取量巨大時,加入緩存,定時計算,能夠極大降低數(shù)據(jù)庫壓力
思路比結(jié)論重要,希望大家有收獲。
【本文為51CTO專欄作者“58沈劍”原創(chuàng)稿件,轉(zhuǎn)載請聯(lián)系原作者】





















