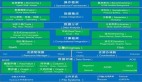
每秒千萬級實時數據處理系統是如何設計的?
閑魚目前實際生產部署環境越來越復雜,橫向依賴各種服務盤根錯節,縱向依賴的運行環境也越來越復雜。
圖片來自 Pexels
當服務出現問題的時候,能否及時在海量的數據中定位到問題根因,成為考驗閑魚服務能力的一個嚴峻挑戰。
線上出現問題時常常需要十多分鐘,甚至更長時間才能找到問題原因,因此一個能夠快速進行自動診斷的系統需求就應運而生,而快速診斷的基礎是一個高性能的實時數據處理系統。
這個實時數據處理系統需要具備如下的能力:
- 數據實時采集、實時分析、復雜計算、分析結果持久化。
- 可以處理多種多樣的數據。包含應用日志、主機性能監控指標、調用鏈路圖。
- 高可靠性。系統不出問題且數據不能丟。
- 高性能,低延時。數據處理的延時不超過 3 秒,支持每秒千萬級的數據處理。
本文不涉及問題自動診斷的具體分析模型,只討論整體實時數據處理鏈路的設計。
輸入輸出定義
為了便于理解系統的運轉,我們定義該系統整體輸入和輸出。
輸入
服務請求日志(包含 traceid、時間戳、客戶端 IP、服務端 IP、耗時、返回碼、服務名、方法名)。
環境監控數據(指標名稱、IP、時間戳、指標值)。比如 CPU、 JVM GC 次數、JVM GC 耗時、數據庫指標。
輸出
一段時間內的某個服務出現錯誤的根因,每個服務的錯誤分析結果用一張有向無環圖表達。(根節點即是被分析的錯誤節點,葉子節點即是錯誤根因節點。葉子節點可能是一個外部依賴的服務錯誤也可能是 JVM 異常等等)。
架構設計
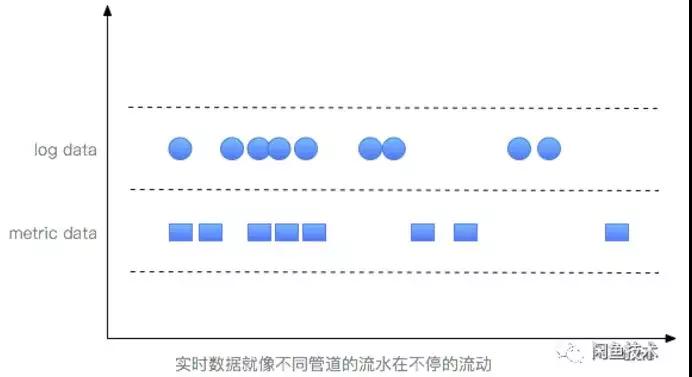
在實際的系統運行過程中,隨著時間的推移,日志數據以及監控數據是源源不斷的在產生的。
每條產生的數據都有一個自己的時間戳。而實時傳輸這些帶有時間戳的數據就像水在不同的管道中流動一樣。
如果把源源不斷的實時數據比作流水,那數據處理過程和自來水生產的過程也是類似的:
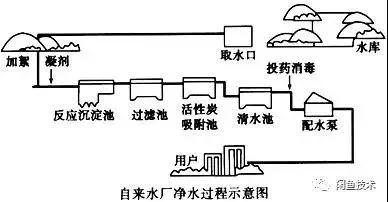
自然地,我們也將實時數據的處理過程分解成采集、傳輸、預處理、計算、存儲、計算與持久化幾個階段。
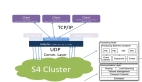
整體的系統架構設計如下:
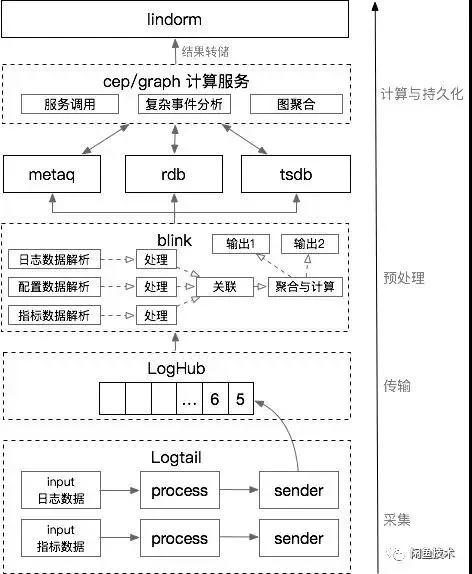
采集
采用阿里自研的 SLS 日志服務產品(包含 Logtail+LogHub 組件),Logtail 是采集客戶端。
之所以選擇 Logtail 是因為其優秀的性能、高可靠性以及其靈活插件擴展機制,閑魚可以定制自己的采集插件實現各種各樣數據的實時采集。
傳輸
Loghub 可以理解為一個數據發布訂閱組件,和 Kafka 的功能類似,作為一個數據傳輸通道其更穩定、更安全。
詳細對比文章參考:
- https://yq.aliyun.com/articles/35979?spm=5176.10695662.1996646101.searchclickresult.6f2c7fbe6g3xgP
預處理
實時數據預處理部分采用 Blink 流計算處理組件(開源版本叫做 Flink,Blink 是阿里在 Flink 基礎上的內部增強版本)。
目前常用的實時流計算開源產品有 Jstorm、Spark Stream、Flink:
- Jstorm 由于沒有中間計算狀態的,其計算過程中需要的中間結果必然依賴于外部存儲,這樣會導致頻繁的 IO 影響其性能。
- Spark Stream 本質上是用微小的批處理來模擬實時計算,實際上還是有一定延時。
- Flink 由于其出色的狀態管理機制保證其計算的性能以及實時性,同時提供了完備 SQL 表達,使得流計算更容易。
計算與持久化
數據經過預處理后最終生成調用鏈路聚合日志和主機監控數據,其中主機監控數據會獨立存儲在 TSDB 時序數據庫中,供后續統計分析。
TSDB 由于其針對時間指標數據的特別存儲結構設計,非常適合做時序數據的存儲與查詢。
調用鏈路日志聚合數據,提供給 Cep/Graph Service 做診斷模型分析。
Cep/Graph Service 是閑魚自研的一個應用,實現模型分析、復雜的數據處理以及外部服務進行交互,同時借助 RDB 實現圖數據的實時聚合。
最后 Cep/Graph Service 分析的結果作為一個圖數據,實時轉儲在 Lindorm 中提供在線查詢。Lindorm 可以看作是增強版的 Hbase,在系統中充當持久化存儲的角色。
詳細設計與性能優化
采集
日志和指標數據采集使用 Logtail,整個數據采集過程如圖:
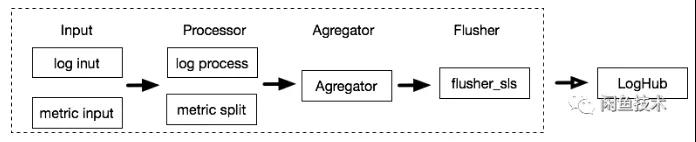
其提供了非常靈活的插件機制,共有四種類型的插件:
- Inputs:輸入插件,獲取數據。
- Processors:處理插件,對得到的數據進行處理。
- Aggregators:聚合插件,對數據進行聚合。
- Flushers:輸出插件,將數據輸出到指定 Sink。
由于指標數據(比如 CPU、內存、JVM 指標)的獲取需要調用本地機器上的服務接口獲取,因此應盡量減少請求次數,在 Logtail 中,一個 Input 占用一個 Goroutine。
閑魚通過定制 Input 插件和 Processors 插件,將多個指標數據(比如 CPU、內存、JVM 指標)在一個 Input 插件中通過一次服務請求獲取(指標獲取接口由基礎監控團隊提供)。
并將其格式化成一個 Json 數組對象,在 Processors 插件中再拆分成多條數據,以減少系統的 IO 次數同時提升性能。
傳輸
數據傳輸使用 LogHub,Logtail 寫入數據后直接由 Blink 消費其中的數據,只需設置合理的分區數量即可。
分區數要大于等于 Blink 讀取任務的并發數,避免 Blink 中的任務空轉。
預處理
預處理主要采用 Blink 實現,主要的設計和優化點:
①編寫高效的計算流程
Blink 是一個有狀態的流計算框架,非常適合做實時聚合、Join 等操作。在我們的應用中只需要關注出現錯誤的的請求上相關服務鏈路的調用情況。
因此整個日志處理流分成兩個流:
- 服務的請求入口日志作為一個單獨的流來處理,篩選出請求出錯的數據。
- 其他中間鏈路的調用日志作為另一個獨立的流來處理,通過和上面的流 Join On Traceid 實現出錯服務依賴的請求數據篩選。
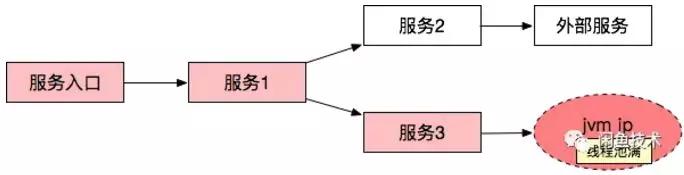
如上圖所示通過雙流 Join 后,輸出的就是所有發生請求錯誤相關鏈路的完整數據。
②設置合理的 State 生命周期
Blink 在做 Join 的時候本質上是通過 State 緩存中間數據狀態,然后做數據的匹配。
而如果 State 的生命周期太長會導致數據膨脹影響性能,如果 State 的生命周期太短就會無法正常關聯出部分延遲到來的數據,所以需要合理的配置 State 生存周期,對于該應用允許最大數據延遲為 1 分鐘。
- 使用niagara作為statebackend,以及設定state數據生命周期,單位毫秒
- state.backend.type=niagara
- state.backend.niagara.ttl.ms=60000
③開啟 MicroBatch/MiniBatch
MicroBatch 和 MiniBatch 都是微批處理,只是微批的觸發機制上略有不同。原理上都是緩存一定的數據后再觸發處理,以減少對 State 的訪問從而顯著提升吞吐,以及減少輸出數據量。
- 開啟join
- blink.miniBatch.join.enabled=true
- 使用 microbatch 時需要保留以下兩個 minibatch 配置
- blink.miniBatch.allowLatencyMs=5000
- 防止OOM,每個批次最多緩存多少條數據
- blink.miniBatch.size=20000
④Dynamic-Rebalance 替代 Rebalance
Blink 任務在運行時最忌諱的就是存在計算熱點,為保證數據均勻使用 Dynamic Rebalance,它可以根據當前各 Subpartition 中堆積的 Buffer 的數量,選擇負載較輕的 Subpartition 進行寫入,從而實現動態的負載均衡。
相比于靜態的 Rebalance 策略,在下游各任務計算能力不均衡時,可以使各任務相對負載更加均衡,從而提高整個作業的性能。
- 開啟動態負載
- task.dynamic.rebalance.enabled=true
⑤自定義輸出插件
數據關聯后需要將統一請求鏈路上的數據作為一個數據包通知下游圖分析節點,傳統的方式是通過消息服務來投遞數據。
但是通過消息服務有兩個缺點:
- 其吞吐量和 RDB 這種內存數據庫相比還是較大差距(大概差一個數量級)。
- 在接受端還需要根據 traceid 做數據關聯。
我們通過自定義插件的方式將數據通過異步的方式寫入 RDB,同時設定數據過期時間。
在 RDB 中以
寫入的同時只將 traceid 做為消息內容通過 MetaQ 通知下游計算服務,極大的減少了 MetaQ 的數據傳輸壓力。
圖聚合計算
Cep/Graph 計算服務節點在接收到 MetaQ 的通知后,綜合根據請求的鏈路數據以及依賴的環境監控數據,會實時生成診斷結果。
診斷結果簡化為如下形式:
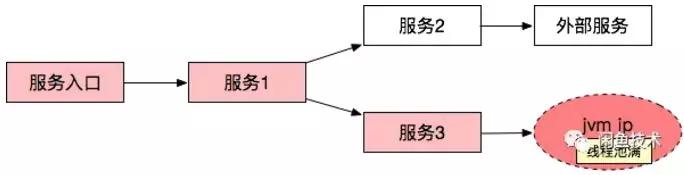
說明本次請求是由于下游 JVM 的線程池滿導致的,但是一次調用并不能說明該服務是不可用的根本原因,需要分析整體的錯誤情況,那就需要對圖數據做實時聚合。
聚合設計如下(為了說明基本思路,做了簡化處理):
- 首先利用 Redis 的 Zrank 能力為根據服務名或 IP 信息為每個節點分配一個全局唯一排序序號。
- 為圖中的每個節點生成對應圖節點編碼,編碼格式。
- 對于頭節點:頭節點序號|歸整時間戳|節點編碼。
- 對于普通節點:|歸整時間戳|節點編碼。
- 由于每個節點在一個時間周期內都有唯一的 Key,因此可以將節點編碼作為 Key 利用 Redis 為每個節點做計數。同時消除了并發讀寫的問題。
- 利用 Redis 中的 Set 集合可以很方便的疊加圖的邊。
- 記錄根節點,即可通過遍歷還原聚合后的圖結構。
聚合后的結果大致如下:
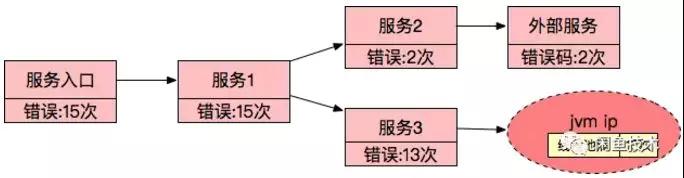
這樣最終生成了服務不可用的整體原因,并且通過葉子節點的計數可以實現根因的排序。
收益
系統上線后,整個實時處理數據鏈路的延遲不超過 3 秒。閑魚服務端問題的定位時間從十多分鐘甚至更長時間下降到 5 秒內。大大的提升了問題定位的效率。
展望
目前的系統可以支持閑魚每秒千萬的數據處理能力。后續自動定位問題的服務可能會推廣到阿里內部更多的業務場景,隨之而來的是數據量的成倍增加,因此對于效率和成本提出了更好的要求。
未來我們可能做的改進:
- 能夠自動的減少或者壓縮處理的數據。
- 復雜的模型分析計算也可以在 Blink 中完成,減少 IO,提升性能。
- 支持多租戶的數據隔離。