詳解MySQL索引長度和區分度之間的平衡,值得收藏
概述
前面我們講了怎么去計算索引所占用的長度?那么換個方式想?索引又應該設置多少長度比較合理呢?
區分度與索引長度的權衡
首先索引長度和區分度是相互矛盾的,
索引長度太短,那么區分度就很低,吧索引長度加長,區分度就高,但是索引也是要占內存的,所以我們需要找到一個平衡點;
那么這個平衡點怎么來定?
比如用戶表有個字段 username ,要給他加索引,問題是索引長度多少合適?
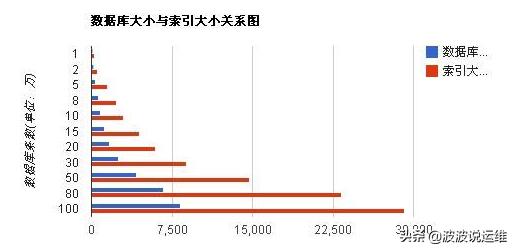
其實我們知道 百家姓里面有百多個姓 ,但是大多數人的姓 集中在前十多個;如果我設置索引索引長度為1,占內存少,但是區分度低,區分度低索引的效率越低。太長則占內存;
首先 mysql的索引都是排好序的。如果區分度高排序越快,區分度越低,排序慢;
舉個例子: (張,張三,張三哥),如果索引長度取1的話,那么每一行的索引都是 張 這個字,完全沒有區分度,你讓他怎么排序?結果這樣三行完全是隨機排的,因為索引都一樣;如果長度取2,那么排序的時候至少前兩個是排對了的,如果取3,區分度達到100%,排序完全正確;
那是不是索引越長越好? 答案肯定是錯的,比如 (張,李,王) 和 (張三啦啦啦,張三呵呵呵,張三呼呼呼);前者在內存中排序占得空間少,排序也快,后者明顯更慢更占內存。
總之:
索引長度越低,索引在內存中占的長度越小,排序越快,然而區分度就越低。這樣不利于查找。
索引長度越長,區分度就高,雖然利于查找了,但是索引在內存中占得空間就多了。
mysql創建索引的時候指定索引長度
大部分的索引前面一部分的長度就能夠有很好的區分度了。
通過減小索引長度,這樣能夠減小索引文件的大小,能夠加快數據的insert。
語法:
- CREATE INDEX index_name ON table_name (column_name(length), clolumn_name(length)…);
如何確認當前字段設置一個合適的長度呢?
索引長度與區分度要做一個取舍;這個取舍不是沒有一個固定的量;需要根據數據庫里面的數據來判斷;比較常規的公式是:
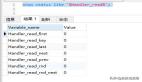
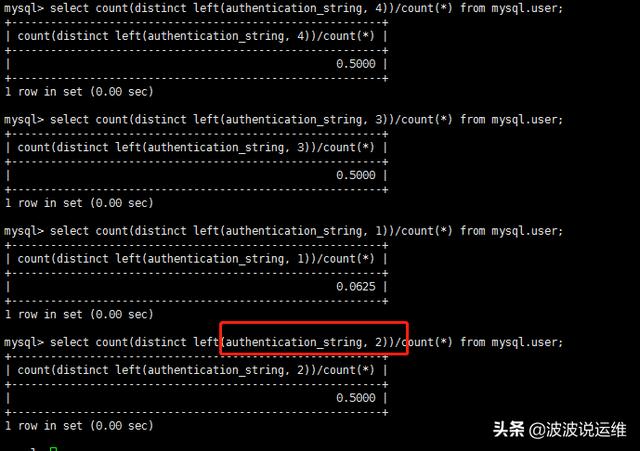
- select count(distinct left(password, 5))/count(*) from user
其中password是要加索引的字段,5是索引長度,求出一個浮點數,這個浮點數是逐漸趨向1的,上面這個比值,也算是區分度,也可以算作索引長度測試值,多測試幾組,找出最合適的來,一般的區分值在0.1左右就差不多了。
網上找了個圖片來分析下;
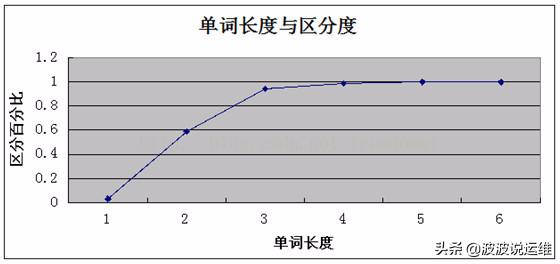
這個地方觀察到,當索引長度達到4的時候就已經趨向1了,所以長度設為4是最佳的,在大點增加的索引效果已經很小了,這個地方不是說必須接近1才行;總之要找一個平衡點;
還有一些特殊的字段常規方法用起不太順暢,比如有一個url字段,絕大部分的url都是 http://www. 開頭的,這種情況下索引長度取取到11都是無效的,需要更長的索引,那么有沒有優雅的方式來解決呢;
- 第一種方法: 可以將數據倒序存入數據庫;
- 第二種方法:對字符串進行crc32哈希處理;
兩種方法都不錯,當然要配合客戶端程序完成;
簡單測試:
這個方法可能是優化最后才考慮的點了,不建議太過深究,了解到這就行了。后面會分享更多devops和DBA方面的內容,感興趣的朋友可以關注一下~