優化體系 | 我是怎么計算MySQL數據庫索引長度的?
概述
我們知道MySQL Innodb 對于索引長度的限制為 767 字節,并且UTF8mb4字符集是4字節字符集,則 767字節 / 4字節每字符 = 191字符(默認索引最大長度),所以在varchar(255)或char(255) 類型字段上創建索引會失敗,提示最大索引長度為767字節。
那么怎么去計算mysql數據庫索引長度呢?
實驗測試
先看網上一道題目,針對表t,包含了三個字段a、b、c,假設其默認值都非空,現創建組合索引index(a,b,c) 分析select * from t where a=1 and c=1 和select * from t where a=1 and b=1區別?
1、創建表
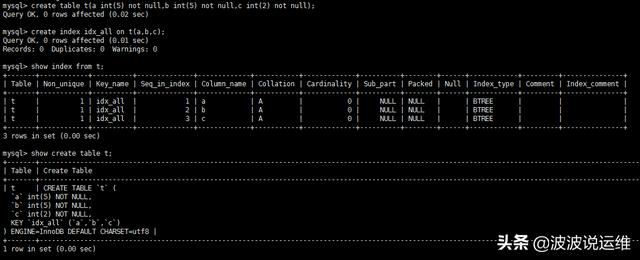
- create table t(a int(5) not null,b int(5) not null,c int(2) not null);
- create index idx_all on t(a,b,c);
2、分別執行這兩條語句
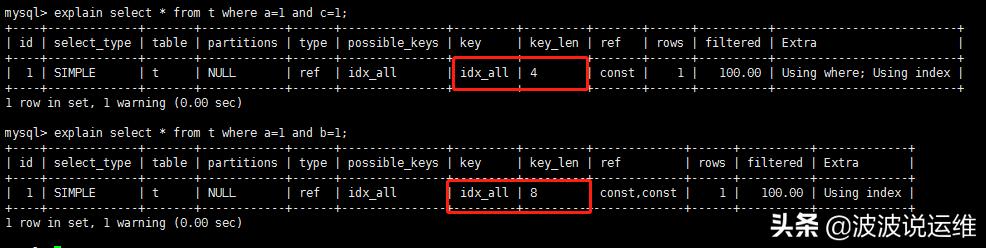
- mysql> explain select * from t where a=1 and c=1;
- mysql> explain select * from t where a=1 and b=1;
3、思路
這里可以發現,前面兩個的區別主要是在于key_len上,我的理解是:
將組合索引想成書的一級目錄、二級目錄、三級目錄,如index(a,b,c),相當于a是一級目錄,b是一級目錄下的二級目錄,c是二級目錄下的三級目錄。要使用某一目錄,必須先使用其上級目錄,除了一級目錄除外。
所以
where a=1 and c=1只使用了一級目錄,c在三級目錄,沒有使用二級目錄,那么三級目錄就沒法使用
where a=1 and b=1只使用了一級目錄、二級目錄。
于是第二條查詢的key_len更大。
但是,具體key_len怎么計算的,上面怎樣計算出是4和8的呢?
4、key_len的計算.
1.所有的索引字段,如果沒有設置not null,則需要加一個字節。
2.定長字段,int占四個字節、date占三個字節、char(n)占n個字符。
3.對于變成字段varchar(n),則有n個字符+兩個字節。
4.不同的字符集,一個字符占用的字節數不同。latin1編碼的,一個字符占用一個字節,gbk編碼的,一個字符占用兩個字節,utf8編碼的,一個字符占用三個字節。
5.索引長度 char()、varchar()索引長度的計算公式:
(Character Set:utf8mb4=4,utf8=3,gbk=2,latin1=1) * 列長度 + 1(允許null) + 2(變長列)
所以從上面可以得出
where a=1 and c=1而言,key_len=4
where a=1 and b=1而言,key_len=4+4=8
5、創建新的測試表t2
創建一個t2表,數據結構如下
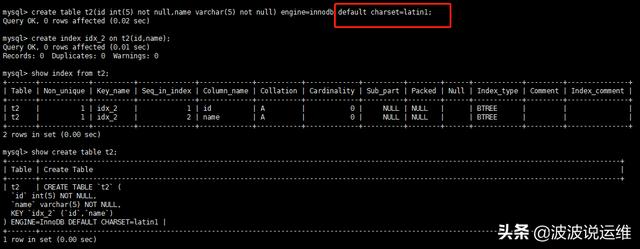
- create table t2(id int(5) not null,name varchar(5) not null) engine=innodb default charset=latin1;
- create index idx_2 on t2(id,name);
6、計算key_len
- explain select * from t2 where name="001" and id=1;

分析key_len=4+5*1+2=11,因為字段都是not null,int類型4個字節,varchar(5) 占用5個字符+2個字節,latin1編碼的表一個字符占1個字節,故varchar(5) 占用7個字節。
總結
因為MySQL具有查詢優化器,所以對where a=1 and c=1類型的查詢,字段順序沒有任何影響,查詢優化器會自動優化。where c=1 and a=1會被優化成where a=1 and c=1,但是建議還是使用where a=1 and c=1吧,便于理解以及查詢緩沖。