SQL:一種熟悉又陌生的編程語言,你了解他嗎?
一、SQL :一種熟悉又陌生的編程語言
這里有幾個關鍵詞;“熟悉”、“陌生”、“編程語言”。
說它“熟悉”,是因為它是DBA和廣大開發人員,操作數據庫的主要手段,幾乎每天都在使用。說它“陌生”,是很多人只是簡單的使用它,至于它是怎么工作的?如何才能讓它更高效的工作?卻從來沒有考慮過。
這里把SQL歸結為一種“編程語言”,可能跟很多人對它的認知不同。讓我們看看它的簡單定義(以下內容摘自百度百科)
結構化查詢語言(Structured Query Language),簡稱SQL,是一種特殊目的的編程語言,是一種數據庫查詢和程序設計語言,用于存取數據以及查詢、更新和管理關系數據庫系統。結構化查詢語言是高級的非過程化編程語言,允許用戶在高層數據結構上工作。它不要求用戶指定對數據的存放方法,也不需要用戶了解具體的數據存放方式,所以具有完全不同底層結構的不同數據庫系統, 可以使用相同的結構化查詢語言作為數據輸入與管理的接口。結構化查詢語言語句可以嵌套,這使它具有極大的靈活性和強大的功能。
總結一句話,SQL是一種非過程化的的編程語言,可通過它去訪問關系型數據庫系統。
二、你真的了解“SQL”嗎?
下面我會通過一個小例子,看看大家是否真正了解SQL。
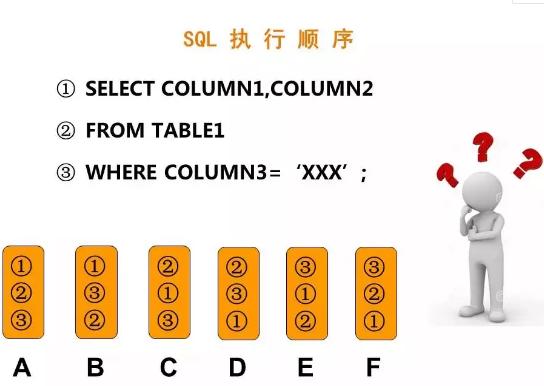
這是一個很簡單的示例,是關于SQL語句執行順序的。這里將一個普通的SELECT語句,拆分為三個子句。那么在實際的執行過程中,是按照什么順序處理的呢?這里有A-F六個選項,大家可以思考選擇一下…
最終的答案是D,即按照先執行FROM子句,然后WHERE子句,最后是SELECT部分。
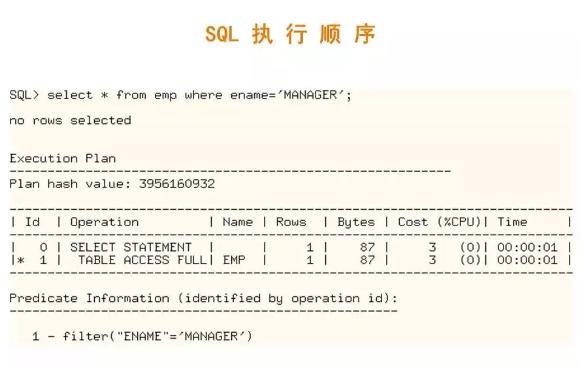
針對上面的示例,讓我們真實構造一個場景,通過查看執行計劃看看是否按照我們選擇的順序執行的。關于執行計劃的判讀,我后面會專門談到。這里我先解釋一下整個執行過程。
第一步,是按照全表掃描的方式訪問了對象表(EMP)。對應于語句中的FROM部分。
第二步,是對提取出的結果集進行了過濾(filter部分),即將滿足條件的記錄篩選出來。對應于語句中的WHERE部分。
第三步,是對滿足條件的記錄進行字段投射,即將需要顯示的字段提取出來。對應于語句中的SELECT部分。

這是一個詳細的SQL各部分執行順序的說明。
通過對執行順序的理解,可以為我們未來的優化工作帶來很大幫助。一個很淺顯的認識就是,優化動作越靠前越好。
三、SQL現在是否仍然重要?
這里引入了一個新的問題,在現有階段SQL語言是否還重要?
之所以引入這一話題,是因為隨著NOSQL、NEWSQL、BIGDATA等技術逐步成熟推廣,“SQL語言在現階段已經變得不那么重要”成為一些人的觀點。那實際情況又是如何呢?、
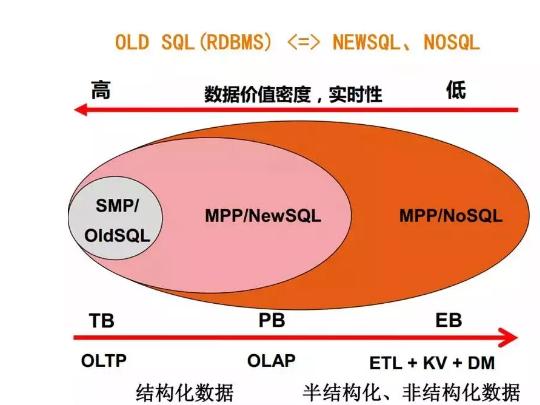
讓我們先來看一張經典的圖。圖中描述了傳統SMP架構的關系型數據庫、MPP架構的NEWSQL、MPP架構的NoSQL不同方案的適用場景對比。
從上面的“數據價值密度、實時性”來看,傳統關系型數據庫適合于價值密度更高、實時性要求更高的場景(這也就不難理解類似賬戶、金額類信息都是保存在傳統關系型數據庫中);MPP架構的NewSQL次之,MPP架構的NoSQL更適合于低價值、實時性要求不高的場景。
從下面的“數據規模”來看,傳統關系型數據庫適合保存的大小限制在TB級別,而后兩者可在更大尺度上(PB、EB)級保存數據。
從下面的“典型場景”來看,傳統關系型數據庫適合于OLTP在線交易系統;MPP架構的NewSQL適合于OLAP在線分析系統;而NoSQL的使用場景較多(利于KV型需求、數據挖掘等均可以考慮)。
最后從“數據特征”來看,前兩者適合于保存結構化數據,后者更適合于半結構化、乃至非結構化數據的保存。
歸納一下,不同技術有其各自特點,不存在誰代替誰的問題。傳統關系型數據庫有其自身鮮明特點,在某些場合依然是不二選擇。而作為其主要交互語言,SQL必然長期存在發展下去。
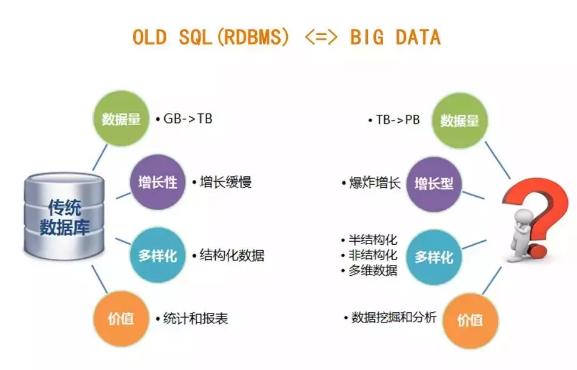
我們再來對比一下傳統數據庫與大數據技術。從數據量、增長型、多樣化、價值等維度對比兩種技術,各自有其適用場景。
對于大數據領域而言,各種技術層出不窮。但對于廣大使用者來說,往往會存在一定的使用門檻,因此現在的一種趨勢就是在大數據領域也引入“類SQL”,以類似SQL的方式訪問數據。這對于廣大使用者來說,無疑大大降低了使用門檻。
解答一些疑問:

NoSQL、NewSQL已經超越了傳統數據庫,SQL沒有了用武之地!
各種技術有著各自適合的不同場景,不能一概而論。SQL語言作為關系型數據庫的主要訪問方式,依然有其用武之地。
以后都是云時代了,誰還用關系型數據庫!
對于價值密度高,嚴格一致性的場景,仍然適合采用關系型數據庫作為解決方案。
我編程都是用OR Mapping工具,從不需要寫SQL!
的確,引入OR Mapping工具大大提高了生產效率,但是它的副作用也很明顯,那就是對語句的運行效率失去了控制。很多低效的語句,往往是通過工具直接生成的。這也是為什么有的Mapping工具還提供了原始的SQL接口,用來保證關鍵語句的執行效率。
大數據時代,我們都用Hadoop、Spark了,不用寫SQL啦!
無論是使用Hadoop、Spark都是可以通過編寫程序完成數據分析的,但其生產效率往往很低。這也是為什么產生了Hive 、Spark SQL等“類SQL”的解決方案來提高生產效率。
數據庫處理能力很強,不用太在意SQL性能!
的確,隨著多核CPU、大內存、閃存等硬件技術的發展,數據庫的處理能力較以前有了很大的增強。但是SQL的性能依然很重要。后面我們可以看到,一個簡單SQL語句就可以輕易地搞垮一個數據庫。
SQL優化,找DBA就行了,我就不用學了!
SQL優化是DBA的職責范疇,但對于開發人員來講,更應該對自己的代碼負責。如果能在開發階段就注重SQL質量,會避免很多低級問題。
我只是個運維DBA,SQL優化我不行!
DBA的發展可分為“運維DBA->開發DBA->數據架構師…”。如果只能完成數據庫的運維類工作,無疑是技能的欠缺,也是對各人未來發展不利。況且,隨著Paas云的逐步推廣,對于數據庫的運維需求越來越少,對于優化、設計、架構的要求越來越多。因此,SQL優化是每個DBA必須掌握的技能。
現在優化有工具了,很簡單的!
的確現在有些工具可以為我們減少些優化分析工作,會自動給出一些優化建議。但是,作為DBA來講,不僅要知其然,還要知其所以然。況且,數據庫優化器本身就是一個非常復雜的組件,很難做到完全無誤的優化,這就需要人工的介入,分析。
優化不就是加索引嘛,這有啥!
的確,加索引是一個非常常用的優化手段,但其不是唯一的。且很多情況下,加了索引可能導致性能更差。后面,會有一個案例說明。
四、SQL仍然很重要!
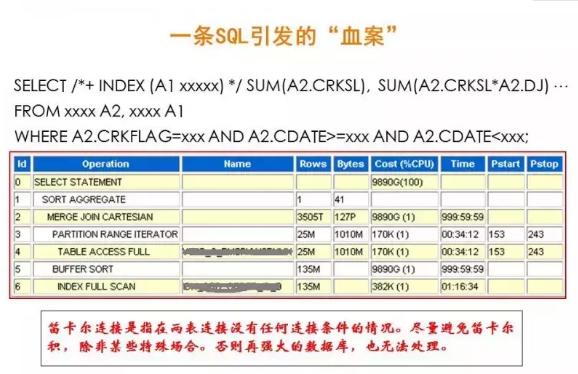
我們通過一個示例,說明一下理解SQL運行原理仍然很重要。
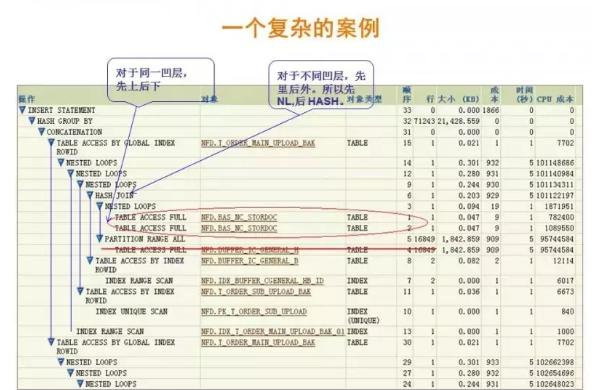
這是我在生產環境碰到的一個真實案例。Oracle數據庫環境,兩個表做關聯。執行計劃觸目驚心,優化器評估返回的數據量為3505T條記錄,計劃返回量127P字節,總成本9890G,返回時間999:59:59。
從執行計劃中可見,兩表關聯使用了笛卡爾積的關聯方式。我們知道笛卡爾連接是指在兩表連接沒有任何連接條件的情況。一般情況下應盡量避免笛卡爾積,除非某些特殊場合。否則再強大的數據庫,也無法處理。這是一個典型的多表關聯缺乏連接條件,導致笛卡爾積,引發性能問題的案例。
從案例本身來講,并沒有什么特別之處,不過是開發人員疏忽,導致了一條質量很差的SQL。但從更深層次來講,這個案例可以給我們帶來如下啟示:
開發人員的一個疏忽,造成了嚴重的后果,原來數據庫竟是如此的脆弱。需要對數據庫保持一種"敬畏"之心。
電腦不是人腦,它不知道你的需求是什么,只能用寫好的邏輯進行處理。
不要去責怪開發人員,誰都會犯錯誤,關鍵是如何從制度上保證不再發生類似的問題。
五、SQL優化法則
下面我們來看看常見的優化法則。這里所說的優化法則,其實是指可以從那些角度去考慮SQL優化的問題。可以有很多種方式去看待它。下面列舉一二。
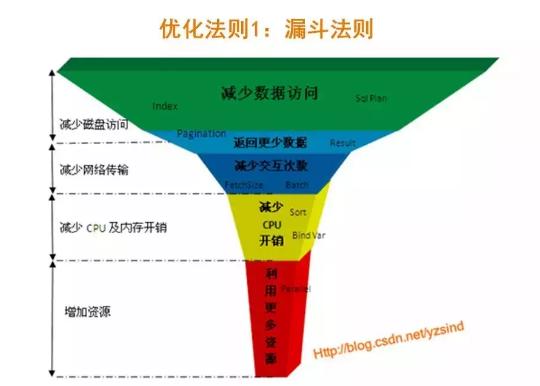
這里來自阿里-葉正盛的一篇博客里的一張圖,相信很多人都看過。這里提出了經典的漏斗優化法則,高度是指我們投入的資源,寬度是指可能實現的收益。從圖中可見,“減少數據訪問”是投入資源最少,而收益較多的方式;“增加硬件資源”是相對投入資源最多,而收益較少的一種方式。受時間所限,這里不展開說明了。

這是我總結的一個優化法則,簡稱為“DoDo”法則。
第一條,“Do Less or not do!”翻譯過來,就是盡量讓數據庫少做工作、甚至不做工作。
怎么樣來理解少做工作呢?比如創建索引往往可以提高訪問效率,其原理就是將原來的表掃描轉換為索引掃描,通過一個有序的結構,只需要少量的IO訪問就可以得到相應的數據,因此效率才比較高。這就可以歸納為少做工作。
怎么樣來理解不做工作呢?比如在系統設計中常見的緩存設計,很多是將原來需要訪問數據庫的情況,改為訪問緩存即可。這樣既提高了訪問效率,又減少了數據庫的壓力。從數據庫角度來說,這就是典型的不做工作。
第二條,“If must do,do it fast!”翻譯過來,如果數據庫必須做這件事件,那么請盡快做完它。
怎么樣來理解這句話呢?比如數據庫里常見的并行操作,就是通過引入多進程來加速原來的執行過程。加速處理過程,可以少占用相關資源,提高系統整體吞吐量。
六、SQL 執行過程
SQL的執行過程比較復雜,不同數據庫有一定差異。下面介紹以兩種主流的數據庫(Oracle、MySQL)介紹一下。
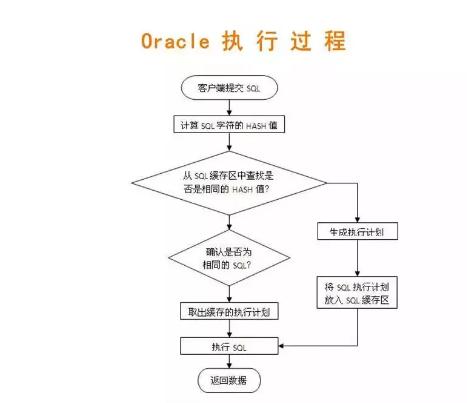
用戶提交了一條SQL語句
數據庫按照SQL語句的字面值計算出一個HASH值
根據HASH值,判斷一下在數據庫緩沖區中是否存在此SQL的執行計劃。
如果不存在,則需要生成一個執行計劃(硬解析過程),然后將結果存入緩沖區。
如果存在的話,判斷是否為相同SQL(同樣HASH值的語句,可能字符不相同;即使完全相同,也可能代表不同的語句。這塊不展開說了)
確認是同一條SQL語句,則從緩沖區中取出執行計劃。
將執行計劃,交給執行器執行。
結果返回給客戶端。
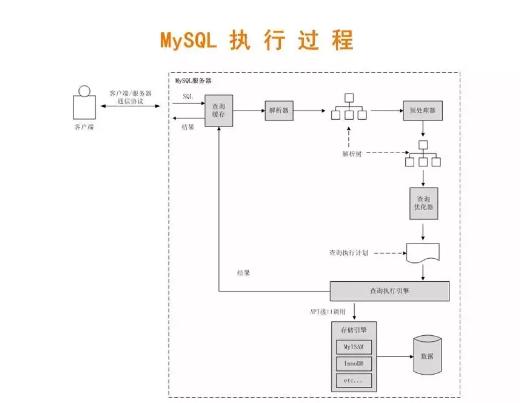
客戶提交一條語句
現在查詢緩存查看是否存在對應的緩存數據,如有則直接返回(一般有的可能性極小,因此一般建議關閉查詢緩存)。
交給解析器處理,解析器會將提交的語句生成一個解析樹。
預處理器會處理解析樹,形成新的解析樹。這一階段存在一些SQL改寫的過程。
改寫后的解析樹提交給查詢優化器。查詢優化器生成執行計劃。
執行計劃交由執行引擎調用存儲引擎接口,完成執行過程。這里要注意,MySQL的Server層和Engine層是分離的。
最終的結果有執行引擎返回給客戶端,如果開啟查詢緩存的話,則會緩存。
七、SQL優化器
在上面的執行過程描述中,多次提高了優化器。它也是數據庫中最核心的組件。下面我們來介紹一下優化器。

上面是我對優化器的一些認識。優化器是數據庫的精華所在,值得DBA去認真研究。但是遺憾的是,數據庫對這方面的開放程度并不夠。(相對來說,Oracle還是做的不錯的)
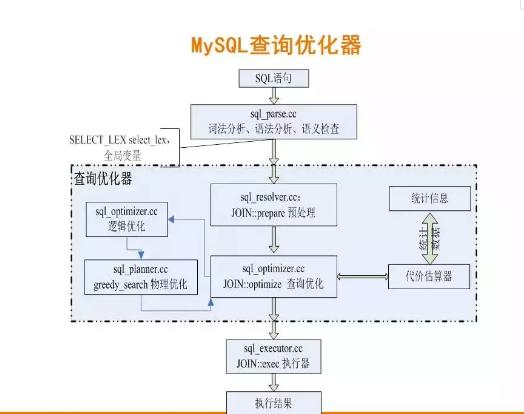
這里我們看到的MySQL的優化器的工作過程,大致經歷了如下處理:
詞法分析、語法分析、語義檢查
預處理階段(查詢改寫等)
查詢優化階段(可詳細劃分為邏輯優化、物理優化兩部分)
查詢優化器優化依據,來自于代價估算器估算結果(它會調用統計信息作為計算依據)
交由執行器執行
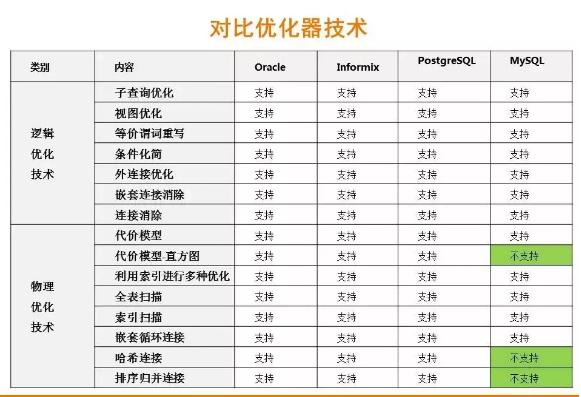
此圖是DBAplus社群MySQL原創專家李海翔對比不同數據庫優化器技術所總結的。從這里可以看出:
不同數據庫的實現層次不同,有些支持、有些不支持
即使支持,其實現原理也差異很大
這只是列出了一小部分優化技術
以上對比,也可以解釋不同數據庫對同樣語句的行為不同。下面會有一個示例說明
八、SQL 執行計劃

看懂執行計劃是DBA優化的前提之一,它為我們開啟一扇通往數據庫內部的窗口。但是很遺憾,從沒有一本書叫做“如何看懂執行計劃”,這里的情況非常復雜,很多是需要DBA常年積累而成。
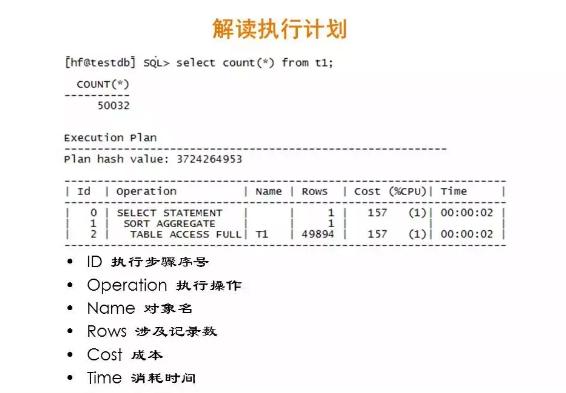
這是Oracle執行計劃簡單的示例,說明了執行計劃的大致內容。