Web攻擊檢測的機器學習深度實踐
一、概述
1. 傳統WAF的痛點
傳統的WAF,依賴規則和黑白名單的方式來進行Web攻擊檢測。該方式過分依賴安全人員的知識廣度,針對未知攻擊類型無可奈何;另一方面即使是已知的攻擊類型,由于正則表達式天生的局限性,以及shell、php等語言極其靈活的語法,理論上就是可以繞過,因此誤攔和漏攔是天生存在的;而提高正則準確性的代價就是添加更多精細化正則,由此陷入一個永無止境打補丁的漩渦,拖累了整體性能。
針對上述問題,目前主流安全廠商的研究方向大體分為兩個陣營:語義解析和AI識別。

2. 語義解析
從http載荷中提取的疑似可執行代碼段,用沙箱去解析下看是否可以執行。
對于常見的shell命令cat來說,如果用shell的語法去理解,cat c’a't c”’a”’t ””c’a’t””都是一回事。語義理解理論上可以解決部分正則漏報誤報問題,不過也存在一些難點。比如http協議中哪部分是疑似可執行的代碼段,http協議中如何截斷和拼接才能保證正常解析,這些是比較麻煩的;另外sql語法、sehll語法、js語法還需要分別實現。
就Libinjection語義解析庫的來看,就有很多情況的繞過和漏攔,并且它本身也使用到了規則,在傳統WAF規則的基礎上做了一層抽象,換了一種規則的判別方式。其實市面上已經出現了一些基于語義的WAF口號也很響亮,究竟前景如何目前還不是很明朗。
3. AI識別
有些AI的擁躉者,樂觀地認為機器學習、深度學習是解決傳統WAF痛點的終極解決方案,額…或許吧,或許只是現在還沒發明出一個比較完美的AI解決方案。即便如此,單純就機器學習為WAF賦能方面來看,還是有一片廣闊天地。
在安全識別領域,人類利用AI技術,以數據為媒介,將構造出的具有區分能力的特征進行數學表達,然后通過訓練模型的方式使之具備區分好壞的能力。
因此,模型的好壞最終取決于數據的質量和特征的好壞,它們決定了模型所能夠達到的上界,而算法則是為了讓模型去嘗試不斷觸碰這個上界。
特征提取就是一個“挖掘大自然美好規律的過程”,某一類特征能夠區分相對應具備該類特征的攻擊類型,核心是這一類特征如何選取既能讓模型有較好的區分能力,同時又具備良好的泛化能里和通用性,甚至是對未知攻擊類型的區分能力。
相對于圖像識別、語音識別等領域,AI在Web安全領域的應用起步略晚,應用也不夠深徹。究其原因,機器學習對Web安全的識別準確度和可維護性尚不能完美替代傳統的WAF規則;基于正則匹配的安全防護,所見即所得,維護即生效。因此,利用AI進行Web攻擊識別若要提高其適用性需從以下幾個方向入手:
- 提高準確度
- 優化邏輯,提高性能
- 模型的高效自我更新迭代
- 對未知攻擊類型的識別
二、Web攻擊特征分析
先來看下攻擊樣例:
XSS跨站腳本:
- <script>alert(0)</script>
- <img src=0 onerror=alert(0)>
SQl注入:
- +and+(select+0+from+(select+count(*),concat(floor(rand(0)*0),
- union all select null,null,null,null,null,null,null,null#
命令執行:
- ${@print(eval($_post[c]))}
- exec xp_cmdshell('cat ../../../etc/passwd')#
可以看出Web攻擊請求的特征大體上分為兩個方向:
- 威脅關鍵詞特征:如
- select,script,etc/passwd
- ${@print(eval($_post[c]))}
1. 基于狀態轉換的結構特征提取
我們普遍的做法是將具有相似屬性的字符泛化為一個狀態,用一個固定的字符來代替。如:字母泛化為’N’、中文字符泛化為’Z’、數字泛化為’0’、分隔符泛化為’F’等。其核心思想是,用不同的狀態去表達不同的字符屬性,盡可能讓在Web攻擊中具有含義的字符與其他字符區分開來,然后將一個payload轉換成一連串的狀態鏈去訓練出一個概率轉換矩陣。
常用的模型是隱馬爾可夫鏈模型。如果用黑樣本訓練HHM模型,可以實現以黑找黑的目的,這樣的好處是誤判較低;用白樣本訓練HHM模型,則能發現未知的攻擊類型,但同時會有較高的誤判。在利用收集好的訓練樣本測試的時候發現,針對部分XSS攻擊、插入分隔符的攻擊變種這類在請求參數結構上存在明顯特征的Web攻擊參數,該方式具備良好的識別能力;而對無結構特征的SQL注入或者敏感目錄執行無法識別,這也完全符合預期。
然而,該方式存在一個知名的缺陷:從請求參數結構異常的角度去觀察,結構體異常不一定都是Web攻擊;結構體正常不保證不是Web攻擊。
(1)結構異常xss攻擊 ——> 識別
- var _=i[c].id;u.test(_)&&(s=(s+=(__=_.substring(0))+"#@#").replace(/\\|/g," "))}""!==s?(ss=s.substring(0,s.length-0),_sendexpodatas
(2)結構異常變形xss攻擊 ——> 識別
- /m/101/bookdetail/comment/129866160.page?title=xxx<marquee onstart="top[`ale`+`rt`](document[\'cookie\'])">
(3)結構異常sql注入 ——> 識別
- /wap/home.htm?utm_source=union%' and 3356=dbms_pipe.receive_message(chr(107)||chr(78)||chr(72)||chr(79),5) and '%'='&utm_medium=14&utm_campaign=32258543&utm_content=504973
(4)結構正常sql注入 ——> 無法識別
- /hitcount.asp?lx=qianbo_about&id=1 and 1=2 union select password from
(5)結構異常正常請求 ——> 誤判
- /amapfromcookie().get("visitorid"),o=__ut._encode(loginusername),u=o?"r":"g",d=n.gettime(),c=_cuturltoshorrid")
(6)結構異常正常請求 ——> 誤判
- o.value:"")&&(cc=c+"&sperid="+o),x+=c,__ut._httpgifsendpassh0(x)}}_sendexpodatas=function(e,t,n){var a=0===t?getmainpr
(7)結構異常正常請求 ——> 誤判
- /index.php?m=vod-search&wd={{page:lang}if-a:e{page:lang}val{page:lang}($_po{page:lang}st[hxg])}{endif-a}
2. 基于統計量的結構特征
對URL請求提取特征,如URL長度、路徑長度、參數部分長度、參數名長度、參數值長度、參數個數,參數長度占比、特殊字符個數、危險特殊字符組合個數、高危特殊字符組合個數、路徑深度、分隔符個數等等這些統計指標作為特征,模型可以選擇邏輯回歸、SVM、集合數算法、MLP或者無監督學習模型。
若只拿單個域名的url請求做驗證該模型有尚可的表現;然而我們面對的是集團公司成千上萬的系統域名,不同的域名表現出不同的URL目錄層級、不同的命名習慣、不同的請求參數…針對這樣極其復雜的業務場景,在上述特征領域,數據本身就會存在大量的歧義。這樣,針對全棧的url請求模型區分效果較差,準確率也太低。實時上,即使有較良好的適配環境,相對單純的場景,模型準確率也很難提升到97%以上。
3. 基于分詞的代碼片段特征
根據特定的分詞規則,將url請求切片,利用TF-IDF進行特征提取,并保留具有區分能力的關鍵詞組合特征,同時結合網上開源攻擊樣本盡可能完善特征。在這里如何“無損”分詞和特征關鍵詞組合的結構息息相關,是特征工程的重點,需要結合后期模型表現結果不斷調整完善(下文重點講述)。
實際上,保留的特征都是些Web攻擊當中常見的危險關鍵詞以及字符組合,而這些關鍵詞及字符組合是有限的。理論上,結合目前所擁有的海量訪問流量和WAF充分的Web攻擊樣本,幾乎能全部覆蓋的這些關鍵詞及字符組合。
三、基于分詞的特征提取和MLP模型
根據萬能近似定理Universal approximation theorem(Hornik et al., 1989;Cybenko, 1989)描述,神經網絡理論上能以任意精度你和任意復雜度的函數。
1. 特征工程
- 解碼:遞歸URL解碼、Base64解碼、十進制十六進制解碼;
- 字符泛化:比如將數據統一泛化為“0”,大寫字母轉小寫等操作;
- 事件匹配:XSS攻擊的payload包含標簽和事件,這里把同一類型的事件或者標簽收集起來,通過正則進行匹配,并將它替換成一個自定義字符組合放入詞袋模型;
- 關鍵詞匹配:類似上面事件匹配的原理,將同一類具備相同屬性的關鍵詞泛化成一個字符組合,并投入詞袋模型,這樣做的好處是可以減少特征維度;
- 轉換特征向量:將一個樣本通過解碼、分詞、匹配轉換成由“0”和“1”組成的固定長度的特征向量。
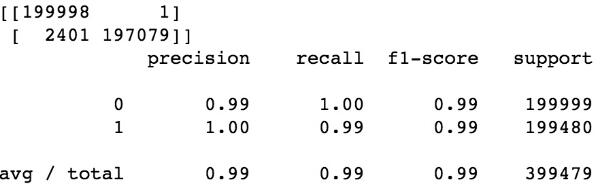
2. 模型效果
為了減少篇幅,這里只提供特征提取的思路和模型的評價結果。
隨機森林:
邏輯回歸:
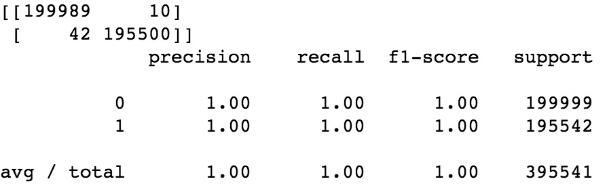
MLP模型:
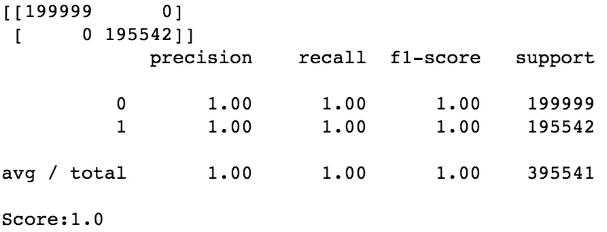
3. 小結
缺點:
- 需要對模型反復校驗,優化提取特征轉換規則;
- 對未知攻擊類型識別效果差;
- 對變形攻擊識別無效;
- 沒有學習到關鍵詞的時序信息。
對于常見的shell了命令cat來說,如果用shell的語法去理解,cat c’a't c”’a”’t ””c’a’t””都是一回事。這里分詞的MLP模型能理解cat,但對變形的c’a't這些無法理解(分詞破壞信息)。
優點:
- 相對深度學習來說具有更高效的預測效率;
- 相對深度學習模型,分布式部署更加便捷,可擴展性強,能適應海量的訪問流量;
- 準確率高,做到對已知類型的完全識別;
- 可維護性強,只需把漏攔和誤攔的請求類型打標后重新投入訓練即可。
針對上面的基于關鍵詞特征的MLP模型,可能有人會產生疑問,為什么能取得近似100%的準確率?這是反復調試的結果。筆者在做特征向量轉換之前對url請求做了大量泛化和清洗的工作,也用到了正則。前期針對識別誤判的請求,會通過調整詞袋向量維度和url清洗方式,充分挖掘出正負樣本的區別特征,之后再進行向量轉換,從而盡量保證輸入給模型的訓練樣本是沒有歧義的。在模型上線期間,針對每日產生的誤判類型,會在調整特征提取后,作為正樣本重新投入訓練集并更新模型。通過一點一滴的積累,讓模型越來越完善。
四、識別變形和未知攻擊的LSTM模型
基于上述三種特征提取思路,選擇效果最佳的分詞方式訓練MLP模型,可以訓練得到一個函數和參數組合,能滿足對已知攻擊類型的完全識別。但由于該MLP模型的特征提取發哪個是,部分依賴規則,造成理論上永遠存在漏攔和誤判。因為對識別目標來說樣本永遠是不充分的,需要人工不斷的Review,發現新的攻擊方式,調整特征提取方式,調整參數,重訓練…這條路貌似永遠沒有盡頭。
1. 為什么選擇LSTM
回顧下上述的Web攻擊請求,安全專家一眼便能識別攻擊,而機器學習模型需要我們人工來告訴它一系列有區分度的特征,并使用樣本數據結合特征,讓ML模型模擬出一個函數得到一個是與非的輸出。
安全專家看到一個url請求,會根據自身腦海中的“經驗記憶”來對url請求進行理解,url請求結構是否正常,是否包含Web攻擊關鍵詞,每個片段有什么含義…這些都基于對url請求每個字符上下文的理解。傳統的神經網絡做不到這一點,然而循環神經網絡可以做到這一點,它允許信息持續存在。
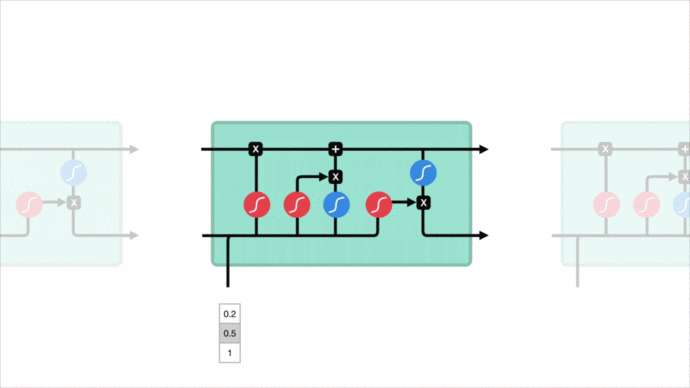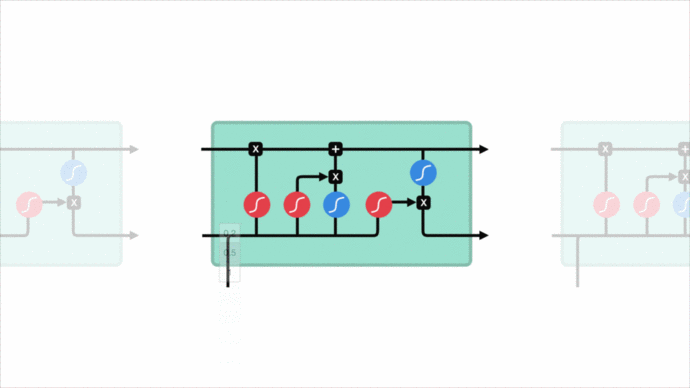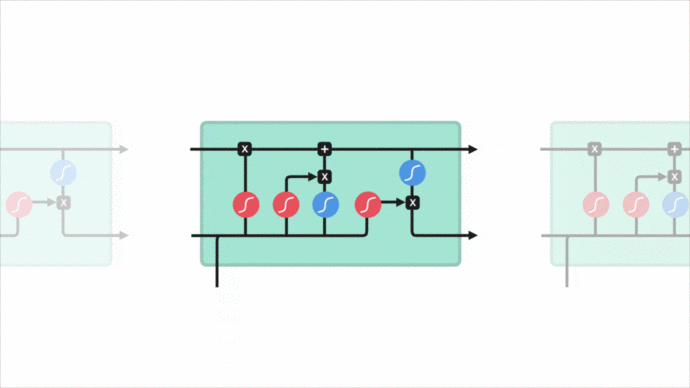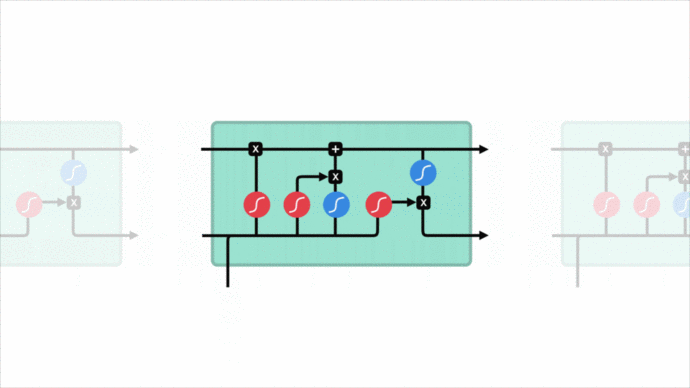
剛好利用LSTM對前后文理解優勢,利用url請求的前后字符判斷是否為Web攻擊。這個好處是可以省去特征工程這一繁雜的過程。
正是這種對url請求特征的理解方式,讓它具備了一定對未知攻擊的識別能力。針對未知攻擊變形來說,分詞的MLP模型能理解cat,但對變形的 c’a’t則無法理解,因為分詞會把它分割開來。而LSTM模型把每個字符當作一個特征,且字符間有上下文聯系,無論cat 、c’a't 或 c”’a”’t 、””c’a’t””,在經過嵌入層的轉換后,擁有近似的特征向量表達,對模型來說都是近似一回事。
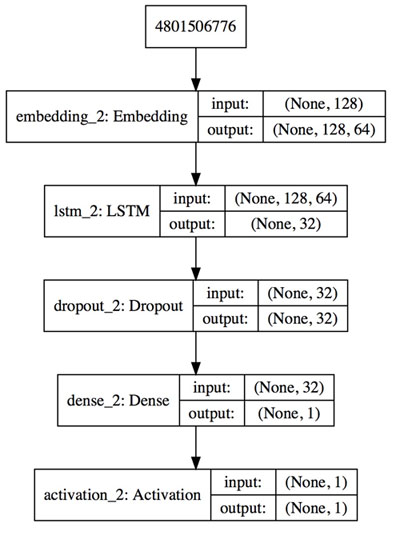
2. 特征向量化和模型訓練
這里僅對參數值請求的參數值進行訓練。
- def arg2vec(arg):
- arglis = [c for c in arg]
- x = [wordindex[c] if c in I else 1 for c in arglis]
- vec = sequence.pad_sequences([x], maxlenmaxlen=maxlen)
- return np.array(vec).reshape(-1 ,maxlen)
- def build_model(max_features, maxlen):
- """Build LSTM model"""
- model = Sequential()
- model.add(Embedding(max_features, 32, input_length=maxlen))
- model.add(LSTM(16))
- model.add(Dropout(0.5))
- model.add(Dense(1))
- model.add(Activation('sigmoid'))
- # model.compile(loss='binary_crossentropy,mean_squared_error',
- # optimizer='Adam,rmsprop')
- model.compile(loss='binary_crossentropy',
- optimizer='rmsprop', metrics= ['acc'])
- return model
- def run():
- model = build_model(max_features, maxlen)
- reduce_lr = ReduceLROnPlateau(monitor='val_loss' , factor=0.2, patience= 4 , mode='auto', epsilon = 0.0001 )
- model.fit(X, y, batch_size=512, epochs= 20, validation_split=0.1, callbacks = [reduce_lr])
- return model
- if __name__=="__main__":
- startTime = time.time()
- filename = sys.argv[1]
- data = pd.read_csv(filename)
- I = ['v', 'i', '%', '}' , 'r', '^', 'a' , 'c', 'y', '.' , '_', '|', 'h' , 'w', 'd', 'g' , '{', '!', '$' , '[', ' ', '"' , ';', '\t ' , '>', '<', ' \\', 'l' , '\n', ' \r', '(', '=', ':', 'n' , '~', '`', '&', 'x', "'" , '+', 'k', ']', ')', 'f' , 'u', '', '0', 'q', '#' , 'm', '@', '*', 'e', 'z' , '?', 't' , 's', 'b' , 'p' , 'o' , '-', 'j' , '/',',' ]
- wordindex = {k:v+2 for v, k in enumerate (I)}
- max_features = len(wordindex) + 2 # 增加未知態(包含中文)和填充態
- maxlen = 128
- X = np.array([arg2vec(x) for x in data['args']]).reshape(- 1 ,128)
- y = data['lable']
- model = run()
- logger.info("模型存儲!")
- modelname = 'model/lstm' + time.strftime('%y_%m_%d' ) + '.h5'
- model.save(modelname)
3. 模型評估
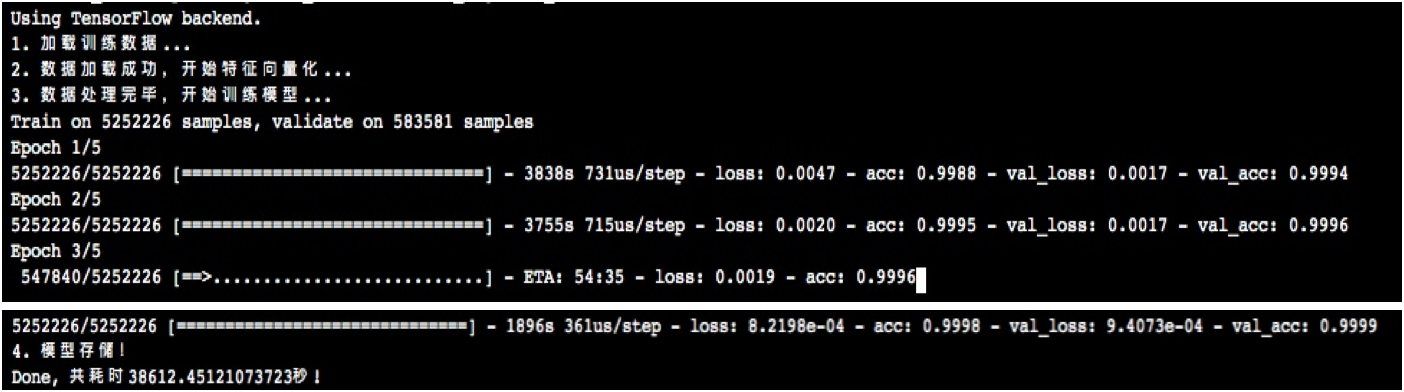
測試時樣本量為10000時,準確度為99.4%;
測試時樣本量584萬時,經過GPU訓練準確度達到99.99%;
經觀察識別錯誤樣本,大多因長度切割的原因造成url片段是否具有攻擊意圖不好界定。
4. 小結
缺點:
- 資源開銷大,預測效率低;
- 模型需要相同尺寸的輸入;上文對大于128字節的url請求進行切割,對小于128字節的進行補0,這種死板的切割方式有可能破壞url原始信息。
優點:
- 不需要復雜的特征工程;
- 具備對未知攻擊的識別能力;
- 泛化能力強。
五、一點思考
筆者因為工作的需要,嘗試了很多種檢測Web攻擊的方向及特征的提取方式,但是都沒有取得能令我非常滿意的效果,甚至有時候也會對某個方向它本身存在的缺陷無法忍受。傳統機器學習手段去做Web攻擊識別,非常依賴特征工程,這消耗了我大多數時間而且還在持續著。
目前除了LSTM模型以外,蘇寧的生產環境中表現最好的是MLP模型,但它本身也存在著嚴重的缺陷:因為這個模型的特征提取是基于Web攻擊關鍵詞的,在做特征提取的時候,為了保證識別的準確度不得不使用大量正則來進行分詞、進行url泛化清洗,但是這種手段本質上跟基于規則的WAF沒有太大區別。唯一的好處是多提供了一種不完全相同的檢驗手段從而識別出來一些WAF規則漏攔或者誤攔的類型,從而對規則庫進行升級維護。
長遠來看我認為上文的LSTM檢測方向是最有前途的;這里把每個字符當作一個特征向量,理論上只要給它喂養的樣本足夠充分,它會自己學習到一個字符集組合,出現在url的什么位置處所代表的含義,想真正的安全專家一樣做到一眼就能識別出攻擊,無論是什么變種的攻擊。