Redis專題(2):Redis數據結構底層探秘
前言
上篇文章Redis閑談(1):構建知識圖譜介紹了Redis的基本概念、優缺點以及它的內存淘汰機制,相信大家對Redis有了初步的認識。互聯網的很多應用場景都有著Redis的身影,它能做的事情遠遠超出了我們的想像。Redis的底層數據結構到底是什么樣的呢,為什么它能做這么多的事情?本文將探秘Redis的底層數據結構以及常用的命令。
本文知識腦圖如下:
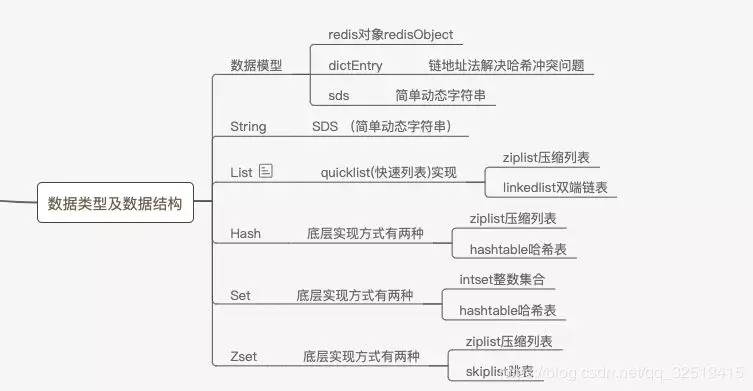
一、Redis的數據模型
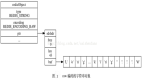
用 鍵值對 name:"小明"來展示Redis的數據模型如下:

- dictEntry:在一些編程語言中,鍵值對的數據結構被稱為字典,而在Redis中,會給每一個key-value鍵值對分配一個字典實體,就是“dicEntry”。dicEntry包含三部分: key的指針、val的指針、next指針,next指針指向下一個dicteEntry形成鏈表,這個next指針可以將多個哈希值相同的鍵值對鏈接在一起,通過鏈地址法來解決哈希沖突的問題
- sds :Simple Dynamic String,簡單動態字符串,存儲字符串數據。
- redisObject:Redis的5種常用類型都是以RedisObject來存儲的,redisObject中的type字段指明了值的數據類型(也就是5種基本類型)。ptr字段指向對象所在的地址。
RedisObject對象很重要,Redis對象的類型、內部編碼、內存回收、共享對象等功能,都是基于RedisObject對象來實現的。
這樣設計的好處是:可以針對不同的使用場景,對5種常用類型設置多種不同的數據結構實現,從而優化對象在不同場景下的使用效率。
Redis將jemalloc作為默認內存分配器,減小內存碎片。jemalloc在64位系統中,將內存空間劃分為小、大、巨大三個范圍;每個范圍內又劃分了許多小的內存塊單位;當Redis存儲數據時,會選擇大小最合適的內存塊進行存儲。
二、Redis支持的數據結構
Redis支持的數據結構有哪些?
如果回答是String、List、Hash、Set、Zset就不對了,這5種是Redis的常用基本數據類型,每一種數據類型內部還包含著多種數據結構。
用encoding指令來看一個值的數據結構。比如:
- 127.0.0.1:6379> set name tom
- OK
- 127.0.0.1:6379> object encoding name
- "embstr
此處設置了name值是tom,它的數據結構是embstr,下文介紹字符串時會詳解說明。
- 127.0.0.1:6379> set age 18
- OK
- 127.0.0.1:6379> object encoding age
- "int"
如下表格總結Redis中所有的數據結構類型:
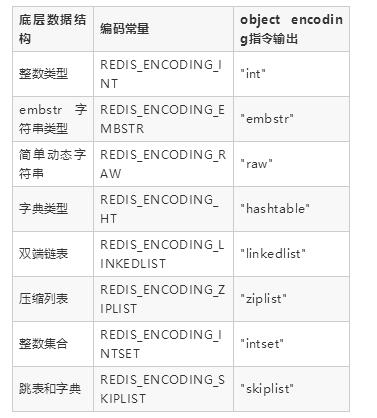
補充說明:
| 假如面試官問:Redis的數據類型有哪些?
回答:String、list、hash、set、zet |
一般情況下這樣回答是正確的,前文也提到Redis的數據類型確實是包含這5種,但細心的同學肯定發現了之前說的是“常用”的5種數據類型。其實,隨著Redis的不斷更新和完善,Redis的數據類型早已不止5種了。
登錄Redis的官方網站打開官方的數據類型介紹(https://redis.io/topics/data-types-intro):

發現Redis支持的數據結構不止5種,而是8種,后三種類型分別是:
- 位數組(或簡稱位圖):使用特殊命令可以處理字符串值,如位數組:您可以設置和清除各個位,將所有位設置為1,查找第一個位或未設置位,等等。
- HyperLogLogs:這是一個概率數據結構,用于估計集合的基數。不要害怕,它比看起來更簡單。
- Streams:僅附加的類似于地圖的條目集合,提供抽象日志數據類型。
本文主要介紹5種常用的數據類型,上述三種以后再共同探索。
1. string字符串
字符串類型是Redis最常用的數據類型,在Redis中,字符串是可以修改的,在底層它是以字節數組的形式存在的。
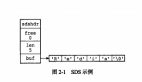
Redis中的字符串被稱為簡單動態字符串「SDS」,這種結構很像Java中的ArrayList,其長度是動態可變的。
- struct SDS<T> {
- T capacity; // 數組容量
- T len; // 數組長度
- byte[] content; // 數組內容
- }
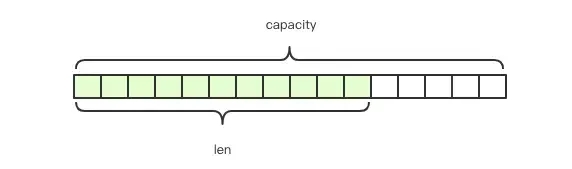
content[] 存儲的是字符串的內容,capacity表示數組分配的長度,len表示字符串的實際長度。
字符串的編碼類型有int、embstr和raw三種,如上表所示,那么這三種編碼類型有什么不同呢?
- int 編碼:保存的是可以用 long 類型表示的整數值。
- raw 編碼:保存長度大于44字節的字符串(redis3.2版本之前是39字節,之后是44字節)。
- embstr 編碼:保存長度小于44字節的字符串(redis3.2版本之前是39字節,之后是44字節)。
設置一個值測試一下:
- 127.0.0.1:6379> set num 300
- 127.0.0.1:6379> object encoding num
- "int"
- 127.0.0.1:6379> set key1 wealwaysbyhappyhahaha
- OK
- 127.0.0.1:6379> object encoding key1
- "embstr"
- 127.0.0.1:6379> set key2 hahahahahahahaahahahahahahahahahahahaha
- OK
- 127.0.0.1:6379> strlen key2
- (integer) 39
- 127.0.0.1:6379> object encoding key2
- "embstr"
- 127.0.0.1:6379> set key2 hahahahahahahaahahahahahahahahahahahahahahaha
- OK
- 127.0.0.1:6379> object encoding key2
- "raw"
- 127.0.0.1:6379> strlen key2
- (integer) 45
aw類型和embstr類型對比:
embstr編碼的結構:

raw編碼的結構:
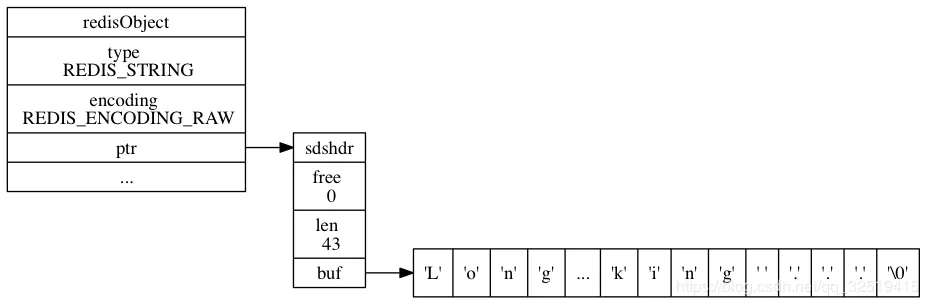
- embstr和raw都是由redisObject和sds組成的。不同的是:embstr的redisObject和sds是連續的,只需要使用malloc分配一次內存;而raw需要為redisObject和sds分別分配內存,即需要分配兩次內存。
- 所有相比較而言,embstr少分配一次內存,更方便。但embstr也有明顯的缺點:如要增加長度,redisObject和sds都需要重新分配內存。
上文介紹了embstr和raw結構上的不同。重點來了~ 為什么會選擇44作為兩種編碼的分界點?在3.2版本之前為什么是39?這兩個值是怎么得出來的呢?
(1) 計算RedisObject占用的字節大小
- struct RedisObject {
- int4 type; // 4bits
- int4 encoding; // 4bits
- int24 lru; // 24bits
- int32 refcount; // 4bytes = 32bits
- void *ptr; // 8bytes,64-bit system
- }
- type:不同的redis對象會有不同的數據類型(string、list、hash等),type記錄類型,會用到4bits。
- encoding:存儲編碼形式,用4bits。
- lru:用24bits記錄對象的LRU信息。
- refcount:引用計數器,用到32bits。
- *ptr:指針指向對象的具體內容,需要64bits。
計算: 4 + 4 + 24 + 32 + 64 = 128bits = 16bytes
第一步就完成了,RedisObject對象頭信息會占用16字節的大小,這個大小通常是固定不變的.
(2) sds占用字節大小計算
舊版本:
- struct SDS {
- unsigned int capacity; // 4byte
- unsigned int len; // 4byte
- byte[] content; // 內聯數組,長度為 capacity
- }
這里的unsigned int 一個4字節,加起來是8字節.
內存分配器jemalloc分配的內存如果超出了64個字節就認為是一個大字符串,就會用到embstr編碼。
前面提到 SDS 結構體中的 content 的字符串是以字節\0結尾的字符串,之所以多出這樣一個字節,是為了便于直接使用 glibc 的字符串處理函數,以及為了便于字符串的調試打印輸出。所以我們還要減去1字節 64byte - 16byte - 8byte - 1byte = 39byte
新版本:
- struct SDS {
- int8 capacity; // 1byte
- int8 len; // 1byte
- int8 flags; // 1byte
- byte[] content; // 內聯數組,長度為 capacity
- }
這里unsigned int 變成了uint8_t、uint16_t.的形式,還加了一個char flags標識,總共只用了3個字節的大小。相當于優化了sds的內存使用,相應的用于存儲字符串的內存就會變大。
然后進行計算:

64byte - 16byte -3byte -1byte = 44byte。
總結:所以,Redis 3.2版本之后embstr最大能容納的字符串長度是44,之前是39。長度變化的原因是SDS中內存的優化。
2. List
Redis中List對象的底層是由quicklist(快速列表)實現的,快速列表支持從鏈表頭和尾添加元素,并且可以獲取指定位置的元素內容。
那么,快速列表的底層是如何實現的呢?為什么能夠達到如此快的性能?
羅馬不是一日建成的,quicklist也不是一日實現的,起初redis的list的底層是ziplist(壓縮列表)或者是 linkedlist(雙端列表)。先分別介紹這兩種數據結構。
(1) ziplist 壓縮列表
當一個列表中只包含少量列表項,且是小整數值或長度比較短的字符串時,redis就使用ziplist(壓縮列表)來做列表鍵的底層實現。
測試:
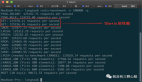
- 127.0.0.1:6379> rpush dotahero sf qop doom
- (integer) 3
- 127.0.0.1:6379> object encoding dotahero
- "ziplist"
此處使用老版本Redis進行測試,向dota英雄列表中加入了qop痛苦女王、sf影魔、doom末日使者三個英雄,數據結構編碼使用的是ziplist。
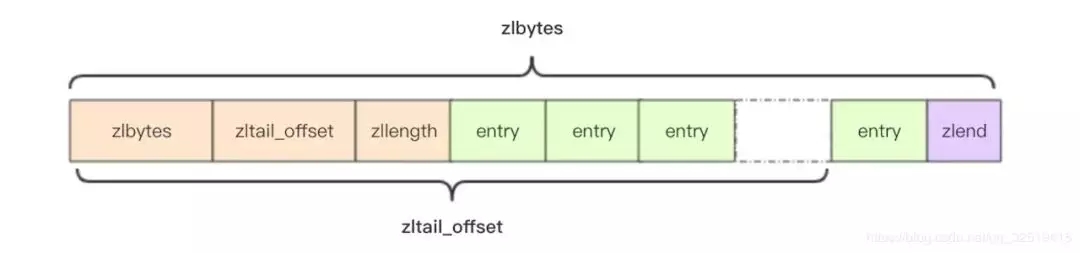
壓縮列表顧名思義是進行了壓縮,每一個節點之間沒有指針的指向,而是多個元素相鄰,沒有縫隙。所以 ziplist是Redis為了節約內存而開發的,是由一系列特殊編碼的連續內存塊組成的順序型數據結構。具體結構相對比較復雜,大家有興趣地話可以深入了解。
- struct ziplist<T> {
- int32 zlbytes; // 整個壓縮列表占用字節數
- int32 zltail_offset; // 最后一個元素距離壓縮列表起始位置的偏移量,用于快速定位到最后一個節點
- int16 zllength; // 元素個數
- T[] entries; // 元素內容列表,挨個挨個緊湊存儲
- int8 zlend; // 標志壓縮列表的結束,值恒為 0xFF
- }
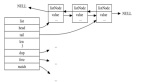
(2) 雙端列表(linkedlist)
雙端列表大家都很熟悉,這里的雙端列表和java中的linkedlist很類似。
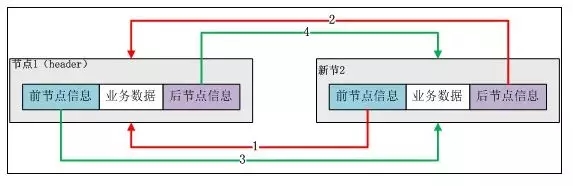
從圖中可以看出Redis的linkedlist雙端鏈表有以下特性:節點帶有prev、next指針、head指針和tail指針,獲取前置節點、后置節點、表頭節點和表尾節點、獲取長度的復雜度都是O(1)。
壓縮列表占用內存少,但是是順序型的數據結構,插入刪除元素的操作比較復雜,所以壓縮列表適合數據比較小的情況,當數據比較多的時候,雙端列表的高效插入刪除還是更好的選擇
在Redis開發者的眼中,數據結構的選擇,時間上、空間上都要達到極致,所以,他們將壓縮列表和雙端列表合二為一,創建了快速列表(quicklist)。和java中的hashmap一樣,結合了數組和鏈表的優點。
(3) 快速列表(quicklist)
- rpush: listAddNodeHead ---O(1)
- lpush: listAddNodeTail ---O(1)
- push:listInsertNode ---O(1)
- index : listIndex ---O(N)
- pop:ListFirst/listLast ---O(1)
- llen:listLength ---O(N)
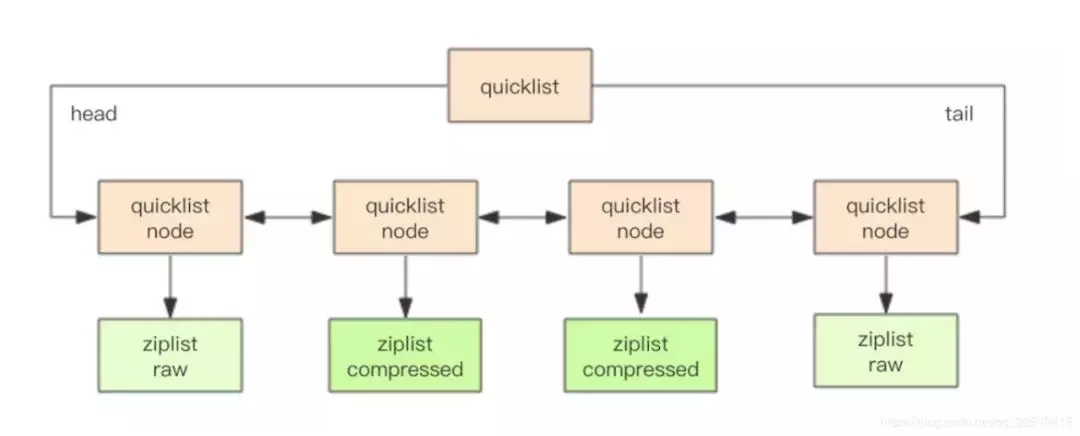
- struct ziplist {
- ...
- }
- struct ziplist_compressed {
- int32 size;
- byte[] compressed_data;
- }
- struct quicklistNode {
- quicklistNode* prev;
- quicklistNode* next;
- ziplist* zl; // 指向壓縮列表
- int32 size; // ziplist 的字節總數
- int16 count; // ziplist 中的元素數量
- int2 encoding; // 存儲形式 2bit,原生字節數組還是 LZF 壓縮存儲
- ...
- }
- struct quicklist {
- quicklistNode* head;
- quicklistNode* tail;
- long count; // 元素總數
- int nodes; // ziplist 節點的個數
- int compressDepth; // LZF 算法壓縮深度
- ...
- }
quicklist 默認的壓縮深度是 0,也就是不壓縮。壓縮的實際深度由配置參數list-compress-depth決定。為了支持快速的 push/pop 操作,quicklist 的首尾兩個 ziplist 不壓縮,此時深度就是 1。如果深度為 2,表示 quicklist 的首尾第一個 ziplist 以及首尾第二個 ziplist 都不壓縮。
3. Hash
Hash數據類型的底層實現是ziplist(壓縮列表)或字典(也稱為hashtable或散列表)。這里壓縮列表或者字典的選擇,也是根據元素的數量大小決定的。

如圖hset了三個鍵值對,每個值的字節數不超過64的時候,默認使用的數據結構是ziplist。

當我們加入了字節數超過64的值的數據時,默認的數據結構已經成為了hashtable。
Hash對象只有同時滿足下面兩個條件時,才會使用ziplist(壓縮列表):
- 哈希中元素數量小于512個;
- 哈希中所有鍵值對的鍵和值字符串長度都小于64字節。
壓縮列表剛才已經了解了,hashtables類似于jdk1.7以前的hashmap。hashmap采用了鏈地址法的方法解決了哈希沖突的問題。想要深入了解的話可以參考之前寫的一篇博客: hashmap你真的了解嗎?
(https://blog.csdn.net/qq_32519415/article/details/87006982)
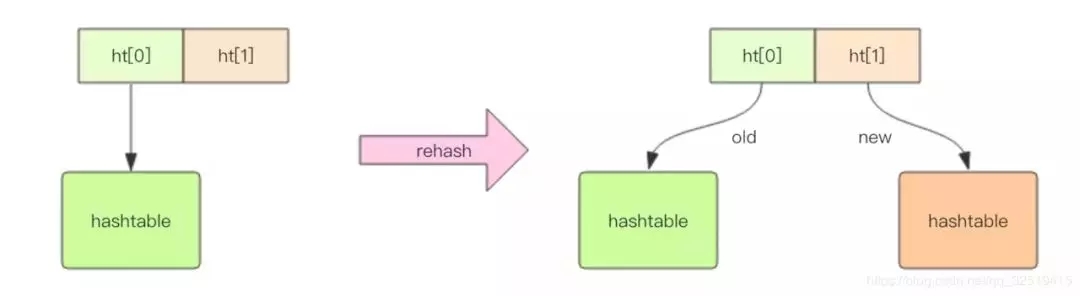
Redis中的字典:
Redis中的dict 結構內部包含兩個 hashtable,通常情況下只有一個 hashtable 是有值的。但是在 dict 擴容縮容時,需要分配新的 hashtable,然后進行漸進式搬遷,這時兩個 hashtable 存儲的分別是舊的 hashtable 和新的 hashtable。待搬遷結束后,舊的 hashtable 被刪除,新的 hashtable 取而代之。
4. Set
Set數據類型的底層可以是intset(整數集)或者是hashtable(散列表也叫哈希表)。
當數據都是整數并且數量不多時,使用intset作為底層數據結構;當有除整數以外的數據或者數據量增多時,使用hashtable作為底層數據結構。
- 127.0.0.1:6379> sadd myset 111 222 333
- (integer) 3
- 127.0.0.1:6379> object encoding myset
- "intset"
- 127.0.0.1:6379> sadd myset hahaha
- (integer) 1
- 127.0.0.1:6379> object encoding myset
- "hashtable"
inset的數據結構為:
- typedef struct intset {
- // 編碼方式
- uint32_t encoding;
- // 集合包含的元素數量
- uint32_t length;
- // 保存元素的數組
- int8_t contents[];
- } intset;
intset底層實現為有序、無重復數的數組。 intset的整數類型可以是16位的、32位的、64位的。如果數組里所有的整數都是16位長度的,新加入一個32位的整數,那么整個16的數組將升級成一個32位的數組。升級可以提升intset的靈活性,又可以節約內存,但不可逆。
5. Zset
Redis中的Zset,也叫做有序集合。它的底層是ziplist(壓縮列表)或 skiplist(跳躍表)。
壓縮列表前文已經介紹過了,同理是在元素數量比較少的時候使用。此處主要介紹跳躍列表。
跳表:
跳躍列表,顧名思義是可以跳的,跳著查詢自己想要查到的元素。大家可能對這種數據結構比較陌生,雖然平時接觸的少,但它確實是一個各方面性能都很好的數據結構,可以支持快速的查詢、插入、刪除操作,開發難度也比紅黑樹要容易的多。
為什么跳表有如此高的性能呢?它究竟是如何“跳”的呢?跳表利用了二分的思想,在數組中可以用二分法來快速進行查找,在鏈表中也是可以的。
舉個例子,鏈表如下:

假設要找到10這個節點,需要一個一個去遍歷,判斷是不是要找的節點。那如何提高效率呢?mysql索引相信大家都很熟悉,可以提高效率,這里也可以使用索引。抽出一個索引層來:
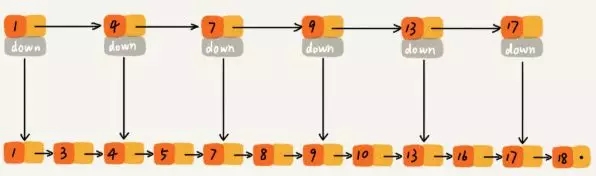
這樣只需要找到9然后再找10就可以了,大大節省了查找的時間。
還可以再抽出來一層索引,可以更好地節約時間:
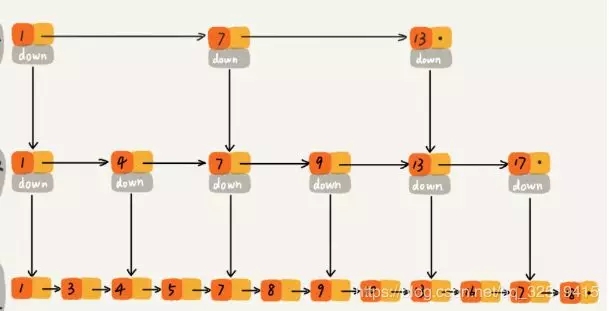
這樣基于鏈表的“二分查找”支持快速的插入、刪除,時間復雜度都是O(logn)。
由于跳表的快速查找效率,以及實現的簡單、易讀。所以Redis放棄了紅黑樹而選擇了更為簡單的跳表。
Redis中的跳躍表:
- typedef struct zskiplist {
- // 表頭節點和表尾節點
- struct zskiplistNode *header, *tail;
- // 表中節點的數量
- unsigned long length;
- // 表中層數最大的節點的層數
- int level;
- } zskiplist;
- typedef struct zskiplistNode {
- // 成員對象
- robj *obj;
- // 分值
- double score;
- // 后退指針
- struct zskiplistNode *backward;
- // 層
- struct zskiplistLevel {
- // 前進指針
- struct zskiplistNode *forward;
- // 跨度---前進指針所指向節點與當前節點的距離
- unsigned int span;
- } level[];
- } zskiplistNode;
- zadd---zslinsert---平均O(logN), 最壞O(N)
- zrem---zsldelete---平均O(logN), 最壞O(N)
- zrank--zslGetRank---平均O(logN), 最壞O(N)
總結
本文大概介紹了Redis的5種常用數據類型的底層實現,希望大家結合源碼和資料更深入地了解。
數據結構之美在Redis中體現得淋漓盡致,從String到壓縮列表、快速列表、散列表、跳表,這些數據結構都適用在了不同的地方,各司其職。
不僅如此,Redis將這些數據結構加以升級、結合,將內存存儲的效率性能達到了極致,正因為如此,Redis才能成為眾多互聯網公司不可缺少的高性能、秒級的key-value內存數據庫。
【本文是51CTO專欄機構宜信技術學院的原創文章,微信公眾號“宜信技術學院( id: CE_TECH)”】