K8S從懵圈到熟練:讀懂此文,集群節點不下線!
排查完全陌生的問題、不熟悉的系統組件,對許多工程師來說是***的工作樂趣,當然也是一大挑戰。今天,阿里巴巴售后技術專家聲東跟大家分享一例 Kubernetes 集群上的問題。這個問題影響范圍較廣,或許某天你也會遇到。更重要的是,作者在問題排查過程中的思路和方法,也會讓你有所啟發。
關于問題
I am Not Ready
阿里云有自己的 Kubernetes 容器集群產品。隨著 Kubernetes 集群出貨量劇增,線上用戶零星地發現,集群會非常低概率地出現節點 NotReady 情況。據我們觀察,這個問題差不多每個月,都會有一兩個用戶遇到。在節點 NotReady 之后,集群 Master 沒有辦法對這個節點做任何控制,比如下發新的 Pod,再比如抓取節點上正在運行 Pod 的實時信息。

需要知道的Kubernetes知識
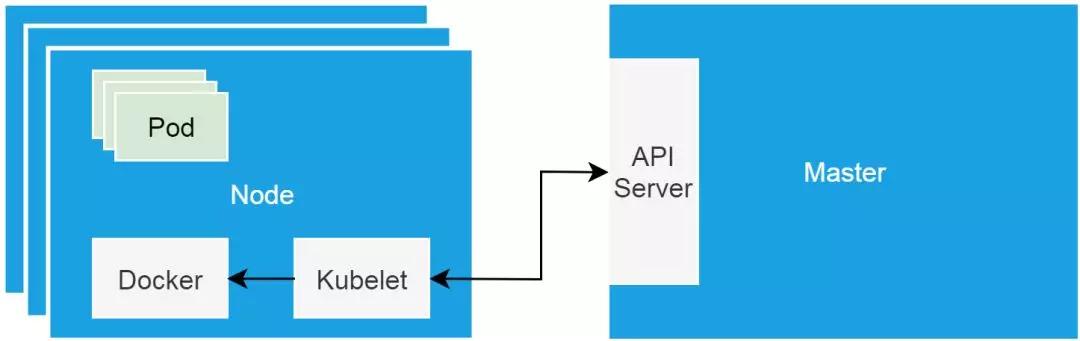
這里我稍微補充一點 Kubernetes 集群的基本知識。Kubernetes 集群的“硬件基礎”,是以單機形態存在的集群節點。這些節點可以是物理機,也可以是虛擬機。集群節點分為 Master 節點和 Worker 節點。Master 節點主要用來承載集群管控組件,比如調度器和控制器。而 Worker 節點主要用來跑業務。Kubelet 是跑在各個節點上的代理,它負責與管控組件溝通,并按照管控組件的指示,直接管理 Worker節點。
當集群節點進入 NotReady 狀態的時候,我們需要做的***件事情,是檢查運行在節點上的 kubelet 是否正常。在這個問題出現的時候,使用 systemctl 命令查看的kubelet 狀態(kubelet 是 systemd 管理的一個 daemon )發現它是正常運行的。當我們用 journalctl 查看 kubelet 日志的時候,發現以下錯誤。

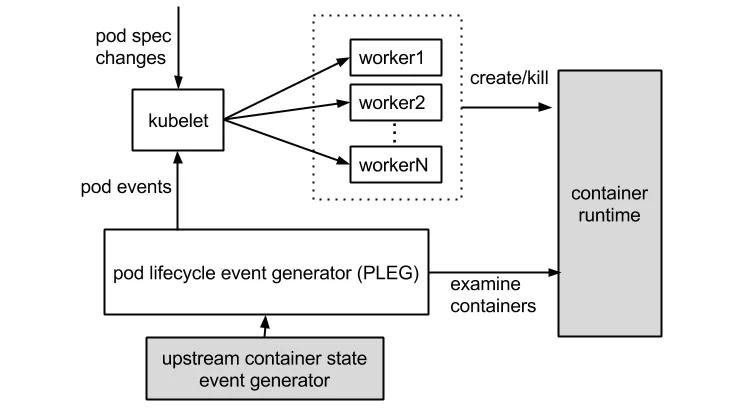
什么是PLEG?
這個報錯清楚地告訴我們,容器 runtime 是不工作的,且 PLEG 是不健康的。這里容器 runtime 指的就是 docker daemon 。Kubelet 通過操作 docker daemon 來控制容器的生命周期。而這里的 PLEG,指的是 pod lifecycle event generator。PLEG 是 kubelet 用來檢查 runtime 的健康檢查機制。這件事情本來可以由 kubelet 使用 polling 的方式來做。但是 polling 有其高成本的缺陷,所以 PLEG 應用而生。PLEG 嘗試以一種“中斷”的形式,來實現對容器 runtime 的健康檢查,雖然實際上,它同時用了 polling 和”中斷”這樣折中的方案。
基本上,根據上邊的報錯,我們可以確認容器 runtime 出了問題。在有問題的節點上,通過 docker 命令嘗試運行新的容器,命令會沒有響應,這說明上邊的報錯是準確的。
Docker Stack
Docker Daemon調用棧分析
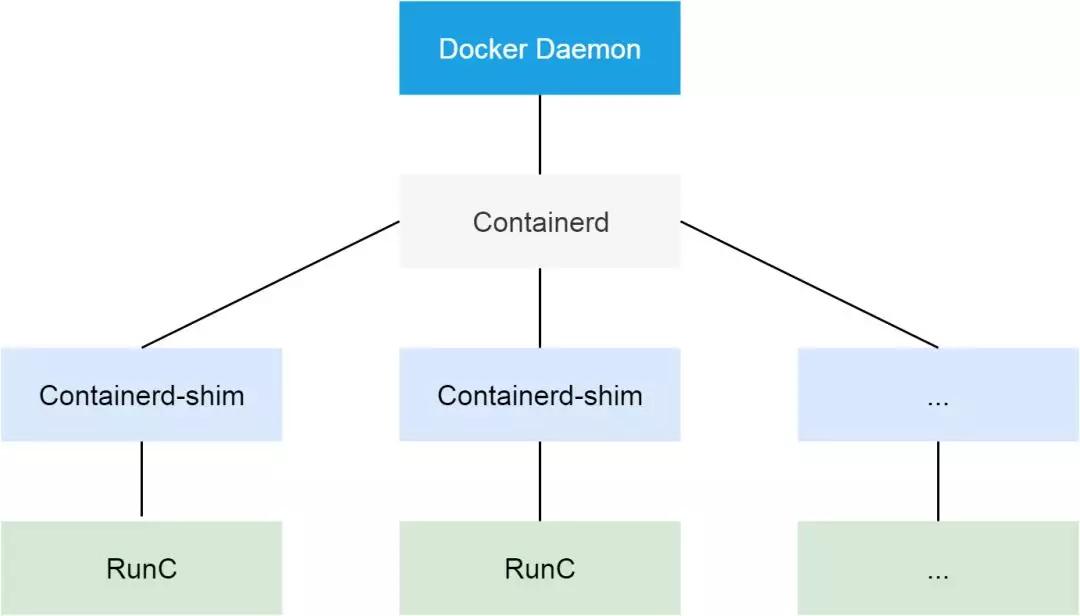
Docker 作為阿里云 Kubernetes 集群使用的容器 runtime ,在1.11之后,被拆分成了多個組件以適應 OCI 標準。拆分之后,其包括 docker daemon,containerd,containerd-shim 以及 runC。組件 containerd 負責集群節點上容器的生命周期管理,并向上為 docker daemon 提供 gRPC 接口。
在這個問題中,既然 PLEG 認為容器 runtime 出了問題,我們需要從 docker daemon 進程看起。我們可以使用 kill -USR1
Docker daemon 進程的調用棧是比較容易分析的。稍加留意,我們會發現大多數的調用棧都長成下圖中的樣子。通過觀察棧上每個函數的名字,以及函數所在的文件(模塊)名稱,我們可以了解到,這個調用棧的下半部分,是進程接到 http 請求,做請求路由的過程;而上半部分則是具體的處理函數。最終處理函數進入等待狀態,等待一個mutex實例。
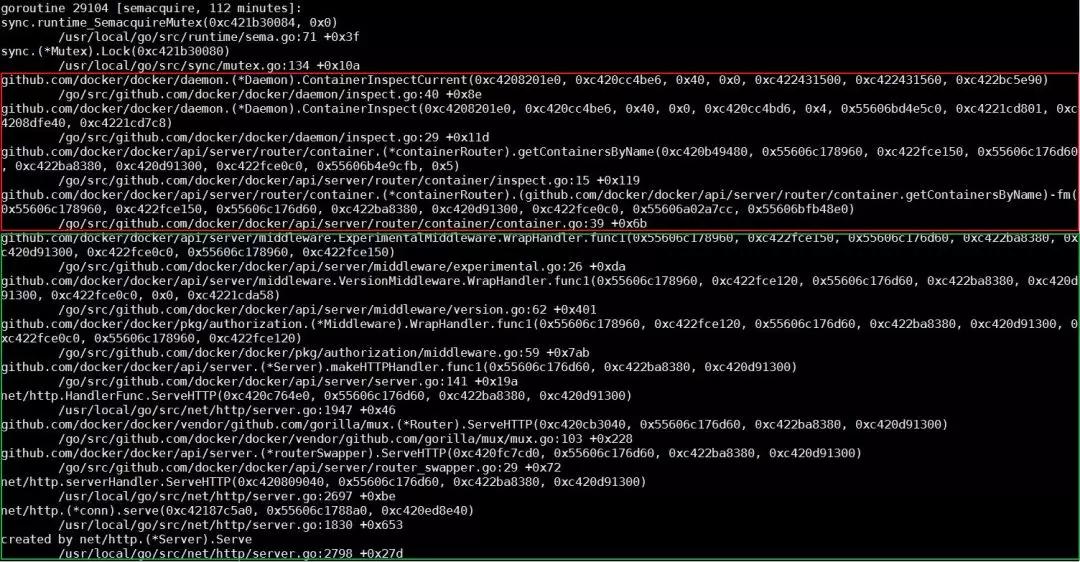
到這里,我們需要稍微看一下 ContainerInspectCurrent 這個函數的實現。從實現可以看到,這個函數的***個參數,就是這個線程正在操作的容器名指針。使用這個指針搜索整個調用棧文件,我們會找出所有等在這個容器上的線程。同時,我們可以看到下邊這個線程。
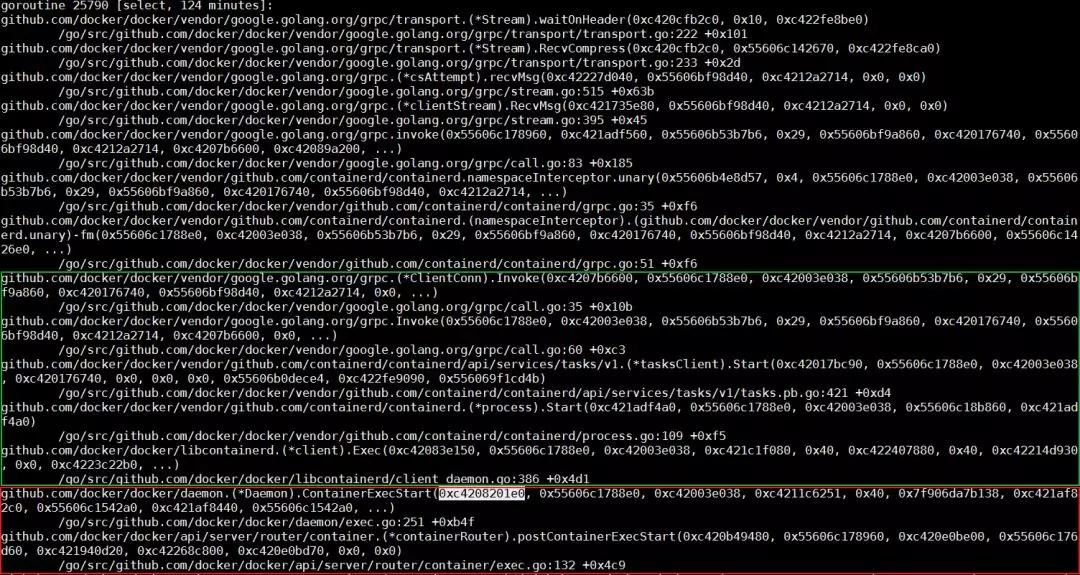
這個線程調用棧上的函數 ContainerExecStart 也是在處理相同容器。但不同的是,ContainerExecStart 并沒有在等這個容器,而是已經拿到了這個容器的操作權(mutex),并把執行邏輯轉向了 containerd 調用。關于這一點,我們也可以使用代碼來驗證。前邊我提到過,containerd 通過 gRPC 向上對 docker daemon 提供接口。此調用棧上半部分內容,正是 docker daemon 在通過 gRPC 請求來呼叫containerd。
Containerd調用棧分析
與 docker daemon 類似,我們可以通過 kill -SIGUSR1
Containerd 作為一個 gRPC 的服務器,會在接到 docker daemon 的遠程調用之后,新建一個線程去處理這次請求。關于 gRPC 的細節,我們這里其實不用太多關注。在這次請求的客戶端調用棧上,可以看到這次調用的核心函數在 Start 一個Process 。我們在 containerd 的調用棧里搜索 Start,Process 以及 process.go 等字段,很容易發現下邊這個線程。
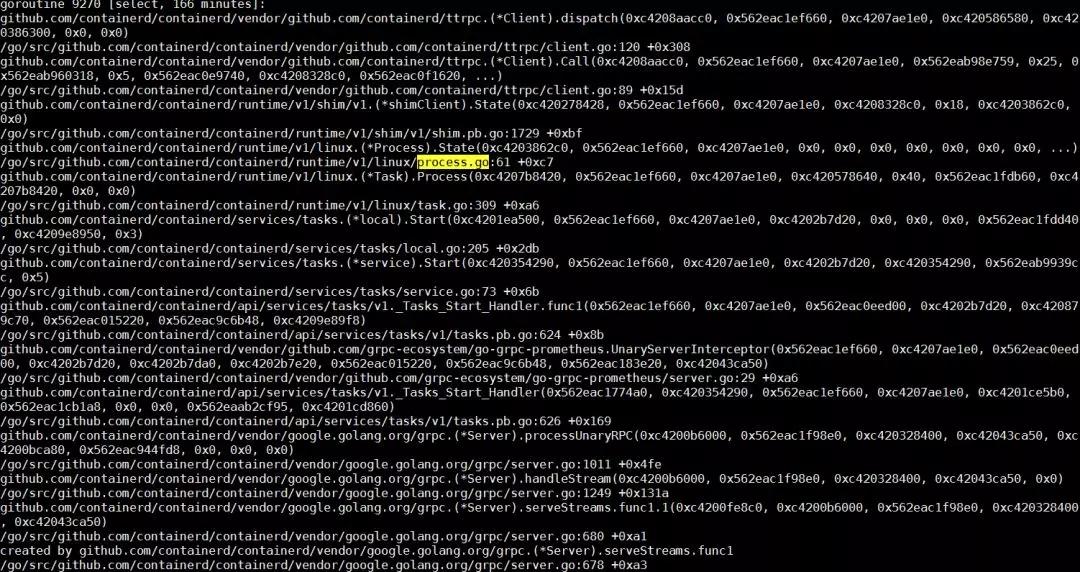
這個線程的核心任務,就是依靠 runC 去創建容器進程。而在容器啟動之后,runC 進程會退出。所以下一步,我們自然而然會想到,runC 是不是有順利完成自己的任務。查看進程列表,我們會發現,系統中有個別 runC 進程還在執行,這不是預期的行為。容器的啟動,跟進程的啟動,耗時應該是差不多數量級的,系統里有正在運行的 runC 進程,則說明 runC 不能正常啟動容器。
什么是D-Bus?
RunC請求D-Bus
容器 runtime 的 runC 命令,是 libcontainer 的一個簡單的封裝。這個工具可以用來管理單個容器,比如容器創建和容器刪除。在上節的***,我們發現 runC 不能完成創建容器的任務。我們可以把對應的進程殺掉,然后在命令行用同樣的命令啟動容器,同時用 strace 追蹤整個過程。
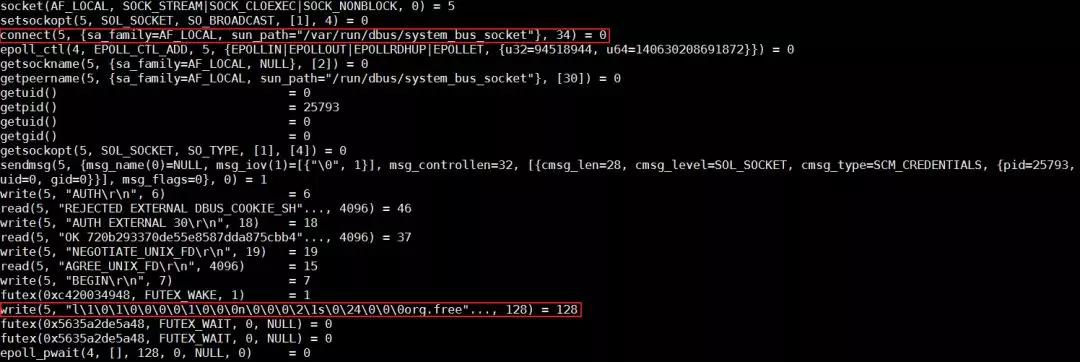
分析發現,runC 停在了向帶有 org.free 字段的 dbus socket 寫數據的地方。那什么是 dbus 呢?在 Linux 上,dbus 是一種進程間進行消息通信的機制。
原因并不在 D-Bus
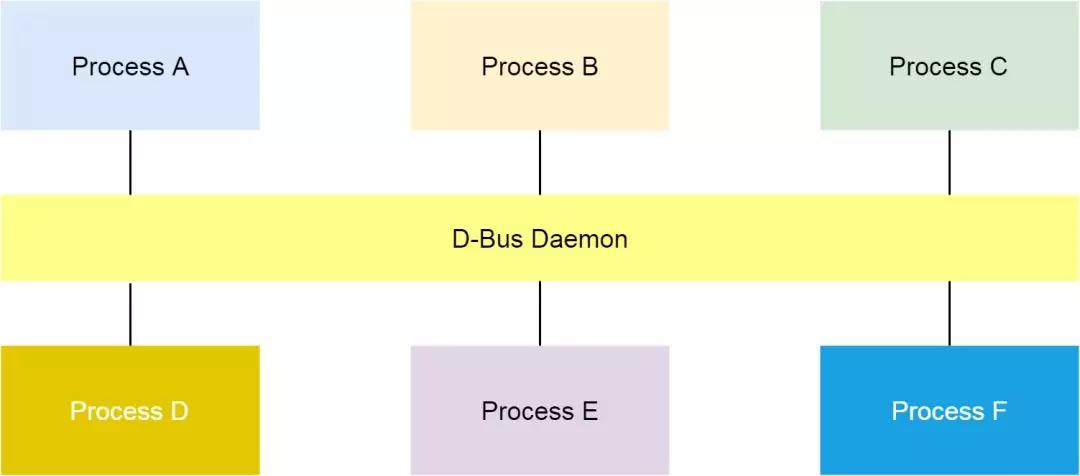
我們可以使用 busctl 命令列出系統現有的所有 bus 。如下圖,在問題發生的時候,我看到問題節點 bus name 編號非常大。所以我傾向于認為,dbus 某些相關的數據結構,比如 name,耗盡了引起了這個問題。
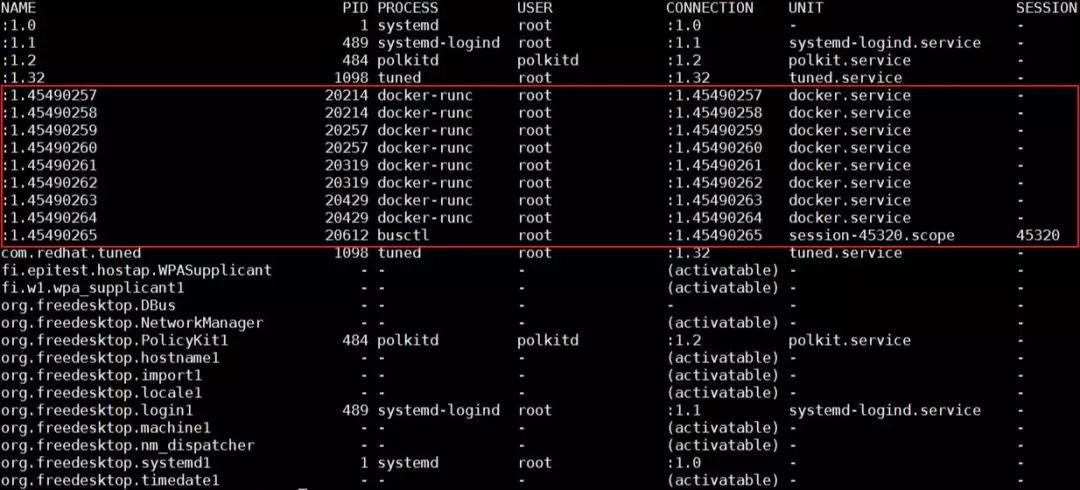
Dbus 機制的實現,依賴于一個組件叫做 dbus daemon。如果真的是 dbus 相關數據結構耗盡,那么重啟這個 daemon,應該可以解決這個問題。但不幸的是,問題并沒有這么直接。重啟 dbus daemon 之后,問題依然存在。
在上邊 strace 追蹤 runC 的截圖中,runC 停在向帶有 org.free 字段的 bus 寫數據的地方。在 busctl 輸出的 bus 列表里,顯然帶有這個字段的 bus,都在被 systemd使用。這時,我們用 systemctl daemon-reexec 來重啟 systemd,問題消失了。所以基本上我們可以判斷一個方向,問題可能跟 systemd 有關。
Systemd是硬骨頭
Systemd 是相當復雜的一個組件,尤其對沒有做過相關開發工作的同學來說,比如我自己。基本上,排查 systemd 的問題,我用到了四個方法,(調試級別)日志,core dump,代碼分析,以及 live debugging。其中***個,第三個和第四個結合起來使用,讓我在經過幾天的鏖戰之后,找到了問題的原因。但是這里我們先從“沒用”的 core dump 說起。
“沒用的”Core Dump
因為重啟 systemd 解決了問題,而這個問題本身,是 runC 在使用 dbus 和systemd 通信的時候沒有了響應,所以我們需要驗證的***件事情,就是 systemd不是有關鍵線程被鎖住了。查看 core dump 里所有線程,只有以下一個線程,此線程并沒有被鎖住,它在等待 dbus 事件,以便做出響應。

零散的信息
因為無計可施,所以只能做各種測試、嘗試。使用 busctl tree 命令,可以輸出所有bus 上對外暴露的接口。從輸出結果看來,org.freedesktop.systemd1 這個 bus 是不能響應接口查詢請求的。
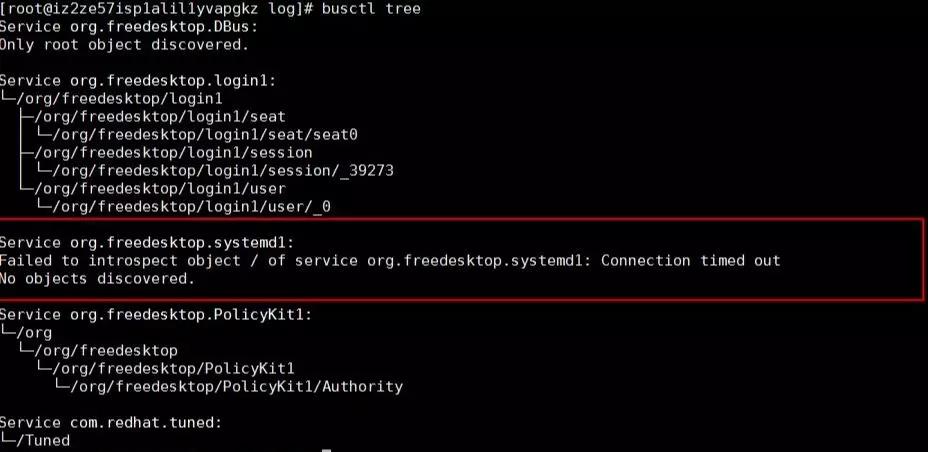
使用下邊的命令,觀察 org.freedesktop.systemd1 上接受到的所以請求,可以看到,在正常系統里,有大量 Unit 創建刪除的消息,但是有問題的系統里,這個 bus 上完全沒有任何消息。
gdbus monitor --system --dest org.freedesktop.systemd1 --object-path /org/freedesktop/systemd1
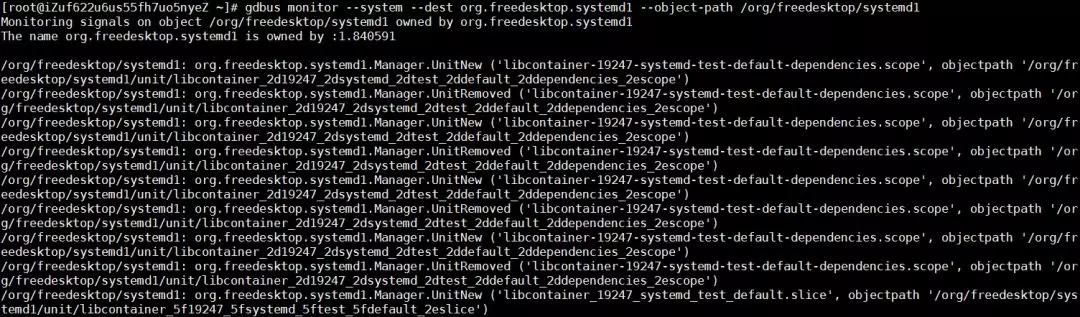
分析問題發生前后的系統日志,runC在重復的跑一個libcontainer_%d_systemd_test_default.slice 測試,這個測試非常頻繁,但是當問題發生的時候,這個測試就停止了。所以直覺告訴我,這個問題,可能和這個測試有很大的關系。
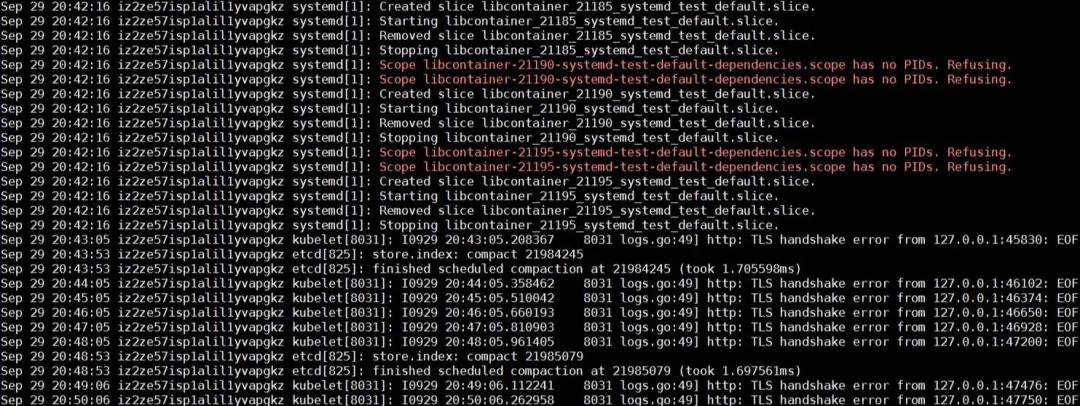
另外,我使用 systemd-analyze 命令,打開了 systemd 的調試級別日志,發現 systemd 有 Operation not supported 的報錯。
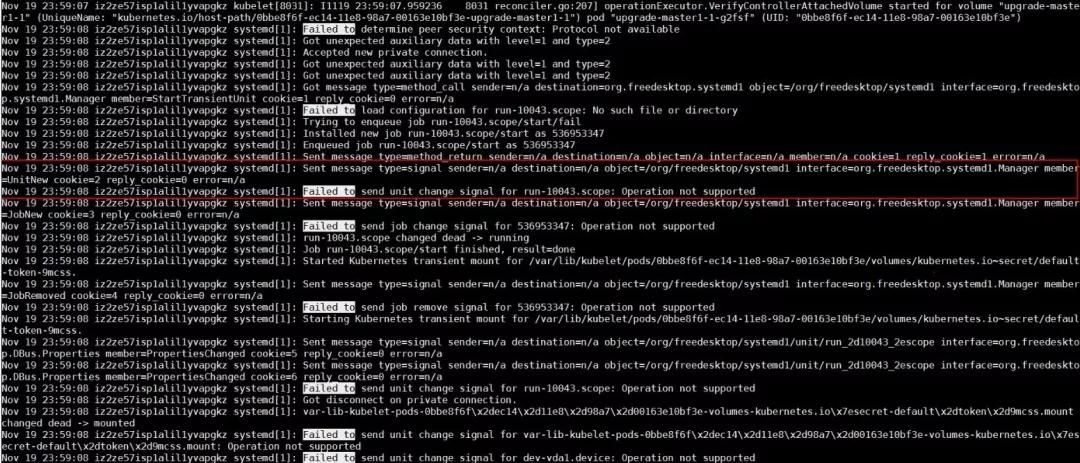
根據以上零散的知識,可以給出一個大概的結論:org.freedesktop.systemd1 這個 bus 在經過大量 unit 創建刪除之后,沒有了響應。而這些頻繁的 unit 創建刪除測試,是 runC 某一個改動引入的。這個改動使得 UseSystemd 函數通過創建 unit 來測試 systemd 的功能。UseSystemd 在很多地方被調用,比如創建容器,或者查看容器性能等操作。
代碼分析
這個問題在線上所有 Kubernetes 集群中,發生的頻率大概是一個月兩例。問題一直在發生,且只能在問題發生之后,通過重啟 systemd 來處理,這風險極大。
我們分別給 systemd 和 runC 社區提交了 bug,但是一個很現實的問題是,他們并沒有像阿里云這樣的線上環境,他們重現這個問題的概率幾乎是零,所以這個問題沒有辦法指望社區來解決。硬骨頭還得我們自己啃。
在上一節***,我們看到了,問題出現的時候,systemd 會輸出一些 Operation not supported 報錯。這個報錯看起來和問題本身風馬牛不相及,但是直覺告訴我,這,或許是離問題最近的一個地方,所以我決定,先搞清楚這個報錯因何而來。
Systemd 代碼量比較大,而報這個錯誤的地方非常多。通過大量的代碼分析(這里略去一千字),我發現有幾處比較可疑地方,有了這些可疑的地方,接下來需要做的事情,就是等待。在等了三周以后,終于有線上集群,再次重現了這個問題。
Live Debugging
在征求用戶同意之后,下載 systemd 調試符號,掛載 gdb 到 systemd 上,在可疑的函數下斷點,continue 繼續執行。經過多次驗證,發現 systemd 最終踩到了sd_bus_message_seal 這個函數里的 EOPNOTSUPP 報錯。
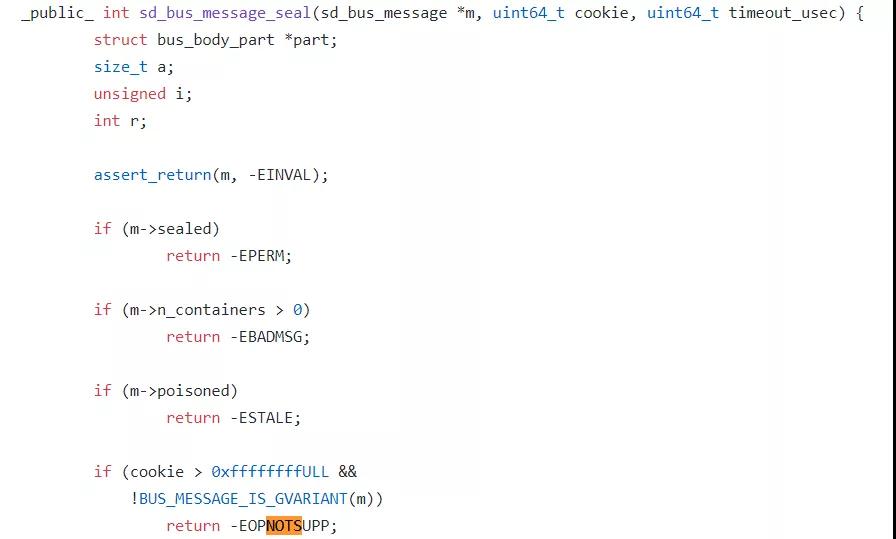
這個報錯背后的道理是,systemd 使用了一個變量 cookie,來追蹤自己處理的 dbus message 。每次在加封一個新的 message 的時候,systemd 會先給 cookie的值加一,然后再把這個值復制給這個新的 message。
我們使用 gdb 打印出 dbus->cookie 這個值,可以很清楚看到,這個值超過了0xffffffff 。所以看起來,問題是 systemd 在加封過大量 message 之后,cookie 這個值32位溢出了,導致新的消息不能被加封,從而使得 systemd 對 runC 沒有了響應。

另外,在一個正常的系統上,使用 gdb 把 bus->cookie 這個值改到接近 0xffffffff,然后觀察到,問題在 cookie 溢出的時候立刻出現,則證明了我們的結論。
怎么判斷集群節點NotReady是這個問題導致的
首先我們需要在有問題的節點上安裝 gdb 和 systemd debuginfo,然后用命令 gdb /usr/lib/systemd/systemd1 把 gdb attach 到 systemd ,在函數sd_bus_send 設置斷點,然后繼續執行。等 systemd 踩到斷點之后,用 p /x bus->cookie 查看對應的cookie值,如果此值超過了 0xffffffff,那么 cookie 就溢出了,則必然導致節點 NotReady 的問題。確認完之后,可以使用 quit 來 detach 調試器。
問題修復
這個問題的修復,并沒有那么直截了當。原因之一,是 systemd 使用了同一個 cookie 變量,來兼容 dbus1 和 dbus2 。對于 dbus1 來說, cookie 是32位的,這個值在經過 systemd 三五個月頻繁創建刪除 unit 之后,是肯定會溢出的;而 dbus2 的 cookie 是64位的,可能到了時間的盡頭,它也不會溢出。
另外一個原因是,我們并不能簡單的讓 cookie 折返,來解決溢出問題。因為這有可能導致 systemd 使用同一個 cookie 來加封不同的消息,這樣的結果將是災難性的。
最終的修復方法是,使用32位 cookie 來同樣處理 dbus1 和 dbus2 兩種情形。同時在 cookie 達到 0xfffffff 的之后,下一個 cookie 則變成 0x80000000,即用***位來標記 cookie 已經處于溢出狀態。檢查到 cookie 處于這種狀態時,我們需要檢查是否下一個 cookie 正在被其他 message 使用,來避免 cookie 沖突。
后記
這個問題根本原因肯定在 systemd,但是 runC 的函數 UseSystemd 使用不那么美麗的方法,去測試 systemd 的功能,而這個函數在整個容器生命周期管理過程中,被頻繁的調用,讓這個低概率問題的發生成為了可能。systemd 的修復已經被紅帽接受,預期不久的將來,我們可以通過升級 systemd,從根本上解決這個問題。