Facebook開源了超大規(guī)模圖嵌入算法,上億個節(jié)點也能快速完成
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯(lián)系出處。
圖,是很有用的數(shù)據(jù)結構,用節(jié)點 (Node) 和邊 (Edge) 織成一張網(wǎng)。比如,知識圖譜就是這樣的網(wǎng)。
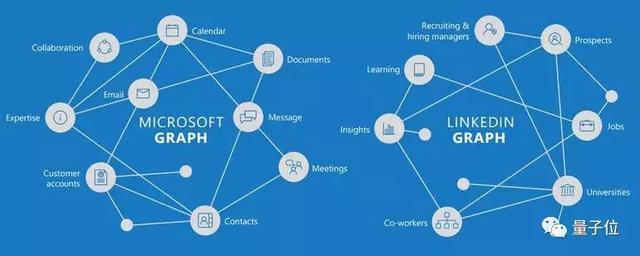
處理這樣的數(shù)據(jù),要用到圖嵌入 (Graph Embedding) :把高維的網(wǎng)絡,轉換成低維的向量。處理之后,機器學習模型才能輕易食用。
如果像上圖這樣,只有幾個節(jié)點,十幾條邊,圖嵌入沒什么難度。
如果有幾十億個節(jié)點,幾萬億條邊呢?傳統(tǒng)的圖嵌入方法就捉急了。
但現(xiàn)在,F(xiàn)acebook開源了叫做PyTorch-BigGraph (簡稱PBG) 的新工具。

有了它,再大的圖 (原文是arbitrarily large,任意大) 都能快速生成圖嵌入。而且,完全不需要GPU。
開源模型除了可以自己訓練之外,還有拿7,800萬節(jié)點的Wikidata數(shù)據(jù)預訓練過的模型,可以直接下載來用。
PBG發(fā)表之后,小伙伴們紛紛奔走相告:
LeCun老師還親自轉發(fā)了兩次。
如何養(yǎng)成
PBG是一個分布式系統(tǒng),用1.2億個節(jié)點的完整FreeBase知識圖譜來訓練的。

訓練過程中,PBG會吃進圖上所有邊 (Edge) 的大列表,每條邊都是用它兩端的節(jié)點來定義,一個是源 (Source) ,一個是目標 (Target) 。定義中也有兩點之間的關系 (Relation Type) 。
然后,PBG給每一個節(jié)點,輸出一個特征向量 (就是嵌入) ,讓兩個相鄰的節(jié)點在向量空間中離得近一些,讓不相鄰節(jié)點的離遠一些。
這樣一來,那些周圍環(huán)境分布相近的節(jié)點,在向量空間里的位置也會彼此靠近,圖原本要表達的意思就保留下來了。
另外,針對每種不同的關系,“近似度得分 (Proximity Score) ”都可以定制不同的計算方法。這樣,一個節(jié)點的嵌入,就可以在不同種類的關系里共享了。
快一點,再快一點
要快速處理大規(guī)模的圖數(shù)據(jù),PBG用了這幾個法術:
一是圖分區(qū) (Graph Partitioning) ,這樣就不需要把整個模型加載到內(nèi)存里了。在圖嵌入質(zhì)量不損失的情況下,比不分區(qū)時節(jié)省了88%的內(nèi)存占用。二是一臺機器進行多線程計算。三是在多臺機器上同時跑,在圖上各自跑一個不相鄰的區(qū)域。四是批次負采樣(Batched Negative Sampling) ,能讓一臺CPU每秒處理100萬條邊,每條邊100次負采樣。
訓練完成之后,在FB15k、Youtube、LiveJournal等等圖譜上,都測試過。
團隊說,PBG和大前輩們的圖嵌入質(zhì)量相當,但需要的時間明顯縮短了。
你也試一試吧
你也去訓練一個PBG吧。
反正,也不用GPU。
不想訓練的話,還有用完整WikiData預訓練的模型。
你需要的傳送門,都在這里了。
代碼傳送門:
https://github.com/facebookresearch/PyTorch-BigGraph
食用索引:
https://torchbiggraph.readthedocs.io/en/latest/
論文傳送門:
https://arxiv.org/abs/1903.12287
博客傳送門:
https://ai.facebook.com/blog/open-sourcing-pytorch-biggraph-for-faster-embeddings-of-extremely-large-graphs/